







【前言】 介绍Opcode的提取方法,并探讨多种机器学习算法在Webshell检测中的应用,理解如何在实际项目中应用Opcode进行高效的Webshell检测。
Ⅰ 基本概念
Opcode:计算机指令的一部分,也叫字节码,一个php文件可以抽取出一个指令序列,如ADD、ECHO、RETURN。
【原因】由于直接对php文件使用词袋和TF-IDF进行模型训练会消耗大量计算资源,使用opcode模型进行降维可以有效提升模型效率和模型的准确率。
【作用】避免Webshell中为了绕开静态检测恶意添加的无用注释的干扰
Ⅱ Opcode提取
【背景】php版本72,路径/www/server/php/72/bin
安装地址:https://pecl.php.net/package/vld 官网下载对应的vld版本
安装脚本
cd vld-0.15.0
# 使用phpize生成配置脚本,并指定php-config路径(与你的 PHP 路径相关 )
/www/server/php/72/bin/phpize
./configure --with-php-config=/www/server/php/72/bin/php-config --enable-vld
# 编译
make && make install
#可看到一个so文件
/opt/vld-0.15.0/vld-0.15.0/modules/vld.so
# php.ini文件添加
extension=vld.so
# 重启php服务
systemctl restart php7.2
测试 111.php
<?php
echo "Hello World";
?>
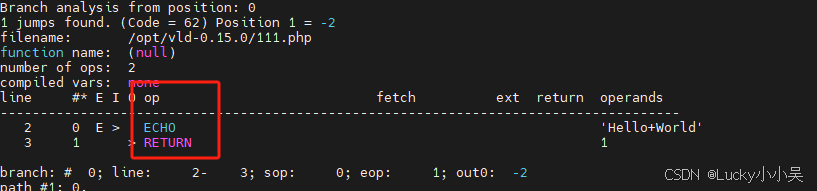
查看php文件的Opcode
php -dvld.active=1 -dvld.execute=0 111.php
效果如下,op值就是了,直接提取下来
Ⅲ 训练过程
提取opcode很简单,就是采用什么模型训练,才能尽可能提高召回率和准确率
第一种:朴素贝叶斯
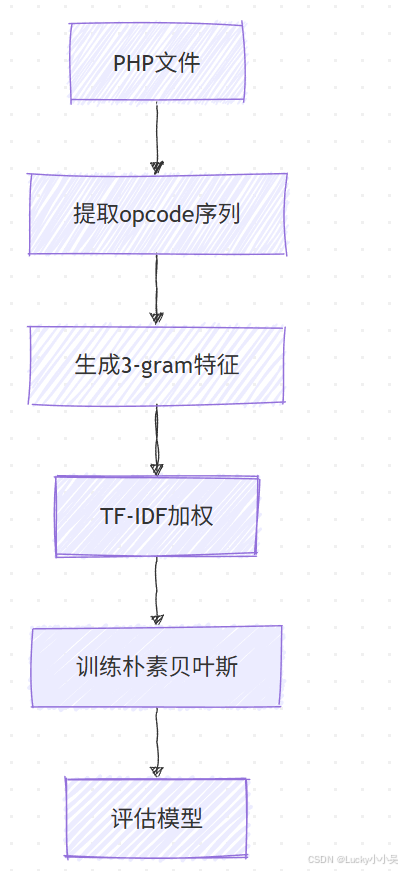
特征提取使用词袋&TF-IDF模型
- 将 WebShell 样本以及常见 PHP 开源软件的文件提取词袋。
- 使用 TF-IDF 处理。
- 随机划分为训练集和测试集。
- 使用朴素贝叶斯算法在训练集上训练,获得模型数据。
- 使用模型数据在测试集上进行预测。
- 验证朴素贝叶斯算法预测效果。
第二种:使用MLP算法
特征提取使用特征提取使用opcode&n-gram
完整的处理流程为
- 将 WebShell 样本以及常见 PHP 开源软件的文件提取 opcode.
- 使用 n-gram 处理。
- 随机划分为训练集和测试集。
- 使用 MLP 算法在训练集上训练,获得模型数据。
- 使用模型数据在测试集上进行预测。
- 验证 MLP 算法预测效果。
第三种:CNN模型训练
还未实现
Ⅳ 实战环节
def extract_opcodes(filepath: str, php_executable: str = 'php') -> Optional[str]:
"""
使用vld扩展从文件中提取PHP opcodes,适配详细输出格式。
Args:
filepath: PHP文件的路径。
php_executable: PHP可执行文件的路径。
Returns:
如果成功,返回一个包含opcode的空格分隔字符串,否则返回None。
"""
if not os.path.exists(filepath):
logger.error(f"文件未找到用于opcode提取: {filepath}")
return None
cmd = [
php_executable,
'-dvld.active=1',
'-dvld.execute=0',
filepath
]
logger.debug(f"运行命令用于opcode提取: {' '.join(cmd)}")
try:
# --- 正确的提取逻辑,用于解析表格 ---
output = subprocess.check_output(
cmd,
stderr=subprocess.STDOUT
)
output_str = output.decode('utf-8', errors='ignore') # 使用 utf-8 解码,忽略可能的解码错误
tokens = re.findall(r'\s(\b[A-Z_]+\b)\s', output_str)
opcodes = " ".join(tokens)
# --- 提取逻辑结束 ---
if not opcodes:
# 即使命令成功,也可能因为文件内容或VLD的特殊输出而没有Opcode
# logger.warning(f"未从 {filepath} 提取到有效格式的Opcode。VLD输出起始部分: {result.stdout[:300]}...")
return ""
print("|==============文件{}提取出来的opcode:{}".format(filepath,opcodes))
return opcodes
except FileNotFoundError:
logger.error(f"'{php_executable}'命令未找到。无法提取opcode。")
return None
except subprocess.TimeoutExpired:
logger.warning(f"Opcode提取超时于{filepath}。跳过。")
return None
except Exception as e:
logger.error(f"在{filepath}提取opcode时发生错误: {e}")
return None
- 使用 TF-IDF 处理:特征工程 (CountVectorizer + TF-IDF)
logger.info(f"应用 CountVectorizer (ngrams={ngram_range}, min_df={min_df}, max_df={max_df})...")
vectorizer = CountVectorizer(
ngram_range=ngram_range,
decode_error="ignore",
# token_pattern=r'\s(\b[A-Z_]+\b)\s', # 匹配 Opcode 的模式
min_df=min_df,
max_df=max_df
)
- 随机划分为训练集和测试集。
logger.info(f"划分数据 (test_size={test_size}, random_state={random_state})...")
X_train, X_test, y_train, y_test = train_test_split(
X_tfidf, y_labels, test_size=test_size, random_state=random_state, stratify=y_labels # stratify 保证训练集和测试集标签比例相似
)
logger.info(f"训练集大小: {X_train.shape[0]}, 测试集大小: {X_test.shape[0]}")
大概划分 训练集大小: 13359, 测试集大小: 5726
- 使用朴素贝叶斯算法在训练集上训练,获得模型数据。
logger.info("训练多项式朴素贝叶斯模型...")
model = MultinomialNB()
model.fit(X_train, y_train)
logger.info("模型训练完成。")
用模型数据在测试集上进行预测。
logger.info("--- 在测试集上评估模型 ---")
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, zero_division=0) # 处理除零情况
recall = recall_score(y_test, y_pred, zero_division=0)
f1 = f1_score(y_test, y_pred, zero_division=0)
conf_matrix = confusion_matrix(y_test, y_pred)
logger.info(f"准确率 (Accuracy): {accuracy:.4f}")
logger.info(f"精确率 (Precision): {precision:.4f}")
logger.info(f"召回率 (Recall): {recall:.4f}")
logger.info(f"F1 分数 (F1-Score): {f1:.4f}")
- 验证朴素贝叶斯算法预测效果。
--- 在测试集上评估模型 ---
- 准确率 (Accuracy): 0.9555
- 精确率 (Precision): 0.9305
- 召回率 (Recall): 0.8796
- F1 分数 (F1-Score): 0.9043
- 混淆矩阵 (Confusion Matrix):
-
[[4266 90]
[ 165 1205]]
实战测试
效果很一般,误报极高,本来只有两个文件的

Ⅴ 当前问题
第一:go进程如果要调用opcode进行预测,是否需要自动编译一个内置环境,还是说有内置go环境
需要手动写一个内置的php环境,用于获取opcode,单纯go程序,无法正常获取
Ⅵ 下一步优化
- 调参
- AST解析出操作序列

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









