






jdk1.7
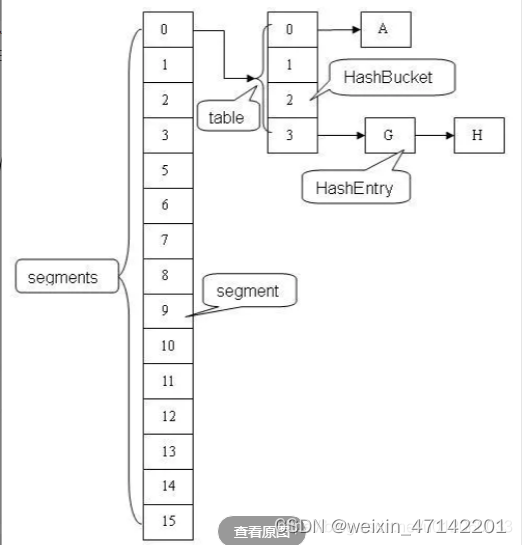
ConcurrentHashMap底层结构:Segment数组结构和HashEntry数组结构组成
Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组
Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素
每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
ConcurrentHashMap的get操作
get操作不加锁,原因是它的get方法的共享变量都定义成了volatile,例如统计当前segment大小的count字段和用于存储值的HashEntry的vaule。都定义成了volatile的变量,能够在多线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期值,但是只能被单线程写。在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
ConcurrentHashMap的size操作
在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化
jdk 1.8之后
JDK 1.8的实现已经摈弃了segment分段锁机制,利用CAS+Sychronized来保证并发更新的安全。
数据结构采用:数组 + 链表/红黑树
put方法
步骤:
-
检查
Key或者Value是否为null, -
得到
Key的hash值 -
如果
Node数组是空的,此时才初始化initTable(), -
如果找的对应的下标的位置为空,直接new一个Node节点并放入, break;
-
如果对应头结点不为空, 进入同步代码块
-
判断此头结点的
hash值,是否大于零,大于零则说明是链表的头结点在链表中寻找,如果有相同hash值并且key相同,就直接覆盖,返回旧值 结束如果没有则就直接放置在链表的尾部此头节点的Hash值小于零,则说明此节点是红黑二叉树的根节点调用树的添加元素方法判断当前数组是否要转变为红黑树















 2878
2878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









