







 本文介绍了岭回归的基本概念,包括其原理、优点、局限性以及如何处理多重共线性。通过实际例子展示了如何使用scikit-learn实现岭回归,并计算了模型在测试集上的性能。
本文介绍了岭回归的基本概念,包括其原理、优点、局限性以及如何处理多重共线性。通过实际例子展示了如何使用scikit-learn实现岭回归,并计算了模型在测试集上的性能。
目录
前言
“岭回归”这个词源于英文“Ridge Regression”,是一种用于处理回归分析中多重共线性(multicollinearity)问题的统计方法。在传统的最小二乘回归(Ordinary Least Squares,OLS)中,当自变量之间存在高度相关性时,会导致回归系数估计的不稳定性和偏误。岭回归通过对回归系数的估计进行调整,有效地解决了这一问题。
一、基本概念
1. 引言
在回归分析中,最小二乘法(OLS)是最常见的估计方法之一,用于估计自变量与因变量之间的关系。然而,在实际应用中,自变量之间往往存在着一定程度的相关性,即多重共线性问题。多重共线性会导致OLS估计出的回归系数不稳定,难以准确解释和预测。为了解决这一问题,岭回归作为一种正则化方法被提出,并在实践中得到广泛应用。
2. 岭回归的原理
岭回归的核心思想是在OLS的基础上引入一个正则化项,通过对回归系数进行调整来解决多重共线性问题。正则化项是一个惩罚项,它能够约束回归系数的大小,降低模型的复杂度,防止过拟合。
3. 数学表达式

4. 岭回归的优点
- 解决多重共线性问题:岭回归能够有效地处理自变量之间存在高度相关性的情况,提高回归系数估计的稳定性。
- 控制过拟合:通过引入正则化项,岭回归可以降低模型的复杂度,减少过拟合的风险。
- 灵活性:岭回归的岭参数可以根据实际情况进行调整,使模型更加灵活适用于不同的数据集和问题。
5. 岭回归的局限性
- 岭参数的选择:选择合适的岭参数需要一定的经验和技巧,过大或过小的岭参数都可能导致不良的结果。
- 系数解释性:由于岭回归对回归系数进行了调整,因此解释岭回归模型的系数可能相对复杂。
6. 实际应用
- 与交叉验证等方法结合使用:通常通过交叉验证等方法来选择最佳的岭参数,以及评估模型的性能。
- 在机器学习中的应用:岭回归的思想被推广到其他机器学习算法中,如岭分类和岭主成分分析,以解决不同领域中的相关问题。
二、具体实例
这段代码实现了以下功能:
- 创建了一个具有10个特征的示例数据集,其中包含100个样本。
- 将数据集划分为训练集和测试集,其中80%的数据用于训练,20%用于测试。
- 使用scikit-learn库中的
Ridge类定义了岭回归模型,并指定了岭参数(alpha)为1.0。- 在训练集上训练了岭回归模型。
- 在测试集上进行了预测,并计算了预测结果与真实值之间的均方误差(MSE)。
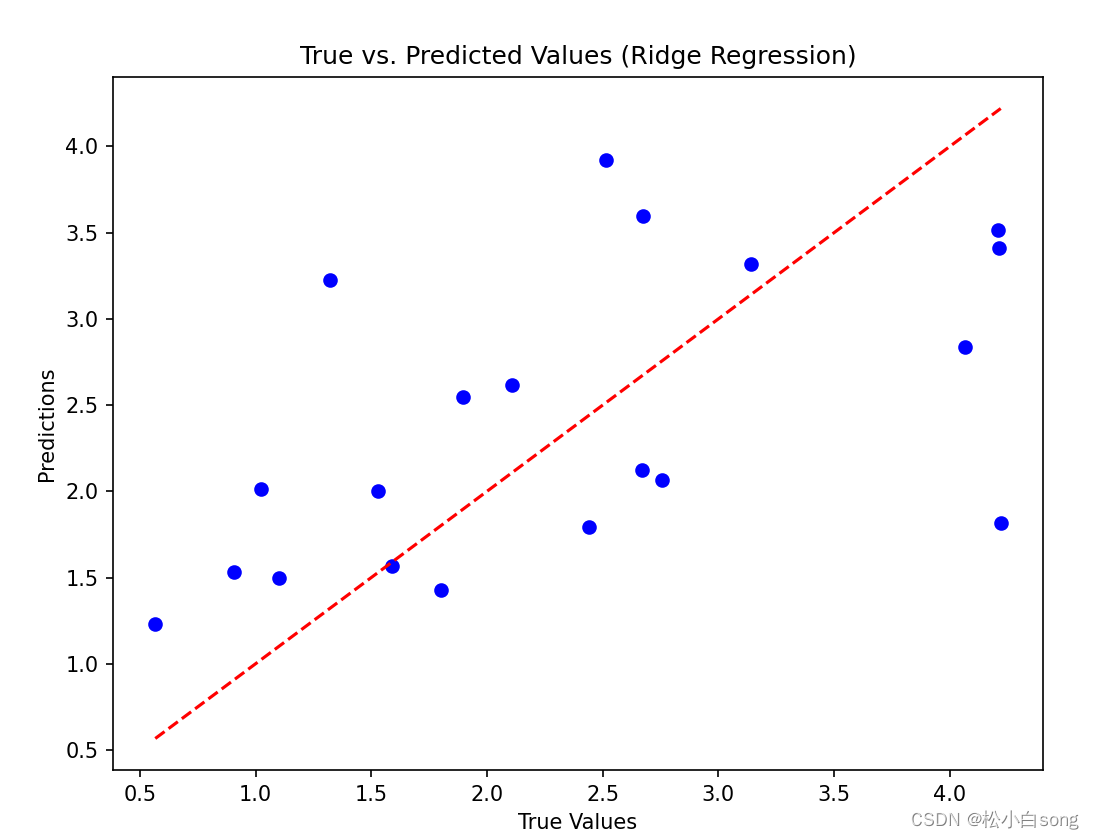
- 最后,绘制了预测值与真实值的对比图,以直观地展示模型的性能。
代码:
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 创建示例数据集
np.random.seed(0)
X = np.random.rand(100, 10) # 100个样本,10个特征
y = 2 * X[:, 0] + 3 * X[:, 1] + np.random.randn(100) # 构造线性关系,并添加噪声
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义岭回归模型
ridge = Ridge(alpha=1.0) # alpha为岭参数,默认为1.0
# 在训练集上训练模型
ridge.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = ridge.predict(X_test)
# 计算均方误差(MSE)作为性能评估指标
mse = mean_squared_error(y_test, y_pred)
print("岭回归模型的均方误差为:", mse)
# 绘制预测值与真实值的对比图
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], linestyle='--', color='red')
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.title('True vs. Predicted Values (Ridge Regression)')
plt.show()
结果:
![]()

















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









