







知识背景
问:说说构造函数有哪几种?分别有什么用?
C++中的构造函数可以分为4类:默认构造函数、初始化构造函数、拷贝构造函数、移动构造函数。
1. 默认构造函数和初始化构造函数(在定义类的对象时,完成对象的初始化工作)
class Student{
public:
//默认构造函数
Student() {
num=1001;
age=18;
}
//初始化构造函数
Student(int n,int a):num(n),age(a){}
private:
int num;
int age;
};
int main()
{
//用默认构造函数初始化对象S1
Student s1;
//用初始化构造函数初始化对象S2
Student s2(1002,18);
return 0;
}有了有参的构造了,编译器就不提供默认的构造函数。
2. 拷贝构造函数
include "stdafx.h"
#include "iostream.h"
class Test{
int i;
int *p;
public:
Test(int ai,int value)
{
i = ai;
p = new int(value);
}
~ Test() {
delete p;
}
Test(const Test& t)
{
this->i = t.i;
this->p = new int(*t.p);
}
};
//复制构造函数用于复制本类的对象
int main(int argc, char* argv[])
{
Test t1(1,2);
Test t2(t1);//将对象t1复制给t2。注意复制和赋值的概念不同
return 0;
}赋值构造函数默认实现的是值拷贝(浅拷贝)。
在拷贝构造函数中有一种删除拷贝构造函数:可以使用 `= delete` 关键字在类定义中显式声明并定义拷贝构造函数,并将其标记为 `delete`。这将阻止编译器自动生成默认的拷贝构造函数。
以下是一个示例:
class MyClass {
public:
MyClass(const MyClass&) = delete;
};通过将拷贝构造函数标记为 `delete`,我们禁止了对象的拷贝操作。如果尝试复制 `MyClass` 对象,编译器会报错。
以下是一个使用被删除拷贝构造函数的示例:
MyClass obj1;
MyClass obj2(obj1); // 编译错误,拷贝构造函数被删除需要注意的是,删除拷贝构造函数并不会影响对象的移动构造函数。如果需要禁止对象的移动操作,可以类似地删除移动构造函数。
3. 移动构造函数
移动构造函数(Move Constructor)是C++11引入的一种特殊的构造函数,用于实现对象的移动语义。它允许将一个对象的资源(如动态分配的内存或文件句柄)从一个对象转移到另一个对象,而不进行深拷贝。
移动构造函数的定义通常采用以下形式:
class MyClass {
public:
MyClass(MyClass&& other) {
// 执行资源的移动操作
// 将 other 的资源转移到当前对象
}
};移动构造函数使用右值引用(`&&`)作为参数类型,表示传入的参数是一个临时对象或将被销毁的对象。在移动构造函数内部,可以通过将资源的所有权从传入的对象转移给当前对象来实现移动操作。通常,这涉及将指针或句柄从一个对象复制到另一个对象,并将原始对象的资源指针设置为 `nullptr` 或无效值,以避免资源的重复释放。
以下是一个移动构造函数的简单示例,假设我们有一个表示动态分配的内存的类 `MyClass`:
#include <iostream>
class MyClass {
private:
int* data;
public:
// 默认构造函数
MyClass() : data(nullptr) {}
// 移动构造函数
MyClass(MyClass&& other) {
data = other.data; // 移动资源
other.data = nullptr; // 将原始对象的资源指针设置为 nullptr
}
// 析构函数
~MyClass() {
delete data; // 释放资源
}
// 其他成员函数...
};
int main() {
MyClass obj1;
// 假设 obj1 分配了一块动态内存
MyClass obj2(std::move(obj1)); // 调用移动构造函数
// 现在 obj1 不再拥有动态内存,而是被 obj2 移动了
return 0;
}在上面的示例中,我们定义了一个 `MyClass` 类,其中包含了一个动态分配的整数数组 `data`。移动构造函数将 `data` 的所有权从 `other` 对象移动到当前对象中,并将 `other` 的 `data` 指针设置为 `nullptr`。这样,我们就成功地将资源从一个对象转移到了另一个对象。
注意,在调用移动构造函数时,我们使用了 `std::move` 函数将 `obj1` 转换为右值引用,以便调用移动构造函数而不是拷贝构造函数。
移动构造函数在处理大型对象、资源管理类(如智能指针)或需要高效传递临时对象的情况下非常有用,可以避免不必要的拷贝操作,提高性能。
问:什么是虚析构?虚析构的作用是什么?
虚析构函数(Virtual Destructor)是C++中的一个特殊函数,用于在继承关系中正确释放资源。当基类指针指向派生类对象时,如果基类的析构函数不是虚析构函数,那么在使用 `delete` 删除基类指针时,只会调用基类的析构函数,而不会调用派生类的析构函数,这可能导致派生类中的资源无法正确释放,造成内存泄漏。
为了解决这个问题,可以将基类的析构函数声明为虚析构函数。虚析构函数使用 `virtual` 关键字进行声明,它允许在通过基类指针删除对象时,调用正确的析构函数。
虚析构函数的定义通常采用以下形式:
class Base {
public:
virtual ~Base() {
// 析构函数的实现
// 可以是空函数,或者释放基类中的资源
}
};
class Derived : public Base {
public:
~Derived() override {
// 派生类的析构函数的实现
// 可以是空函数,或者释放派生类中的资源
}
};在上面的示例中,`Base` 类的析构函数被声明为虚析构函数,使用 `virtual` 关键字进行修饰。`Derived` 类继承自 `Base` 类,并重写了虚析构函数。
当使用基类指针指向派生类对象时,通过基类指针删除对象时,会调用正确的析构函数,即首先调用派生类的析构函数,然后调用基类的析构函数,确保资源的正确释放。
以下是一个虚析构函数的简单示例:
#include <iostream>
class Base {
public:
virtual ~Base() {
std::cout << "Base destructor" << std::endl;
}
};
class Derived : public Base {
public:
~Derived() override {
std::cout << "Derived destructor" << std::endl;
}
};
int main() {
Base* ptr = new Derived();
delete ptr; // 调用正确的析构函数
return 0;
}在上面的示例中,我们创建了一个基类指针 `ptr`,指向一个派生类对象。通过 `delete` 删除 `ptr` 时,会首先调用派生类 `Derived` 的析构函数,然后调用基类 `Base` 的析构函数。输出结果将是:
Derived destructor
Base destructor通过使用虚析构函数,可以确保在继承关系中正确释放对象的资源,避免内存泄漏的问题。虚析构函数在基类中声明为虚函数,而在派生类中可以选择是否重写虚析构函数。
问:什么是多态、虚函数、纯虚函数?三者有什么联系?
在C++中,多态(Polymorphism)是面向对象编程的一个重要概念,它允许以统一的方式处理不同类型的对象。多态性通过虚函数和纯虚函数来实现。
1. 多态(Polymorphism)
(1)多态是指同一个函数或方法可以根据调用的对象类型而表现出不同的行为。
(2)多态性通过虚函数实现,允许以基类的指针或引用调用派生类的函数,实现动态绑定。
(3)多态性可以提高代码的可扩展性和可维护性,使得程序更加灵活和易于扩展。
2. 虚函数(Virtual Function)
(1)虚函数是在基类中声明为虚函数的成员函数。
(2)虚函数通过动态绑定实现运行时多态性。
(3)在基类中声明为虚函数后,派生类可以重写(覆盖)这些函数。
(4)在使用基类指针或引用调用虚函数时,会根据对象的实际类型来调用相应的函数。
3. 纯虚函数(Pure Virtual Function)
(1)纯虚函数是在基类中声明为纯虚函数的虚函数。
(2)纯虚函数没有函数体,只有声明,通过在声明后添加 `= 0` 来指定。
(3)纯虚函数在基类中没有实际的实现,而是要求派生类必须重写它们。
(4)包含纯虚函数的类被称为抽象类,它不能被实例化,只能用作基类。
下面是一个简单的示例来说明多态、虚函数和纯虚函数的概念:
#include <iostream>
class Animal {
public:
virtual void makeSound() {
std::cout << "Animal makes a sound." << std::endl;
}
virtual void eat() = 0; // 纯虚函数
};
class Dog : public Animal {
public:
void makeSound() override {
std::cout << "Dog barks." << std::endl;
}
void eat() override {
std::cout << "Dog eats bones." << std::endl;
}
};
class Cat : public Animal {
public:
void makeSound() override {
std::cout << "Cat meows." << std::endl;
}
void eat() override {
std::cout << "Cat eats fish." << std::endl;
}
};
int main() {
Animal* animal1 = new Dog();
Animal* animal2 = new Cat();
animal1->makeSound(); // 调用派生类的虚函数
animal1->eat(); // 调用派生类的纯虚函数
animal2->makeSound(); // 调用派生类的虚函数
animal2->eat(); // 调用派生类的纯虚函数
delete animal1;
delete animal2;
return 0;
}在上面的示例中,我们定义了一个基类 Animal,其中包含一个虚函数 makeSound 和一个纯虚函数 eat。派生类 Dog 和 Cat 分别重写了这两个函数。
在 main 函数中,我们使用基类指针 animal1 和 animal2 分别指向 Dog 对象和 Cat 对象。通过基类指针调用虚函数 makeSound 和纯虚函数 eat 时,实际调用的是派生类的函数。
输出结果将是:
Dog barks.
Dog eats bones.
Cat meows.
Cat eats fish.通过多态性和虚函数的机制,我们可以通过基类指针或引用来处理不同类型的对象,实现统一的接口调用,使代码更加灵活和可扩展。纯虚函数则提供了一种接口规范,要求派生类必须实现该函数。
问:DDL 和 DML 的区别?
在SQL中,DDL(Data Definition Language)和DML(Data Manipulation Language)是两种不同的语言类型,用于对数据库进行定义和操作。
DDL用于定义数据库的结构和模式,它包括创建、修改和删除数据库对象的语句。
以下是一些常见的DDL语句:
(1)CREATE:用于创建数据库对象,如表、视图、索引等。
(2)ALTER:用于修改数据库对象的结构,如修改表的列、添加约束等。
(3)DROP:用于删除数据库对象,如删除表、视图、索引等。
(4)TRUNCATE:用于删除表中的所有数据,但保留表的结构。
下面是一些DDL语句的示例:
创建表:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);修改表结构:
ALTER TABLE employees
ADD COLUMN salary DECIMAL(10, 2);删除表:
DROP TABLE employees;DML用于对数据库中的数据进行操作,它包括插入、更新和删除数据的语句。
以下是一些常见的DML语句:
(1)SELECT:用于查询数据库中的数据。
(2)INSERT:用于向表中插入新数据。
(3)UPDATE:用于更新表中的数据。
(4)DELETE:用于删除表中的数据。
下面是一些DML语句的示例:
查询数据:
SELECT * FROM employees WHERE age > 30;插入数据:
INSERT INTO employees (id, name, age) VALUES (1, 'John', 35);更新数据:
UPDATE employees SET age = 40 WHERE id = 1;删除数据:
DELETE FROM employees WHERE id = 1;总结:
DDL用于定义数据库的结构和模式,包括创建、修改和删除数据库对象的语句;DML用于对数据库中的数据进行操作,包括插入、更新和删除数据的语句。
问:关键字 `explicit` 的作用?
在 C++ 中,`explicit` 是一个关键字,用于修饰单参数构造函数,防止它们在隐式类型转换中被调用。
通常情况下,单参数构造函数可以被用于隐式类型转换。例如,如果一个类 `A` 有一个单参数构造函数,可以将另一个类型的对象隐式地转换为 `A` 类型的对象。这种隐式类型转换在某些情况下可能会导致意外的行为或错误。
使用 `explicit` 关键字可以阻止这种隐式类型转换,将构造函数声明为显式构造函数。当构造函数被声明为显式构造函数时,在使用时必须显式地调用构造函数,而不能进行隐式的类型转换。
下面是一个示例,展示了使用 `explicit` 关键字的情况:
class A {
public:
explicit A(int x) {
// 构造函数的实现
}
};
void foo(A obj) {
// 函数的实现
}
int main() {
A a1(10); // 直接调用构造函数,显式构造对象
A a2 = 20; // 错误!隐式类型转换被禁止
A a3 = A(30); // 正确!显式调用构造函数
foo(40); // 错误!隐式类型转换被禁止
foo(A(50)); // 正确!显式调用构造函数
return 0;
}在上面的示例中,`A` 类的构造函数被声明为显式构造函数,因此不能进行隐式类型转换。只能通过显式调用构造函数来创建对象。
通过使用 `explicit` 关键字,可以明确指定构造函数的使用方式,避免了一些潜在的问题和误用。它提供了更严格的类型转换控制,有助于编写更安全和可靠的代码。
问:C++中的智能指针有哪些?分别解决的问题及区别?
1、智能指针种类
C++中的智能指针有 4 种,分别为:shared_ptr、unique_ptr、weak_ptr、auto_ptr,其中auto_ptr被C++11弃用。
2、使用智能指针的原因
申请的空间(即 new 出来的空间),在使用结束时,需要 delete 掉,否则会形成内存碎片。在程序运行期间,new 出来的对象,在析构函数中 delete 掉,但是这种方法不能解决所有问题,因为有时候 new 发生在某个全局函数里面,该方法会给程序员造成精神负担。此时,智能指针就派上了用场。使用智能指针可以很大程度上避免这个问题,因为智能指针就是一个类,当超出了类的作用域时,类会自动调用析构函数,析构函数会自动释放资源。所以,智能指针的作用原理就是在函数结束时自动释放内存空间,避免了手动释放内存空间。
3. 四种指针分别解决的问题以及各自特性
(1)auto_ptr(C++98的方案,C++11已经弃用)
采用所有权模式
auto_ptr<string> p1(new string("I reigned loney as a cloud."));
auto_ptr<string> p2;
p2=p1; //auto_ptr不会报错此时不会报错,但 p2剥夺了 p1 的所有权,但是当程序运行时访问 p1 将会报错。所以 auto_ptr 的缺点是:存在潜在的内存崩溃问题。
(2)unique_ptr(替换 auto_ptr)
unique_ptr 实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露,例如,以 new创建对象后因为发生异常而忘记调用 delete 时的情形特别有用。采用所有权模式,和上面例子一样。
auto_ptr<string> p3(new string("I reigned loney as a cloud."));
auto_ptr<string> p4;
p4=p3; //此时会报错编译器认为 P4=P3 非法,避免了 p3 不再指向有效数据的问题。因此,unique_ptr 比 auto_ptr 更安全。 另外 unique_ptr 还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
unique_ptr<string> pu1(new string ("hello world"));unique_ptr<string> pu2;
pu2 = pu1;
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string ("You"));
// #1 not allowed
// #2 allowed其中 #1 留下悬挂的 unique_ptr(pu1),这可能导致危害。而 #2 不会留下悬挂的 unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的 auto_ptr 。
注意:如果确实想执行类似与 #1 的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数 std::move(),让你能够将一个unique_ptr 赋给另一个。例如:
unique_ptr<string> ps1, ps2;
ps1 = demo("hello");
ps2 = move(ps1);
ps1 = demo("alexia");
cout << *ps2 << *ps1 << endl;(3)shared_ptr(非常好使)
shared_ptr 实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share 就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数 use_count() 来查看资源的所有者个数。除了可以通过 new 来构造,还可以通过传入 auto_ptr, unique_ptr, weak_ptr 来构造。当我们调用 release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
成员函数:
- use_count 返回引用计数的个数
- unique 返回是否是独占所有权( use_count 为 1)
- swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
- reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
- get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的,如 shared_ptr sp(new int(1)); sp 与 sp.get()是等价的
(4)weak_ptr
weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象。进行该对象的内存管理的是那个强引用的 shared_ptr。weak_ptr 只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作,它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。weak_ptr 是用来解决 shared_ptr 相互引用时的死锁问题,如果说两个 shared_ptr 相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和 shared_ptr 之间可以相互转化,shared_ptr 可以直接赋值给它,它可以通过调用 lock 函数来获得 shared_ptr。
class B;
class A{
public:
shared_ptr<B>pb_;
~A(){
cout<<"A delete\n";
}
};
class B{
public:
shared_ptr<A> pa_;
~B(){
cout<<"B delete\n";
}
};
void fun{
shared_ptr<B>pb(new B());
shared_ptr<A> pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<<pb.use_count()<<endl;
cout<<pa.use_count()<<endl;
}
int main()
{
fun();
return 0;
}可以看到 fun 函数中 pa ,pb 之间互相引用,两个资源的引用计数为 2,当要跳出函数时,智能指针 pa,pb 析构时两个资源引用计数会减一,但是两者引用计数还是为1,导致跳出函数时资源没有被释放(A B的析构函数没有被调用),如果把其中一个改为 weak_ptr 就可以了,我们把类 A 里面的 shared_ptr pb_; 改为 weak_ptr pb; 运行结果如下,这样的话,资源 B 的引用开始就只有 1,当 pb 析构时,B的计数变为0,B 得到释放,B 释放的同时也会使 A 的计数减一,同时 pa 析构时使 A 的计数减一,那么 A 的计数为0,A 得到释放。
注意:我们不能通过 weak_ptr 直接访问对象的方法,比如 B 对象中有一个方法 print(),我们不能这样访问,pa->pb->print(); 因为 pb 是一个 weak_ptr,应该先把它转化为 shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
问:SELECT语句各部分执行顺序?若有相关子查询,则主查询和子查询执行顺序?
一条完整的 SELECT 语句中,各个查询块的执行顺序通常按照以下顺序进行:
1、FROM 子句:首先,数据库会执行 FROM 子句中指定的表格。这包括从相关表格中检索数据、执行连接操作(如果有连接条件),以及加载表格数据到内存中以供后续查询使用。
2、WHERE 子句:一旦表格数据可用,数据库会应用 WHERE 子句中的筛选条件,以排除不符合条件的行。只有符合条件的行将被保留下来,用于后续的处理。
3、GROUP BY 子句:如果查询包括 GROUP BY 子句,数据库会根据指定的分组条件对符合 WHERE 条件的行进行分组。这通常涉及聚合操作,如 SUM、AVG 等。
4、HAVING 子句:如果有 GROUP BY 子句,数据库会应用 HAVING 子句中的筛选条件,以排除不符合条件的分组。只有符合条件的分组将被保留下来。
5、SELECT 子句:最后,数据库会执行 SELECT 子句,以计算和选择要包含在结果集中的列,包括计算列和聚合函数(如果有)。
当一个 SELECT 查询中包含子查询时,执行顺序可以分为主查询与子查询的执行顺序。以下是它们的一般执行顺序:
1、主查询:首先,数据库会执行主查询的 FROM 子句和 WHERE 子句。这涉及从相关表中检索数据、执行连接操作(如果有连接条件),并将符合 WHERE 子句条件的行保留下来。
2、子查询:一旦主查询的 FROM 子句和 WHERE 子句执行完成,数据库会依次执行各个子查询。子查询可以出现在以下位置:
- 在主查询的 SELECT 列表中:子查询会为每个主查询的行执行一次,并将结果作为主查询的一部分返回。
- 在主查询的 WHERE 子句中:子查询会对每个主查询的行执行,用于筛选主查询的行。
- 在主查询的 HAVING 子句中:子查询会在 GROUP BY 分组后对每个分组应用,并根据子查询的结果来选择保留哪些分组。
- 在主查询的连接条件中:如果主查询涉及多个表格,子查询可能会出现在连接条件中,以决定匹配的行。
子查询的执行顺序是依次执行的,对于每个主查询的行,都会执行子查询,然后再进行下一行的主查询处理。
1、GROUP BY 子句和聚合函数:如果查询包括 GROUP BY 子句和聚合函数(如 SUM、AVG),则在子查询执行之后,数据库将对主查询的结果进行分组和聚合。这通常涉及对已选择的列进行聚合操作。
2、HAVING 子句:HAVING 子句将应用于 GROUP BY 分组后的结果。它用于进一步筛选分组,并决定哪些分组的结果应包含在最终结果集中。
3、ORDER BY 子句:如果查询包括 ORDER BY 子句,数据库将对最终结果进行排序,以满足指定的排序顺序。
4、LIMIT 子句:最后,如果查询包括 LIMIT 子句,数据库将返回结果集的前若干行,以满足限制条件。
需要注意的是,优化器可以根据查询的复杂性和性能优化的需求来重新安排这些步骤,以提高查询性能。具体的执行顺序可能因数据库管理系统和查询优化器的不同而异。
问:什么是查询表达式?什么是查询块?什么是查询块内部查询表达式?
查询表达式:查询表达式是一个由一个或多个查询块组成的结构,用于描述一个数据库查询的整体操作。它可以包含多个查询块,这些查询块可以使用集合操作(如UNION、INTERSECT、EXCEPT)来组合结果。
查询表达式示例:
SELECT column1, column2
FROM table1
UNION
SELECT column3, column4
FROM table2;这个查询表达式包含两个查询块,第一个查询块是 SELECT column1, column2 FROM table1,第二个查询块是 SELECT column3, column4 FROM table2。它们通过 UNION 操作符组合在一起,表示取两个查询块的结果的并集。
查询块:查询块代表了一个独立的查询单元,它描述了一个具体的操作,如从一个表格中检索数据。一个查询块可以包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等子句,用于指定操作的详细条件。
查询块示例:
SELECT column1, column2
FROM table1
WHERE condition = 'value'
ORDER BY column1;问:什么是分区表?什么是分区表剪枝?
分区表(Partitioned Table)是将数据按照特定规则划分为多个逻辑部分的表。每个部分称为一个分区,每个分区可以独立管理和存储数据。分区表的目的是提高查询和维护的效率。
分区表的划分规则可以是多种多样的,常见的包括:
1)范围分区(Range Partitioning):根据某个列的范围值进行划分,例如按照日期范围或数值范围进行分区。
2)列表分区(List Partitioning):根据某个列的离散值进行划分,例如按照地区或部门进行分区。
3)哈希分区(Hash Partitioning):根据某个列的哈希值进行划分,将数据均匀地分散到多个分区中。
4)复合分区(Composite Partitioning):结合多个划分规则进行分区,例如先按照范围划分,再按照列表划分。
分区表的好处包括:
1)提高查询性能:查询只需要处理特定分区的数据,避免了全表扫描,加快查询速度。
2)简化维护操作:可以对某个分区进行独立的备份、恢复、优化和维护,而不需要操作整个表。
3)改善数据加载和删除的效率:可以针对特定分区进行数据加载和删除操作,减少对其他分区的影响。
分区表剪枝(Partition Pruning)是对分区表进行查询优化的技术,目的是减少需要扫描的分区数量,提高查询性能。分区表剪枝的原理是根据查询条件中的谓词信息,确定哪些分区中的数据不可能满足查询条件,从而避免扫描这些分区。
通过分析查询条件和分区表的分区规则,数据库系统可以确定哪些分区的数据不可能在查询条件下满足要求,然后只扫描包含有可能满足条件的分区,而忽略其他分区。这样可以大大减少数据访问量,提高查询性能。
分区表剪枝是在查询执行计划生成阶段进行的优化操作,数据库系统会根据查询条件和分区表的分区规则,自动进行分区剪枝。这种优化技术可以在处理大量数据的情况下显著提高查询性能,减少查询时间和资源消耗。
1. dispatch_sql_command() 函数
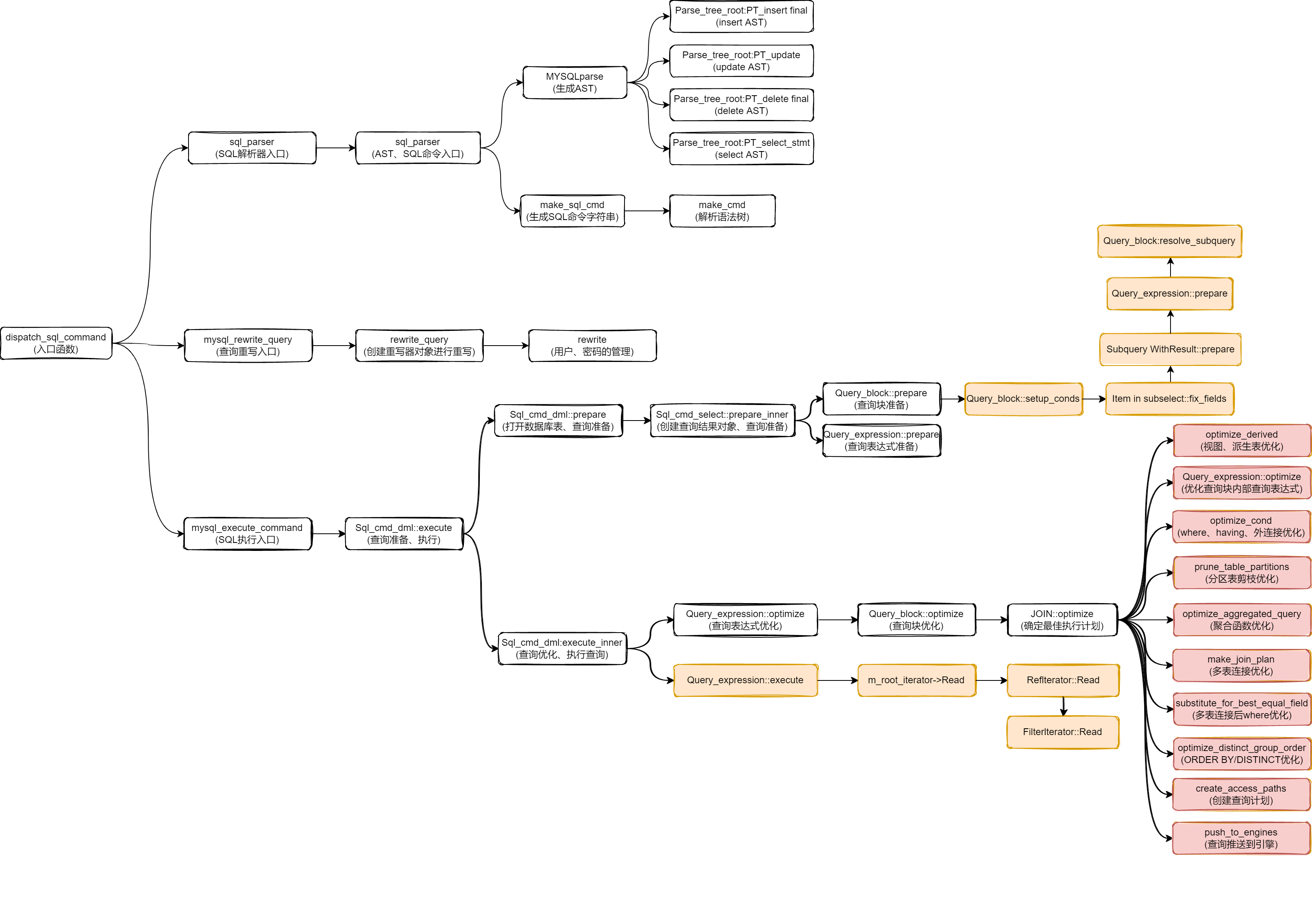
`dispatch_sql_command()` 函数是 MySQL 数据库内部的一个函数,用于处理和分派 SQL 命令。下面是该函数的具体功能和作用的概述:
功能:
1)调用parse_sql()函数解析SQL语句
2)调用mysql_rewrite_query进行查询重写
3)执行客户端发送的SQL命令
void dispatch_sql_command(THD *thd, Parser_state *parser_state) {
//重置thd(Thread)对象的状态,以准备执行下一个SQL命令
mysql_reset_thd_for_next_command(thd);
//初始化thd(Thread)对象的词法分析器,以准备解析下一个SQL命令
lex_start(thd);
//======1)调用parse_sql()函数解析SQL语句======//
parse_sql(thd, parser_state, nullptr);
//用于指示解析器是否找到了分号
found_semicolon = parser_state->m_lip.found_semicolon;
//======2)调用mysql_rewrite_query进行查询重写======//
if (!err) {
if (thd->rewritten_query().length() == 0) mysql_rewrite_query(thd);
...
}
//======3)执行客户端发送的SQL命令======//
error = mysql_execute_command(thd, true);
//处理数据库线程结束查询时的一些清理工作和资源释放
THD_STAGE_INFO(thd, stage_freeing_items);
sp_cache_enforce_limit(thd->sp_proc_cache, stored_program_cache_size);
sp_cache_enforce_limit(thd->sp_func_cache, stored_program_cache_size);
thd->lex->destroy();
thd->end_statement();
thd->cleanup_after_query();
assert(thd->change_list.is_empty());
}digest(摘要)
在 SQL 语句解析器中,摘要的用途是对 SQL 语句进行标识、比较或索引。摘要是根据 SQL 语句的内容计算得出的固定长度的哈希值或指纹。
摘要的主要作用包括:
1)缓存查询计划:解析器可以使用 SQL 语句的摘要来检查是否已经解析和优化过该语句。如果摘要已经存在于缓存中,解析器可以直接使用缓存中的查询计划,而无需重新解析和优化。
2)唯一标识语句:摘要可以用作 SQL 语句的唯一标识符。通过比较语句的摘要,可以确定是否存在相同的 SQL 语句,从而避免重复执行相同的操作。
3)提高查询效率:数据库系统可以使用摘要来构建索引或优化查询。通过在摘要上建立索引,可以加快查询的速度,特别是在大型数据库系统中。
4)安全性考虑:在某些情况下,摘要可以用于隐藏敏感信息。例如,可以对敏感的 SQL 语句进行摘要处理,然后存储摘要值,而不是明文存储实际的 SQL 语句。
需要注意的是,摘要是通过哈希函数计算得出的,它是一种单向函数,无法从摘要反推出原始的 SQL 语句。因此,摘要主要用于标识和比较,而不是还原原始的 SQL 语句内容。
在解析过程中,只有那些被认为是顶层查询语句的语句才会被考虑计算摘要;其他类型的语句,如子查询或嵌套查询,可能不需要计算摘要;目的可能是为了优化解析过程,避免对不需要摘要的语句进行不必要的计算。
总而言之,SQL 语句解析器中的摘要在查询优化、缓存、索引和唯一标识等方面发挥着重要的作用。它提供了一种高效、快速和安全的方式来处理和管理 SQL 语句。
1.1 parse_sql() 函数

parse_sql 函数是 sql 语句解析入口函数,在该函数中通过调用 sql_parser 函数在完成 sql 解析的具体实现。
功能:
1)解析查询语句前的准备工作:获取解析器诊断区、语句诊断去及内存根的相关设置
2)调用sql_parser函数执行SQL解析
3)恢复内存根的默认状态、处理解析器诊断区、语句诊断去的状态信息并进行清除
4)如果解析器诊断区中当前语句的条件计数不为0,处理错误或发出警告
/*
@param thd Thread context.线程上下文
@param parser_state Parser state.解析器状态
@param creation_ctx Object creation context.对象创建上下文,它是指在软件开发中,用于跟踪和记录对象创建的环境和上下文信息
*/
bool parse_sql(THD *thd, Parser_state *parser_state,
Object_creation_ctx *creation_ctx) {
//创建上下文的类
Object_creation_ctx *backup_ctx = nullptr;
//将线程对象 thd 的状态备份到 creation_ctx 中,并返回一个备份的上下文对象
if (creation_ctx) backup_ctx = creation_ctx->set_n_backup(thd);
//设置解析器状态
thd->m_parser_state = parser_state;
/*-------------------------------------------------------------
判断是否需要计算摘要信息,若需要,则计算
在解析过程中,只有那些被认为是顶层查询语句的语句才会被考虑计算摘要;
其他类型的语句,如子查询或嵌套查询,可能不需要计算摘要;
目的可能是为了优化解析过程,避免对不需要摘要的语句进行不必要的计算;
-------------------------------------------------------------*/
if (parser_state->m_input.m_has_digest) {
if (thd->m_digest != nullptr) {
parser_state->m_digest_psi = MYSQL_DIGEST_START(thd->m_statement_psi);
...
}
}
}
/*
在解析过程中,无法确定当前命令是否是诊断性语句。因此,为了在解析之后能够处理可能出现的诊断性语句,
需要在解析过程中使用临时的 DA。这样,即使当前命令不是诊断性语句,也可以保留之前的 DA,以便能够回答与之相关的问题。
*/
//-------1)解析查询语句前的准备工作:获取解析器诊断区、语句诊断去及内存根的相关设置------//
//获取当前线程的解析器诊断区,用于存储解析过程中的诊断信息
Diagnostics_area *parser_da = thd->get_parser_da();
//获取当前线程的语句诊断区(da),用于存储语句执行过程中的诊断信息
Diagnostics_area *da = thd->get_stmt_da();
//创建了一个解析器内存溢出处理器(Parser_oom_handler),用于处理解析过程中的内存溢出情况
Parser_oom_handler poomh;
//设置当前线程的内存根(mem_root)的最大容量,限制解析过程中可以使用的最大内存量
thd->mem_root->set_max_capacity(thd->variables.parser_max_mem_size);
//设置当解析过程中超过内存根的最大容量时,产生错误
thd->mem_root->set_error_for_capacity_exceeded(true);
//将内存溢出处理器(poomh)推入当前线程的内部处理器栈,以便在发生内存溢出时进行处理
thd->push_internal_handler(&poomh);
//将解析器诊断区(parser_da)推入当前线程的诊断区栈,以便在解析过程中记录诊断信息
thd->push_diagnostics_area(parser_da, false);
//-------2)调用sql_parser函数执行SQL解析------//
bool mysql_parse_status = thd->sql_parser();
//-------3)恢复内存根的默认状态、处理解析器诊断区、语句诊断去的状态信息并进行清除------//
//从当前线程的内部处理器栈中弹出内存溢出处理器
thd->pop_internal_handler();
//将当前线程的内存根的最大容量设置为0,恢复默认状态
thd->mem_root->set_max_capacity(0);
//将内存根的容量超限错误设置为不产生错误
thd->mem_root->set_error_for_capacity_exceeded(false);
//======4)如果解析器诊断区中当前语句的条件计数不为0,即有错误或警告发生时执行以下代码块======//
if (parser_da->current_statement_cond_count() != 0) {
/*
确保解析过程中的错误或警告能够正确地记录在顶层诊断区,并在必要时发送给客户端。
这样可以提供准确的诊断信息,帮助用户理解和解决解析过程中的问题;
*/
//重置语句诊断区的条件信息,清除之前的条件
if (thd->lex->sql_command != SQLCOM_SHOW_WARNS &&
thd->lex->sql_command != SQLCOM_GET_DIAGNOSTICS)
da->reset_condition_info(thd);
//如果解析器诊断区中存在错误,并且语句诊断区中没有错误时执行以下代码块
if (parser_da->is_error() && !da->is_error()) {
//将解析器诊断区中的错误信息设置到语句诊断区中
da->set_error_status(parser_da->mysql_errno(), parser_da->message_text(),
parser_da->returned_sqlstate());
}
//从解析器诊断区复制 SQL 条件到语句诊断区
da->copy_sql_conditions_from_da(thd, parser_da);
//重置解析器诊断区,清除其中的诊断信息
parser_da->reset_diagnostics_area();
//重置解析器诊断区的条件信息,清除之前的条件
parser_da->reset_condition_info(thd);
//将当前线程解析器的诊断信息保留标志设置为 DA_KEEP_PARSE_ERROR,表示保留解析过程中的错误信息
thd->lex->keep_diagnostics = DA_KEEP_PARSE_ERROR;
}
thd->pop_diagnostics_area();
/*
检查在 THD::sql_parser() 函数执行失败时,要么 thd->is_error() 被设置,要么存在一个内部错误处理程序
该断言(assert)无法捕捉到解析失败但没有报告错误的情况,如果存在错误处理程序的话;
问题在于错误处理程序可能拦截了错误,所以 thd->is_error() 没有被设置;
然而,这里无法百分之百确定(因为错误处理程序可能是针对解析错误以外的其他错误)。
目的是确保在解析过程中发生错误时,要么通过 thd->is_error() 设置错误标志,
要么存在一个内部错误处理程序来处理错误情况。这是为了确保在解析失败时能够正确地处理错误,
并提供适当的错误报告或处理机制。然而,由于错误处理程序的存在,无法完全确定解析是否失败,
因此该断言无法捕获所有可能的情况。
*/
//如果条件满足,代码会继续执行后续的操作
assert(!mysql_parse_status || (mysql_parse_status && thd->is_error()) ||
(mysql_parse_status && thd->get_internal_handler()));
/* Reset parser state. */
//重置解析器的状态,将 thd->m_parser_state 设置为 nullptr,以清除解析器的状态信息
thd->m_parser_state = nullptr;
if (creation_ctx) creation_ctx->restore_env(thd, backup_ctx);
ret_value = mysql_parse_status || thd->is_fatal_error();
if ((ret_value == 0) && (parser_state->m_digest_psi != nullptr)) {
assert(thd->m_digest != nullptr);
MYSQL_DIGEST_END(parser_state->m_digest_psi,
&thd->m_digest->m_digest_storage);
}
return ret_value;
}解析器诊断区和语句诊断区的功能及二者间的联系?
解析器诊断区的功能:
1)收集解析过程中的错误信息:解析器诊断区记录了解析器在解析 SQL 语句时遇到的错误信息,例如语法错误、解析树构建错误等。这些错误信息对于开发人员和管理员来说是非常有用的,可以帮助他们定位和修复 SQL 语句中的问题。
2)记录解析树和解析器状态:解析器诊断区还可以记录解析器的状态和解析树的结构。这些信息可以帮助开发人员了解 SQL 语句的结构,包括表、列、操作符等,从而更好地理解和调试 SQL 语句。
语句诊断区的功能:
1)收集执行过程中的错误信息:语句诊断区记录了执行 SQL 语句过程中的错误信息,包括执行计划错误、运行时错误等。这些错误信息对于故障排除和错误修复非常有用。
2)提供执行计划和性能统计信息:语句诊断区可以提供执行 SQL 语句的执行计划和性能统计信息,例如查询的执行时间、资源消耗、索引使用情况等。这些信息对于性能分析和查询优化非常有用。
联系:
1)数据共享:解析器诊断区和语句诊断区都是数据库系统内部的特定区域,用于存储和共享诊断信息。这些信息可以被数据库系统提供的工具和接口访问,以便开发人员和管理员进行诊断和调试操作。
2)诊断链:解析器诊断区和语句诊断区之间存在一定的关联。解析器诊断区提供了解析过程中的信息,包括解析树和错误信息。这些信息通常用于生成执行计划和优化查询。执行过程中的错误信息和执行计划则记录在语句诊断区中,可以帮助开发人员了解查询的执行情况和性能。
总的来说,解析器诊断区和语句诊断区在数据库系统中扮演着不同的角色,但它们共同提供了对 SQL 语句解析和执行过程的详细信息。这些信息可以帮助开发人员和管理员理解和优化数据库系统的行为,并进行故障排除和性能调优。
1.1.1 sql_parser() 函数
sql_parser 函数是 sql 语句解析入口函数,在该函数中通过调用 MYSQLparse 函数来完成 sql 解析的具体实现,并生成抽象语法树(ast)
功能:
1)调用MYSQLparse函数生成抽象语法树(ast)
2)调用make_sql_cmd函数根据ast生成SQL命令,即SQL命令字符串
bool THD::sql_parser() {
//ast根节点
Parse_tree_root *root = nullptr;
//==============1)解析sql语句并生成ast==============//
MYSQLparse(this, &root);
//==============2)根据解析树生成SQL命令==============//
make_sql_cmd(root);
return false;
}1.1.2 MYSQLparse函数
MYSQLparse 对应 sql_yacc.yy
使用 MYSQLparse 函数对 SQL 语句进行解析后生成对应语法树(ast)
以 insert 语句说明 MySQL 中抽象语法树的生成过程
insert 语句抽象语法树结构如下:
class PT_insert final : public Parse_tree_root {
const bool is_replace;//是否执行替换操作
PT_hint_list *opt_hints;//查询提示列表类,用于指导查询执行计划的生成和优化器的行为
const thr_lock_type lock_option; //线程锁定类型
const bool ignore;//是否忽略重复的插入
Table_ident *const table_ident;//表标识符,帮助数据库引擎准确地定位和操作指定的表
List<String> *const opt_use_partition;//表示一个可选的用于指定分区的字符串列表
PT_item_list *const column_list;//存储列名列表解析树
PT_insert_values_list *row_value_list;//存储插入的值列表解析树
/*-------------------------------------------------------------------------------
insert_query_expression 用于引用或存储包含在 INSERT 语句中的查询表达式
通过访问 insert_query_expression 成员变量,可以获取或操作与查询表达式相关的信息
例如查询的列、表、条件等。这个成员变量在解析和处理 INSERT 语句时起到关键作用
帮助解析器和执行器正确地处理和执行相应的查询操作
-------------------------------------------------------------------------------*/
PT_query_expression_body *insert_query_expression;
/*-------------------------------------------------------------------------------
通过访问 opt_values_table_alias 成员变量,可以获取或使用存储的字符串地址
例如用于命名查询中的表别名。这个成员变量的主要作用是提供一个不可更改的字符串地址
以便在查询处理过程中引用或使用该字符串
-------------------------------------------------------------------------------*/
const char *const opt_values_table_alias;
Create_col_name_list *const opt_values_column_list;//插入数据的值列表的列名列表
PT_item_list *const opt_on_duplicate_column_list;//出现重复记录时更新的列列表
PT_item_list *const opt_on_duplicate_value_list;//指定在出现重复记录时更新的值列表
public:
PT_insert(){ ... }
/*---------------------------------------------------------
make_cmd 函数会解析语法树中的各个部分,提取出相关的查询信息;
例如要查询的表、查询条件、排序规则等,并将这些信息设置到
Sql_cmd_select 对象中。然后,make_cmd 函数会返回创建的
Sql_cmd 对象的指针,以便在后续的执行阶段使用;
---------------------------------------------------------*/
Sql_cmd *make_cmd(THD *thd) override;
private:
bool has_query_block() const { return insert_query_expression != nullptr; }
};
1.1.3 make_sql_cmd() 函数
功能:
1)通过调用make_cmd函数在解析阶段根据语法树创建一个SQL命令(Sql_cmd)对象
bool LEX::make_sql_cmd(Parse_tree_root *parse_tree) {
//======1)通过调用make_cmd函数在解析阶段根据解析树创建一个SQL命令(Sql_cmd)对象======//
m_sql_cmd = parse_tree->make_cmd(thd);
}1.1.4 make_cmd() 函数
make_cmd() 是一个纯虚函数,在每一个语法树中都有相应的定义,如:select、insert、update...;下面的make_cmd()函数定义,以select为例。
Sql_cmd *PT_select_stmt::make_cmd(THD *thd) {
//解析和处理 SQL 语句的上下文对象
Parse_context pc(thd, thd->lex->current_query_block());
//SQL语句类型
thd->lex->sql_command = m_sql_command;
//对查询表达式进行上下文化处理,以便在执行查询时能够正确地解释和处理这些组件
if (m_qe->contextualize(&pc)) {
return nullptr;
}
//用于表示查询块内是否存在 INTO 子句
const bool has_into_clause_inside_query_block = thd->lex->result != nullptr;
//检查是否同时存在查询块内的 INTO 子句和 m_into 对象
if (has_into_clause_inside_query_block && m_into != nullptr) {
my_error(ER_MULTIPLE_INTO_CLAUSES, MYF(0));
return nullptr;
}
//对 m_into 对象进行安全上下文化处理的检查,并将结果存储到 m_into 对象中
if (contextualize_safe(&pc, m_into)) {
return nullptr;
}
//对查询表达式进行最终处理和准备,以便进行后续的执行或操作。
if (pc.finalize_query_expression()) return nullptr;
//检查是否存在特定情况下的警告和处理逻辑
if (m_into != nullptr && m_has_trailing_locking_clauses) {
// Example: ... INTO ... FOR UPDATE;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
} else if (has_into_clause_inside_query_block &&
thd->lex->unit->is_set_operation()) {
// Example: ... UNION ... INTO ...;
if (!m_qe->has_trailing_into_clause()) {
// Example: ... UNION SELECT * INTO OUTFILE 'foo' FROM ...;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
} else if (m_has_trailing_locking_clauses) {
// Example: ... UNION SELECT ... FROM ... INTO OUTFILE 'foo' FOR UPDATE;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
}
}
DBUG_EXECUTE_IF("ast", Query_term *qn =
pc.select->master_query_expression()->query_term();
std::ostringstream buf; qn->debugPrint(0, buf);
DBUG_PRINT("ast", ("\n%s", buf.str().c_str())););
//======1)创建一个用于表示SELECT语句的执行计划的 SQL 命令对象======//
if (thd->lex->sql_command == SQLCOM_SELECT)
return new (thd->mem_root) Sql_cmd_select(thd->lex->result);
//不是SELECT语句时,创建一个用于表示DO语句的执行计划的 SQL 命令对象
/*-----------------------------------------------------------------------------
DO语句是一种用于执行SQL语句的特殊类型的语句。
它通常用于执行一些存储过程、函数、变量赋值或其他数据库操作,而不是返回结果集。
因此,当处理DO语句时,虽然不涉及返回结果集,但仍然需要创建一个执行计划的SQL命令对象,
以便MySQL能够执行并跟踪这些操作的进度。
-----------------------------------------------------------------------------*/
else // (thd->lex->sql_command == SQLCOM_DO)
return new (thd->mem_root) Sql_cmd_do(nullptr);
}1.2 mysql_rewrite_query() 函数 ===> 查询重写入口函数

`mysql_rewrite_query()` 函数是 MySQL 数据库内部的一个函数,用于重写查询语句(select、delete、update、insert)。下面是该函数的具体功能和作用的概述:
功能:
1)调用rewrite_query函数实现重写查询语句
/*
1)调用rewrite_query函数实现重写查询语句
*/
void mysql_rewrite_query(THD *thd, Consumer_type type /*= Consumer_type::LOG */,
const Rewrite_params *params /*= nullptr*/) {
String rlb;//重写后的查询语句
DBUG_TRACE;
if (thd->lex->contains_plaintext_password ||
thd->lex->is_rewrite_required()) {
//======1)调用rewrite_query函数实现重写查询语句======//
rewrite_query(thd, type, params, rlb);
/*-----------------------------------------
将重写后的查询语句与thd中的查询语句进行交换
原因:rlb是局部变量,若不交换超出作用域
-----------------------------------------*/
if (rlb.length() > 0) thd->swap_rewritten_query(rlb);
// The previous rewritten query is in rlb now, which now goes out of scope.
}
}1.2.1 rewrite_query() 函数
函数 `bool rewrite_query` 是 MySQL 数据库中的一个函数,用于重写查询语句。下面是该函数的功能和作用的解释:
功能:
1)针对不同的 sql_command,创建相应类型的重写器对象,并将其赋值给 rw 智能指针
2)如果 rw 指针不为空(即有相应的重写器对象),则调用该对象的 rewrite 方法进行查询重写
bool rewrite_query(THD *thd, Consumer_type type, const Rewrite_params *params,
String &rlb) {
std::unique_ptr<I_rewriter> rw = nullptr;
//======1)针对不同的 sql_command 值,创建相应类型的重写器对象,并将其赋值给 rw 智能指针======//
switch (thd->lex->sql_command) {
case SQLCOM_GRANT:
rw.reset(new Rewriter_grant(thd, type, params));
break;
case SQLCOM_SET_PASSWORD:
rw.reset(new Rewriter_set_password(thd, type, params));
break;
...
}
//======2)如果 rw 指针不为空(即有相应的重写器对象),则调用该对象的 rewrite 方法进行查询重写======//
if (rw) rewrite = rw->rewrite(rlb);
return rewrite;
}1.2.2 rewrite() 函数
该函数用于重写与用户相关的查询语(主要负责查询重写前的安全工作)。它调用了多个重写函数来处理不同方面的用户相关信息,如用户权限、密码策略等。重写的目的是根据特定规则修改查询语句,以满足业务需求或确保数据的一致性。
功能:
1)处理查询重写前的全安工作(用户、密码的管理)
/*
1)处理查询重写前的全安工作(用户、密码的管理)
*/
bool Rewriter_user::rewrite(String &rlb) const {
//声明一个指向当前会话(m_thd)的语法分析器(LEX)的指针
LEX *lex = m_thd->lex;
//重写用户相关的查询语句,这可能包括创建、修改或删除用户的操作
rewrite_users(lex, &rlb);
//重写默认角色相关的查询语句,这可能涉及设置或更改用户的默认角色
rewrite_default_roles(lex, &rlb);
//重写 SSL 属性相关的查询语句,这可能涉及配置 SSL 连接的参数
rewrite_ssl_properties(lex, &rlb);
//重写用户资源相关的查询语句,这可能包括分配或管理用户的资源限制
rewrite_user_resources(lex, &rlb);
//重写密码过期相关的查询语句,这可能涉及检查或更改用户密码是否过期
rewrite_password_expired(lex, &rlb);
//重写账户锁定相关的查询语句,这可能涉及检查或更改用户账户的锁定状态
rewrite_account_lock(lex, &rlb);
//重写密码历史记录相关的查询语句,这可能涉及检查或管理用户密码的历史记录
rewrite_password_history(lex, &rlb);
//重写密码重用相关的查询语句,这可能涉及检查或管理用户密码的重用策略
rewrite_password_reuse(lex, &rlb);
//重写要求当前密码相关的查询语句,这可能涉及检查或管理用户是否需要提供当前密码进行操作
rewrite_password_require_current(lex, &rlb);
//重写账户锁定状态相关的查询语句,这可能涉及检查或更改用户账户的锁定状态
rewrite_account_lock_state(lex, &rlb);
//重写用户应用程序元数据相关的查询语句,这可能涉及管理用户在应用程序中的元数据信息
rewrite_user_application_user_metadata(lex, &rlb);
return false;
}1.3 mysql_execute_command() 函数
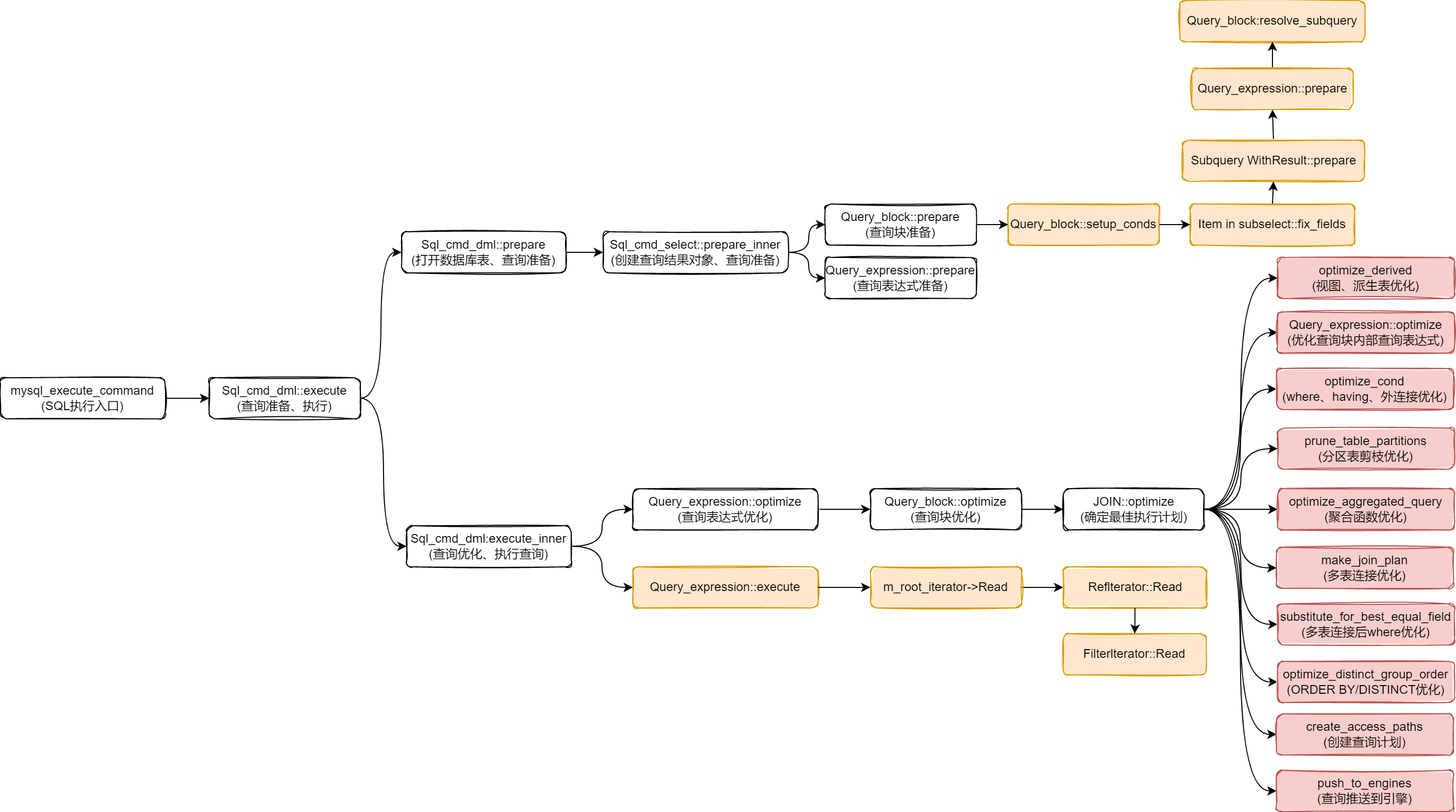
`mysql_execute_command()` 函数是 MySQL 数据库内部的一个函数,用于执行客户端发送的 SQL 命令(此时 SQL 命令已经通过解析器生成语法树,并经过 make_sql_cmd 函数将语法树转换为 SQL 命令字符串,最终将字符串存放于 m_sql_cmd 中)。下面是该函数的具体功能和作用的概述:
功能:
1)根据sql语句类型对sql进行解析、执行
int mysql_execute_command(THD *thd, bool first_level) {
//检查当前的 SQL 命令是否是允许的命令类型,如果不是允许的命令类型,会发出错误并回滚事务
if (thd->m_transactional_ddl.inited() && lex->sql_command != SQLCOM_COMMIT &&
lex->sql_command != SQLCOM_ROLLBACK &&
lex->sql_command != SQLCOM_BINLOG_BASE64_EVENT) {
binlog_gtid_end_transaction(thd);
return 1;
}
//数据库过滤器,保证只执行允许的数据库操作
if (unlikely(thd->slave_thread)) {
if (!check_database_filters(thd, thd->db().str, lex->sql_command)) {
binlog_gtid_end_transaction(thd);
return 0;
}
...
}
//收集和记录当前SQL语句的相关信息
Opt_trace_start ots(thd, all_tables, lex->sql_command, &lex->var_list,
thd->query().str, thd->query().length, nullptr,
thd->variables.character_set_client);
//======1)根据sql语句类型对sql进行解析、执行======//
switch (lex->sql_command) {
case SQLCOM_PREPARE: { ... }
case SQLCOM_EXECUTE: { ... }
case SQLCOM_DEALLOCATE_PREPARE: { ... }
...
case SQLCOM_UNINSTALL_COMPONENT:
case SQLCOM_SHUTDOWN:
case SQLCOM_ALTER_INSTANCE:
...
case SQLCOM_SELECT:
...
case SQLCOM_DO:
case SQLCOM_CALL:
case SQLCOM_CREATE_ROLE:
case SQLCOM_DROP_ROLE:
...
case SQLCOM_RESTART_SERVER:
case SQLCOM_CREATE_SRS:
case SQLCOM_DROP_SRS: {
assert(lex->m_sql_cmd != nullptr);
//======2)执行SQL语句======//
res = lex->m_sql_cmd->execute(thd);
break;
}
case SQLCOM_ALTER_USER: { ... }
default:
assert(0); /* Impossible */
my_ok(thd);
break;
}
return false;
}1.3.1 Sql_cmd_dml::execute() 函数
bool Sql_cmd_dml::execute(THD *thd) 函数通常是在数据库管理系统(DBMS)中处理数据操作语句(Data Manipulation Language,DML)的一个成员函数。具体功能和作用如下:
功能:
1)执行sql语句前的准备工作
2)执行sql语句操作
bool Sql_cmd_dml::execute(THD *thd) {
lex = thd->lex;
//======1)执行sql语句前的准备工作======//
prepare(thd);
//用于标记sql语句的执行已经开始
lex->set_exec_started();
/*------------------------------------------------------------------------------------
检查查询语句是否为空(是否包含有效的操作或内容)
如果不为空,则尝试锁定查询涉及的数据库表格。
锁定表格的目的是确保查询的一致性和完整性,防止其他会话对表格执行写入操作,从而避免数据冲突。
------------------------------------------------------------------------------------*/
if (!is_empty_query()) {
if (lock_tables(thd, lex->query_tables, lex->table_count, 0)) goto err;
}
//======2)执行sql语句操作======//
execute_inner(thd);
//在查询结束后,释放资源
cleanup();
return false;
}1.3.2 Sql_cmd_dml::prepare() 函数
Sql_cmd_dml::prepare(THD *thd) 函数是MySQL中用于DML(数据操作语言)类型的SQL命令(如INSERT、UPDATE、DELETE)执行准备阶段的函数。以下是该函数的功能和作用:
功能:
1)尝试打开与查询相关的数据库表
2)准备一个SELECT查询语句
bool Sql_cmd_dml::prepare(THD *thd) {
//======1)尝试打开与查询相关的数据库表======//
open_tables_for_query(thd, lex->query_tables,
needs_explicit_preparation() ? MYSQL_OPEN_FORCE_SHARED_MDL : 0);
//======2)准备一个SELECT查询语句======//
prepare_inner(thd);
//确定当前查询是否是一种正常的查询,例如普通的SELECT、INSERT、UPDATE或DELETE查询,而不是特殊的或非标准的查询
if (!is_regular()) {
if (save_cmd_properties(thd)) goto err;
lex->set_secondary_engine_execution_context(nullptr);
//设置某些标志、属性或状态,以表示一个对象或资源已经准备好被使用
set_prepared();
}
}1.3.2.1 Sql_cmd_select::prepare_inner() 函数
Sql_cmd_select::prepare_inner(THD *thd) 函数是MySQL中用于SELECT语句执行准备阶段的函数,和Sql_cmd_dml::prepare(THD *thd) 函数功能类似。
功能:
1)根据查询类型创建不同类型的查询结果对象
3)在查询优化前,对查询块进行准备工作
bool Sql_cmd_select::prepare_inner(THD *thd) {
//======1)根据查询类型创建不同类型的查询结果对象用于存储查询结果======//
result = new (thd->mem_root) Query_result_send();
//当查询不包含LIMIT子句时,可以启用SELECT LIMIT优化,以提高查询的性能和效率
if (!parameters->has_limit()) {
parameters->m_use_select_limit = true;//启用SELECT LIMIT优化
}
//======2)在查询优化前,对查询块进行准备工作======//
prepare(thd, nullptr);
//设置整个查询单元为已准备状态,表示查询已经完成了准备阶段
unit->set_prepared();
return false;
}查询单元与查询块的关系?
1)查询单元(Query Unit):
- 查询单元通常是指一个完整的SQL查询语句,可以是简单查询也可以是复杂查询。
- 它表示查询的最小单元,可以独立执行。
- 查询单元通常以分号(;)结尾,表示语句的结束。
- 一个查询单元可以包含多个查询块,如子查询、联接操作等。
- 例如,以下是两个不同的查询单元:
-- 第一个查询单元
SELECT * FROM customers;
-- 第二个查询单元
INSERT INTO orders (customer_id, order_date) VALUES (1, '2023-09-19');2)查询块(Query Block):
- 查询块是一个更小的结构,通常位于查询单元内部,用于执行特定的查询操作。
- 查询块通常包含在查询单元内,并与其他查询块协同工作以实现更复杂的查询逻辑。
- 查询块可以是SELECT语句中的子查询、联接操作、GROUP BY子句等。
- 一个查询单元可以包含一个或多个查询块。
- 例如,以下是一个查询单元包含两个查询块的示例:
-- 查询单元
SELECT * FROM (
-- 查询块 1: 子查询
SELECT product_name, price FROM products WHERE category = 'Electronics'
) AS electronics
INNER JOIN (
-- 查询块 2: 另一个子查询
SELECT customer_id, COUNT(*) AS order_count FROM orders GROUP BY customer_id
) AS order_counts
ON electronics.product_id = order_counts.product_id;1.3.2.2 Query_block::prepare() 函数
功能:
1)解析表和列信息:数据库系统需要知道要访问哪些表格以及哪些列将用于查询中的选择、连接和其他操作。
2)解析所有表达式:包括 WHERE子句中的条件、连接条件、GROUP BY子句中的分组条件、HAVING子句中的筛选条件、ORDER BY子句中的排序条件以及LIMIT子句中的行数限制。这是为了理解查询中的各种操作和约束条件。
3)递归准备所有子查询:子查询也是查询块的一部分,因此需要对它们进行相同的优化步骤,以确保整个查询的性能优化。
4)应用一些永久性转换的抽象语法树:数据库系统可能会应用一些永久性的查询转换,以改进查询的执行计划。包括将查询块转换为半连接(semi-join)操作、派生表(derived table)的转换、消除常数值和冗余子句(例如ORDER BY、GROUP BY)等。这些转换可以减少查询的复杂性,提高查询性能。
bool Query_block::prepare(THD *thd, mem_root_deque<Item *> *insert_field_list) {
DBUG_TRACE;
//特殊查询块的特殊处理
if (is_table_value_constructor) return prepare_values(thd);
//获取主查询表达式(包括SELECT子句、FROM子句、WHERE子句、GROUP BY子句、HAVING子句和ORDER BY子句等)
Query_expression *const unit = master_query_expression();
...
}1.3.2.3 Query_expression::prepare() 函数
功能:
1)准备查询表达式中的所有查询块包括 fake_query_block。如果查询是递归的,还会创建一个用于存储中间结果的具体化临时表。
/*
准备查询表达式中的所有查询块
*/
bool Query_expression::prepare(THD *thd, Query_result *sel_result,
mem_root_deque<Item *> *insert_field_list,
ulonglong added_options,
ulonglong removed_options) {1.3.3 Sql_cmd_dml::execute_inner () 函数
功能:
1)调用optimize函数执行查询优化操作
2)调用execute函数执行实际查询操作
bool Sql_cmd_dml::execute_inner(THD *thd) {
//======1)调用optimize函数执行查询优化操作======//
unit->optimize(thd, /*materialize_destination=*/nullptr,
/*create_iterators=*/true, /*finalize_access_paths=*/true);
//计算语句成本
accumulate_statement_cost(lex);
//执行辅助引擎的优化
optimize_secondary_engine(thd);
//======2)通过调用execute函数执行实际查询操作======//
if (unit->execute(thd)) return true;
return false;
}1.3.3.1 Query_expression::optimize() 函数
Query_expression::optimize 函数是用于优化查询表达式(Query Expression)的函数。这个函数通常在数据库查询优化的过程中调用,以下是其功能和作用:
功能:
1)优化查询表达式(优化所有查询代码块)
bool Query_expression::optimize(THD *thd, TABLE *materialize_destination,
bool create_iterators,
bool finalize_access_paths) {
//遍历sql语句的所有查询块
for (Query_block *query_block = first_query_block(); query_block != nullptr;
query_block = query_block->next_query_block()) {
thd->lex->set_current_query_block(query_block);
//在进行数据库查询时,为了获得更好的性能和效率,通常应该使用 "LIMIT" 子句来限制结果集的大小,以避免不必要的数据检索和处理
set_limit(thd, query_block); /* purecov: inspected */
//======1)优化当前查询块======//
optimize(thd, finalize_access_paths);
}
//创建逻辑执行计划
create_access_paths(thd);
//所有查询块都已经完成了优化
set_optimized();
//创建物理执行计划,并生成迭代器
m_root_iterator = CreateIteratorFromAccessPath(
thd, m_root_access_path, join, /*eligible_for_batch_mode=*/true);
return false;
}相关定义:
1)查询表达式:查询表达式是一个由一个或多个查询块组成的结构,用于描述一个数据库查询的整体操作。它可以包含多个查询块,这些查询块可以使用集合操作(如UNION、INTERSECT、EXCEPT)来组合结果。
查询表达式示例:
SELECT column1, column2
FROM table1
UNION
SELECT column3, column4
FROM table2;
这个查询表达式包含两个查询块,第一个查询块是 SELECT column1, column2 FROM table1,第二个查询块是 SELECT column3, column4 FROM table2。它们通过 UNION 操作符组合在一起,表示取两个查询块的结果的并集。
2)查询块:查询块代表了一个独立的查询单元,它描述了一个具体的操作,如从一个表格中检索数据。一个查询块可以包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等子句,用于指定操作的详细条件。
查询块示例:
SELECT column1, column2
FROM table1
WHERE condition = 'value'
ORDER BY column1;1.3.3.2 Query_block::optimize() 函数
bool Query_block::optimize(THD *thd, bool finalize_access_paths) 函数是用于优化查询块(Query Block)的函数。这个函数通常在数据库查询的查询优化阶段调用。以下是它的功能和作用:
功能:
1)确定最佳的执行计划
2)遍历查询表达式,对每个尚未优化的表达式执行优化操作
bool Query_block::optimize(THD *thd, bool finalize_access_paths) {
/*
锁定当前线程的查询计划。这通常用于多线程环境中,以确保在某个线程修改查询计划时,
其他线程不能同时修改或访问查询计划,从而防止竞争条件和数据一致性问题。
*/
thd->lock_query_plan();
//======1)确定最佳的执行计划======//
optimize(finalize_access_paths);
//======2)遍历查询表达式,对每个尚未优化的表达式执行优化操作======//
for (Query_expression *query_expression = first_inner_query_expression();
query_expression;
query_expression = query_expression->next_query_expression()) {
if (!query_expression->is_optimized() &&
query_expression->optimize(thd, /*materialize_destination=*/nullptr,
/*create_iterators=*/false,
/*finalize_access_paths=*/true))
return true;
}
return false;
}1.3.3.3 JOIN::optimize()函数
bool JOIN::optimize(bool finalize_access_paths) 函数是用于优化 JOIN 操作并确定最佳执行计划。
功能:
1)把一个查询块优化成查询计划
2)主要优化阶段:
# 逻辑优化
--外部到内部连接转换
--等式变换、常量传递
--分区剪枝,旨在减少需要扫描的分区数量
--在没有明确的 GROUP BY 子句的情况下,对于聚合函数 COUNT()、MIN() 和 MAX() 的优化处理
--排序优化
# 针对表的连接顺序和访问路径进行成本优化 ---make_join_plan()
# 在表连接之后,对查询执行计划进行进一步的优化和调整
--从查询的 WHERE 子句和表连接的条件中生成最优的表条件
--在查询计划中插入外连接(Outer Join)的保护条件
--在确定表条件后多次调整数据访问方法
--优化ORDER BY/DISTINCT
# 代码生成
--设置数据访问功能
--尝试优化sorting/distinct
--设置临时表用于分组和/或排序
bool JOIN::optimize(bool finalize_access_paths) {
//阻止重复优化
if (optimized) return false;
if (query_block->get_optimizable_conditions(thd, &where_cond, &having_cond))
return true;
set_optimized();
/*
"叶子表" 是指在查询块(query block)中直接参与查询操作的基本表格,
而不包括子查询、派生表或其他复杂的表达式。叶子表是查询的最底层的数据源,它们存储了实际的数据。
*/
//======1逻辑优化======//
for (TABLE_LIST *tl = query_block->leaf_tables; tl; tl = tl->next_leaf) {
//=====1.1)视图或派生表优化======//
if (tl->is_view_or_derived()) {
if (tl->optimize_derived(thd)) return true;
}
//======1.2)优化查询块内部查询表达式(子查询)======//
if (thd->lex->using_hypergraph_optimizer) {
for (Query_expression *unit = query_block->first_inner_query_expression();
unit; unit = unit->next_query_expression()) {
if (!unit->is_optimized() &&
unit->optimize(thd, /*materialize_destination=*/nullptr,
/*create_iterators=*/false,
/*finalize_access_paths=*/false))
}
}
//======1.3)where表达式、外连接的优化======//
if (where_cond || query_block->outer_join) {
if (optimize_cond(thd, &where_cond, &cond_equal,
&query_block->top_join_list, &query_block->cond_value)) {
...
}
}
//======1.4)having表达式优化======//
if (having_cond) {
if (optimize_cond(thd, &having_cond, &cond_equal, nullptr,
&query_block->having_value)) {
...
}
}
//======1.5)分区表剪枝,旨在减少需要扫描的分区数量======//
if (query_block->partitioned_table_count && prune_table_partitions()) {
...
}
//======1.6)在没有明确的 GROUP BY 子句的情况下,对于聚合函数 COUNT()、MIN() 和 MAX() 的优化处理======//
if (tables_list && implicit_grouping &&
!(query_block->active_options() & OPTION_NO_CONST_TABLES)) {
//优化聚合查询
if (optimize_aggregated_query(thd, query_block, *fields, where_cond,
&outcome)) {
...
}
//在没有相关表的情况下进行查询优化和准备执行计划
if (tables_list == nullptr) {
if (make_tmp_tables_info()) return true;
count_field_types(query_block, &tmp_table_param, *fields, false, false);
//创建执行计划
create_access_paths();
return false;
}
/*
在使用超图优化器的情况下,执行一系列优化和计划操作,
包括移除 IN-to-EXISTS 谓词、查找最佳查询计划、最终化查询计划等。
*/
if (thd->lex->using_hypergraph_optimizer) {
//从 WHERE 条件中移除 IN-to-EXISTS 谓词
Item *where_cond_no_in2exists =
remove_in2exists_conds(thd, where_cond, /*copy=*/true);
//从 HAVING 条件中移除 IN-to-EXISTS 谓词
Item *having_cond_no_in2exists =
remove_in2exists_conds(thd, having_cond, /*copy=*/true);
//查找当前查询块的最佳查询计划
m_root_access_path = FindBestQueryPlan(thd, query_block, trace_ptr);
if (finalize_access_paths && m_root_access_path != nullptr) {
if (FinalizePlanForQueryBlock(thd, query_block)) {
return true;
}
}
//查询计划已准备就绪
set_plan_state(PLAN_READY);
}
// ----------------------------------------------------------------------------
// All of this is never called for the hypergraph join optimizer!
// ----------------------------------------------------------------------------
//======2)对表的连接顺序和访问路径进行成本优化======//
make_join_plan();
//======3)在表连接之后,对查询执行计划进行进一步的优化和调整======//
//======3.1)检查是否存在 WHERE 子句,如果存在则尝试对其进行优化======//
if (where_cond) {
where_cond =
substitute_for_best_equal_field(thd, where_cond, cond_equal, map2table);
}
//======3.2)遍历连接操作中的一系列表,尝试优化连接条件======//
for (uint i = const_tables; i < tables; ++i) {
if (tab->position() && tab->join_cond()) {
tab->set_join_cond(substitute_for_best_equal_field(
thd, tab->join_cond(), tab->cond_equal, map2table));
}
}
//======3.3)优化ORDER BY/DISTINCT======//
optimize_distinct_group_order();
/*
检查是否有全文本搜索函数存在,并在存在时尝试对相关查询进行性能优化。
这有助于提高全文本搜索的效率和准确性,特别是在处理大量文本数据时。
*/
if (query_block->has_ft_funcs() && optimize_fts_query()) return true;
//处理 HAVING 子句中的条件,包括条件的简化、检查是否永远不满足以及处理零行结果的情况
if (having_cond && !having_cond->has_aggregation() && (const_tables > 0)) {
//移除having中的等值条件
if (remove_eq_conds(thd, having_cond, &having_cond,
&query_block->having_value)) {
...
}
}
//涉及全文搜索列时进行聚合操作
if (!need_tmp_before_win && implicit_grouping &&
primary_tables - const_tables == 1 && order.empty() &&
best_ref[const_tables]->table_ref->is_fulltext_searched()) {
for (Item *item : VisibleFields(*fields)) {
need_tmp_before_win |=
contains_function_of_type(item, Item_func::FT_FUNC);
if (need_tmp_before_win) break;
}
}
//======4)设置临时表用于分组和排序======//
/*
Check if we need to create a temporary table prior to any windowing.
(1) If there is ROLLUP, which happens before DISTINCT, windowing and ORDER
BY, any of those clauses needs the result of ROLLUP in a tmp table.
Rows which ROLLUP adds to the result are visible only to DISTINCT,
windowing and ORDER BY which we handled above. So for the rest of
conditions ((2), etc), we can do as if there were no ROLLUP.
(2) If all tables are constant, the query's result is guaranteed to have 0
or 1 row only, so all SQL clauses discussed below (DISTINCT, ORDER BY,
GROUP BY, windowing, SQL_BUFFER_RESULT) are useless and need no tmp
table.
(3) If there is GROUP BY which isn't resolved by using an index or sorting
the first table, we need a tmp table to compute the grouped rows.
GROUP BY happens before windowing; so it is a pre-windowing tmp
table.
(4) (5) If there is DISTINCT, or ORDER BY which isn't resolved by using an
index or sorting the first table, those clauses need an input tmp table.
If we have windowing, as those clauses are used after windowing, they can
use the last window's tmp table.
(6) If there are different ORDER BY and GROUP BY orders, ORDER BY needs an
input tmp table, so it's like (5).
(7) If the user wants us to buffer the result, we need a tmp table. But
windowing creates one anyway, and so does the materialization of a derived
table.
See also the computation of Window::m_short_circuit,
where we make sure to create a tmp table if the clauses above want one.
(8) If the first windowing step needs sorting, filesort() will be used; it
can sort one table but not a join of tables, so we need a tmp table
then. If GROUP BY was optimized away, the pre-windowing result is 0 or 1
row so doesn't need sorting.
*/
if (rollup_state != RollupState::NONE && // (1)
(select_distinct || has_windows || !order.empty()))
need_tmp_before_win = true;
if (!plan_is_const()) // (2)
{
if ((!group_list.empty() && !simple_group) || // (3)
(!has_windows && (select_distinct || // (4)
(!order.empty() && !simple_order) || // (5)
(!group_list.empty() && !order.empty()))) || // (6)
((query_block->active_options() & OPTION_BUFFER_RESULT) &&
!has_windows &&
!(query_expression()->derived_table &&
query_expression()
->derived_table->uses_materialization())) || // (7)
(has_windows && (primary_tables - const_tables) > 1 && // (8)
m_windows[0]->needs_sorting() && !group_optimized_away))
need_tmp_before_win = true;
}
//分配查询执行计划
alloc_qep(tables);
//创建并初始化连接读取信息
make_join_readinfo(this, no_jbuf_after);
//创建并初始化临时表信息
make_tmp_tables_info();
//创建执行计划
create_access_paths();
//优化查询的执行,将部分查询推送到存储引擎来提高执行效率
if (push_to_engines()) return true;
//查询计划可视化
set_plan_state(PLAN_READY);
return false;
}2. AST 相关数据结构
2.1 AST 节点基类
class Parse_tree_root {
Parse_tree_root(const Parse_tree_root &) = delete;
void operator=(const Parse_tree_root &) = delete;
protected:
virtual ~Parse_tree_root() = default;
Parse_tree_root() = default;
public:
virtual Sql_cmd *make_cmd(THD *thd) = 0;
};以下是对每一行语句的详细解析:
(1)Parse_tree_root(const Parse_tree_root &) = delete:是一个删除的拷贝构造函数声明。使用 = delete 可以防止该类的对象被拷贝,以确保对象的唯一性。这在某些情况下可能是有意义的,例如对于包含资源管理的类,我们可能不希望资源被意外地共享或释放。
(2)void operator=(const Parse_tree_root &) = delete:是一个删除的赋值运算符重载声明。同样地,使用 = delete 可以防止该类的对象被赋值。
(3)protected:关键字表示以下成员在派生类中可访问,但在类外部不可访问。
(4)virtual ~Parse_tree_root() = default:是一个默认的虚析构函数声明。虚析构函数用于在删除派生类的对象时正确地释放资源。= default 表示使用默认的析构函数实现。
(5)Parse_tree_root() = default:是一个默认构造函数声明。= default 表示使用默认的构造函数实现。
(6)public:关键字表示以下成员在类外部可访问。
(7)virtual Sql_cmd *make_cmd(THD *thd) = 0:是一个纯虚函数声明,没有实现。纯虚函数在基类中声明,要求派生类提供实现。这里的 make_cmd 函数返回一个指向 Sql_cmd 类型对象的指针,并接受一个 THD 类型的指针作为参数。
2.2 INSERT 语句语法树
PT_insert final(parse_tree_nodes.h)是一种数据结构,与 sql_yacc.yy 文件中 insert_stmt 产生式下 NEW_PTN PT_insert 结构相对应。换句话说,在书写语法解析器规则时,每一条产生式后面的动作部分已经使用了该数据结构,并对 ast 进行定义与构建。
所谓语法树也即是将解析器解析出来的每一部分分别存储到 PT_insert final 数据结构中,即 insert 语句的 PT_insert final = ast
辅助工具:
文献一:mysql官方文档一
文献二:mysql官方文档二
class PT_insert final : public Parse_tree_root {
const bool is_replace;//是否执行替换操作
PT_hint_list *opt_hints;//查询提示列表类,用于指导查询执行计划的生成和优化器的行为
const thr_lock_type lock_option; //线程锁定类型
const bool ignore;//是否忽略重复的插入
Table_ident *const table_ident;//表标识符,帮助数据库引擎准确地定位和操作指定的表
List<String> *const opt_use_partition;//表示一个可选的用于指定分区的字符串列表
PT_item_list *const column_list;//存储列名列表解析树
/*-------------------------------------------------------------------------------
在查询解析的过程中,MySQL 的查询处理器会使用 PT_insert_values_list 类来解析和处理
INSERT 语句中的值列表。它可以将值列表中的每个值解析为相应的数据类型,并在内部进行处理
-------------------------------------------------------------------------------*/
PT_insert_values_list *row_value_list;//存储插入的值列表解析树
/*-------------------------------------------------------------------------------
insert_query_expression 用于引用或存储包含在 INSERT 语句中的查询表达式
通过访问 insert_query_expression 成员变量,可以获取或操作与查询表达式相关的信息
例如查询的列、表、条件等。这个成员变量在解析和处理 INSERT 语句时起到关键作用
帮助解析器和执行器正确地处理和执行相应的查询操作
-------------------------------------------------------------------------------*/
PT_query_expression_body *insert_query_expression;
/*-------------------------------------------------------------------------------
通过访问 opt_values_table_alias 成员变量,可以获取或使用存储的字符串地址
例如用于命名查询中的表别名。这个成员变量的主要作用是提供一个不可更改的字符串地址
以便在查询处理过程中引用或使用该字符串
-------------------------------------------------------------------------------*/
const char *const opt_values_table_alias;
Create_col_name_list *const opt_values_column_list;//插入数据的值列表的列名列表
PT_item_list *const opt_on_duplicate_column_list;//出现重复记录时更新的列列表
PT_item_list *const opt_on_duplicate_value_list;//指定在出现重复记录时更新的值列表
public:
PT_insert(){ ... }
/*---------------------------------------------------------
make_cmd 函数会解析语法树中的各个部分,提取出相关的查询信息;
例如要查询的表、查询条件、排序规则等,并将这些信息设置到
Sql_cmd_select 对象中。然后,make_cmd 函数会返回创建的
Sql_cmd 对象的指针,以便在后续的执行阶段使用;
---------------------------------------------------------*/
Sql_cmd *make_cmd(THD *thd) override;
private:
bool has_query_block() const { return insert_query_expression != nullptr; }
};
2.2.1 PT_hint_list
该类主要用于存储解析过程之后得到的提示列表,以指导查询优化器如何处理查询块。
class PT_hint_list : public Parse_tree_node {
typedef Parse_tree_node super; //起别名
Mem_root_array<PT_hint *> hints; //动态数组
public:
explicit PT_hint_list(MEM_ROOT *mem_root) : hints(mem_root) {}
/*--------------------------------------------------------------------------------------------------
Function handles list of the hints we get after parse procedure.
它可能会对这些提示进行进一步的操作、分析或应用,以便在后续的查询处理过程中使用这些提示信息。
It also creates query block hint object(Opt_hints_qb) if it does not exists.
提示信息中包括查询块提示。查询块提示是一种指导查询优化器如何处理查询块(例如,子查询、连接等)的提示信息。
这些提示可以包含有关查询块的优化目标、执行顺序、连接算法等信息。
如果在解析过程中得到的提示列表中不存在查询块提示对象,那么该函数会创建一个新的查询块提示对象。
Parse_context *pc:解析上下文的对象
--------------------------------------------------------------------------------------------------*/
bool contextualize(Parse_context *pc) override;
bool push_back(PT_hint *hint) { return hints.push_back(hint); }
};解析上下文对象(Parse_context)是一个数据结构,用于存储和管理解析过程中的各种信息和状态。
解析上下文对象通常包含以下内容:
1)SQL 语句:解析上下文对象中存储了待解析的 SQL 语句文本。
2)解析器状态:解析上下文对象中可以记录解析器的当前状态,例如解析位置、解析错误等。
3)解析结果:解析上下文对象可能包含解析过程中生成的解析结果,如语法树、抽象语法树等。
4)数据字典信息:解析上下文对象中可能包含了数据库的元数据信息,例如表结构、列属性等。
5)错误处理:解析上下文对象可能包含用于处理解析错误的相关信息,如错误代码、错误消息等。
通过解析上下文对象,解析器可以跟踪解析的进度、处理解析过程中的错误,并生成相应的解析结果。解析上下文对象在解析过程中起着重要的作用,它为解析器提供了一个存储和管理解析相关信息的容器,使得解析器能够有效地处理和分析 SQL 语句。
2.2.2 thr_lock_type
在 MySQL 8.0.31 中,`thr_lock_type` 是一个枚举类型,用于表示线程锁定类型。
线程锁定类型用于控制在执行数据库操作时对表进行的锁定行为。MySQL 支持不同的锁定类型,每种类型都具有不同的特性和适用场景。
`thr_lock_type` 枚举类型定义了以下几种线程锁定类型:
(1)`TL_IGNORE`: 表示忽略锁定。在执行数据库操作时,不对表进行任何锁定。这意味着其他线程可以同时对表进行读取和写入操作,可能会导致并发冲突和数据不一致。
(2)`TL_READ_NO_INSERT`: 表示对表进行读取锁定,不允许其他线程对表进行写入操作。其他线程可以同时对表进行读取操作,但不能进行写入操作。
(3)`TL_READ_ALLOW_INSERT`: 表示对表进行读取锁定,并允许其他线程在锁定期间进行插入操作。其他线程可以同时对表进行读取和插入操作,但不能进行更新或删除操作。
(4)`TL_WRITE_ALLOW_INSERT`: 表示对表进行写入锁定,并允许其他线程在锁定期间进行插入操作。其他线程可以同时对表进行写入和插入操作,但不能进行读取、更新或删除操作。
(5)`TL_WRITE_CONCURRENT_INSERT`: 表示对表进行写入锁定,并允许其他线程在锁定期间进行并发插入操作。其他线程可以同时对表进行写入和并发插入操作,但不能进行读取、更新或删除操作。
通过指定适当的线程锁定类型,可以控制对表的并发访问和修改。选择合适的锁定类型可以提高并发性能和数据一致性。
需要注意的是,线程锁定类型在不同的数据库操作和场景中具有不同的应用。具体使用哪种锁定类型取决于具体的需求和业务逻辑。
2.2.3 Table_ident
表标识符(Table Identifier)是在数据库中用于唯一标识表的名称或别名的标识符。在查询语句中,表标识符用于指定要查询的具体表。
在 MySQL 中,表标识符可以是以下形式之一:
- 表名:表标识符可以直接使用表的名称来表示,例如 `SELECT * FROM my_table;` 中的 `my_table` 就是表标识符。
- 别名:在查询语句中,可以使用 `AS` 关键字给表指定一个别名,以便在后续的查询中使用该别名代替表名。例如 `SELECT * FROM my_table AS t;` 中的 `t` 就是表标识符。
表标识符在查询语句中起到了重要的作用,它们帮助数据库引擎准确地定位和操作指定的表。通过使用表标识符,可以避免歧义和命名冲突,并且可以简化复杂查询语句的书写和理解。
在 MySQL 8.0.31 中,Table_ident 是一个类,用于表示表标识符(table identifier)。它在查询处理过程中处理和解析表标识符,提供了一些功能和属性来操作和管理表标识符。
- 表函数(Table Function)是一种能够返回表作为结果的函数。它接受输入参数,并生成一个表作为输出。
- 派生表是通过在查询语句中使用子查询来创建的临时表。
class Table_ident {
...
构造部分省略
...
// True if we can tell from syntax that this is a table function.
//如果从语法上可以确定这是一个表函数,则返回真值(True)
bool is_table_function() const { return (table_function != nullptr); }
// True if we can tell from syntax that this is an unnamed derived table.
如果我们可以从语法上确定这是一个未命名的派生表(Derived Table),则返回True
bool is_derived_table() const { return sel; }
//将当前的数据库连接切换到指定的数据库
void change_db(const char *db_name) {
db.str = db_name;
db.length = strlen(db_name);
}
};Table_ident 类的具体功能可能包括:
(1)表名存储:Table_ident 类可能包含一个属性来存储表名,用于表示特定的表标识符。
(2)表别名:Table_ident 类可能支持存储和管理表的别名,以便在查询中可以使用别名来引用表。
(3)解析和验证:Table_ident 类可能提供方法来解析和验证表标识符,确保它们符合正确的语法和命名规则。
(4)元数据检索:Table_ident 类可能与数据库的元数据系统交互,以获取表的相关信息,如列属性、索引信息等。
(5)表标识符处理:Table_ident 类可能提供方法来处理表标识符,如拼接、分割、规范化等操作。
(6)错误处理:Table_ident 类可能具有处理解析和验证过程中的错误的机制,例如报告错误、生成错误消息等。
需要注意的是,具体的功能和属性可能会因 MySQL 版本的不同而有所差异。以上列出的功能仅是一些可能的功能,具体取决于 MySQL 版本和实现。要了解更多关于 Table_ident 类的具体功能和用法,建议查阅 MySQL 官方文档或相关的源代码文档。
2.2.4 opt_use_partition
在 MySQL 中,INSERT 语句用于向表中插入新的行。对于分区表(Partitioned Table),可以通过 INSERT 语句将数据插入到指定的分区中。而 opt_use_partition 就是用来指定要插入数据的目标分区的。
opt_use_partition 是一个指向 List 类型对象的指针。List 是一个字符串列表,可以存储多个字符串元素。在这个特定的情况下,每个字符串表示一个分区的名称。
通过使用 opt_use_partition,可以在 INSERT 语句中指定要插入数据的目标分区。例如,可以将数据插入到特定的时间范围分区或者根据其他条件选择合适的分区。
这个成员变量的存在允许开发人员在 PT_insert 类的对象中指定要使用的分区,以便在解析和执行 INSERT 语句时将数据插入到指定的分区中。它提供了一种灵活的方式来处理分区表的数据插入操作。
2.3 UPDATE 语句语法树
class PT_update : public Parse_tree_root {
PT_with_clause *m_with_clause;//存储 WITH 子句的解析树
PT_hint_list *opt_hints;//存储可能存在的查询提示列表
thr_lock_type opt_low_priority;//线程锁定类型
bool opt_ignore;//是否忽略重复更新
Mem_root_array_YY<PT_table_reference *> join_table_list;//存储连接表解析树
PT_item_list *column_list;//存储列明列表解析树
PT_item_list *value_list;//存储值列表解析树
Item *opt_where_clause;//存储可能存在的where子句解析树
PT_order *opt_order_clause;//存储可能存在的erder子句解析树
Item *opt_limit_clause;//存储可能存在的limit子句解析树
public:
PT_update():{...}
/*---------------------------------------------------------
make_cmd 函数会解析语法树中的各个部分,提取出相关的查询信息;
例如要查询的表、查询条件、排序规则等,并将这些信息设置到
Sql_cmd_select 对象中。然后,make_cmd 函数会返回创建的
Sql_cmd 对象的指针,以便在后续的执行阶段使用;
---------------------------------------------------------*/
Sql_cmd *make_cmd(THD *thd) override;
};2.4 DELETE 语句语法树
class PT_delete final : public Parse_tree_root {
private:
PT_with_clause *m_with_clause;//存储 WITH 子句的解析树
PT_hint_list *opt_hints;//存储可能存在的查询提示列表
const int opt_delete_options;//用于存储删除选项
Table_ident *table_ident;//表示要删除的表标识符
const char *const opt_table_alias;//存储可能存在的表的别名
Mem_root_array_YY<Table_ident *> table_list;//存储多个表的标识符
List<String> *opt_use_partition;//存储可能存在的分区列表
Mem_root_array_YY<PT_table_reference *> join_table_list;//存储连接表的解析树
Item *opt_where_clause;//存储可能存在的 WHERE 子句的解析树
PT_order *opt_order_clause;//存储可能存在的 order 子句解析树
Item *opt_delete_limit_clause;//存储可能存在的删除限制子句的解析树
SQL_I_List<TABLE_LIST> delete_tables;//存储要删除的表的列表
public:
// single-table DELETE node constructor:
PT_delete()
: {}
// multi-table DELETE node constructor:
PT_delete()
: {}
/*---------------------------------------------------------
make_cmd 函数会解析语法树中的各个部分,提取出相关的查询信息;
例如要查询的表、查询条件、排序规则等,并将这些信息设置到
Sql_cmd_select 对象中。然后,make_cmd 函数会返回创建的
Sql_cmd 对象的指针,以便在后续的执行阶段使用;
---------------------------------------------------------*/
Sql_cmd *make_cmd(THD *thd) override;
private:
//用于判断是否为多表删除操作,通过检查 table_ident 和 table_list 是否为空来确定
bool is_multitable() const {}
//用于向 table_list 添加表标识符
bool add_table(Parse_context *pc, Table_ident *table);
};2.5 SELECT 语句语法树
class PT_select_stmt : public Parse_tree_root {
typedef Parse_tree_root super;//定义了`super`作为`Parse_tree_root`的别名
public:
PT_select_stmt()
: {}
explicit PT_select_stmt()
: {}
//基类中声明,派生类中定义实现---用于构造一个执行 sql 语句的 Sql_cmd 对象
Sql_cmd *make_cmd(THD *thd) override;
private:
/*------------------------------------------------------------
m_sql_command 的作用是存储 SQL 命令的类型;
通过这个变量,可以确定当前语法树节点表示的是哪种类型的 SQL 命令;
------------------------------------------------------------*/
enum_sql_command m_sql_command;
/*-------------------------------------------------------------
m_qe 用于存储 SQL 查询表达式的语法树节点;
它包含了查询的各个部分,如 SELECT 子句、FROM 子句、WHERE 子句等;
-------------------------------------------------------------*/
PT_query_expression_body *m_qe;
/*--------------------------------------------------------------------------------
PT_into_destination 是一个类,表示 SQL 查询中的 INTO 子句的目标;
INTO 子句用于指定查询结果的存储位置,例如将结果插入到表中或将结果写入文件中。
成员变量 m_into 的作用是存储 INTO 子句的目标信息;
通过这个指针,可以访问和操作 INTO 子句的相关属性,例如目标表的名称、目标文件的路径等;
--------------------------------------------------------------------------------*/
PT_into_destination *m_into;
/*------------------------------------------------------------------------------------------
m_has_trailing_locking_clauses 的功能和作用是指示当前查询语句是否包含尾部锁定子句;
尾部锁定子句是在 SQL 查询语句的末尾指定的锁定条件,用于控制对查询结果的并发访问。
通过检查 m_has_trailing_locking_clauses 的值,可以确定查询语句是否包含尾部锁定子句。
如果值为 true,则表示查询语句包含尾部锁定子句;如果值为 false,则表示查询语句不包含尾部锁定子句。
------------------------------------------------------------------------------------------*/
const bool m_has_trailing_locking_clauses;
};2.5.1 PT_query_expression_body
class PT_query_expression_body : public Parse_tree_node {
public:
virtual bool is_set_operation() const = 0;
virtual bool can_absorb_order_and_limit(bool order, bool limit) const = 0;
virtual bool has_into_clause() const = 0;
virtual bool has_trailing_into_clause() const = 0;
virtual bool is_table_value_constructor() const = 0;
virtual PT_insert_values_list *get_row_value_list() const = 0;
};(1)is_set_operation() 函数
- 功能:函数用于确定查询表达式是否执行集合操作。集合操作是指对两个或多个查询结果进行组合的操作,例如 UNION、INTERSECT 和 EXCEPT。这些操作可以将多个查询的结果合并为一个结果集。
- 作用:通过调用 is_set_operation() 函数,可以判断查询表达式是否执行集合操作,以便在程序中根据不同的查询类型执行相应的逻辑。例如,如果查询表达式是一个集合操作,可以采取特定的处理方式来处理结果集的组合和去重。
(2)can_absorb_order_and_limit() 函数
- 功能:函数用于确定查询表达式是否能够将传入的 ORDER BY 和 LIMIT 子句吸收并应用于自身。它根据传入的布尔值 order 和 limit 来判断是否存在 ORDER BY 和 LIMIT 子句。
- 作用:通过调用 can_absorb_order_and_limit() 函数,可以判断查询表达式是否能够处理 ORDER BY 和 LIMIT 子句。如果查询表达式能够吸收这两个子句,意味着它具有相应的功能和逻辑来处理排序和结果集限制。这样,可以在程序中根据查询表达式的能力来决定是否需要应用 ORDER BY 和 LIMIT 子句。
(3)has_into_clause() 函数
- 功能: 函数用于确定查询表达式是否包含 INTO 子句。INTO 子句用于指定查询结果的目标存储位置,例如将查询结果插入到一个表中或将结果保存到一个变量中。
- 作用:通过调用 has_into_clause() 函数,可以判断查询表达式是否包含 INTO 子句,以便在程序中根据查询的结果处理方式进行相应的逻辑。如果查询包含 INTO 子句,可能需要执行特定的操作来处理查询结果的存储或后续处理。
2.5.2 make_cmd() 函数
make_cmd 函数会解析语法树中的各个部分,提取出相关的查询信息,例如要查询的表、查询条件、排序规则等,并将这些信息设置到 Sql_cmd 对象中。然后,make_cmd 函数会返回创建的 Sql_cmd 对象的指针,以便在后续的执行阶段使用(在 make_sql_cmd 函数中被调用)。
Sql_cmd *PT_select_stmt::make_cmd(THD *thd) {
//解析和处理 SQL 语句的上下文对象
Parse_context pc(thd, thd->lex->current_query_block());
//SQL语句类型
thd->lex->sql_command = m_sql_command;
//对查询表达式进行上下文化处理,以便在执行查询时能够正确地解释和处理这些组件
if (m_qe->contextualize(&pc)) {
return nullptr;
}
//用于表示查询块内是否存在 INTO 子句
const bool has_into_clause_inside_query_block = thd->lex->result != nullptr;
//检查是否同时存在查询块内的 INTO 子句和 m_into 对象
if (has_into_clause_inside_query_block && m_into != nullptr) {
my_error(ER_MULTIPLE_INTO_CLAUSES, MYF(0));
return nullptr;
}
//对 m_into 对象进行安全上下文化处理的检查,并将结果存储到 m_into 对象中
if (contextualize_safe(&pc, m_into)) {
return nullptr;
}
//对查询表达式进行最终处理和准备,以便进行后续的执行或操作。
if (pc.finalize_query_expression()) return nullptr;
//检查是否存在特定情况下的警告和处理逻辑
if (m_into != nullptr && m_has_trailing_locking_clauses) {
// Example: ... INTO ... FOR UPDATE;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
} else if (has_into_clause_inside_query_block &&
thd->lex->unit->is_set_operation()) {
// Example: ... UNION ... INTO ...;
if (!m_qe->has_trailing_into_clause()) {
// Example: ... UNION SELECT * INTO OUTFILE 'foo' FROM ...;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
} else if (m_has_trailing_locking_clauses) {
// Example: ... UNION SELECT ... FROM ... INTO OUTFILE 'foo' FOR UPDATE;
push_warning(thd, ER_WARN_DEPRECATED_INNER_INTO);
}
}
DBUG_EXECUTE_IF("ast", Query_term *qn =
pc.select->master_query_expression()->query_term();
std::ostringstream buf; qn->debugPrint(0, buf);
DBUG_PRINT("ast", ("\n%s", buf.str().c_str())););
//======1)创建一个用于表示SELECT语句的执行计划的 SQL 命令对象======//
if (thd->lex->sql_command == SQLCOM_SELECT)
return new (thd->mem_root) Sql_cmd_select(thd->lex->result);
//不是SELECT语句时,创建一个用于表示DO语句的执行计划的 SQL 命令对象
/*-----------------------------------------------------------------------------
DO语句是一种用于执行SQL语句的特殊类型的语句。
它通常用于执行一些存储过程、函数、变量赋值或其他数据库操作,而不是返回结果集。
因此,当处理DO语句时,虽然不涉及返回结果集,但仍然需要创建一个执行计划的SQL命令对象,
以便MySQL能够执行并跟踪这些操作的进度。
-----------------------------------------------------------------------------*/
else // (thd->lex->sql_command == SQLCOM_DO)
return new (thd->mem_root) Sql_cmd_do(nullptr);
}如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











