







 本文详细介绍了C语言的内存管理,包括内存划分、动态内存函数malloc()、calloc()、realloc()、free()的使用,以及野指针、内存泄漏的概念和防范措施。此外,还总结了局部变量、全局变量、静态局部变量和静态全局变量的特性,强调了内存管理在实际开发中的重要性。
本文详细介绍了C语言的内存管理,包括内存划分、动态内存函数malloc()、calloc()、realloc()、free()的使用,以及野指针、内存泄漏的概念和防范措施。此外,还总结了局部变量、全局变量、静态局部变量和静态全局变量的特性,强调了内存管理在实际开发中的重要性。
本篇博客针对内存的划分进行详细讲解,这与指针访问内存息息相关,因此清楚内存的划分区域至关重要,此外,栈区的空间大小相对较小,不够实际使用,相较于之前的静态数组,实际开发是一个动态变化的数组,可理解为顺序表,为方便进行管理,针对堆区的动态内存管理十分重要,本篇博客第二部分主要总结C语言中常用的动态内存函数malloc()、calloc()、realloc()、free(),以及常见的错误和经典的笔试题,最后对于常用的变量类型进行总结,这涉及到多文件编程,变量的生命周期等重要知识。
目录
一、内存划分
1、认识内存
程序是保存在硬盘中的,要载入内存才能运行,CPU也被设计为只能从内存中读取数据和指令。如下图所示:CPU直接与内存打交道,它会读取内存中的数据进行处理,并将结果保存到内存。如果需要保存到硬盘,才会将内存中的数据复制到硬盘。
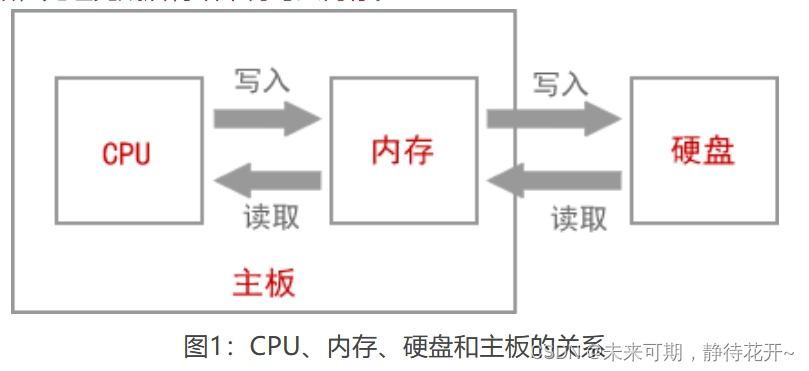
对于CPU来说,内存仅仅是一个存放指令和数据的地方,并不能在内存中完成计算功能,例如要计算 a = b + c,必须将 a、b、c 都读取到CPU内部才能进行加法运算。为了了解具体的运算过程,先来看一下CPU的结构,如下图所示:
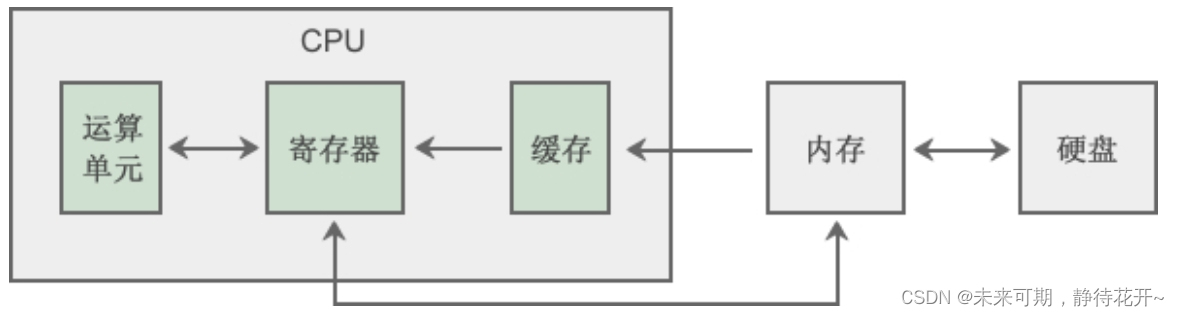
运算单元是CPU的大脑,负责加减乘除、比较、位移等运算工作,每种运算都有对应的电路支持,速度很快。
寄存器(Register)是CPU内部非常小、非常快速的存储部件,它的容量很有限,对于32位的CPU,每个寄存器一般能存储32位(4个字节)的数据,对于64位的CPU,每个寄存器一般能存储64位(8个字节)的数据。为了完成各种复杂的功能,现代CPU都内置了几十个甚至上百个的寄存器,嵌入式系统功能单一,寄存器数量较少。经常听说多少位的CPU,指的就是寄存器的的位数。现在个人电脑使用的CPU已经进入了64位时代,例如 Intel 的 Core i3、i5、i7 等。寄存器在程序的执行过程中至关重要,不可或缺,它们可以用来完成数学运算、控制循环次数、控制程序的执行流程、标记CPU运行状态等。在CPU内部为什么又要设置缓存呢?虽然内存的读取速度已经很快了,但是和CPU比起来,还是有很大差距的,不是一个数量级的,如果每次都从内存中读取数据,会严重拖慢CPU的运行速度,CPU经常处于等待状态,无事可做。在CPU内部设置一个缓存,可以将使用频繁的数据暂时读取到缓存,需要同一地址上的数据时,就不用大老远地再去访问内存,直接从缓存中读取即可。
2、C/C++程序内存区域的划分
window7操作系统开始从微软被分为64位和32位(x86),x86(32位)操作系统,对应32位地址总线,对应个字节,最大运行内存为:
,内存划分的基本单位为1个字节,1个字节等于8个比特位,内存地址为32位二进制序列(4个字节),通常在编译器中以十六进制数表示,即8位十六进制数(因为1位十六进制数相当于4位二进制数),因此4G内存的地址从0x0000 0000-0xffff ffff。4G内存区域划分及各部分存放的数据类型如下图所示:
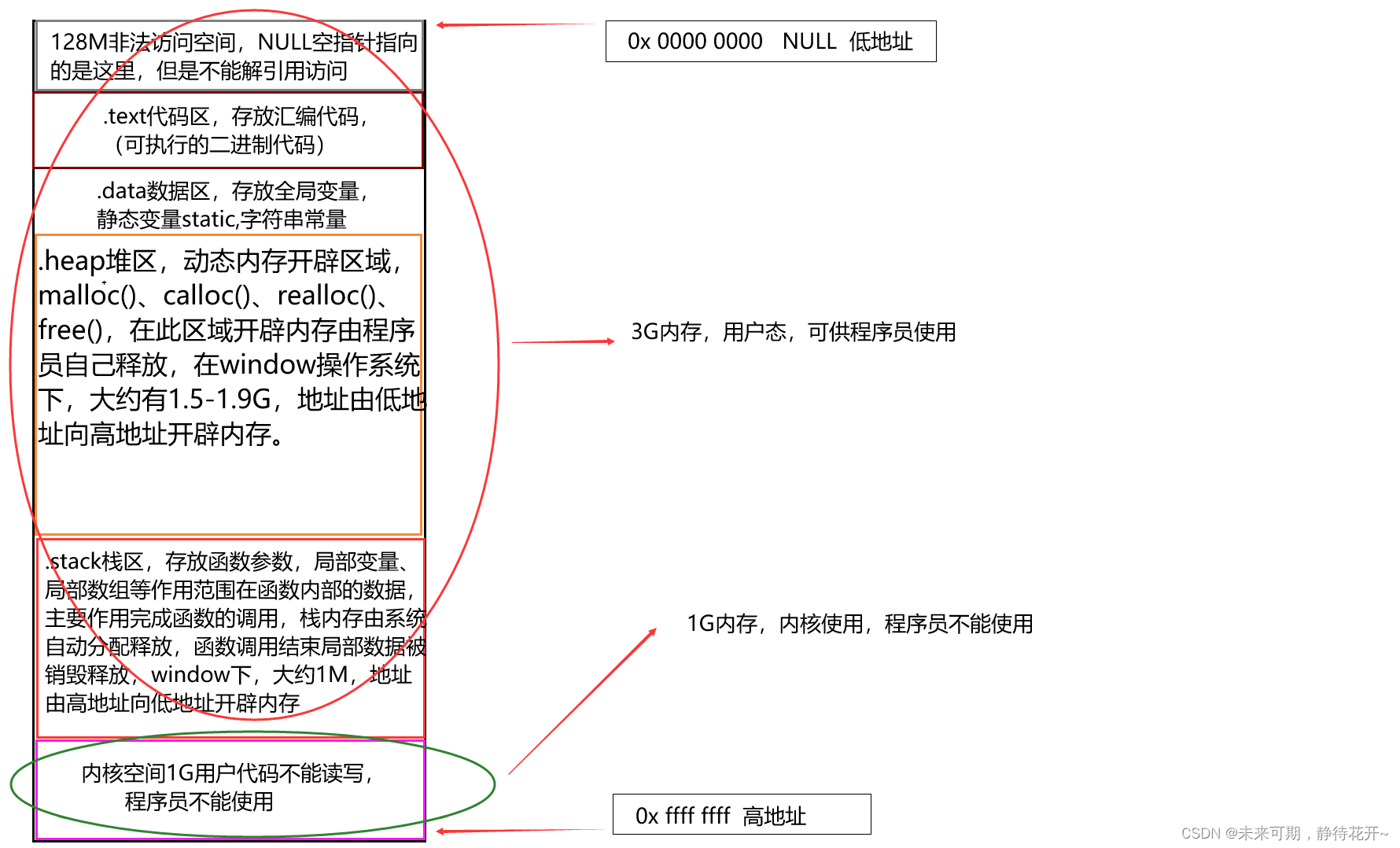
堆区的内存空间开辟由低地址向高地址开辟,而栈区的内存空间开辟由高地址向低地址开辟,二者的方向是相对的。在程序中定义的变量的存放位置如下图可以直观看到:
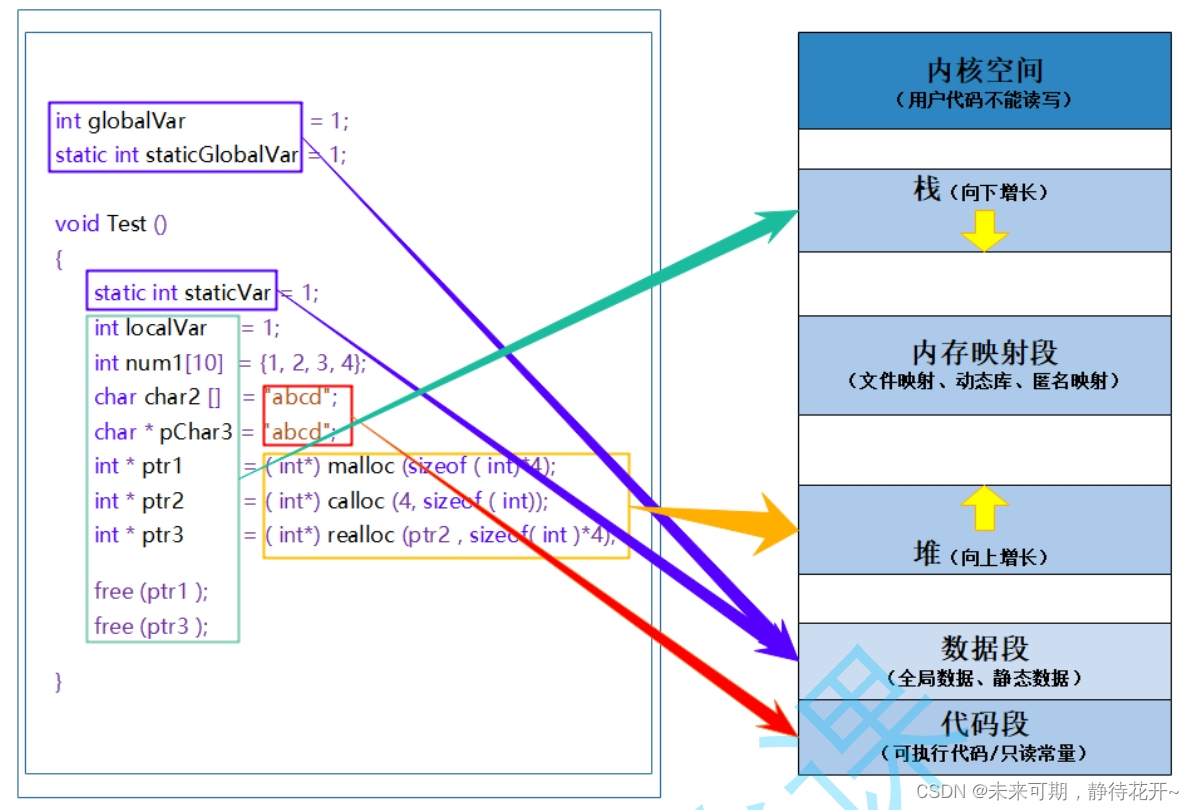
C/C++程序内存分配的几个区域:
1. 栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是 分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。
2. 堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。分配方式类似于链表。
3. 数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放。
4. 代码段:存放函数体(类成员函数和全局函数)的二进制代码。
有了这幅图,我们就可以更好的理解static关键字修饰局部变量的例子。 实际上普通的局部变量是在栈区分配空间的,栈区的特点是在上面创建的变量出了作用域就销毁。 但是被static修饰的变量存放在数据段(静态区),数据段的特点是在上面创建的变量,直到程序结束才销毁所以生命周期变长。
二、动态内存管理(重点)
1、为什么存在动态内存分配?
栈区是内存地址较高的一个区域,栈可以存放函数参数、局部变量、局部数组等作用范围在函数内部的数据,它的用途就是完成函数的调用,栈内存由系统自动分配和释放,发生函数调用时就为函数运行时用到的数据分配内存,函数调用结束后就将之前分配的内存全部销毁,因此,局部变量、参数只在当前函数中有效,不能传递到函数外部。
一般想通过函数传参修改外部数据,都是通过传指针,然后在函数内部进行解引用,此外,不能返回栈区开辟的变量的地址(局部变量的地址),因为,函数调用结束后,局部变量内存被系统回收,此时,这个空间对应的地址虽然存在,但是已经归还给操作系统,可能被用来其他地方,此时无法再进行使用,属于非法访问!
静态内存分配
在进程的地址空间中,代码区、常量区、全局数据区的内存在程序启动时,就已经分配好了,它们的大小固定,不能由程序员分配和释放,只能等到程序运行结束由操作系统回收。
动态内存分配
栈区和堆区的内存在程序运行期间可以根据实际需要来分配和释放,不用程序刚启动时就备足所有内存。
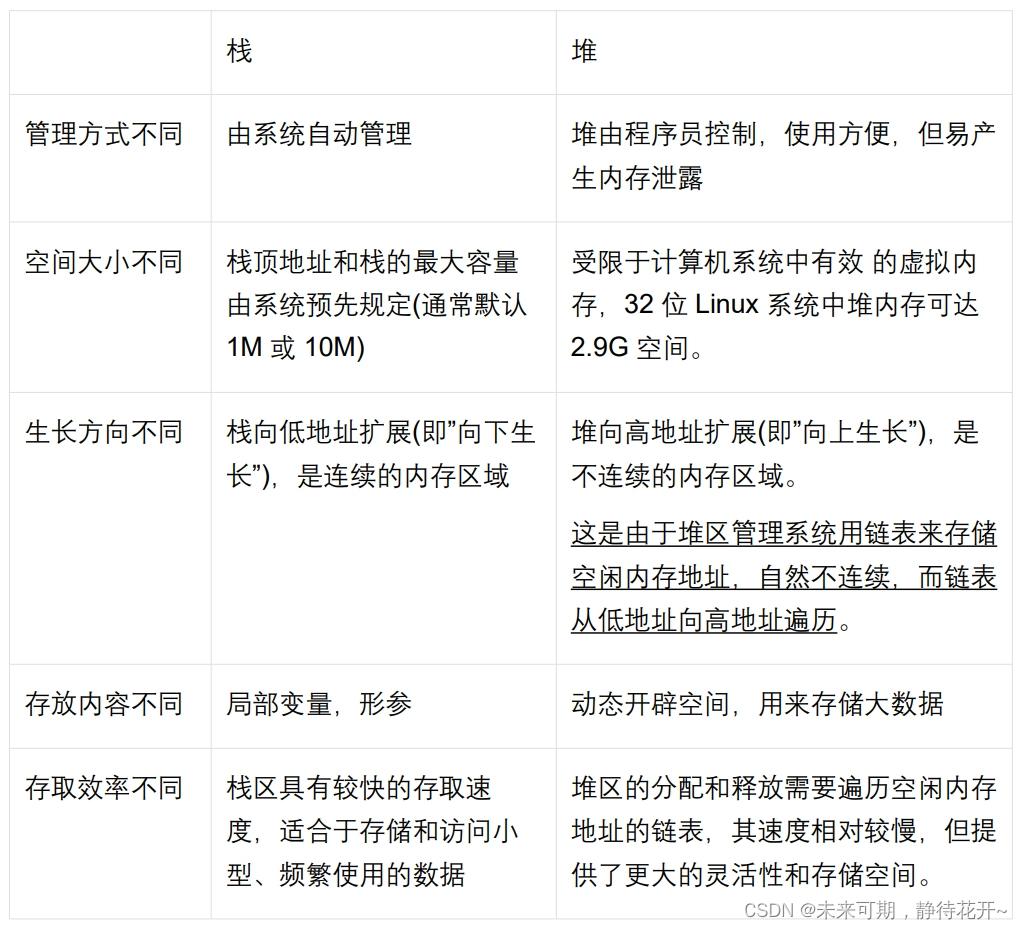
栈区和堆区的区别(重点理解):
(1) 默认大小:window操作系统下,栈区默认大小:1M=1024*1024个字节;Linux操作系统下:栈区默认大小:10M; window操作系统下,堆区默认大小:1.5-1.9G;Linux操作系统下:堆区默认大小:2.9G;二者相比而言,堆区可用的内存空间更大。
(2) 内存空间开辟方向:堆区的内存开辟方向是由低地址向高地址开辟(向上成长),是不连续的内存区域;栈区的内存开辟方向是由高地址向低地址开辟(向下成长)的,是连续的内存区域,二者的方向是相对的。堆通常在头部用一个字节存放其大小,堆用于存储生存期与函数调用无关的数据,具体内容由程序员安排。
(3)管理方式:栈区主要存放局部变量、函数参数、局部数组等,栈区内存由系统分配和释放,不用程序员控制;堆区可申请任意大小的内存空间,并通常与指针强转结合使用,可以转换成任意类型的数据,方便通过指针操作数据(这与指针加1的能力有关),堆区内存完全由程序员掌控,由程序员自己申请和释放,使用方便,但容易产生野指针和内存泄露问题!!实际开发需要注意此类问题。
我们已经掌握的内存开辟方式有:
int a = 20;//在栈空间上开辟四个字节
int arr[10] = {0};//在栈空间上开辟40个字节的连续空间但是上述的开辟空间的方式有两个特点: 1. 空间开辟大小是固定的。 2. 数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。 但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小在程序运行的时候才能知道, 比如对于常用的静态数组在实现增删改查时,就必须要重新开辟一个数组,不方便进行管理,那数组的编译时开辟空间的方式就不能满足了。 这时候就只能试试动态存开辟了。
2、动态内存函数介绍
C语言中常用的动态内存函数有:malloc()、calloc()、realloc()、free(),它们都在头文件"stdlib.h",使用时需要引入这个头文件,重点掌握使用方法和注意事项。
(1)malloc()函数的介绍与使用
函数原型: void* malloc( size_t size ); typedef unsigned int size_t;
函数作用:向内存申请一块连续可用的未经过初始化(随机值)空间,并返回指向这块空间的指针。
返回值:如果开辟成功,则返回一个指向开辟好空间的指针。 如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。 返回值的类型是 void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己来决定,通常与指针强转结合使用,通过强制类型转换可把内存空间划分为不同的单元格个数的内存空间,然后通过指针便可访问内存空间中的数据,这取决于指针+1的能力,使用时同指针访问数组! 如果参数 size 为0,malloc的行为是标准是未定义的,取决于编译器。
使用方法:
1、申请内存int *p=(int *)malloc(NUM*sizeof(int))
2、断言指针:assert(p!=NULL)
3、遵循数组的指针方式使用方法
4、释放内存free(p)
5、防止出现野指针将指针置空p=NULL#include<stdio.h> #include<stdlib.h> //引入头文件 #include<cassert> #define NUM 10 //重定义申请的元素个数 int main() { int* p = (int*)malloc(NUM * sizeof(int)); assert(p != NULL); for (int i = 0; i < NUM; i++) { *(p + i) = i + 1; //或者p[i]=i+1; printf("%d", *(p + i)); //或者p[i] } free(p); p = NULL; //防止多次释放出现指针崩溃,造成程序崩掉。 return 0; }注意事项:为避免
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











