







 这篇博客探讨了如何运用Python进行数据分析和逻辑回归模型建立,以预测顾客在天猫平台是否会使用优惠券。通过分析数据,发现无违约记录、无退货记录的顾客更可能使用优惠券,已婚顾客比单身顾客使用优惠券的概率更高,且60-80岁的顾客使用比例最高。此外,`coupon_used_in_last_month`和年龄与优惠券使用正相关,而其他因素负相关。最终,文章通过调整模型参数优化了预测准确率。
这篇博客探讨了如何运用Python进行数据分析和逻辑回归模型建立,以预测顾客在天猫平台是否会使用优惠券。通过分析数据,发现无违约记录、无退货记录的顾客更可能使用优惠券,已婚顾客比单身顾客使用优惠券的概率更高,且60-80岁的顾客使用比例最高。此外,`coupon_used_in_last_month`和年龄与优惠券使用正相关,而其他因素负相关。最终,文章通过调整模型参数优化了预测准确率。
顾客使用天猫优惠劵预测
“天猫”(Tmall)原名淘宝商城,是一个综合性购物网站,是马云淘宝网全新打造的B2C(Business-to-Coustomer,商业零售)品牌。其整合数千家品牌商,生产商,为商家和消费者之间提供一站式解决方案,提供100%品质保证的商品,7天无理由退货的售后服务,以及购物积分返现等优质服务。
问题:基于所给的数据,利用Python进行数据分析和建立逻辑回归模型,对顾客是否使用优惠劵进行预测。
数据表的主要字段:
ID:记录编号
age:年龄
job:职业
marital:婚姻状态
default:花呗是否有违约(类别型变量)
returned:是否有过退货(类别型变量)
loan:是否使用花呗结账(类别型变量)。
coupon_used_in_last6_month:过去6个月使用的优惠劵数量
coupon_used_in_last_month:过去1个月使用的优惠劵数量
coupon_ind:该次活动中是否有使用优惠劵(预测目标)
打开python,开始敲代码
首先导入相关的库和数据文件
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
#解决中文和负号不正常显示的问题
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
df=pd.read_csv(r'Tmall.csv')
#查看数据概括
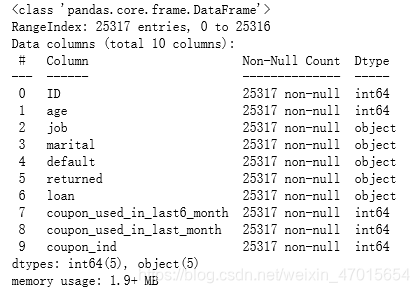
df.info()
#查看前5行数据
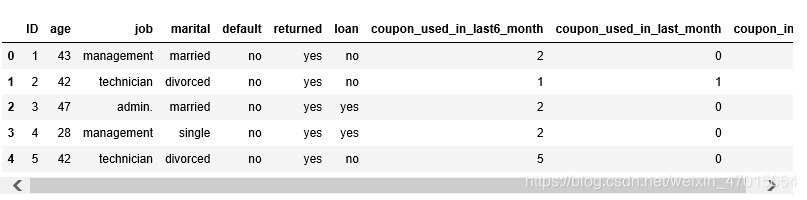
df.head()
#查看job变量的所有不重复值
df.job.value_counts()

#查看marital变量的所有不重复值
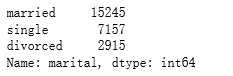
df.marital.value_counts()
对于类别型变量,需要进行哑变量处理。我个人认为job和marital变量不需要进行哑变量处理。job变量的非重复值太多了,经过哑变量处理会使数据显得冗余。marital变量有3个非重复值,可以用下文的相关性分析,没有必要进行哑变量处理。
需要进行哑变量处理的变量为:default,returned,loan。(都是2分类变量)
#把default、returned、loan三个变量单独取出来进行哑变量处理get_dummies()。
df1=df[['default','returned','l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2430
2430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









