







一、mysql死锁及超时的原因
当在业务逻辑中看到这个错误,或者mysql中使用update语句更新数据报错: Lock wait timeout exceeded; try restarting transaction。也就是遇到了mysql死锁,等待资源,事务锁的问题。
可能原因:意外处理没有关闭连接,导致连接过多、或是要更新的表的锁在其它线程手里、系统异常导致事务未提交,再次请求相同记录等等。
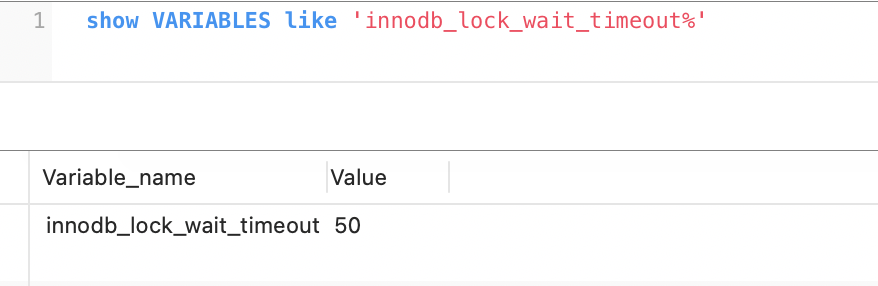
InnoDB关于在出现锁等待的时候,会根据参数innodb_lock_wait_timeout的配置(默认50s),判断是否需要进行timeout的操作:
二、mysql死锁排查思路
1、show full processlist 查询当前数据库全部线程
show full processlist 查询当前数据库全部线程
show engine innodb status命令查看当前的数据库请求,然后再判断当前事务中锁的情况
select * from information_schema.innodb_trx 查询当前运行的全部事务
注:select * from information_schema.innodb_trx;
MySQL 5.5版本以上才可以用此方法,5.5版本以下会没有这个表;[Err] 1109 - Unknown table ‘innodb_trx’ in information_schema
当中trx_mysql_thread_id为事务线程的id,參照show full processlist命令中的线程信息查看
如果数据库中有锁的话,LOCK WAIT的就是锁等待的

此时你可以直接使用命令:kill 事务线程id 杀掉它。比如:kill 99999
没有的话,找到Command 状态是query 并且Time 时间很长的id)有时候一定程度上也能解决一定的问题。
再用 show full processlist 查询当前数据库全部线程,发现刚才的线程没了。
但是一般这样还是很难发现被锁的行记录问题所在
2、information_schema
information_schema这张数据表保存了MySQL服务器所有数据库的信息。
我们可以用这三张表innodb_trx、innodb_locks、innodb_lock_waits,使用如下命令,简单地监控当前的事务并分析可能存在的问题:
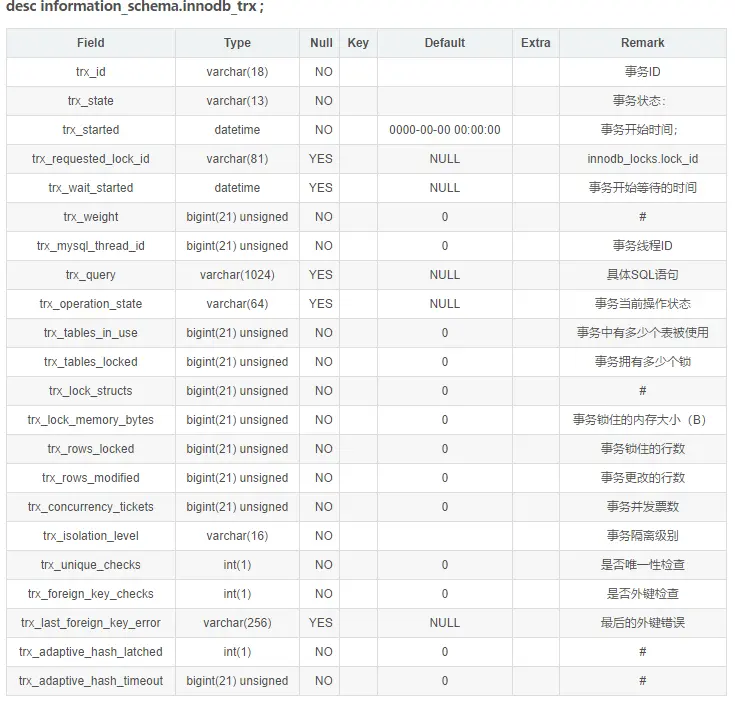
select * from information_schema.innodb_trx ( 当前运行的所有事务)
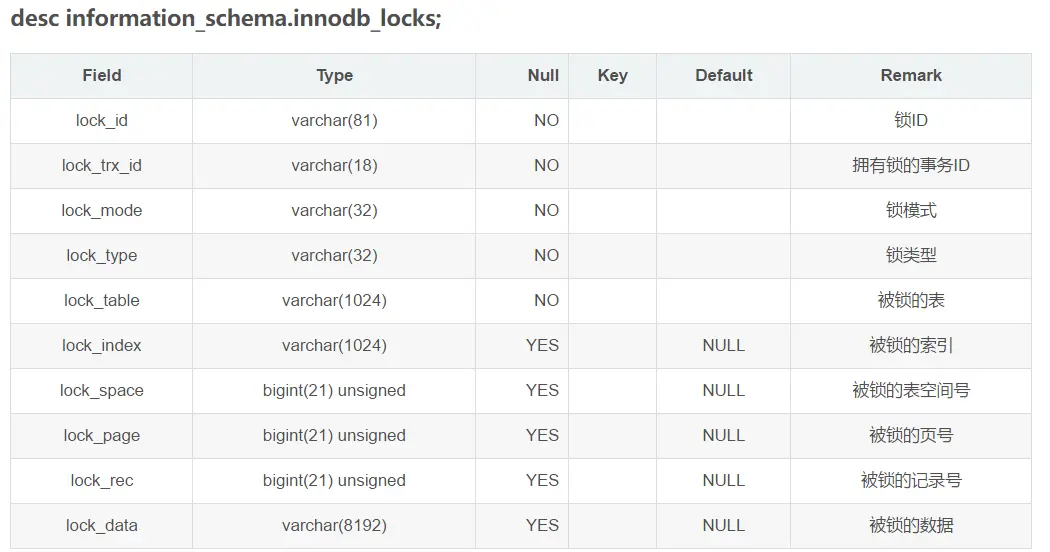
select * from information_schema.innodb_locks (当前出现的锁)
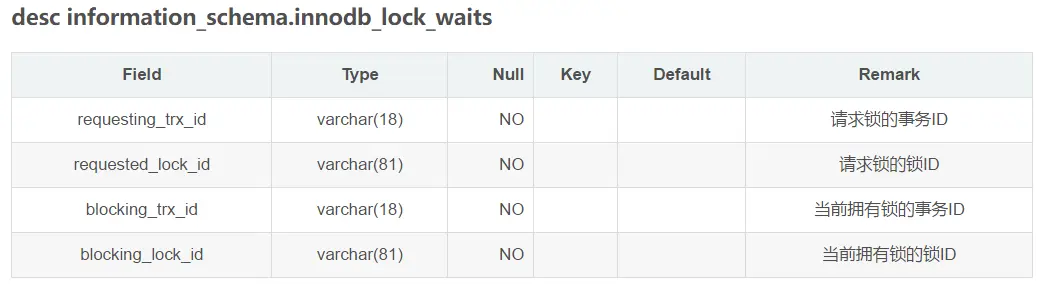
select * from information_schema.innodb_lock_waits (锁等待的对应关系)
注意:在8.0.13版本中
innodb_locks表由performance_schema.data_locks表所代替,
innodb_lock_waits表则由performance_schema.data_lock_waits表代替。
三张表具体信息:
其中比较常用的一些列:
- trx_id:InnoDB存储引擎内部唯一的事物ID
- trx_status:当前事务的状态
- trx_status:事务的开始时间
- trx_requested_lock_id:等待事务的锁ID
- trx_wait_started:事务等待的开始时间
- trx_weight:事务的权重,反应一个事务修改和锁定的行数,当发现死锁需要回滚时,权重越小的值被回滚
- trx_mysql_thread_id:MySQL中的进程ID,与show processlist中的ID值相对应
- trx_query:事务运行的SQL语句
综上大体可以清楚的找到等待的事务即没有获取锁的事务,进一步调整业务逻辑代码。
一些建议:
1、可以结合update语句,调整索引,让update能唯一定位到数据行,尽量退化到行锁粒度;
2、相关查询语句增加索引,减少事物整体耗时;
3、避免长事物、可以降低@Transactional的粒度;
4、减少批处理数据量,规范业务逻辑流程,考虑异常事务回滚等问题;


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











