







3.1 NumPy
3.1.1 NumPy简介
1. 简要介绍
NumPy,即Numeric Python;提供丰富的数学函数、强大的多维数组对象以及优异的运算性能。
- N维数组结构
- 精密复杂的函数
- 可集成到C/C++和Fortran代码的工具
- 线性代数、傅里叶变换以及随机数能力
2.数组运用举例
- 音频文件存储
音频文件可以存储为一维数组audio[],取第一秒的数据audio[:44100],下图中的数组元素表示该段的音频数据。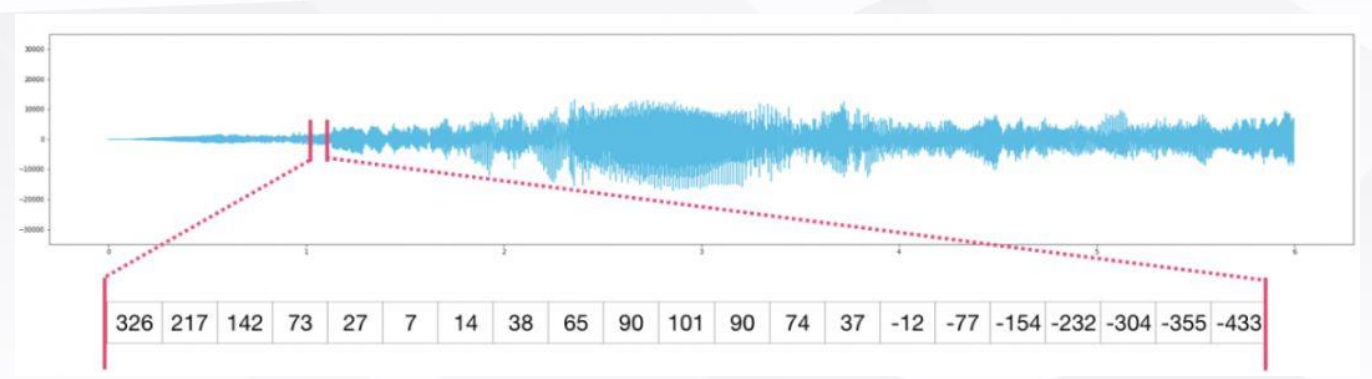
- 图像存储
图像可以看成是若干个像素组成的矩阵,大小为其宽度和高度。
- 黑白图像/灰度图像
每个像素可以由单个数字表示,image[:10,:10]截取下图中的一部分图片表示如下:
- 彩色图像
每个像素点由三个数字表示红绿蓝三种颜色的数据,大小为高宽3,数组为三维数组
3.1.2 NumPy的下载与安装
- NumPy 包的下载地址:https://pypi.python.org/pypi/numpy
- 使用pip工具直接下载NumPy包
pip install numpy

anaconda自带安装了numpy
- 导入NumPy
import numpy
import numpy as np
from numpy import *
from numpy import array, sin
3.1.3 Numpy数组介绍及运算
numpy数组是一个多维数组对象 ,称为ndarray;
numpy.array和标准Python库类array.array不一样,标准库中的只处理一维数组和提供少量功能。
1.numpy.array组成部分
- 实际的数据,下标从0开始,同一个numpy数组的所有元素类型必须相同
- 描述这些数据的元数据
2.列表和numpy数组对比
元素类型
- 列表list:元素可以为多种类型,a = [1,8.0,“abc”,obj]
- numpy数组ndarray:元素必须为同一种类型,如a = numpy.array([0,1,2,3,4]),数据类型均为整型
元素运算
Numpy优势
- 矢量化,代码中没有显示的索引和循环操作
- 广播,对每个元素进行操作
import numpy as np
# 如数组相乘比较
# numpy数组ndarray
a = np.array([0, 1, 2, 3, 4])
b = np.array([5, 6, 7, 8, 9])
c1 = a * b
print(c1)
# 列表list
a = [0, 1, 2, 3, 4]
b = [5, 6, 7, 8, 9]
c2 = list()
for i in range(len(a)):
c2.append(a[i] * b[i])
print(c2)
3.numpy支持的数据类型
bool,int,float,complex
| 名称 | 描述 | 名称 | 描述 |
|---|---|---|---|
| bool | 用一个字节存储的布尔类型 (True或False) | uint32 | 无符号整数,0至2 ** 32 -1 |
| int | 由所在平台决定其大小的整数 (一般为int32或int64) | uint64 | 无符号整数,0至2**63-1 |
| int8 | 一个字节大小,-128 至 127 | float16 | 半精度浮点数:16位,正负号1位, 指数5位,精度10位 |
| int16 | 整数,-32768 至 32767 | float32 | 单精度浮点数:32位,正负号1位, 指数8位,精度23位 |
| int32 | 整数, -2 ** 31 至 2 ** 32 -1 | float64或float | 双精度浮点数:64位,正负号1位, 指数11位,精度52位 |
| int64 | 整数,-263至263-1 | complex64 | 复数,分别用两个32位浮点数表示实部和虚部 |
| uint8 | 无符号整数,0至255 | complex128或complex | 复数,分别用两个64位浮点数表示 实部和虚部 |
| uint16 | 无符号整数, 0 至 65535 |
4. 创建Numpy数组
Python中创建数组的5中通用方法
- 通过其它Python结构创建(例如列表和元组)
- numpy数组本身的数组创建对象(例如arange,ones,zeros等)
- 从磁盘读取数组
- 使用字符串或缓冲区从原始字节创建数组
- 使用特殊的库函数(如随机函数random)
创建数组实例
array,arange,zeros,ones,full,eye,np.linspace
| 代码 | 结果 | 说明 |
|---|---|---|
| a = array([0,1,2,3,4]) | [0,1,2,3,4] | 创建一个一维数组,有5个元素,每个元素为整型 |
| a1 = arange(5) | [0,1,2,3,4] | |
| a2 = arange(0,6,2) | [0,2,4] | arange函数的三个参数分别为:起始数( 含),终止数(不含),步长 |
| b = array([(1.0,2.0,3.0),(4.0,5.0,6.0)]) | [[1.,2.,3.],[4.,5.,6.]] | 创建一个二维数组,2行3列,共有6个元 素,每个元素为浮点型64位 |
| c = array( [ [1,2,3], [4,5,6] ], dtype=complex ) | [[1.+0.j, 2.+0.j, 3.+0.j], [4.+0.j, 5.+0.j, 6.+0.j]] | 二维数组,2行3列,效果与上 面一种方法类似,但数据类型为 complex128 |
| d = zeros((2,3)) | [[0. 0. 0.], [0. 0. 0.]] | 创建一个2行3列的二维数组,值全部为0 |
| e = ones((1,5)) | [[1. 1. 1. 1. 1.]] | 创建一个1行5列的一维数组,值全为1 |
| f = full((2,3,4),8) | [[[8 8 8 8], [8 8 8 8], [8 8 8 8]] [[8 8 8 8], [8 8 8 8], [8 8 8 8]]] | 创建一个元素全是8的三维数组 |
| g = eye(3,3) | [[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]] | 创建3行3列的二维数组,对角线为1,其 它元素均为0 |
| h = random.random((2,3)) | [[0.98772846, 0.53233087, 0.81990949], [0.45654177, 0.25143958, 0.45555412]] | 创建2行3列的二维数组,元素值为随机数 |
| i = np.arange(3) i.repeat(2) | [0,1,2] [0,0,1,1,2,2] | 单个元素重复 |
| j = np.arange(3) np.tile(j, 2) np.tile(j, (2,3)) | [0,1,2] [0,1,2,0,1,2] [[0,1,2,0,1,2,0,1,2], [0,1,2,0,1,2,0,1,2]] | 数组整理重复 |
| k1 = np.linspace(0, 5, 5) k1 = np.linspace(0, 5, 5, endpoint=False) | [0. , 1.25, 2.5 , 3.75, 5. ] [0., 1., 2., 3., 4.] | 在指定的间隔内返回均匀间隔的数字, 形成一个等差数列 |
numpy数组的属性
NumPy支持多维数组,每个维度(dimensions)也称为轴 (axes)。维度的数量称为秩(rank),一维数组的秩为1, 二维数组的秩为2,以此类推。
查看属性:数组名.属性名”或者“属性名(数组名)”,例如:a.ndim或者ndim(a)
a = array([0,1,2,3,4])
b = array( [ (1.0, 2.0, 3.0), (4.0, 5.0, 6.0) ] )
c = array( [ [1,2,3], [4,5,6] ], dtype=complex )
| 属性名 | 描述 | 数组a | 数组b | 数组c |
|---|---|---|---|---|
| ndim | 维数,等于秩 | 1 | 2 | 2 |
| shape | 每个维度上的长度 | 5 | 2,3 | 2,3 |
| size | 数组元素的总个数 | 5 | 6 | 6 |
| dtype | 表示数组中元素类型的对象 | int32 | float64 | complex128 |
| itemsize | 数组中每个元素的大小(以字节为单位) | 4 | 8 | 16 |
numpy数组的输出,索引
- 一维数组被打印成行,二维数组被打印为矩阵,三维数组被打印为矩阵列表
- 如果一个数组太大了,无法完整输出,打印时NumPy将自动省略中间部分而只打印角落的部分
from numpy import *
a = arange(0, 100, 10)
print(a) # [ 0 10 20 30 40 50 60 70 80 90]
a[2] # 20 a数组的第2个元素
a[2:5] # [20,30,40] a数组的第2个到第4个元素
indices = [1, 6, -2] # 通过索引获取数组中的部分数据
print(a[indices]) # [10 60 80] 取a数组的正数第1和第6个,以及倒数第2个元素
mask = array([True, False, True, False, False, True, False, True, False, False])
print(a[mask]) # [0 20 50 70] 通过布尔值来索引,只输出布尔值为真的对应数据
b = array([(1.0, 2.0, 3.0), (4.0, 5.0, 6.0)])
c = array([[1, 2, 3], [4, 5, 6]], dtype=complex)
# 二维数组的第一个元素11所在的位置是第0行第0列
d = array([[11, 12, 13, 14, 15],
[21, 22, 23, 24, 25],
[31, 32, 33, 34, 35],
[41, 42, 43, 44, 45],
[51, 52, 53, 54, 55]])
print(a, b, c, sep='\n')
print(d[0, 1:4]) # 第0行的[1,4)列输出
print(d[1:4, 0]) # 第[1,4)行,第0列输出
print(d[::2]) # 所有行中,步长为2;列为所有列
print(d[::2, ::2]) # 所有行中,步长为2;列为所有列中,步长为2
print(d[:, 1]) # 所有行,列为第一列
- 数组切片结果

5.numpy数组的运算
运算示例1
a = arange(10) #[0,1,2,3,4,5,6,7,8,9]
b=arange(0,100,10) # [0,10,20,30,40,50,60,70,80,90]
| 代码 | 结果 | 说明 |
|---|---|---|
| a.sum() | 45 | 数组求和 |
| a.min() | 0 | 数组的最小值 |
| a.max() | 9 | 数组的最大值 |
| a.cumsum() | [0,1,3,6,10,15,21,28,36,45] | 输出结果中每一个元素的值等于数组前n个元素的累加和 |
| b[b>50] | [60,70,80,90] | 只取出大于50的元素 |
| b[b%3 == 0] | [0,30,60,90] | 只取出B数组中能整除3的元素 |
运算示例2
a = array( [10,20,30,40] )
b = arange( 4 ) # [0,1,2,3]
| 代码 | 结果 | 说明 |
|---|---|---|
| a+b | [10,21,32,43] | 两个数组逐元素相加 |
| a-b | [10,19,28,37] | 两个数组逐元素相减 |
| a*b | [0,20,60,120] | 两个数组逐元素相乘 |
| a/b | [inf,20.,15.,13.33333] | 两个数组逐元素相除,第一个元素为除0的结果 |
| b**2 | [0,1,4,9] | 数组b元素的乘方 |
| 10*sin(a) | [-5.44021111, 9.12945251, -9.88031624, 7.4511316 ] | 对a的元素求sin后再乘以10 |
| a<21 | [Ture,Ture,False,False] | 判断a的元素值是否小于21,小于的显示为True, 不小于的显示为False |
| a.dot(b) | 200 | dot() 函数计算两个数组的点积,即向量乘法,相当于a1b1+a2b2+a3b3+a4b4,得到一个数值 |
统计特征计算
a = array([0,1,2,3,4])
| 函数名 | 描述 | 结果 |
|---|---|---|
| mean(a) | 算数平均值 | 2.0 |
| std(a) | 标准差 | 1.1412135623730951 |
| var(a) | 方差 | 2.0 |
| average(a,weight= [0,0.1,0.2,0.3,0.4]) | 加权平均值 | 3.0 |
| median([1,3,100]) | 中位数 | 3 |
5. numpy数组形状调整
形状调整指的是数组维度方面的变化
reshape函数
reshape后形成的新数组,和原数组共享同一段内存空间,并不会产生一个新的地址空间。如果对其中a、b、c中任何一个数组的元素进行修改,其它2个数组的内容也同时会发生变化。例如:b[0,0]=99,修改完毕后,a[0]和c[0,0,0,0]的值也会变成99。
from numpy import *
a = arange(16) # a是一个一维数组 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
b = a.reshape(4, 4) # b是一个二维数组
c = a.reshape(2, 2, 2, 2) # c是一个四维数组
print(a, b, c, sep='\n')
flatten函数
使用flatten函数可以将高维数组转化为向量,和reshape不同的是, flatten函数会生成一份新的复制。
from numpy import *
a = array([[n + m * 10 for n in range(3) for m in range(4)]])
# n [0,2];m [0,3]
# a是一个3行4列的二维数组,[[ 0 10 20 30 1 11 21 31 2 12 22 32]]
b = a.flatten() # b是一个向量,[ 0 10 20 30 1 11 21 31 2 12 22 32]
print(b)
b[0:4] = -1 # 修改b的前4个元素值
print(a)
print(b)
6. numpy常用函数汇总
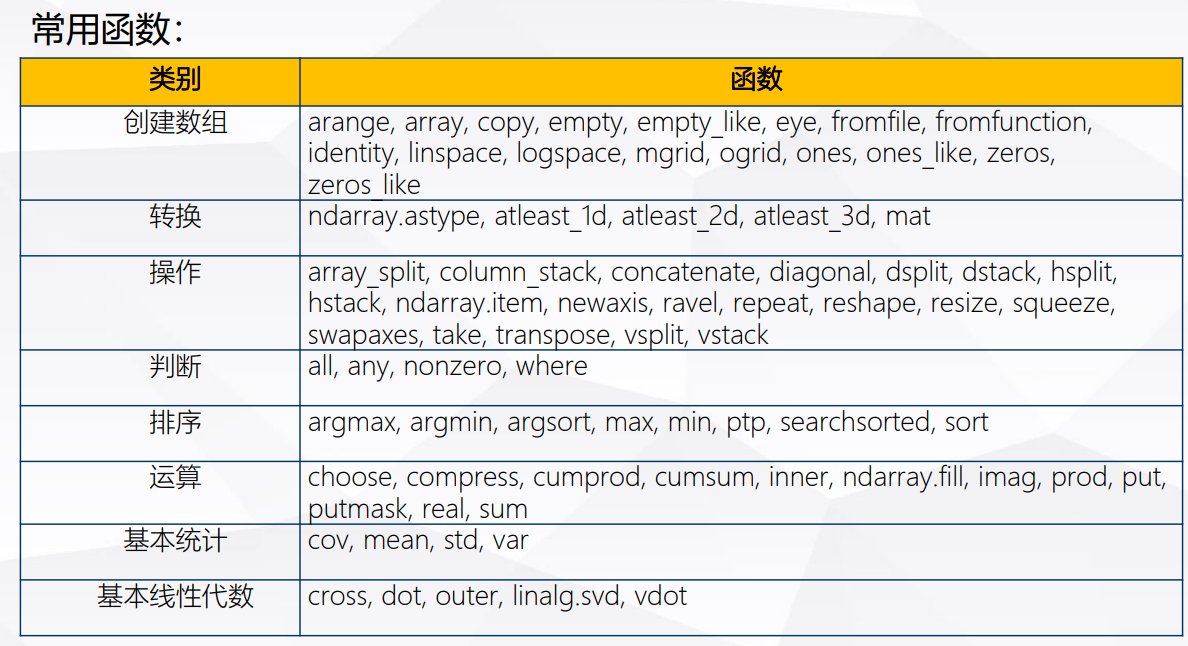















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









