






Huggingface的安装
直接pip这个包即可
pip install transformers
在使用时可能会因为网络的原因无法访问huggingface,可以采用科学上网,或者使用hf-mirror镜像即可解决问题。
简单进行一个情感分析
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I love YUN.",
"I hate this movie.",
]
)

基本流程
——>Tokenizer——>Model——>Post Processing——>
Raw text–>Input IDs–>Logits–>Predictions
This course is amazing–>[101,2023,2607,2003,6429,999,102]–>[-4.3630,4.6859]–>[POSITIVE:99.98%,NEGATIVE:0.11%]
Tokenizer
Tokenzier进行分词,分字及特殊字符–>对每一个token映射得到一个ID,并且得到一些辅助信息(当前词属于哪个句子。。)
from transformers import AutoTokenizer
model = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model)
raw_inputs = [
"I love YUN.",
"I hate this movie.",
]
inputs = tokenizer(raw_inputs,padding=True,truncation=True,return_tensors="pt")
print(inputs)
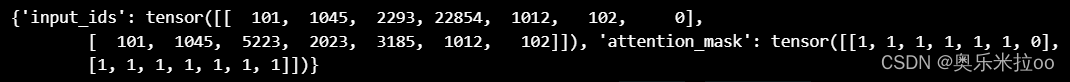
tokenizer.decode([ 101, 1045, 2293, 22854, 1012, 102, 0])
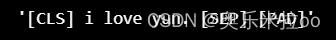
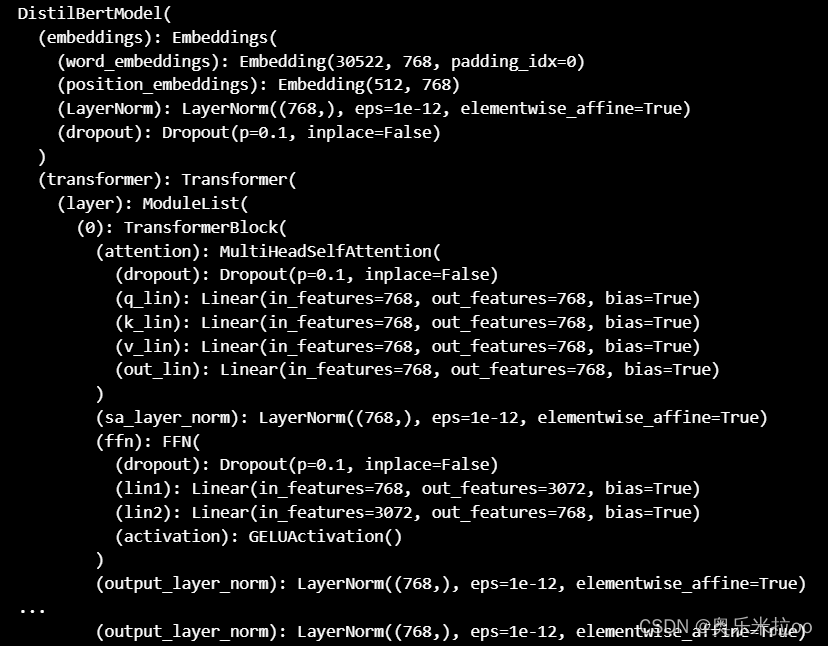
模型的加载
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
model
ps:注意attention_mask的设定,否则会计算padding
下一篇将记录模型基本训练方法
















 3140
3140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











