






我的公众号的后台接入了 AI 机器人,每天都有人在后台私信查找 OCR 相关的开源项目。
今天一网打尽,直接转发、收藏这篇文章就好了,指定全网找不到更全的了。盘点了 10 个在 GitHub 上广受欢迎和好评的 OCR 开源项目,按照 Star 数量排序!
如果密密麻麻的文字看起来麻烦,每个工具介绍都标注出来最重点的部分,看起来省时省力。
解释一下:OCR 就是一种能够将图像中的文字信息转换为可编辑和可处理的文本数据的技术,简单来说就是识别提取图片上的文字。
01
端到端 OCR 模型:GOT-OCR 2.0
这是一款开源的端到端多模态 OCR 模型,模型大小仅 1.43 GB。除了能识别和提取文本,还能处理数学公式、分子式、图表、乐谱、几何图形等多种内容,极大地拓宽了 OCR 技术的应用范围。
目前在 GitHub 上已经获得了 7.2K 的 Star!

开源地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.002
开源多模态模型:兼容文字识别
InternVL 是由 OpenGVLab 团队开发的开源多模态大模型,旨在提供接近 GPT-4V 和 Gemini Pro 等商业模型性能的替代方案,目前已经获得了 7.2K 的 Star。
这个是视觉大模型,它能兼容的场景更广泛,比如图片理解,理论上不算 OCR 领域的垂直模型,不过这种视觉大模型能够向下兼容 OCR 提取文字场景的,所以我就算进来了。
当然开源的视觉大模型有很多,我就不逐个梳理了,先拿这个做案例。
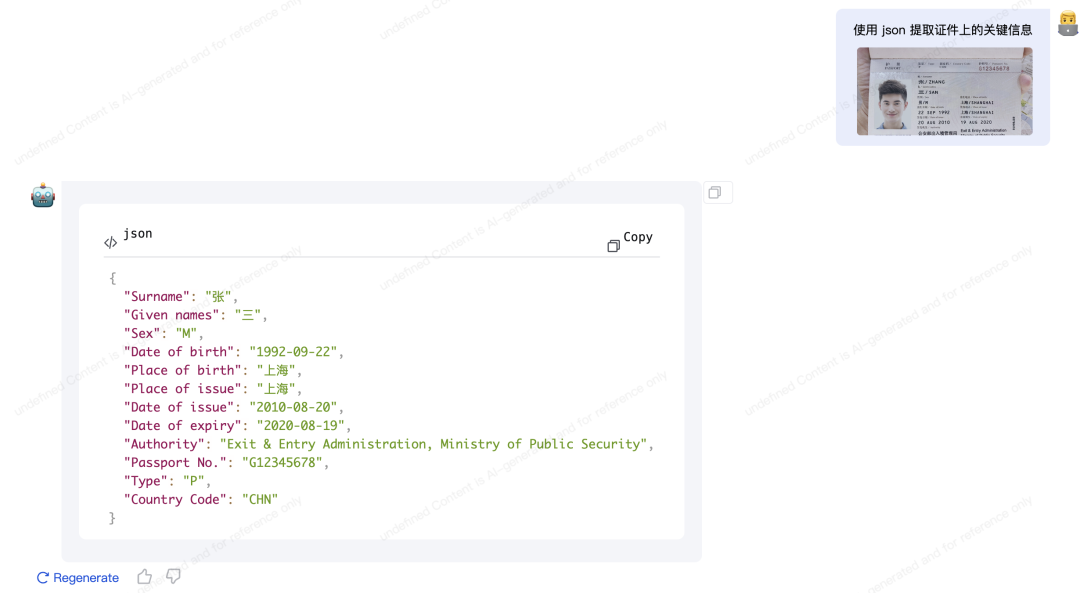
开源地址:https://github.com/OpenGVLab/InternVL03
PDF 转成结构化文本:olmOCR
olmOCR 是由 AllenAI 开发的一款专注于 PDF 文档线性化处理的工具包,将复杂布局的 PDF 转换为适合大语言模型(LLM)训练的结构化文本。目前已经获得了 9.8K 的 Star!
其核心目标是通过高效处理 PDF 的图文混排、多栏布局等问题,生成连贯的文本数据,提升 LLM 在真实场景中的文档理解能力。
要求配置是最新的 NVIDIA GPU(在 RTX 4090、L40S、A100、H100 上测试),至少有 20 GB 的 GPU RAM,30GB 可用磁盘空间

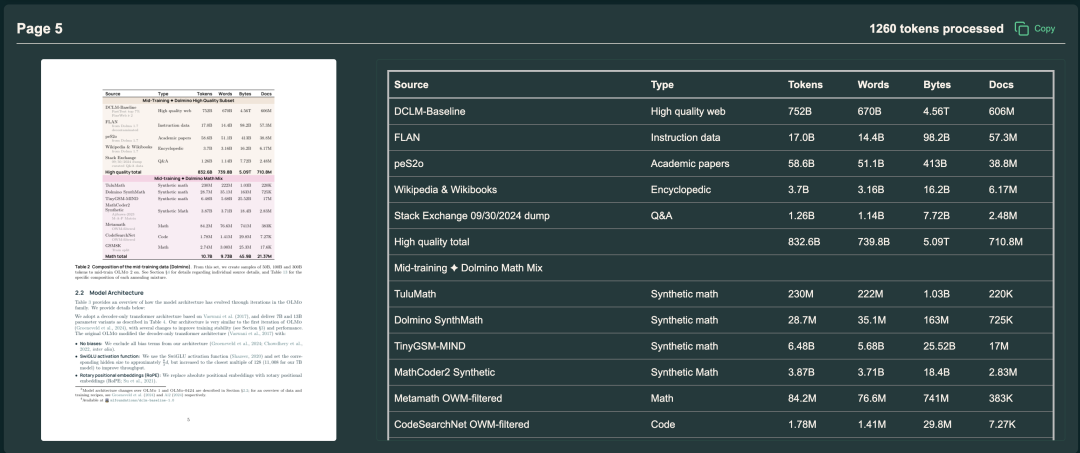
开源地址:https://github.com/allenai/olmocr在线演示:https://olmocr.allenai.org/04
识别文字转成结构化文件:Zerox
Zerox 是由 Omni-AI 团队开发的一款 AI 驱动的提取文字工具,可以把 PDF、图片、Docx 等格式的文档转换为结构化的 Markdown 文件。目前获得了 10.3K 的 Star!
底层实现:底层基于视觉模型(如 GPT-4o-mini)实现 OCR 并直接生成结构化内容。
无需训练:与传统 OCR 工具不同,Zerox 无需提前训练模型即可处理复杂布局。
格式结构:可识别学术论文的分栏排版、技术文档中的代码块、合同表格、试卷公式等,保留逻辑结构并生成整洁的 Markdown。
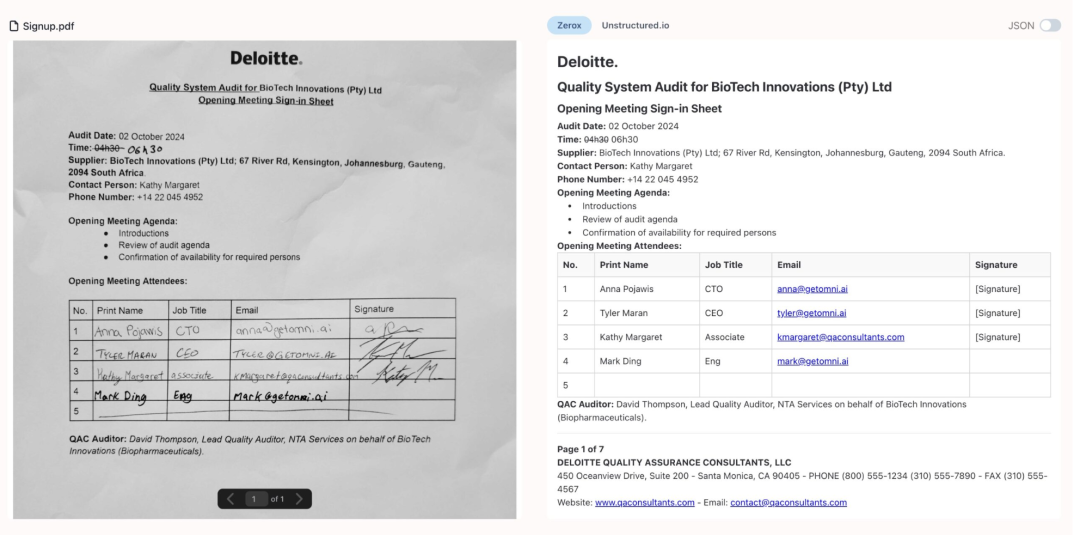
开源地址:https://github.com/getomni-ai/zerox体验地址:https://getomni.ai/ocr-demo05
行级文本检测、布局分析:Surya
Surya 专注于多语言文本及复杂文档结构的识别,尤其以表格识别能力见长。目前在 GitHub 上已经获得了 16.8K 的 Star!
关键词:行级文本检测、布局分析(表格、图像、标题等检测)、阅读顺序检测、表格识别(检测行/列)、LaTeX OCR
① 多语言支持:支持90+ 种语言,涵盖中文、日语、阿拉伯语等复杂文字,以及英语、西班牙语等主流语言,适用于全球化场景的文档处理。
② 表格识别优化:能精准识别表格的行、列、单元格结构,包括旋转或复杂布局的表格,性能优于当前主流开源模型(如 Table Transformer)。
③ 复杂文档解析:可检测文档中的标题、图片、段落等元素,并智能判断阅读顺序,避免输出内容混乱。


④ 高效处理能力:支持 CPU/GPU 运行,通过批量处理和图像预处理优化(如去噪、灰度化),显著提升识别速度,适用于企业级文档数字化需求。
开源地址:https://github.com/VikParuchuri/surya06
图片 PDF 变可复制、搜索
这个开源工具,专为扫描版 PDF 文件(就是 PDF 中全是图片,图片中的文字不可复制的那种)添加可搜索、可复制的文本层。
目前在 GitHub 已经获得了 20.7K 的 Star!

使用的是 Tesseract OCR 引擎,支持 100 多种语言,能保留原始图像质量并优化文件体积,同时生成符合长期存储标准的 PDF 格式。
① 精准识别:打开图片型 PDF 的时候,会发现图片上的文字是没办法复制和搜索的。将 OCR 文本层嵌入图片下方,支持高精度复制和搜索。

② 批量处理:利用多核 CPU 加速,可高效处理上千页文档。
③ 图像优化:自动校正倾斜页面、旋转错误页面,提升识别率。
④ 跨平台支持:安装便捷,兼容 Linux、Windows、macOS 和 Docker
开源地址:https://github.com/ocrmypdf/OCRmyPDF 接入文档:https://ocrmypdf.readthedocs.io/en/latest/07
PDF 转换为 Markdown、JSON 或 HTML
Marker 是由 Vik Paruchuri 开发的高效文档转换工具,可以将 PDF、图像、Office 文档及 EPUB 等格式快速转换为 Markdown、JSON 或 HTML。
目前在 GitHub 上已经获得了 22.8K 的 Star。
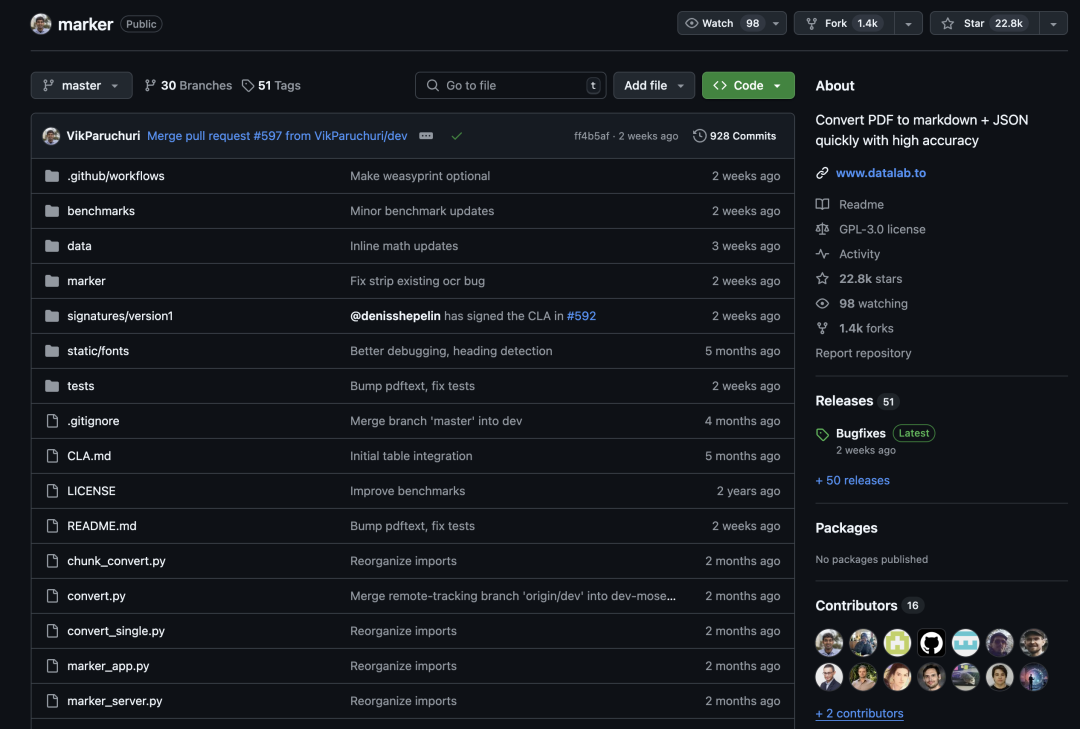
优势在于高精度解析复杂内容(如表格、数学公式、代码块)和出色的处理速度,支持 GPU 加速,性能优于同类云服务(如 Llamaparse、Mathpix)。
可以调用大语言模型(如 Gemini、Ollama)优化结果,例如跨页表格合并、公式格式化、表单数据提取。
开源地址:https://github.com/vikParuchuri/marker08
EasyOCR
EasyOCR 是由 JaidedAI 开发的开源 OCR 工具库,输入图片,返回提取出来的文字、对应位置坐标、置信度,目前在 GitHub 上获得了 26K 的 Star。
支持 80+ 语言和多种文字系统(如中文、拉丁文、阿拉伯文),提供即用型文本识别功能。
基于 PyTorch 深度学习框架,支持图片/字节流/URL等多种输入形式,通过简洁 API 输出文本内容、位置及置信度。
其特点包括多语言混合识别、CPU/GPU 兼容和预训练模型快速部署,适用于多语言文档、自然场景文字(如路牌/车牌)等 OCR 场景,兼顾开发者友好性和工业级应用需求。



开源地址:https://github.com/JaidedAI/EasyOCRDemo 地址:https://www.jaided.ai/documentai/demo09
安装即用的离线 OCR 文字识别软件
这款免费、开源、离线的 OCR 文字识别软件,支持 Windows 7+ x64 和 Linux x64 系统,无需联网,下载即可本地运行。目前已经获得了 30.8K 的 Star 。
关键词:本地软件解压即用,离线运行;截图OCR;批量OCR ;
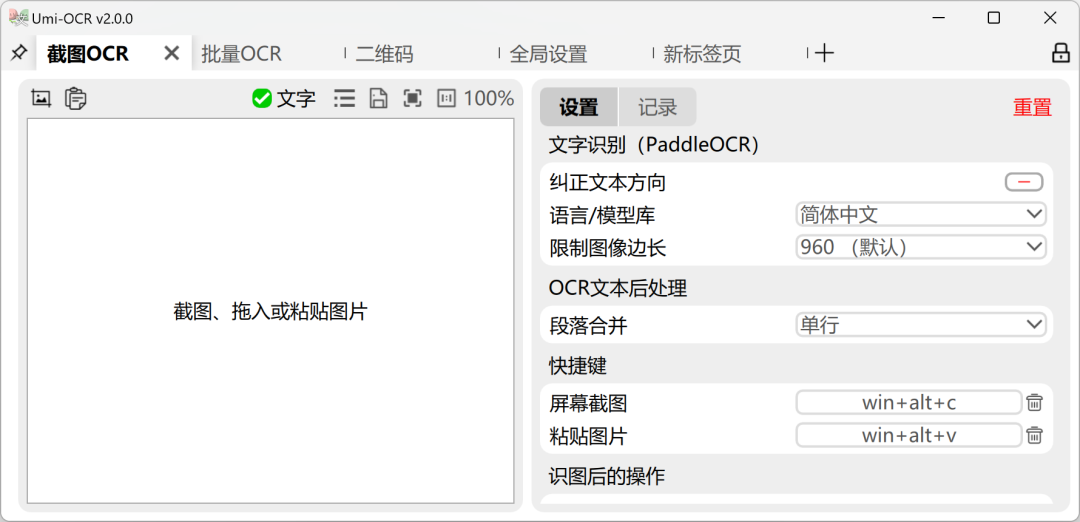
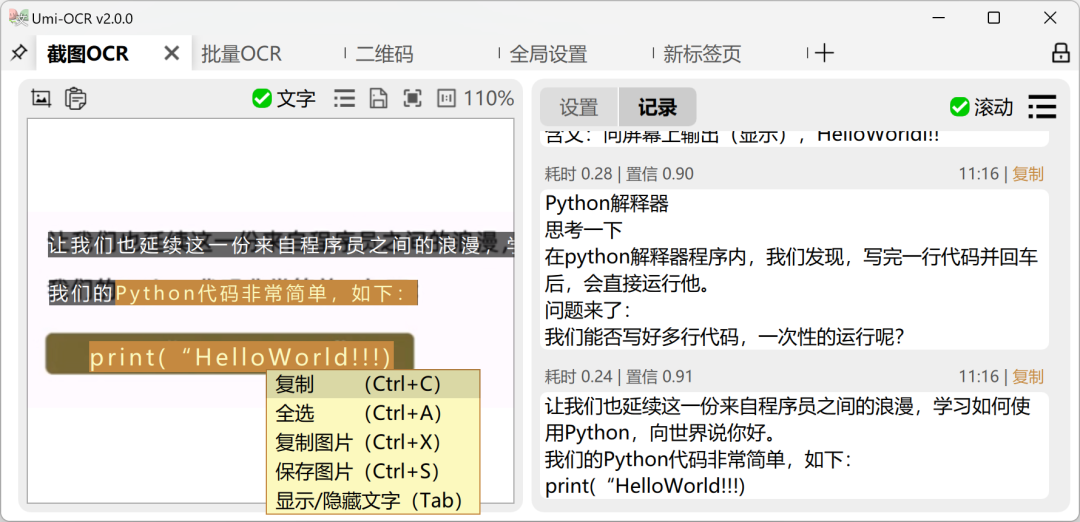
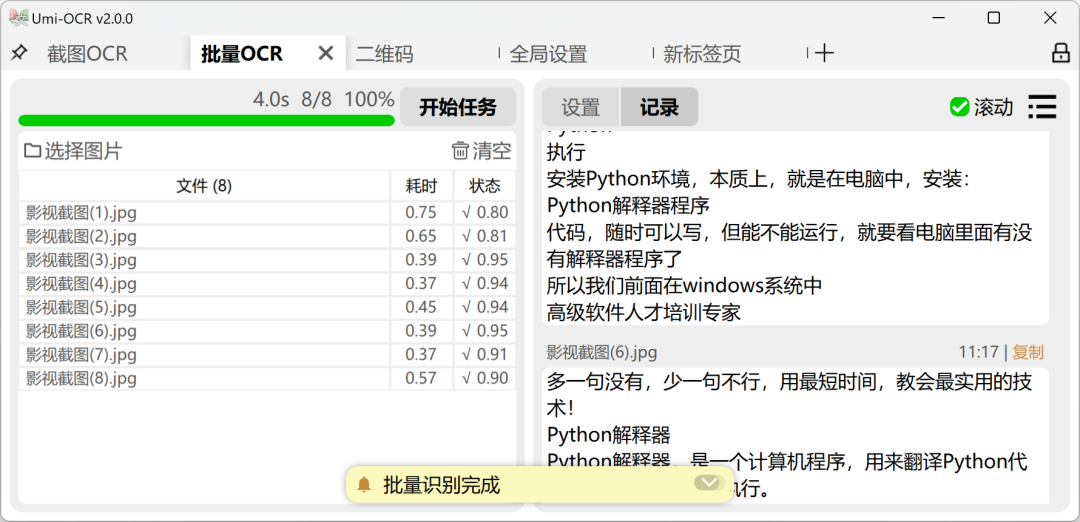
开源地址:https://github.com/hiroi-sora/Umi-OCR10
OCR 远古巨神:Tesseract
Tesseract 是一个功能强大且广泛应用的开源光学字符识别(OCR)引擎,在 GitHub 上已经获得了 65.3K 的 Star 。
能够将图像中的文字转换为可编辑的文本,1985 年至 1994 年间由惠普实验室开发, 1996 年后被移植到 Windows系统, 2005 年惠普将其开源。
并最终由 Google 赞助,是知名度比较高的开源 OCR 系统之一。
官方介绍使用先进的深度学习技术(如卷积神经网络)来进行字符识别,精度较高,尤其在处理质量较好的扫描图像时表现优异。支持超过 100 种语言的文本识别,方便开发者处理不同语言的文本识别任务。
除此之外还有一个 JavaScript 版本的Tesseract OCR:Tesseract.js,但是逛逛实际测试下来,发现 JS 版本中文效果不咋滴。
开源地址:https://github.com/tesseract-ocr/tesseract开源地址:https://github.com/naptha/tesseract.js
11
点击下方卡片,关注我
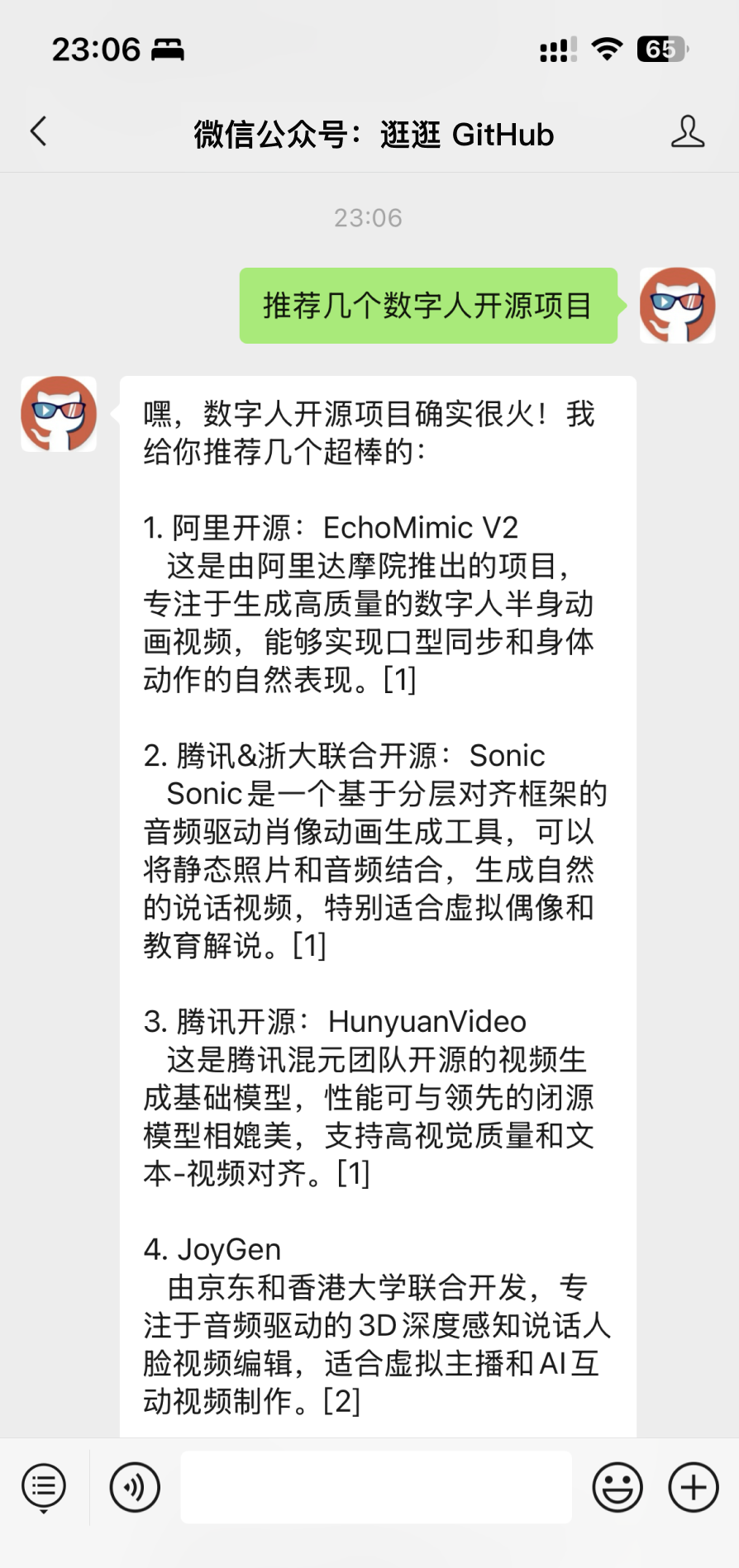
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:

















 5434
5434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









