







Adtributor: Revenue Debugging in Advertising Systems
【核心】最早系统地提出利用根因分析对广告系统收入指标进行溯因, 其基于一个较强的假设:根因的指标来自于单个指标。
【论文地址】:https://www.usenix.org/system/files/conference/nsdi14/nsdi14-paper-bhagwan.pdf
论文解析
背景
- 在互联网Web服务的智能运维(AIOps)过程中,首要需求通常是对监控的各种关键性能指标(KPI)进行实时异常检测,然后需要对检测出的异常指标进行异常定位和根因分析(RCA, root cause analysis),以便尽快做进一步的修复止损等操作。
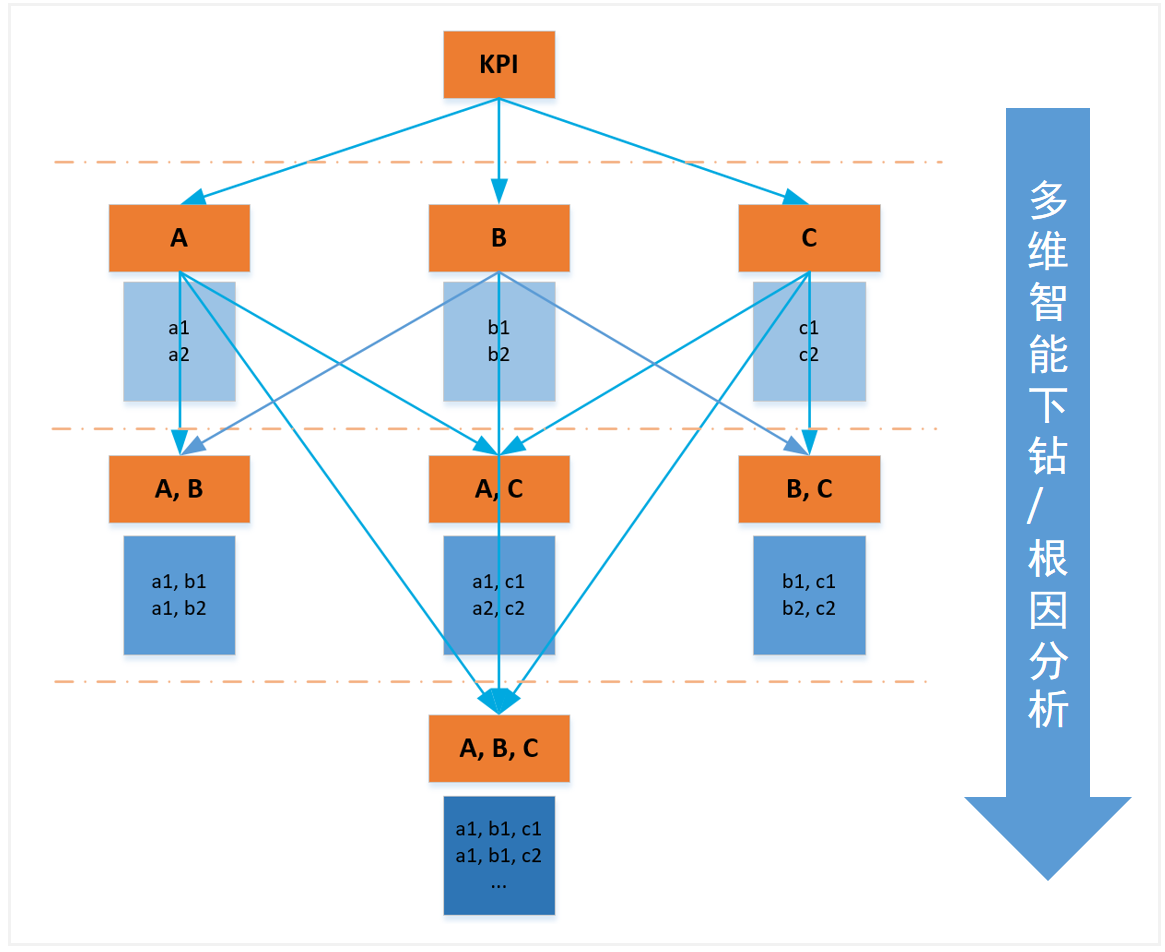
- 通常一个KPI的异常是多个维度异常共同导致的结果,反过来说KPI异常会反映在各个维度下面。例如对于网页访问量(Total_PV)涉及多个维度:用户位置、网络运营商、数据中心等;各维度对应一系列可能情况(或者元素),用户位置:北京,上海,广州等;网络运营商:移动,联通,电信等;数据中心:DC1,DC2等。当Total_PV发生异常时,最可能的异常原因可以表示为不同维度的元素集合,如{北京、上海},或{北京移动,广州电信,DC1}等。
- 指标和维度的示意如下图所示,其中 A, B, C 代表不同维度,a1, b1, a1b1 表示对应维度下的元素指标。对于多维KPI,异常定位和根因分析的目的就是在检测到KPI异常之后,从所有维度中挖掘出最可能是异常发生根本原因的元素,因此根因分析也叫做智能下钻。
主要内容
《Adtributor: Revenue Debugging in Advertising Systems》这篇论文介绍了一种名为Adtributor的广告系统收入调试框架。该框架旨在帮助广告系统识别和解决可能导致收入损失的问题。以下是对论文内容的概括:
- 问题陈述:广告系统在实际运行中可能出现各种问题,例如错误配置、竞价策略问题、广告位问题等,这些问题可能导致广告系统的收入下降。因此,需要一种方法来帮助定位和解决这些问题。
- Adtributor框架概述:Adtributor是一个用于收入调试的框架,通过结合观察、干预和反馈循环来提供调试功能。它利用在线实验和自动化工具来快速识别和定位广告系统中的问题。
- 观察:Adtributor通过监控广告系统的各个组件以及广告投放的数据,收集关键指标和性能数据,以了解系统的整体运行状况。
- 干预:Adtributor通过在线实验对广告系统进行干预,通过调整配置、策略或其他参数来观察系统性能的变化,并识别潜在的问题。
- 反馈:Adtributor根据干预的结果和观察到的数据,提供反馈和建议,帮助广告系统操作员定位和解决问题。这些反馈可以是警报、错误提示或其他形式的信息。
- 实验评估:论文通过在真实的广告系统上进行实验评估,展示了Adtributor框架的有效性和实用性。实验结果表明,Adtributor能够准确地识别和调试导致收入损失的问题,并提供了有价值的解决方案。
综上所述,《Adtributor: Revenue Debugging in Advertising Systems》论文提出了Adtributor框架,该框架通过观察、干预和反馈循环来帮助广告系统定位和解决导致收入损失的问题。该框架在真实环境中进行了评估,并展示了其有效性和实用性。
论文的模型
Adtributor: Revenue Debugging in Advertising Systems》这篇论文主要介绍了Adtributor框架,它是一个用于广告系统收入调试的框架,并没有涉及特定的模型。因此,该论文中没有提出特定的模型。
- Adtributor框架是基于观察、干预和反馈循环的方法来进行收入调试的。它依赖于实时监测广告系统的各个组件和广告投放数据,并结合在线实验和自动化工具来识别和解决可能导致收入损失的问题。
- 虽然没有具体提到模型,但Adtributor框架可以使用各种数据分析和机器学习技术来处理广告系统中的数据,例如数据挖掘、异常检测、特征工程等。具体的数据处理和分析方法可以根据实际情况选择和定制,以便更好地理解广告系统的运行状况并发现潜在的问题。
因此,该论文的重点在于提出了一个综合性的框架,通过观察、干预和反馈循环来进行广告系统收入调试,而不是特定的模型或算法。
论文的methodology
- 监测数据收集:通过监测广告系统的各个组件和广告投放数据,收集关键指标和性能数据。这些数据用于了解广告系统的整体运行状况和收入情况。
- 干预实验设计:基于收集到的监测数据,设计和进行干预实验。干预实验可以通过调整配置、策略或其他参数来改变广告系统的运行方式,以观察系统性能的变化。
- 数据分析和异常检测:对监测数据和干预实验的结果进行数据分析和异常检测。这包括使用数据挖掘、机器学习和统计方法来发现潜在的问题和异常情况,可能涉及特征工程、异常检测算法等。
- 问题定位和解决方案:基于数据分析和异常检测的结果,定位导致收入损失的问题。通过分析问题的根本原因,提出相应的解决方案和建议,帮助广告系统操作员解决问题并提高收入。
- 反馈和报告:根据分析结果和解决方案,向广告系统操作员提供反馈和报告。这可能包括生成警报、错误提示或其他形式的信息,以便操作员能够及时了解问题并采取相应的措施。
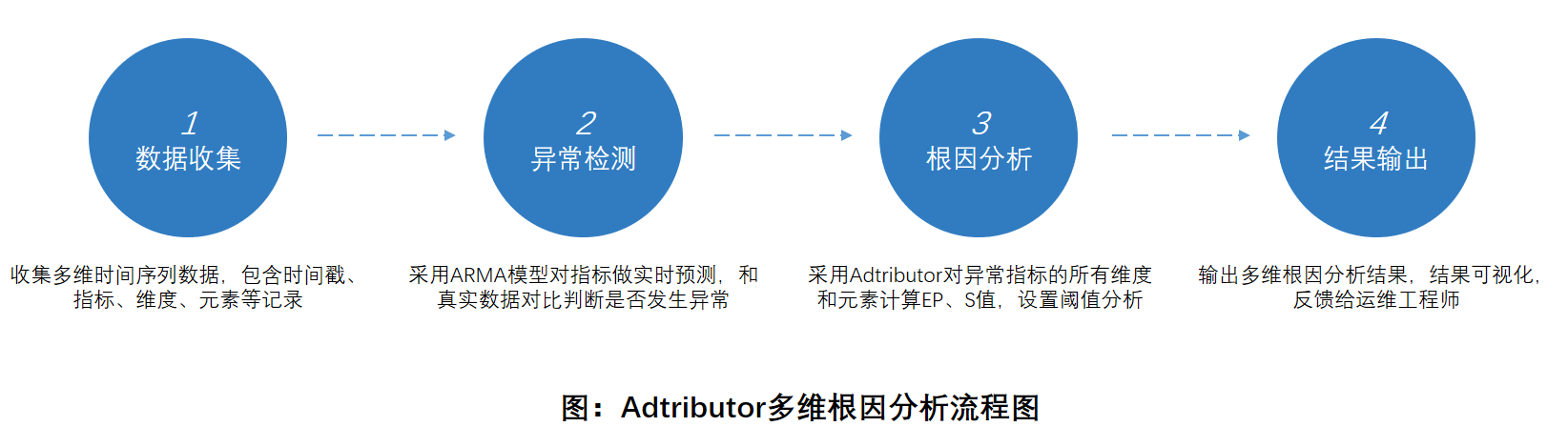
Adtributor多维根因分析流程如图所示,主要包括四个步骤:
- 步骤1数据收集。收集KPI的多维时间序列数据,对于缺失值、死值等进行初步预处理,提升数据质量。
- 步骤2异常检测。采用ARMA时间序列模型对KPI进行实时预测,将预测值F和真实值A对比,判断KPI是否发生异常;预测值F和真实值A将用于Adtributor根因分析。
- 步骤3根因分析。Adtributor对异常KPI的所有维度和元素计算EP值和S值,并与TEP、TEEP阈值比对分析,从而筛选和定位出异常根因。
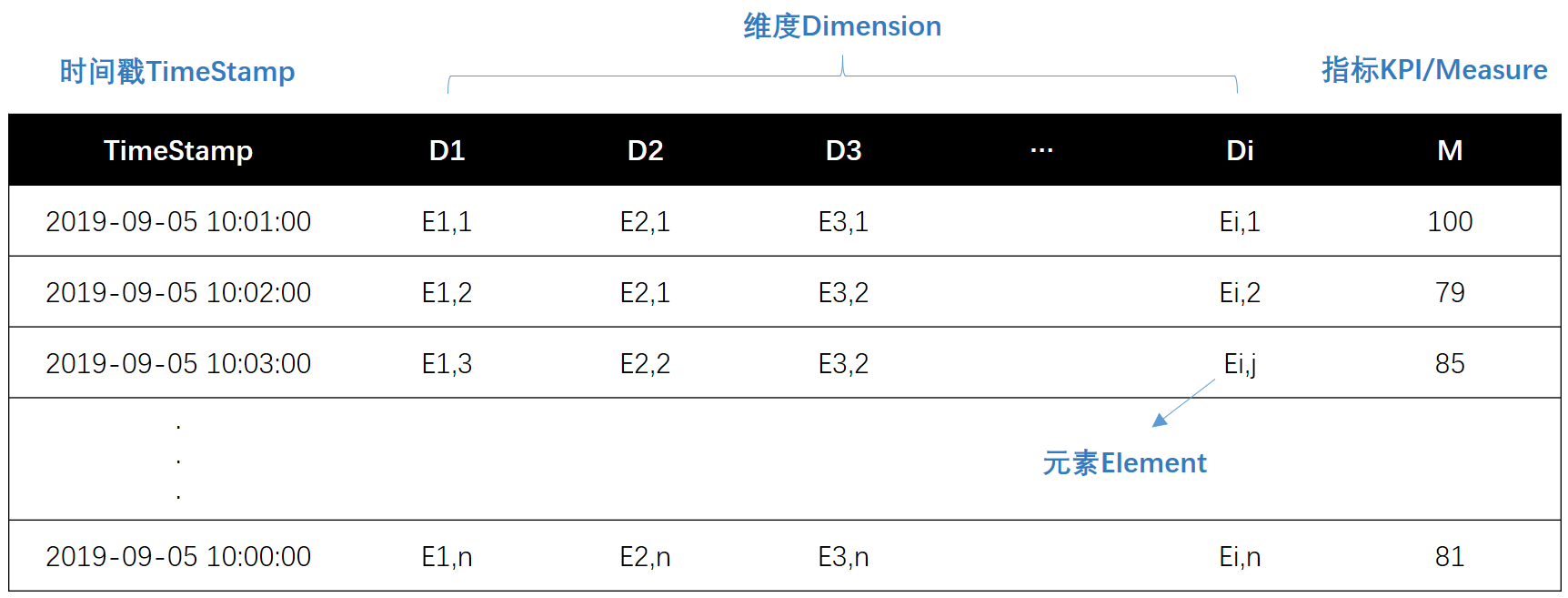
论文的数据和输入
多维时间序列数据,包含:时间戳TimeStamp、指标KPI、维度D、元素E。数据表结构如下:
从统计分析的角度来看, KPI可以分为两类:
- 量值KPI,具有可加性(additive),如成功数、访问总量;
- 率值KPI,量值KPI推导得到,亦称为推导性(derived, ratio)KPI,如点击率、成功率;
举例说明:例如用户位置维度下,北京、上海和广州的访问成功量分别为70、90和10,访问总量均为100,成功率分别为70%、90%、100%;三者的访问成功量相加得到用户位置维度的访问成功量为260,但三者的成功率不能直接相加得到用户位置维度的成功率为260%。因此对于量值KPI和率值KPI需要采用不同的方法进行根因分析。
输出/难点:
能够准确反映KPI发生异常根本原因的维度-元素集合即异常根因。异常根因需要尽可能满足多个条件,这也是根因分析的难点所在:
- 对于每一个维度,元素集合能够尽可能地解释KPI异常波动;
- 对于每一个维度,元素集合符合奥卡姆剃刀原则、形式上尽可能简洁;
- 在所有维度中,找出最意外的、真实情况与期望值相差最大的维度和元素。
论文翻译
摘要
广告 (ad) 收入在支持免费网站方面起着至关重要的作用。当收入急剧下降或增加时,广告系统运营商必须找到并修复根本原因(如果可行的话),例如,通过优化基础设施性能。这种收入调试类似于系统文献中的诊断和根本原因分析,但更为普遍。基础设施要素的故障只是一个潜在原因;许多其他维度(例如,广告商、设备类型)可能是潜在原因的来源。此外,随着收入一起跟踪的每次点击成本等派生指标使问题变得复杂。我们的论文首次系统地审视了收入调试。使用解释力、简洁性和惊喜的概念,我们提出了一种新的多维根本原因算法,用于广告系统的基本和派生度量,以确定最有可能受到指责的维度。此外,我们在名为 Adtributor 的工具中实施了归因算法和可视化界面,以帮助故障排除人员快速识别潜在原因。基于对超大型广告系统的多个案例研究和广泛的评估,我们表明 Adtributor 的准确率超过 95%,并有助于将故障排除时间缩短一个数量级。
1 简介
- 如今,许多免费网站都靠广告 (ads) 产生的收入来支持。网站广告可以分为两种类型,即搜索广告和展示广告。
- 对于搜索广告,最终用户会访问发布商网站(例如 bing.com)并输入查询短语。对查询的响应是可能包含一个或多个广告的搜索结果页面。如果用户点击其中一个广告,发布商就会获得收入。
- 在展示广告的情况下,最终用户可能会访问发布商网站,例如 cnn.com,她可能会在页面顶部或两侧看到广告。这些广告的展示为出版商赚取收入。
- 广告系统有助于每天生成和计算数百万个此类搜索和显示广告。除了上面提到的用户和发布商之外,还有另外两个与广告系统交互的关键组成部分。向用户显示的广告是各个广告商之间的广告拍卖的结果,这些广告商出价竞争以将他们的广告显示给用户。此外,还有各种欺诈运营商 [8] 试图篡夺广告收入的一小部分。
- 广告系统管理用户、发布商、广告商和欺诈运营商之间的交互。广告系统实施各种与广告相关的算法,这些算法在广告商之间运行实时广告拍卖,将获胜的广告返回给发布者,监控用户点击,检测并消除潜在的欺诈活动,计算每个显示或点击的广告的收入,向广告商收取适当的出价金额,并支付给发布商。广告系统的核心是一个大型分布式系统,由分布在多个数据中心的数千台服务器组成,这些服务器执行广告算法并管理广告的投放和计费。
- 本文的重点是调试广告系统。通常,只要感兴趣的度量被识别为异常(例如,收入或搜索次数急剧下降),广告系统监视器就会发出警报。
- 我们的目标是自动识别此异常的潜在根本原因。我们将我们的方法称为收入调试,即使它适用于广告系统运营商感兴趣的多种衡量标准,以承认收入指标的重要性。
- 在本文中,我们描述了一种**新的收入调试算法**,该算法分析广告系统记录的大量数据,并将异常的潜在根本原因范围缩小到广告系统的子组件,以便进一步调查人类故障排除者。
- 根本原因识别和诊断是系统中一个由来已久的问题。过去已经提出了各种性能根源工具 [1、2、3、10、14、15]。但所有这些解决方案都专注于性能/故障调试。在这里,我们解决了一个类似但更普遍的问题:广告系统中的诊断。虽然基础设施系统组件的性能/故障可能是异常测量的一个可能根本原因,但可能存在依赖于与广告系统交互的其他组件的各种其他根本原因。考虑以下示例。
- **Papal Electio**教皇选举:我们注意到教皇选举导致收入下降,因为许多搜索是针对非货币化查询词进行的,例如教皇或教皇选举,广告商通常不会出价。显示的广告总数下降导致收入异常下降。虽然将根本原因确定为教皇选举不可操作,但确定根本原因仍然很重要,因为它消除了可采取行动的根本原因,如下例所示。
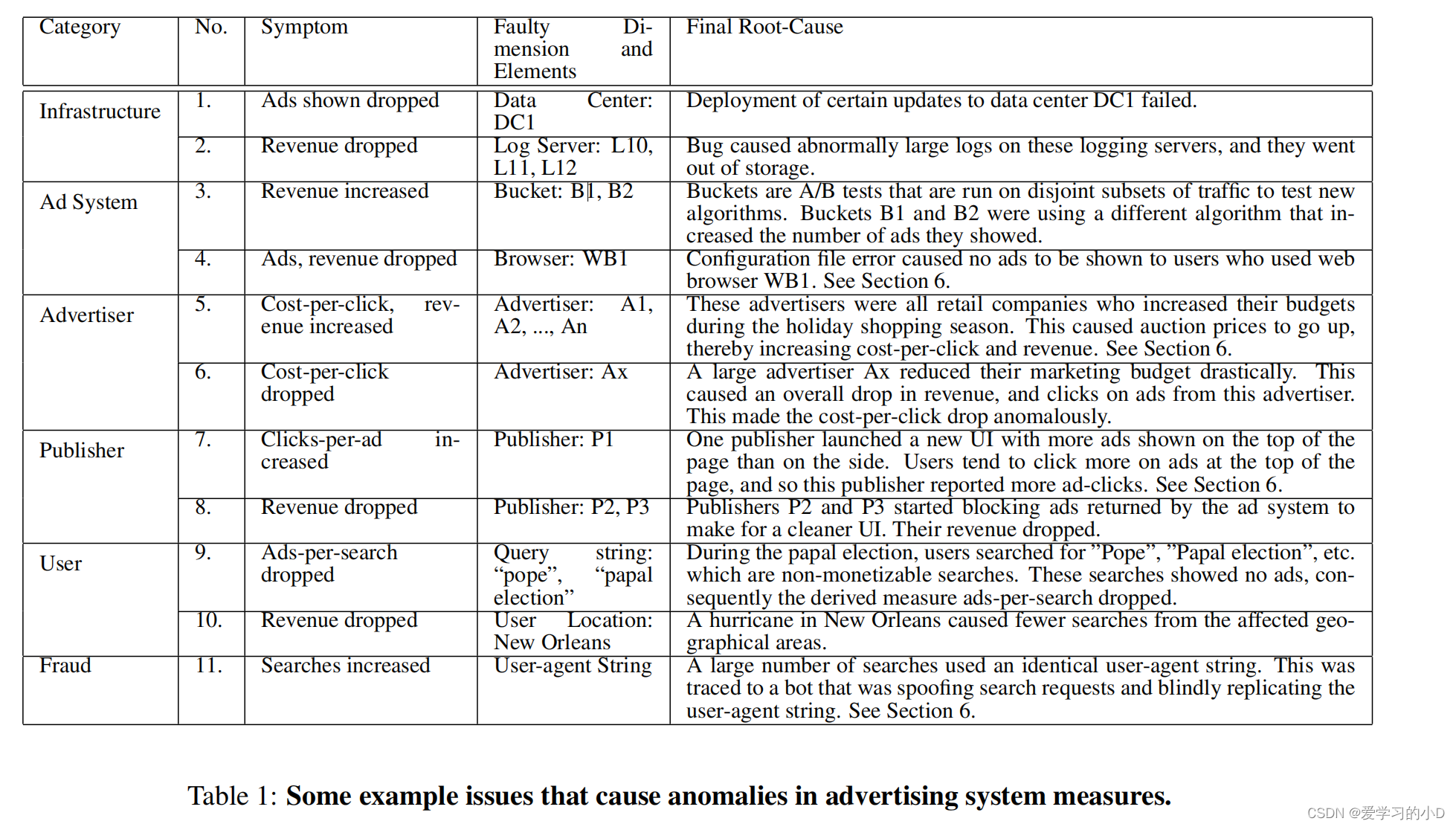
- Browser Ad Failure:我们发现收入下降是由于更新配置文件时的手动错误造成的,该配置文件具有在某些浏览器版本上不显示广告的副作用。在这种情况下,快速识别有助于纠正配置错误,从而恢复广告收入。表 1 中描述了一组更广泛的示例,并在第 2.1 节中进行了讨论。
- 广告系统调试的第一个挑战是庞大的规模。每天有数亿次搜索和点击;在搜索或点击级别执行诊断是不可扩展的(想象一下运行 Mag pie [3] 或通过数百个系统组件为每次点击跟踪一串系统调用)。因此,出于可扩展性原因,广告系统调试对各种措施的聚合进行操作。这些措施通常是在特定时间间隔内聚合的计数器(例如,过去 1 小时内产生的收入)。根本原因识别只能由这些聚合计数器的异常行为触发。与典型系统故障排除相比,
- 广告系统的第二个显着特征是存在多个维度,并且需要首先隔离解释异常的维度。收入等指标可以按照广告商、浏览器或数据中心等不同维度进行细分或预测。例如,在示例 2 中,如果按浏览器维度预测收入,则可以观察到某些浏览器版本并未产生其“典型”收入份额。然而,如果相同的收入被广告商维度分割,收入的分配可能不会发生重大变化。
- 典型的系统根本原因算法,如 SCORE [11] 使用简洁性(奥卡姆剃刀)和解释力(根本原因是否解释了变化?)作为优化的主要参数,并且不必考虑多个维度。为了隔离晚期异常维度,我们引入了惊喜的概念,通过量化每个维度上度量值分布的变化来捕获。例如,在示例 2 中,浏览器维度的收入分布变化比广告商维度的收入分布变化更令人惊讶。因此,我们在本文中的第一个贡献是第 3 节中描述的根本原因算法,该算法除了简洁和解释力外,还使用惊喜来识别广告系统中的根本原因。
- 广告系统的第三个独特特征是衍生措施的流行。考虑两个基本指标:每小时收入和每小时点击次数。从这两个指标中,可以定义一个派生指标,称为每次点击成本,它只是收入除以点击次数。广告系统运营商监控和跟踪许多此类派生措施,这些措施是各种基本措施的函数(见图 1)。例如,点击次数的变化和收入的变化本身可能很小而不是异常的(例如,小于 10%)。然而,相关的变化(例如,收入下降和同时点击增加,每一个增加 10%)是异常的,并且被派生的每次点击成本度量(20% 的变化)捕获。正如我们在第 4 节中讨论的那样,将根本原因归因于衍生措施具有挑战性。为了解决这个问题,我们提出了一种新颖的偏导数启发归因解决方案,用于衍生措施,这是我们论文的第二个贡献。
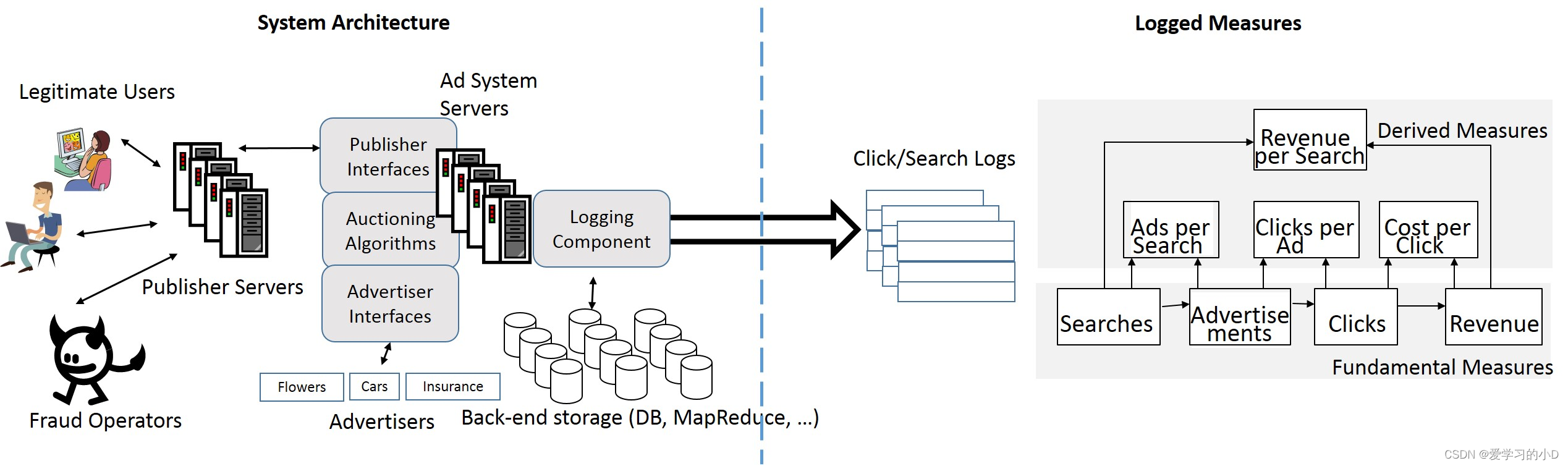
Figure 1: A simplifified representation of an ad system, and the measures it monitors.
- 我们的根本原因识别算法的结果是一组可能解释异常的候选者。但是,这只是诊断过程的第一步,故障排除人员可以在适当的情况下采取措施解决问题。为了帮助故障排除者快速识别潜在的根本原因候选者,我们在名为 Adtributor 的工具中实施了我们的根本原因识别算法和图形可视化工具,这是我们论文的第三个贡献。通过在生产系统中试点部署的经验,我们改进了 Adtributor 中的可视化界面和数据表示技术,以进一步减少故障排除人员的周转时间。
- 最后,我们对我们的根本原因算法进行了广泛的评估。首先,我们列出并讨论了一组具有代表性的案例研究,这些案例研究突出了我们的根源工具的价值。其次,我们在 2 周的真实广告系统数据中对 128 个异常警报评估了我们的算法,发现我们的算法达到了 95% 以上的准确率。事实上,Adtributor 甚至找到了一些被手动故障排除者遗漏的异常的根本原因。此外,该工具还将故障排除过程加快了一个数量级。
2 问题陈述
在本节中,在提供系统概述后,我们将展示实际问题及其根本原因的示例。接下来,我们更准确地陈述问题并激发我们的解决方案。
2.1 系统概述
- 图 1 显示了广告系统的简化表示,以及直接与广告系统交互的实体,例如用户、欺诈操作者、发布者和广告商。广告系统本身有各种子组件,我们展示了其中的一些。
- 虽然日志记录基础架构确实会跟踪每个搜索请求或广告点击,但庞大的规模使得很难在单个请求级别跟踪问题。相反,系统会监控一组聚合指标,如图 1 所示。它首先根据原始日志计算每个时间间隔接收到的总搜索量、显示的总广告量、收到的总广告点击量和总收入从这些点击。这些措施都是可加的,可以沿不同的维度进行切片。例如,总收入是使用该系统的每个广告商的收入总和。总收入也是从广告系统活跃的不同地理区域收到的收入总和。我们将此类附加措施称为基本措施。
- 此外,该系统还监控一组非加性派生指标,这些指标是基本指标的函数,例如每次搜索广告 (ads/searches)、每次广告点击次数 (clicks/ads)、每次点击成本(收入/点击)和每次搜索收入(收入/搜索)。
- 任何这些指标的异常上升或下降都表明存在问题。因此,诊断引擎需要首先检测异常,然后进行根本原因分析。在本文中,我们专注于根源的后一方面,同时依靠众所周知的基于 ARMA 模型的方法 [4] 进行异常检测。异常检测器根据 8 周的历史数据生成基于模型的测量值预测,同时考虑正常的一天中的时间和星期几的波动。然后它将实际值与预测值进行比较——当测量值的实际值与预测值有显着差异时,它会生成异常警报。我们生成警报的阈值差异是根据与预期值的百分比偏差来衡量的。在当前系统中,故障排除人员根据经验手动设置此值。对于每个警报,我们的目标是将度量中的异常归因于维度及其对应元素。接下来我们定义这些术语。
- Dimension维度:维度是一个轴,可以沿其投影度量。例如,我们可以沿广告商轴预测收入,并确定每个广告商的收入有多少。本例中的维度是“广告商”。派生度量可以类似地跨维度投影。其他一些维度是“发布者”、“数据中心”和“用户位置”。通常,一个广告系统会处理几十个这样的维度。请注意,一美元的收入可以在一个维度中添加到广告商 1,在第二个维度中添加到发布商 3。
- Element 元素:每个维度都有一个称为元素的值域。例如,“广告商”域可以包含以下元素:{Geico、Microsoft、Toyota、Frito-Lay,…}。 Publisher 维度可能有元素:{Bing, Amazon, Netflix, …}。
- 表 1 提供了我们遇到的许多问题示例,包括可操作的和不可操作的,需要检测这些问题并将其根本原因归结为适当的维度和元素。第 1 列显示问题可能发生在不同级别。第 3 列显示异常度量。第 4 列显示根本原因分析的输出,这是本文的重点。
- 请注意,第 4 列只是解决问题根源的第一步,但它是必不可少的,因为它为故障排除人员提供了问题实际所在的最佳指示。其他后处理技术(相关引擎、NLP 技术、人工调查)使用多维分析的输出对问题进行更深入的研究,以得出最终的根本原因,如第 5 列所示,但这方面根本原因不在本文讨论范围之内。例如,在第 9 行中,虽然多维分析确实将问题缩小到几个查询字符串,但管理员必须对这些字符串进行语义解释以确定原因是教皇选举。
2.2 问题定义和范围
-
收入调试的多维分析问题是找到最能解释异常上升或异常下降的维度及其元素。在这种情况下,我们需要定义什么构成了异常的“最佳解释”。
-
考虑以下示例。广告系统的收入预计在给定时间为 100 美元。实际上,实际收入仅为 50 美元。收入度量会触发警报,这会引起故障排除人员对问题的注意。
-
为了在出现此类问题时找到根本原因,广告系统会持续跟踪多个维度产生的收入。对于此场景,请考虑三个这样的维度:数据中心 (DC)、广告商 (AD) 和设备类型 (DT)。表 2、3、4 显示了沿这些维度的收入值预测,以及归因于各个元素的值。

-
我们现在解释这些属性的语义。当广告系统收到搜索查询时,它会将查询路由到一个数据中心,该数据中心反过来会提供大量广告作为响应。归因于数据中心的收入是从点击该数据中心服务的广告中获得的总收入。每个广告都有一个关联的广告商。当用户点击广告时,系统会向广告商收取预先确定的金额。归属于广告商的收入是对广告商广告进行的所有此类点击的总成本。用户使用多种设备进行搜索查询,这些设备可能是手机、平板电脑或 PC。归因于设备类型的收入是广告系统从该特定设备类型的广告点击中获得的所有收入的总和。
-
我们试图回答的问题是:我们如何将收入下降精确定位到正确的维度及其元素?我们将问题重述如下:
- “根据维度及其元素找到一个布尔表达式,使得归因于该表达式的收入下降最能解释总收入下降。”
-
虽然我们很快就会研究如何确定“最佳”,但请考虑以下可以解释 50 美元收入下降的表达式:
R e v e n u _ D r o p ( D C = = X ) = $ 47 Revenu\_Drop(DC == X) = \$47\\ Revenu_Drop(DC==X)=$47R e v e n u e _ D r o p ( A D = = A 1 ∨ A D = = A 3 ∨ A D = = A 4 ) = $ 51 Revenue\_Drop(AD == A1 ∨ AD == A3 ∨ AD == A4) = \$51 \\ Revenue_Drop(AD==A1∨AD==A3∨AD==A4)=$51
R e v e n u e _ D r o p ( D T = = M o o b i l e ∨ D T = = T a b l e t ) = $ 49 Revenue\_Drop(DT == Mo obile ∨ DT == T ablet) = \$49 Revenue_Drop(DT==Moobile∨DT==Tablet)=$49
- 例如,等式 (2) 表示行的预测收入与实际收入之间的差异之和广告客户表的 1、3 和 4 为 51 美元,非常接近 50 美元的总收入下降。
-
通常,此类表达式可以包括多个维度,例如 R e v e n u e _ D r o p ( D T = = P C ∧ D C = = X ) Revenue\_Drop (DT == PC ∧ DC == X) Revenue_Drop(DT==PC∧DC==X),它指的是从数据中心 X X X 投放广告的 PC 用户的收入下降。基于大约一年的广告监控警报通过手动研究以及使用将异常归咎于多个维度的归因算法,我们观察到的系统表明,多个维度共同导致根本原因的情况非常罕见。因此,为了简单起见,在本文中,我们将讨论限制在寻找一个布尔表达式,该表达式涉及一个维度和一组解释异常变化的元素。
-
为了理解什么构成了“最佳”维度及其元素集,我们研究了几个标准。考虑以下激发我们最终问题陈述的稻草人方法。
- Strawman:找到维度及其元素集,其收入下降至少是总收入下降的阈值分数 TEP ,并且是最简洁的。
-
我们将一组元素的解释力$ (EP)$ 量化为它所解释的度量变化的分数。我们将一组元素的简洁性 ( P ) (P) (P) 量化为表达式中元素的总数。因此,稻草人将找到至少具有 T E P T_{EP} TEP 解释力的表达式,并使用最少数量的元素。
-
奥卡姆剃刀原则表明,最简洁的集合,只要能在一定的误差范围内 ( T E P ) (T_{EP}) (TEP)解释下降,就是最好的解释。通过这个论证,如果 T E P T_{EP} TEP 设置为 0.9,则三个方程中的最佳维度和元素集在方程 1 中,因为仅数据中心 X 就可以解释总下降的 94%。
-
然而,这种方法在存在多个维度时存在根本原因的缺陷。尽管数据中心 X X X 的收入下降占总收入下降的 94 94% 94,但请注意,预测收入和实际收入在两个数据中心 X 和 Y X 和 Y X和Y 之间平均分布。数据中心 X X X 提供了 94 94% 94 的预测收入(94 美元) 100 美元)和实际收入(50 美元中的 47 美元)。数据中心 Y 在这两个值中贡献了 6%。相比之下,在设备类型维度中,设备类型 PC 贡献了 50% 的预测收入(100 美元中的 50 美元),但占实际收入的 98%(50 美元中的 49 美元)。移动和平板设备类型的贡献也相差很大,从预测收入的 25% 到实际收入的 0% 不等。贡献也随着广告商维度而变化,但不如它们沿着设备类型维度那么多。
-
设备类型维度不同要素的预测收入和实际收入之间贡献的这种巨大变化通常是令人惊讶和意外的。因此,我们认为与仅使用表达的简洁性和解释力相比,惊讶更能说明问题。假设收入下降的根本原因是配置文件错误导致没有广告在手机和平板电脑上显示。虽然数据中心 X 的收入仍然会大幅下降,因为它提供了 94% 的所有跨设备广告展示,但实际的根本原因最好用设备类型维度以及移动和平板电脑元素来解释。换句话说,等式 3 中的表达式是最好的,尽管它不是最简洁的。
-
为了捕捉这一观察结果,我们的方法包括与表达式相关联的“惊奇”(S) 概念(第 3 节有精确定义)。因此,推广到任何度量,我们最终的收入调试问题陈述可以通过三个步骤来捕获:
- 对于一个维度,找到至少解释度量变化的阈值分数 TEP 的所有元素集(具有高解释力)。
- 在每个维度的所有此类集合中,找到该维度中最简洁的集合。
- 在所有维度的所有此类集合中,找到在贡献变化方面最令人惊讶的一组。
-
同样,对于模拟示例,在 T E P = 0.9 T_{EP} = 0.9 TEP=0.9 的情况下,第一步会将集合缩小到数据中心的 { X } \{X\} {X},广告商的 { A 1 , A 3 , A 4 } \{A1, A3, A4\} {A1,A3,A4},以及 { M o b i l e , T a b l e t } 和 { P C , M o b i l e , T a b l e t } \{Mobile, Tablet\} 和 \{PC, Mobile, Tablet\} {Mobile,Tablet}和{PC,Mobile,Tablet} 设备类型。第 2 步会将每个维度的集合缩小到 { X } 、 { A 1 、 A 3 、 A 4 } 和 { M o b i l e 、 T a b l e t } \{X\}、\{A1、A3、A4\} 和 \{Mobile、Tablet\} {X}、{A1、A3、A4}和{Mobile、Tablet}。然后,第 3 步将使用惊喜指标来选择设备类型维度及其集合 { M o b i l e , T a b l e t } \{Mobile, Tablet\} {Mobile,Tablet} 作为下降的最佳解释。
-
我们的算法使用度量变化的每个元素阈值 T E E P T_{EEP} TEEP 来增加简洁性的想法。我们不仅需要最小的元素集,还需要那些至少对异常贡献 T E E P T_{EEP} TEEP 一小部分的元素。
-
我们在第 3.4 节中表明,在最坏的情况下,解决此问题可能需要指数时间(以元素数量计)。因此,我们使用贪婪的方法来近似地解决这个问题。
3 根本原因识别算法
我们从一些符号开始,用它来正式定义解释力和惊喜。然后我们描述根本原因识别算法。虽然算法对于基本测量和派生测量保持相同,但为派生测量计算解释力和惊喜的方式更加复杂,将在第 4 节中单独讨论。
3.1 符号
- 本节中使用的重要术语列表及其符号被总结在表 5 中。让度量集(例如,收入、搜索次数)表示为
M
=
{
m
1
,
m
2
,
.
.
.
,
m
k
}
M = \{m_1, m_2, ..., m_k\}
M={m1,m2,...,mk} 并让维度集(例如,广告商、数据中心)为
D
=
{
D
1
,
D
2
,
.
.
.
,
D
n
}
D = \{D_1, D_2, ..., D_n\}
D={D1,D2,...,Dn}。此外,让给定维度
D
i
D_i
Di 的元素集表示为
E
i
=
{
E
i
1
,
E
i
2
,
.
.
.
,
E
i
C
i
}
E_i = \{E_{i1}, E_{i2}, ..., E_{iC_i}\}
Ei={Ei1,Ei2,...,EiCi}
- 其中 C i C_i Ci 是维度 i i i 的基数。例如, E 21 E_{21} E21可以是广告客户维度的元素“Flowers123”。
- 对于每个感兴趣的度量 m ∈ M m ∈ M m∈M(包括基本和派生度量)和每个元素 E i j E_{ij} Eij,我们可以访问预测或预测值 F i j F_{ij} Fij,以及实际观察值 A i j A_{ij} Aij。请注意,如前所述,这些值是与感兴趣的某个时间间隔相对应的聚合(例如,元素 Flower123 的 100 美元预测收入,维度广告商的 90 美元实际收入)。
- 对于收入或搜索次数等基本衡量指标,衡量指标的总体预测值 F ( m ) F(m) F(m) 以及总体实际值 A ( m ) A(m) A(m) 在所有维度上都保持相同(例如,100 美元上一节示例中的预测收入和 50 美元的实际收入)。对于基本度量,总体度量只是各个维度元素度量值的总和,但对于派生度量而言并非如此,因为它们不是相加的(第 4 节)。
- 因此,给定 F ( m ) 和 A ( m ) F(m) 和 A(m) F(m)和A(m),算法需要输出一个潜在的根本原因来解释两者之间的差异。为此,它使用接下来定义的解释力和惊喜
3.2 解释力
-
一个元素的解释力可以定义为由给定元素值的变化解释的度量的总体值变化的百分比。对于基本度量,维度 i 中元素 j 的解释力简单地为
E P i j = ( A i j ( m ) − F i j ) / ( A ( m ) − F ( m ) ) EP_{ij} = (A_{ij} (m) − F_{ij} )/(A(m) − F(m)) EPij=(Aij(m)−Fij)/(A(m)−F(m)) -
例如,在给定小时偏离预测值 100 万到 80 万,并且特定数据中心 DC1 在同一小时的搜索次数与其预测值 50 万到 40 万不同,要素 DC1 的解释力是 ( 0.4 − 0.5 ) / ( 0.8 − 1 ) = 50 (0.4-0.5)/(0.8-1) = 50% (0.4−0.5)/(0.8−1)=50。
-
请注意,如果元素的变化与整体变化的方向相反,则元素的解释力可能超过 100% 甚至为负。但是,任何维度的所有元素的解释力总和应达到 100%。因此,解释力完全解释了总体措施的变化。
3.3 Surprise
-
正如第 2 节中的示例所讨论的,与未表现出此类变化的维度(例如,数据中心)。我们现在正式定义一个惊喜的衡量标准来捕捉这个概念。
-
对于每个元素 E i j E_{ij} Eij ,令 p i j ( m ) p_{ij} (m) pij(m) 为由给出的预测或先验概率值
p i j ( m ) = F i j ( m ) / F ( m ) , ∀ E i j p_{ij} (m) = F_{ij} (m)/F(m) ,∀Eij pij(m)=Fij(m)/F(m),∀Eij -
给定一个新的异常观测值,令 q i j ( m ) q_{ij} (m) qij(m)是实际或后验概率值
- q i j ( m ) = A i j ( m ) / A ( m ) , ∀ E i j q_{ij} (m) = A_{ij} (m)/A(m), ∀E_{ij} qij(m)=Aij(m)/A(m),∀Eij
-
直觉上,如果后验概率分布与先验概率显着不同,则给定维度的新观察结果令人惊讶分配。两个概率分布 P 和 Q P 和 Q P和Q 之间的这种差异可以通过相对熵或 Kullback-Leibler (KL) 散度 [12] 来捕捉。然而,在我们的上下文中使用 KL 散度有两个问题。首先,KL 散度不是对称的。其次,KL 散度仅在对于所有 i i i,仅当 p i = 0 时 q i = 0 p_i = 0 时 q_i = 0 pi=0时qi=0时才定义,这在我们的设置中不成立(例如,广告商暂停了他的活动)。
-
因此,我们使用称为 J e n s e n − S h a n n o n ( J S ) Jensen-Shannon (JS) Jensen−Shannon(JS) 散度 [12] 的相关度量代替 KL 散度来计算惊喜,定义为
D J S ( P , Q ) = 0.5 ( ∑ i p i l o g 2 p i p i + q i + ∑ i q i l o g 2 q i p i + q i ) D_{JS}(P, Q)=0.5(\sum_ip_i log \frac{2pi}{p_i + q_i} + \sum_iq_i log \frac{2q_i}{p_i + q_i} ) DJS(P,Q)=0.5(i∑pilogpi+qi2pi+i∑qilogpi+qi2qi) -
观察到 D J S ( P , Q ) D_{JS}(P, Q) DJS(P,Q) 是对称的并且即使当 q i = 0 和 / 或 p i = 0 q_i = 0 和/或 p_i = 0 qi=0和/或pi=0 时也是有限的。此外, 0 ≤ D J S ( P , Q ) ≤ 1 0 ≤ D_{JS}(P, Q) ≤ 1 0≤DJS(P,Q)≤1,其中 0 表示分布没有变化P 和 Q 之间,值越高表示差异越大。
-
因此,为了计算元素 E i j 的惊喜 S i j E_{ij} 的惊喜 S_{ij} Eij的惊喜Sij,我们使用 p = p i j ( m ) 和 q = q i j ( m ) p = p_{ij} (m) 和 q = q_{ij} (m) p=pij(m)和q=qij(m) 来计算
S i j ( m ) = ( 0.5 ( p l o g 2 p p + q + q l o g 2 q p + q ) S_{ij} (m)=(0.5(p \ log \frac{2p}{p + q} + q\ log \frac{2q}{p + q} ) Sij(m)=(0.5(p logp+q2p+q logp+q2q)
3.4 Algorithm
- 对于异常KPI,计算所有元素的S值
- 将每一维度下的元素按照S值降序排列
- 计算EP值,筛选可疑元素加入根因集合
- 计算维度EP值,忽略影响小的元素
- 根因集合按照S值降序排列,结果输出

根本原因识别算法试图使用上述解释力和意外的定义来解决第 2 节中指定的优化问题。
- 请注意,在最坏情况下获得问题的最优解将花费指数时间。这可以通过一个简单的例子来说明:考虑一个大小为 n 的集合,其中每个元素都具有相同的解释力,我们需要集合中的 n / 2 n/2 n/2 个元素来解释 T E P T_{EP} TEP 。在这种情况下,基数 n / 2 n/2 n/2 的每个可能子集都具有可能的最小大小(简洁)并且具有 T E P T_{EP} TEP 的解释力。因此,我们必须比较所有这些子集的意外值(其计数是 n n n 的指数),以便找到具有最大惊喜的子集,即最优解。
- 我们的算法(图 2)不是枚举具有至少 T E P T_{EP} TEP 的解释力的各种最小基数子集,而是使用以下贪心启发式算法。在每个维度中,在计算出所有元素的惊喜之后(第 1-5 行),它首先按照惊喜的降序对元素进行排序(第 8 行)。然后它将每个元素添加到候选集中,只要该元素本身至少解释了总异常变化的 T E E P T_{EEP} TEEP(第 12-15 行)。参数 T E E P T_{EEP} TEEP 有助于控制集合的基数(奥卡姆剃刀)。例如,如果 T E E P T_{EEP} TEEP 为 10%, T E P T_{EP} TEP 为 67%,我们最多可以有 7 个元素来解释异常变化。此外,通过按惊喜降序检查元素,我们贪婪地寻求最大化候选集的惊喜。该算法最多为每个维度添加一个候选集(第 16-19 行),只要该集能够解释异常变化的主要 ( T E P ) (T_{EP}) (TEP)(解释力)。最后,该算法根据惊喜值对各种候选集进行排序,并返回前三个最令人惊讶的候选集作为潜在的根本原因候选者(第 21-22 行)。
4 派生度量
派生度量是故障排除者跟踪的基本度量的函数,因为与简单跟踪基本度量相比,它们揭示了更多信息。在本节中,我们将讨论如何计算派生措施的解释力和惊喜。
4.1 解释力
虽然将单个元素的贡献归因于派生度量的整体值对于根本原因识别很重要,但这并不像计算基本度量那样简单。在本节中,我们首先从一个有助于定义派生度量的解释力的说明性示例开始,然后介绍我们对派生度量归因问题的解决方案。
Example:考虑表 6 和表 7 中的假设示例,分别显示异常期间四个不同广告商的收入和点击次数。对于这两个基本度量,使用解释力(等式 4)可以简单地将整体变化归因于每个广告商,并显示在标记为 EP 的列中。因此,对于收入下降,可以将其归因于广告商 A1 (400%),而对于点击次数的增加,可以将其归因于广告商 A2 (200%)。
-
让我们假设,如果测量值与其预期值相差至少 20%,则会引发异常。请注意,总收入下降了 10%,而点击次数上升了 16%,两者均未超过异常阈值。相应的每次点击成本值显示在表 8 中,使用相同的 20% 阈值,整体每次点击成本(减少 22.5%)可以标记为异常因此,可以看出派生的度量可以用于显示仅通过检查基本措施无法发现的异常谎言。我们在第 6 节中定量地证实了这一点。
-
导出的度量归因问题如下:如何将总体每次点击成本从 0.2(预期)下降到 0.155(实际)归因于每个广告商?如果检查表 8 中广告商的每次点击成本,我们会发现广告商 A1、A2、A4 的每次点击成本没有变化,而广告商 A3 的每次点击成本有所增加。因此,乍一看,似乎不能将整体下降归咎于任何广告商,但肯定有一个或多个广告商负有责任!鉴于这种情况,我们如何为这些广告商分配每次点击费用变化的解释力值?
-
检查基本措施确实有助于阐明更多信息。例如,尽管 A1 的每次点击费用没有变化,但与收入和点击次数的预测值相比,A1 的价格下降了 5 倍。鉴于 A1 的每次点击费用 (0.5) 高于总体价值 (0.2),5 倍的减少意味着 A1 确实降低了总体每次点击费用。 A1 解释了总体派生指标的一些下降这一事实可以通过观察得到进一步验证,如果我们使用 A1 的实际值但假设其余广告商提供了他们各自的预测值,那么总体每次成本点击下降到 60/420 = 0.143,影响为 -29%。
-
同样,虽然 A2 的预测收入为 0,但 A2 的点击次数大幅增加,最终降低了总体每次点击费用。同样,如果我们使用 A2 的实际值,但将其余广告商的度量值保持在他们的预测值,则每次点击的总成本将下降到 100/660 = 0.152,影响为 -24%。上述一次更改一个广告商价值的练习还表明,A1 比 A2 更能降低总体每次点击成本(因为使用 A1 的实际值导致总体价值低于 A2)。
-
现在考虑 A3。在点击次数没有变化的情况下,A3 的收入高于预测,因此 A3 显然没有对整体下降做出贡献。在上述练习中使用 A3 的实际值实际上会将总体每次点击成本增加到 0.26,影响为 +30%。
-
最后,A4 的收入或点击次数都没有变化。因此,A4 对总体每次点击成本没有影响。
-
将单个影响值归一化,使所有元素总计解释 100% 的总体变化,上述练习将使 A1 的解释力为 125%,A2 的解释力为 106%,A3 的解释力为 -131%,A4 的解释力为 0%。
-
总结以上示例中的观察结果,可以看出,可以通过计算新的派生度量值来确定元素对派生度量的解释力,其中使用给定元素的实际值和所有其他元素的预测值,并且将此派生度量值与派生度量的预期值进行比较。
-
现在,问题是我们如何将这种直觉形式化,以确定对任意衍生措施的解释力?我们接下来描述这个。
- Derived measure attribution派生度量属性。我们对派生度量归因问题的解决方案是根据偏导数和有限差分微积分改编的。回想一下,偏导数是衡量一个变量的函数在其中一个变量发生变化时如何变化的量度。然而,由于我们在离散域中操作,我们使用来自有限差分微积分 [13] 的偏导数等价物。
-
我们正式定义元素 i i i 对派生测度的解释力,即基本测度 m 1 , . . . , m k m_1, ..., m_k m1,...,mk 的函数 h ( m 1 , . . . , m k ) h(m_1,...,m_k) h(m1,...,mk),作为关于有限导数 i i i 的偏导数 h ( . ) h(.) h(.) 的差异,归一化,以便维度的所有元素的值总和达到 100%。
-
虽然上述定义是一般性的并且适用于作为基本测度的任意函数的派生测度(只要它们在有限差分中可微),我们现在通过形式为 A ( m 1 ) / A ( m 2 ) A(m_1)/A(m_2) A(m1)/A(m2)的派生函数的具体示例来说明),它构成了广告系统中的许多派生度量(图 1)。例如,对于每次点击成本派生的衡量标准,我们有 m 1 = r e v e n u e 和 m 2 = c l i c k s m_1 = revenue和 m_2 = clicks m1=revenue和m2=clicks。 f ( . ) / g ( . ) f(.)/g(.) f(.)/g(.) 的有限差分中的偏导数形式为$ (Δf ∗ g − Δg ∗ f)/(g ∗ (g + Δg))$,类似于连续域偏导数,除了分母中的额外 Δg。
-
因此,对于 m 1 / m 2 m_1/m_2 m1/m2 形式的派生度量,元素 j j j 对维度 i i i 的解释力由
E P i j = ( ( A i j ( m 1 ) − F i j ( m 1 ) ) ∗ F ( m 2 ) − ( A i j ( m 2 ) − F i j ( m 2 ) ) ∗ F ( m 1 ) ) / ( F ( m 2 ) ∗ ( F ( m 2 ) + A i j ( m 2 ) − F i j ( m 2 ) ) ) EP_{ij} = ((A_{ij} (m_1) − F_{ij} (m_1)) ∗ F(m_2) −(A_{ij} (m_2) − F_{ij} ( m_2)) ∗ F(m_1)) /(F(m_2) ∗ (F(m_2) + A_{ij} (m_2) − F_{ij} (m_2))) EPij=((Aij(m1)−Fij(m1))∗F(m2)−(Aij(m2)−Fij(m2))∗F(m1))/(F(m2)∗(F(m2)+Aij(m2)−Fij(m2))) -
我们使用上述等式计算每个元素的 E P i j EP_{ij} EPij 并归一化这样它们加起来就是 100%。
-
-
表 8 显示了使用上述公式为每个广告商计算的解释力。我们可以看到,A1、A2、A4、A3的排序以及它们各自对整体变化归因的解释力值,与之前的直观观察是一致的。
4.2 Surprise
- 回想一下,我们在第 3.3 节中根据测量值 m 的先验质量函数和后验质量函数之间的相对熵(特别是 JS 散度)定义了基本测量的惊奇。在本节中,我们试图将意外的概念扩展到多项措施的派生函数。
- 考虑上一节中的每次点击费用示例。计算派生度量的意外的简单方法如下。与基本度量一样,可以计算每个元素 Eij 的每次点击成本的先验概率值和后验概率值,例如 pij(每次点击成本)和 qij(每次点击成本),并计算惊喜在第 3.3 节中。
- 然而,这样的方法是行不通的。考虑表 8 中广告商 A2 的示例。A2 的每次点击成本预测为零,实际值也为 0。因此,如果使用上述方法计算元素 A2 的惊喜,其值为0(不足为奇)。但是,我们发现 A2 对于由于 A2 点击次数的变化而导致的每次点击成本的总体变化具有 106% 的高解释力。
- 从相对熵的角度来考察问题,给定几个测度,首先需要计算测度的联合概率分布,然后计算联合概率分布函数的相对熵。如果测度是独立的,那么联合概率分布的相对熵(以及 JS 散度)就是单个测度的概率分布的相对熵的总和。在广告系统中,这些指标并不总是严格独立的,因为其中一些指标可能相关(例如,随着搜索次数的增加,收入有望增加)。但是,作为近似值,我们假设度量是独立的,并将派生度量的意外计算为作为派生函数一部分的各个度量的意外总和。
5 实施和经验
在本节中,我们描述了我们在 Adtributor 工具中实施上述算法,并概述了我们在生产广告系统中进行试点部署的经验。
5.1 实施
-
在我们的实施中,数据库实时记录所有度量、维度和元素的计数器,并将它们公开为支持多维分析查询的 OLAP 服务 [19]。当系统触发异常事件时,Adtributor 工具链首先收集与异常相关的数据,如异常时间、度量、各种度量的数据、维度和元素。从数据库中查询数据后,Adtributor 使用根本原因算法来发现给定异常的潜在根本原因。
-
回想一下,措施不一定彼此独立。某个指标的异常可能与另一个指标的值变化相关。因此,我们构建了一个度量的依赖图,并且对于给定的异常度量,为与其相关的每个度量运行根源算法。
-
Adtributor 过滤候选根本原因集(如第 3 节所述)以生成最终的根本原因列表。我们使用 67% 的 TEP 值和 10% 的 TEEP 值。这些阈值由问题排查人员在手动过程中已经使用的内容驱动。此外,我们当前的实施挑选出前三个维度的列表。故障排除专家根据他们自己的要求以及可视化的难易程度推荐了这个数字。数字越小,他们可能会错过有用的信息,而数字越大,他们就会发现太多信息,无法筛选。
-
最终输出是一个独立的 HTML5 应用程序。图 3 显示了 Adtributor 工具链生成的输出示例。根本原因的可视化包含以下信息:
-
Dependency Graph依赖关系图:系统中不同措施之间依赖关系的图形表示(左半部分)。
-
Measure Historical Graph:度量历史图:描述度量历史行为的图(右上图)。
-
Element Root-Causes and Historical Graph元素根本原因和历史图表:对于给定的度量和维度,最重要的元素是根本原因。元素根本原因按维度及其历史图表(右上图下方)分组。
-
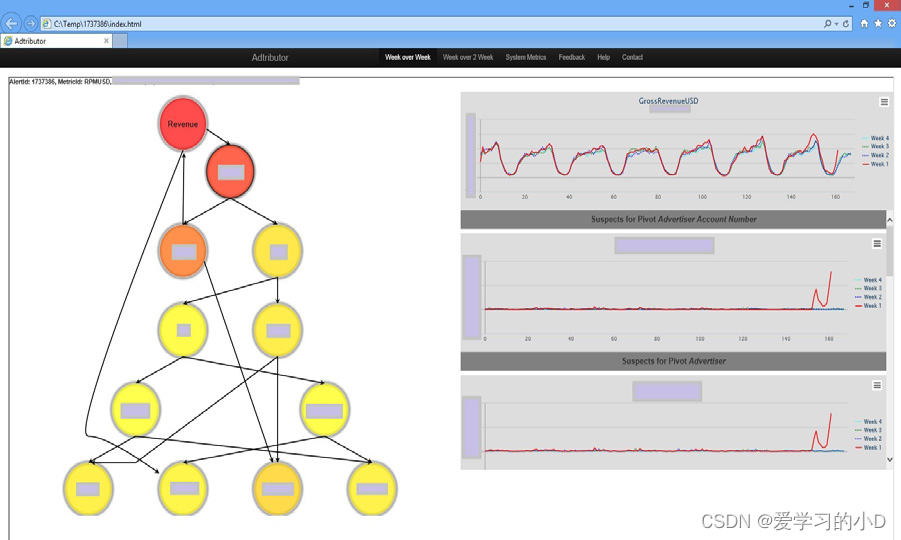
Figure 3: An example output of the Adtributor. Note:certain sensitive fifields are masked.
- 通过与故障排除专家的反复讨论,我们得出了可视化要求。依赖图允许他们观察不同度量值之间的因果关系,每个维度的历史图帮助他们就根本原因究竟是什么做出更明智的选择。整个 Adtributor 工具链是使用 .NET Framework 4 实现的,使用 12,500 行代码并针对每个异常自动执行。
5.2 部署经验
我们在2013 年5 月1 日至2013 年5 月10 日期间与生产系统的故障排除人员进行了Adtributor 的试点部署,以解决根源异常问题,以了解Adtributor 的用处。此部署在帮助故障排除人员处理当前流程方面取得了部分成功。这个试验的结果导致我们的算法和可视化得到了一系列改进,从而显着提高了性能,正如我们在第 6 节中的评估中所展示的那样。
- Volatile dimensions易变的维度:各种维度可能非常不稳定,并且可能会发生意想不到的变化沿着这些轴线采取措施,即使它们不一定是问题的根本原因。考虑一个经常更改广告预算分配的广告商的例子。当出现收入异常时,这有时会导致根本原因算法将广告商选为罪魁祸首,即使变化恰好发生在异常事件发生之前。这促使我们通过增加预测模型中近期发生的大变化的权重来改进与易变维度元素相关的度量的预测算法,从而在很大程度上解决了这个问题。
- Visualization enhancements可视化增强:相关措施的依赖图被故障排除者发现非常有用。但是,该工具中的当前视图仅限于一小组措施。在广告系统中还有数百种其他措施正在被监控,其依赖关系是未知的。我们因此使用贝叶斯结构学习算法 [5] 来推断这些依赖关系的子集,并计划通过这些附加措施来增强依赖关系图的可视化。
6 评估
在本节中,我们首先描述了四个案例研究,其中多维分析是找到最终根本原因的关键。接下来,我们对 Adtributor 的准确性以及我们使用该工具节省的时间进行量化评估。
6.1 案例研究
- Case 1案例 1:这是由收入异常下降引发的。在执行多维分析时,我们发现维度浏览器负责。图 4 有助于解释 Adtributor 如何得出这个结果。它显示了三个维度(浏览器、数据中心和存储桶)对预测收入和实际收入的收入贡献百分比(有关存储桶的定义,请参见表 1,示例 3。)。请注意,浏览器 3 的收入贡献预计为 12%,但实际收入为 0%!同样,浏览器 1 的贡献预计为 60%,但实际上要高得多,为 74%。数据中心维度和存储桶维度都没有显示出如此惊人的贡献变化。这个问题是可以解决的,因为进一步的调查显示配置错误导致没有广告在浏览器 3 上向用户显示。更正错误解决了问题和进一步的收入损失。
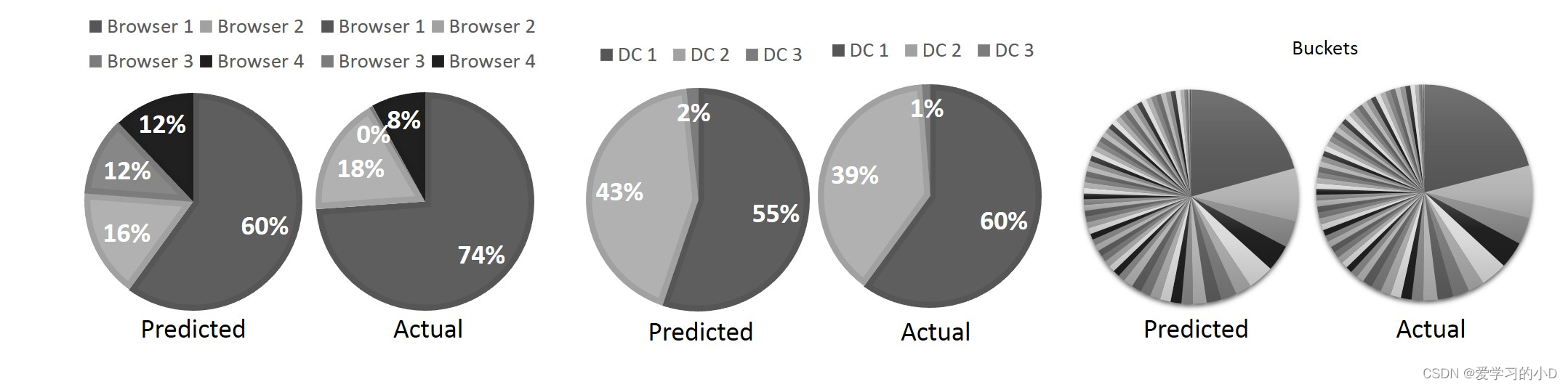
Figure 4: Predicted and actual revenues for the Browser, Data center, and Bucket dimensions (Case Study 1).
- Case 2案例 2:我们注意到特定时间的异常收入增长,Adtributor 将其归因于一组特定的六个广告商。其中两个广告商是机票供应商,两个是汽车租赁公司,其余两个是酒店。总的来说,他们充分解释了收入的变化。深入调查后,我们注意到这些广告商在一段时间内故意增加了预算。这些广告出现在一个长周末假期临近的地理区域。因此,我们推断广告商试图在用户执行与假期相关的搜索时利用并吸引他们的注意力。显然,在这种情况下,收入的突然增加归因于广告商的行为,而不是由于系统中可采取行动的错误。当广告商也故意降低预算时,也会发生一些这样的异常情况。
- Case 3案例 3:搜索总数异常高,分析表明大部分增加都归因于 User-agent 字符串维度。从对该结果的后处理中,可以推断出大多数使用重复用户代理字符串的搜索来自一小部分 IP 地址,因此具有可疑的机器人流量特征。特别是,该机器人的目标是执行查询并收集搜索引擎优化 (SEO) 的信息。这是一个可操作的问题,通过过滤此流量对各种指标的贡献而迅速解决。
- Case 4案例 4:我们注意到,有时,发布商会更改其页面上的广告位置,从而使广告更(或更不)显眼。这反过来会导致收入相应增加或减少。这些显示为页面上广告位置维度的收入变化。例如,如果发布商将本应显示在页面侧面的广告移动到页面顶部,这本身就表现为显示在顶部的广告带来的收入的惊人增长。这是因为用户往往会更多地点击页面顶部显示的广告,而不是侧边显示的广告。
6.2 比较研究
- 我们的定量评估是基于使用 Adtributor 来解决广泛部署的广告系统中的根本原因问题。我们评估了 33 个维度上总共 12 项措施(包括基本措施和派生措施)产生的所有异常。我们在此展示的结果使用了 2013 年 9 月 1 日至 2013 年 9 月 15 日期间超过 10 亿次搜索生成的 128 个有效异常的子集,涉及 8 个人群:美国、英国、法国和德国的 PC 和移动广告系统。出于本研究的目的,我们不考虑异常生成过程中的误报,因为它们在应用根本原因过程 2 之前已被故障排除人员清除。 50% 的测试异常仅在派生测量上产生,构成派生测量的相应基本测量没有产生相关异常。这表明在聚合根本原因分析中使用派生度量是极其重要的。
- 我们将 Adtributor 的多维分析输出与故障排除团队的输出进行比较,故障排除团队在其他工具(而非 Adtributor)的协助下通过手动方式对这些异常进行深入和详细的分析。手动分析异常原因有很多优势。故障排除人员了解大量信息和领域知识,并且他们在故障排除过程中经常使用这些知识。 Adtributor 等自动化工具不可能了解所有这些。此外,Adtributor 仅缩小了根本原因的范围(表 1 的第 4 列)——在许多情况下可能仍然需要手动过程来识别最终的根本原因(表 1 的第 4 列),因为一些下一步执行此操作所需的数据可能无法用于自动化过程(例如,验证发布者是否确实更改了广告的位置)。
- 然而,使用 Adtributor 的优势在于它通过 1) 使用多维根本原因分析来彻底检查所有可能的维度(如我们所示,在 2Evaluating the number of false-positives and负面影响是评估异常检测算法,如前所述,这超出了本文的范围。在少数情况下,手动过程可能会忽略一个维度,导致错误的结论)和 2)显着更快地处理冒泡最高嫌疑人可以决定。例如,有几十个维度,有些维度可以有数千个元素。
- 如第 5 节所述,Adtributor 显示前三个维度及其元素作为潜在嫌疑人。如果 Adtributor 在这三个位置中的任何一个位置显示与手动过程相同的维度和完全相同的元素,我们就说 Adtributor 匹配手动根源过程的输出。

- 表 9 显示了 Adtributor 的输出与人工调查之间的比较结果。在 128 个异常中,Adtributor 在 118 个案例中匹配了手动分析的结果。其中,81 个(69%)在位置 1 匹配,27 个(23%)仅在位置 2 匹配而不在位置 1,10 个(8%)在位置 3 匹配,而不在位置 1 或 2。对于我们与手动输出不匹配的 10 个异常谎言,我们与故障排除专家进行了更深入的探讨。仔细检查后,我们发现在 10 个手动根本原因中有 4 个是错误的,而 Adtributor 在位置 1 的输出实际上是正确的根本原因。这显示了使用系统算法(如在 Adtributor 中)的实用性,该算法详尽地搜索所有维度以执行多维根本原因分析。
- 在剩余的 6 个异常中,手动输出有 5 个是正确的,而 Adtribu tor 的输出是错误的。在所有这些情况下,Adtributor 都缺乏领域知识,或者缺乏故障排除人员明确知道的系统外部事件的知识。然而,在一种情况下(标记为不明确),故障排除人员认为 Adtributor 指责的维度和元素与通过手动分析获得的维度和元素一样可能是真正的根本原因。在这种情况下,他认为需要进一步深入挖掘以确定正确的根本原因。考虑到人为错误,Adtributor 的总体准确率为 (118+4)/128,即 95%。
- 我们还比较了使用 Adtributor 可以节省的潜在时间与手动故障排除过程中的第一步(确定可能是潜在根本原因的维度和元素)相比。 Adtrib utor 使用多线程实现和缓存来加速研究每个维度和每个度量的过程。每个异常的周转时间约为 3-5 分钟。手动故障排除过程耗时从最快的 13 分钟到 231 分钟不等,平均周转时间为 73 分钟。因此,我们得出结论,Adtributor 将初始根本原因过程加快了一个数量级。
- 最后,我们通过将我们的算法与第 2 节中讨论的仅使用简洁性和解释力的 Strawman 算法进行比较来展示使用惊喜的价值。与 Adtributor 95% 的准确率相比,我们发现 Strawman 的准确率只有 20%。这清楚地证明了使用惊喜来确定正确的维度和元素作为根本原因的价值。
7 广告系统之外的适用性
我们相信本文介绍的技术足够通用,可用于其他设置。例如,
- Multi-dimensional analysis多维分析:考虑一个拥有全球受众的网络服务器,突然发现点击量急剧下降。本文中考虑的许多维度,例如数据中心或 CDN、浏览器、用户位置、欺诈运营商/机器人等,都可能是多维分析可以帮助消除歧义的潜在根本原因。
- Derived measure attribution派生度量归因:考虑以下问题。 VoIP 呼叫的平均意见得分 (MOS) 已经下降,调查人员想了解呼叫路由中的哪个链接是造成这种下降的主要原因。每个链路可能有不同的延迟量、抖动和丢失百分比,MOS 是延迟、丢失和抖动等度量的复杂函数 [6]。使用派生归因技术可以帮助计算每个链接的 MOS 下降的解释力。
8 相关工作
- System and Network Root-Cause Analysis系统和网络根本原因分析:先前的研究广泛研究了系统和网络中的根本原因性能和故障问题 [14, 2, 10, 1, 21, 15, 3, 20, 11, 18] .其中一些使用系统 [3、14] 中跨单个请求的跟踪来诊断问题,而其他使用系统性能或配置值的聚合计数器 [15、10、20] 来诊断问题。
- Distalyzer [14] 是前一类的一个例子。它使用单独的事件日志并学习表明系统组件中存在性能问题的事件之间的异常模式。 Ganesha [15] 是后者的一个例子。它使用跨聚合门度量(例如 CPU 使用率)的集群方法来构建 MapReduce 节点的不同配置文件。虽然我们的方法也使用聚合度量,但我们打算发现的不仅仅是性能问题或诊断故障。
- Q-Score [18] 使用机器学习来找出根本原因。我们尝试了类似的方法并决定反对它们,因为选择正确的特征集以输入到股票机器学习算法被证明是一项非常重要的任务。相反,我们发现构建自定义算法更简单,更适合我们领域专家的分析和反馈。
- SCORE [11] 使用简洁的解释将 IP 故障定位到底层组件。给定一组链路故障作为观察值,它确定可以解释故障的最小风险组集。然而,正如我们所展示的,这种方法不足以跨维度执行归因,并且惊喜的概念对于完成我们的解决方案至关重要。
- Data Mining for Summarization用于汇总的数据挖掘:数据挖掘 [17、16、7] 的先前工作集中在对 OLAP 产品中的多维数据进行汇总。目标是对跨多个维度的数据值差异提供易于解释的总结。这种汇总技术也已应用于网络流量汇总[9]。虽然跨多个维度的数据汇总与我们的工作相关,但它不符合我们寻找令人惊讶的变化以执行根本原因分析的目标。事实上,我们的根本原因分析方法是对这些方法的补充,可以应用于它们生成的摘要。
9 结论
我们已经描述了一种算法、实施和评估方法,该方法使用多维分析来解决大型广告系统中的根本问题。我们发现我们的方法具有很高的准确性 (95%),在少数情况下帮助识别比手动调查更准确的根本原因,并且能够显着减少故障排除时间。
10 致谢
感谢我们的牧羊人 VYAS SEKAR 提出的宝贵意见和建议。我们还要感谢 MURALI KRISHNA 帮助我们验证 Adtributor 的输出并确定其准确性。

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









