







二叉搜索树
二叉查找树是指一棵有下列性质的[二叉树]:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树;
左子树数值比它小,右子树数值比它大
一般来说,BST不允许插入相同元素,除非多加一个值域去记录插入元素的次数
BST的中序遍历一定是
有序序列
二叉搜索树树高没有限制,很容易变成直线,所以实际应用一般用变式的BST
数据结构:
struct node{
int val;
node *left, *right;
node(int v,node* l=NULL,node* r=NULL):val(v),left(l),right(r){}
};
node *root;
![通用算法- [树结构] - 二叉搜索树_树结构搜索算法-CSDN博客](https://img-blog.csdnimg.cn/20191116212144764.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2R1YW4yMDE0MDYxNA==,size_16,color_FFFFFF,t_70)
BST的查找
查找值为x结点是否存在
从根结点出发:
- 如果当前结点key值等于x,查找成功
- 如果当前结点key值
小于x,则递归检索左子树 - 如果当前结点key值
大于x,则递归检索右子树 - 如果当前结点为NULL,则查找失败
//查找
node* bstFind(node*t,int x){
if(!t) return NULL;
if(val < t->val)
return searchBST(t->left,val);
else if(val > t->val)
return searchBST(t->right,val);
else{
return t;
}
return NULL;
}
BST的插入
插入值为x的结点
与查找类似,从根节点出发:
- 如果插入值x存在,放弃插入,或者x对应节点值计数+1
- 如果插入值不存在,就在对应位置的父节点创建左孩子或者右孩子
插入1:void,传入*&
//传入指针的引用
void insertBST(node*& root,int x){
if(!root){//找到位置了,插入
root=new node(x);
return;
}
if(x <root->val){
insertBST(root->left,x);
}else if(x >root->val){
insertBST(root->right,x);
}else{//提前有了
return;
}
}
插入2:返回指针,注意连链
node* insertBST(node* root, int x) {
if (!root) {
return root = new node(x);
}
if (x < root->val) {
root->left = insertBST(root->left, x);
} else if (x > root->val) {
root->right = insertBST(root->right, x);
} else { //==
return NULL;
}
return root; // 返回根
}
创建树时,定义一个数组多次插入即可
//创建树 void createBst(int a[],int n){ root = new node(a[0]); for (int i = 1; i < n;i++){ insertBST(root, a[i]); //root=insertBST(),具体看返回类型 } }
BST的前驱后继
不同于链表,bst中val的前驱和后继要求:
bst中val的前驱:BST中比val小的最大结点
bst中val的后继:BST中比val大的最小结点
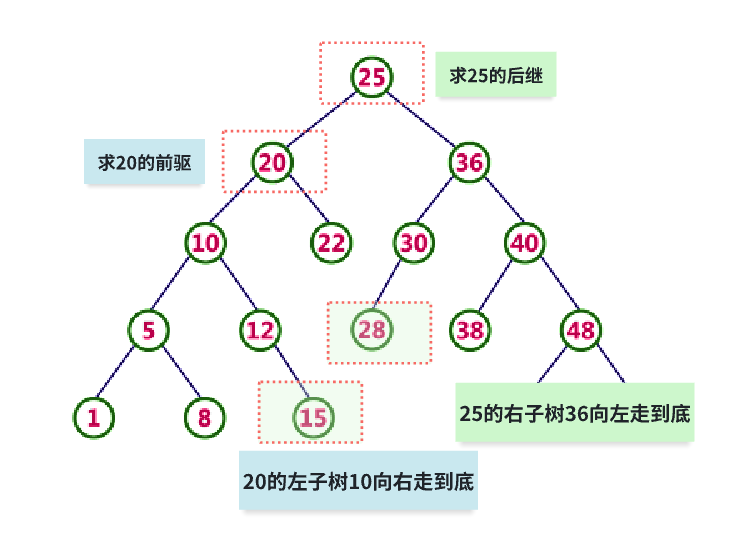
分为两种:
- 左右子树存在
-
如果左子树存在,那么前驱就是左子树的最右子树
-
如果右子树存在,那么后继就是右子树的最左子树
其实就是前驱求左子树最大值,后继求右子树最小值
- 左右子树不存在
如果该节点的左子树不存在,找前驱的方法
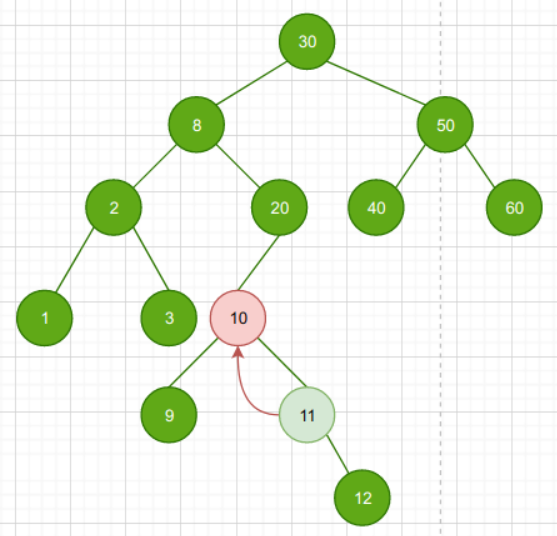
- 若节点N无左子树,但节点N是其父节点P的右孩子,那么父节点P就是该节点N的前驱结点
也就是说:如果结点不存在左孩子,但是是它父节点的右孩子,那么前驱就是父节点
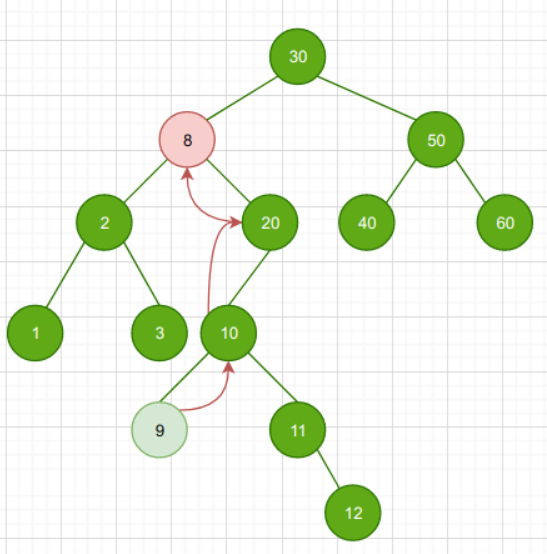
- 若节点N无左子树且是其父节点P的左孩子,那么需要沿着父亲节点P一直向树的顶端寻找,直到找到一个节点X是其父节点M的右孩子,则节点M为前驱节点
也就是说:
如过结点N没有左节点,而且是它的父节点的左孩子,就一直往其祖先结点迭代。
结点N的前驱就是结点x,x的右孩子是它的祖先之一
同理也可以求后继:
如果该节点的右子树不存在,找后继的方法
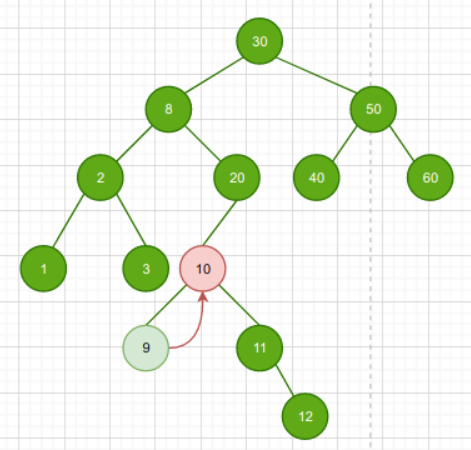
- 若节点N无右子树,但节点N是其父节点P的左孩子,那么父节点P就是该节点N的后继结点
也就是:如果该节点没有右子树,但是它是父节点的左儿子,那么父节点就是它的后继
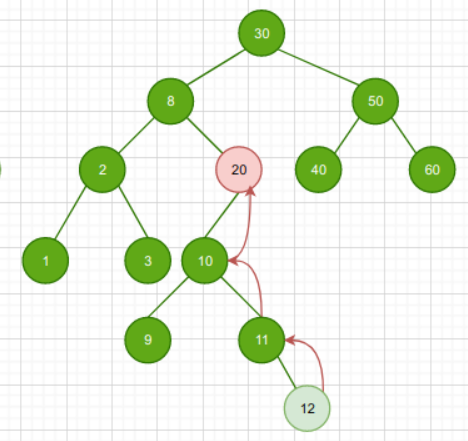
- 若节点N无右子树,但该节点N是其父节点P的右孩子,那么需要沿着父亲节点P一直向树的顶端寻找,直到找到一个节点X是其父节点M的左孩子,则节点M为后继节点
也就是说:
如果该节点没有右子树,而且是它父节点的右孩子,那么一直向上迭代。
那么该节点的后继就是它的祖先结点是该后继节点的左儿子
总结:
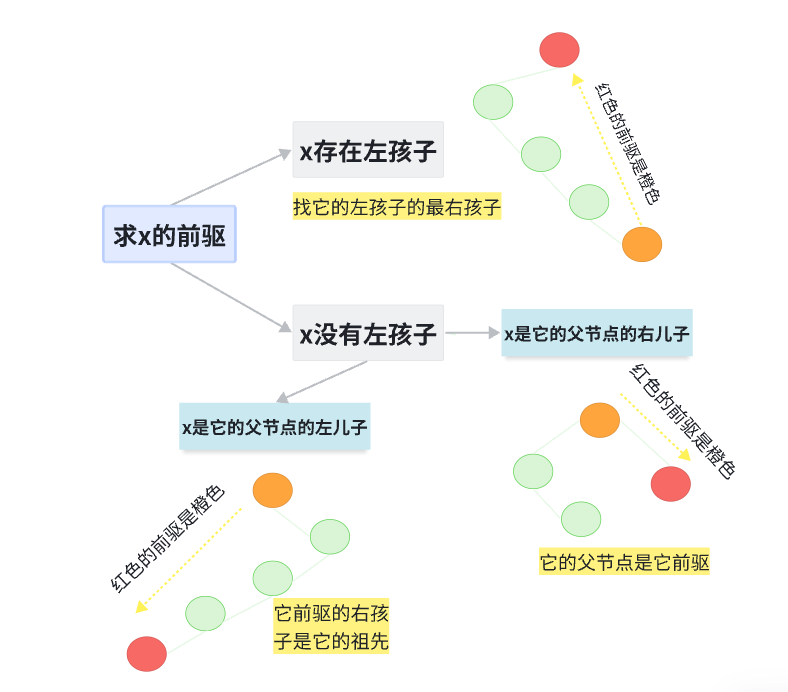

也就是说:
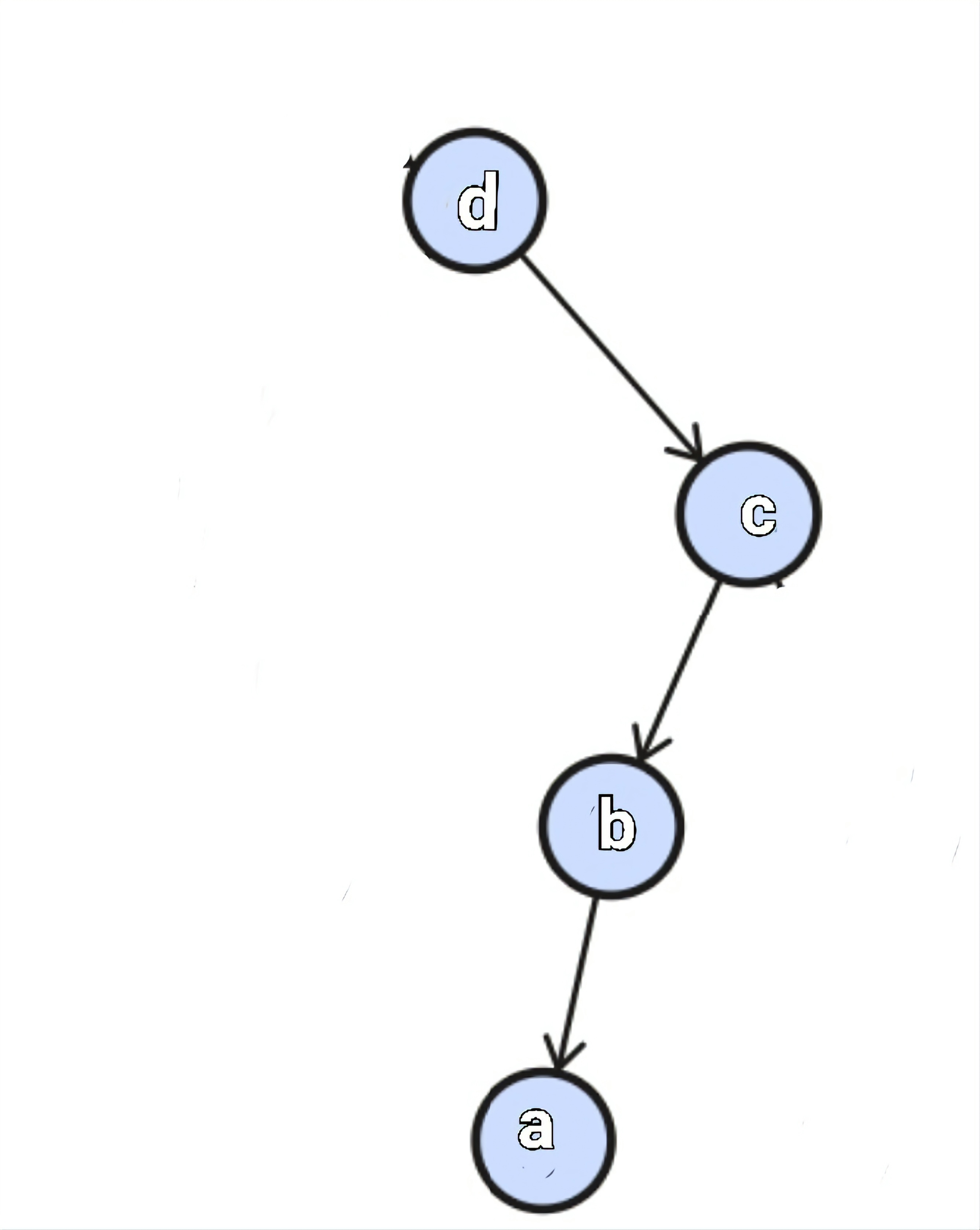
如果一个结点不存在左孩子,那么它的前驱就是:找到一个结点的右孩子是它的祖先结点
也就是:a的父节点是b,b的父节点是c,c的父节点是d,d是a的前驱
那么必定:d的右孩子是c,c的左孩子是b,b的左孩子是a
这是中序遍历左根右的特点
BST 删除
删除操作一定要维护二叉查找树的性质!!
大致分为三类
- 删除叶子结点—直接删即可
- 删除只有一棵子树的节点----把删除结点的子树取代自己位置连到父节点
只有以下四种情况
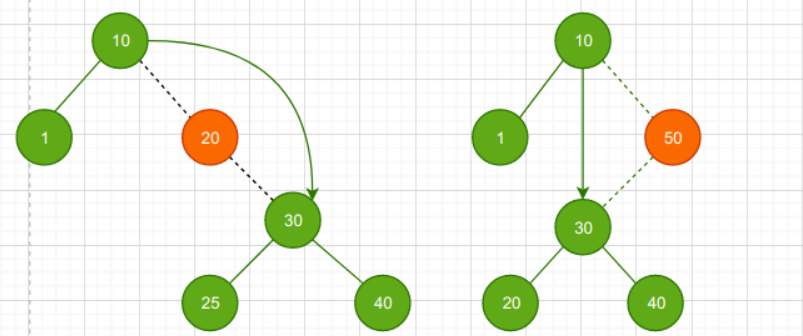
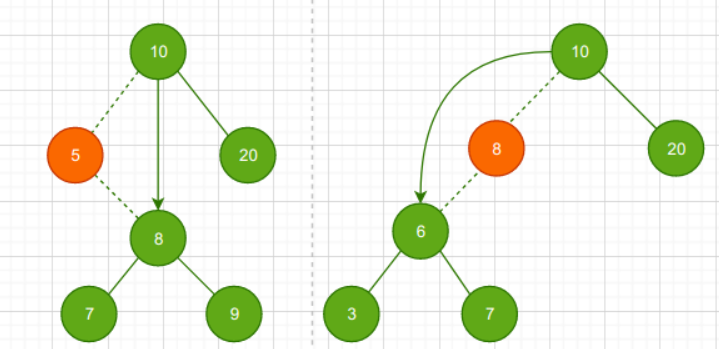
- 删除有两棵子树的节点
找到结点的直接前驱或直接后继替代结点,然后再从二叉查找树中删去它的直接前驱(或直接后继)。
后继或前驱只能为叶子或者单子树结点
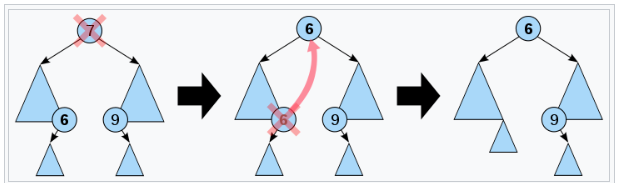
采取"找直接后继方法":把后继结点值取代待删结点,然后把后继结点删了,如果存在单只子树就连到其父节点

BST代码实现
遍历
//遍历
void midTraverse(node* t){
if(!t) return;
midTraverse(t->left);
cout << t->val << " ";
midTraverse(t->right);
}
void levelTraverse(node* t){
queue<node *> que;
if(t==NULL)
return;
que.push(t);
while(!que.empty()){
int sz = que.size();
for (int i = 0; i < sz;i++){
auto tmp = que.front();
que.pop();
cout << tmp->val << " ";
if(tmp->left)
que.push(tmp->left);
if(tmp->right)
que.push(tmp->right);
}
cout << endl;
}
}
求父节点两种方法
//求父节点
node* parent(node* t,node* par,int x){
if(t->val==x)
return par;
if(x<t->val){
return parent(t->left,t, x);
}
else if(x>t->val){
return parent(t->right,t, x);
}
return NULL;
}
//求父节点2
node* parent2(node* t,int x){
if(x<t->val){
if(t->left){
if(t->left->val==x)
return t;
return parent2(t->left, x);
}
}
if(x>t->val){
if(t->right){
if(t->right->val==x)
return t;
return parent2(t->right, x);
}
}
return NULL;
}
求前驱和后继
(需要调用查找和求父节点)
//求前驱
node* preNode(node* root,int x){
node *t = bstFind(root, x);
if(t->left){
//有左子树,找左子树最右
t = t->left;
while(t->right)
t = t->right;
return t;
}
//没有左子树,找一个结点的右子树是它的祖先
//node *par = parent2(root, t->val);
node *par = parent(root,NULL, t->val);
while(par && par->right!=t){
t = par;
par = parent2(root, t->val);
}
return par;
}
//求后继
node* postNode(node* root,int x){
node *t = bstFind(root, x);
if(t->right){
//有右子树,找右子树最左
t = t->right;
while(t->left)
t = t->left;
return t;
}
//没有右子树,找一个结点的左子树是它的祖先
//node *par = parent2(root, t->val);
node *par = parent(root,NULL, t->val);
while(par && par->left!=t){
t = par;
par = parent2(root, t->val);
}
return par;
}
也可以采用map记录父节点
#include <unordered_map> unordered_map<node *, node *> mp; //---- //map void findPar(node* root){ if(!root) return; if(root->left){ mp[root->left] = root; findPar(root->left); } if(root->right){ mp[root->right] = root; findPar(root->right); } }主程序测试
createBst(a, n); findPar(root); for(auto [k,v]:mp){ cout << k->val << "的父节点是" << v->val << endl; }
此时父节点可以利用
mp求出
while(mp[t] && mp[t]->right!=t)
不可以把mp[t]改成mp.count(t)mp.count(key),key存在不一定代表v存在
//求前驱 node* preNode(node* root,int x){ node *t = bstFind(root, x); if(t->left){ //有左子树,找左子树最右 t = t->left; while(t->right) t = t->right; return t; } while(mp[t] && mp[t]->right!=t){ t = mp[t]; } return mp[t];//返回的是父节点mp[t] } //求后继 node* postNode(node* root,int x){ node *t = bstFind(root, x); if(t->right){ //有右子树,找右子树最左 t = t->right; while(t->left) t = t->left; return t; } while(mp[t] && mp[t]->left!=t){ t = mp[t]; } return mp[t]; }主程序测试
findPar(root); for (int i = 0; i < n;i++){ node *aa = preNode(root, a[i]); if(aa){ cout <<a[i]<<"的前驱"<<aa->val << endl; } } for (int i = 0; i < n;i++){ node *bb = postNode(root, a[i]); if(bb){ cout <<a[i]<<"的后继"<<bb->val << endl; } }
bst力扣题
一:插入操作
返回值为:
TreeNode*,注意把新的结点链入树中
root->left=insertIntoBST(root->left,val);
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root==NULL){
root=new TreeNode(val);
return root;
}
if(val<root->val){
//把插入的点连到树中
root->left=insertIntoBST(root->left,val);
}
else if(val>root->val){
root->right=insertIntoBST(root->right,val);
}
return root;
}
二:找后继
关键就是记录好父节点的信息
class Solution {
public:
TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {
if(!p) return NULL;
getPar(root);
//右子树最左端
if(p->right){
p=p->right;
while(p->left) p=p->left;
return p;
}
//找结点的左子树是它祖先
while(mp[p]&&mp[p]->left!=p){
p=mp[p];
}
return mp[p];
}
private:
unordered_map<TreeNode*, TreeNode*> mp;
void getPar(TreeNode* root) {
if (root == NULL)
return;
if (root->left) {
mp[root->left] = root;
getPar(root->left);
}
if (root->right) {
mp[root->right] = root;
getPar(root->right);
}
}
};
利用非递归的中序遍历
void midTraver(TreeNode* root){
if(!root) return;
stack<TreeNode*> sta;
TreeNode* p=root;
while(p || !sta.empty()){
while(p){//左子树不断进栈
sta.push(p);
p=p->left;
}
//if(!sta.empty()){
p=sta.top();
sta.pop();
cout<<p->val<<" ";
p=p->right;
//}
}
cout<<endl;
}
这里第二个条件可以不判断
while(a||b) 如果while(a)不运行,b一定成立;假设a成立,b不成立,那么运行a一定会让b满足
本题格外加一个结点,记录右子树前内容
TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {
if (!root)
return NULL;
stack<TreeNode*> sta;
TreeNode* post=NULL;//记录后继
TreeNode* t = root;
while (t || !sta.empty()) {
while (t) { // 左子树不断进栈
sta.push(t);
t = t->left;
}
t = sta.top();
sta.pop();
if(post==p){
//t是post的后继
return t;
}
post=t;
t = t->right;
}
return NULL;
}
利用bst后继自身特点
也就是:当前节点值比查找值大,需要不断向左,顺便记录好这个可能的前驱
当前节点值比查找值大,一定不是前驱,只要不断向右判断是否存在该节点即可
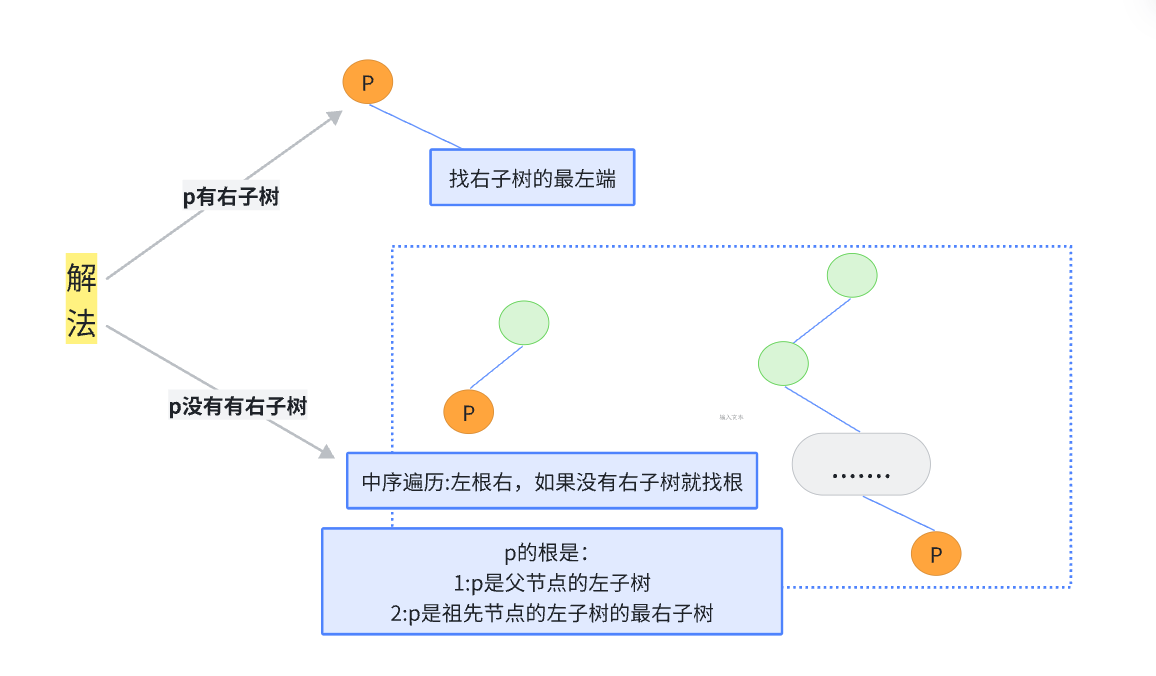

TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {
if(root==NULL || p==NULL) return NULL;
//p有右子树
while(p->right){
p=p->right;
while(p->left) p=p->left;
return p;
}
//p没有右子树
TreeNode* t=root;
TreeNode* post=NULL;
while(t){
//后继一定比p->val大
if(t->val > p->val){
post=t;
t=t->left;
}else {//t->val <=p->val
t=t->right;
}
}
return post;
}
代码默认一定能找到p
这种方法还可以求前驱
TreeNode * inorderPredecessor(TreeNode * root, TreeNode * p) { if(!root || !p) return NULL; //p左子树存在 if(p->left){ p=p->left; while(p->right) p=p->right; return p; } //不存在 TreeNode* pre=NULL; while(root){//从根出发 if(root->val < p->val){ pre=root; root=root->right; }else{ root=root->left; } } return pre; }
递归求法
也就是如果当前值小于p,去寻找比p大的下一个结点,需要加上等号
TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {
if(!root || !p) return NULL;
//找比p大的下一个结点,找到就返回
if(root->val <= p->val){
return inorderSuccessor(root->right,p);
}else{//
//后继为根,要么是父节点,要么是祖先节点
TreeNode* tmp=inorderSuccessor(root->left,p);
return tmp?tmp:root;
}
}
三:删除节点
首先先检索,找到要删的结点。
查到节点后,依据情况删除:
- 叶子结点直接删,单枝结点取代原来位置
- 双支结点,可以选择找前驱和后继取代该节点,再去左/右子树删掉该前驱或后继
选择后继取代双枝结点的方法
TreeNode* deleteNode(TreeNode* root, int key) {
if(!root) return NULL;
//查找节点
if(key < root->val){
root->left=deleteNode(root->left,key);
}else if(key >root->val){
root->right=deleteNode(root->right,key);
}else{//==
if(!root->left || !root->right){
TreeNode* tmp=root;
root=(root->left)?root->left:root->right;
delete tmp;
}else{//左右子树都存在
//取后继当代替
TreeNode* tmp=root->right;
while(tmp->left) tmp=tmp->left;
//替换值
root->val=tmp->val;
//去右子树删了
root->right=deleteNode(root->right,tmp->val);
}
}
return root;
}
if(!root->left || !root->right){ //TreeNode* tmp=root; root=(root->left)?root->left:root->right; //delete tmp; }这段代码合并了只有单枝子树和叶子结点的情况,也就是有左子树,左子树取代、有右子树,右子树取代
如果是叶子,直接删,和用叶子的左右子树取代是一样的,都是NULL
不delete只断链也可以达到删除目的,最好是delete
if(!root->left ) return root->right; else if(!root->right) return root->left;这样也可以达到目的
这种返回指针,千万不能断链,所以一定得有左端接收值
比如:
root->right=deleteNode(root->right,tmp->val);
当然了还可以不用返回值,这时候必须传指针的引用
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
delHelper(root,key);
return root;
}
private:
void delHelper(TreeNode*& root,int k){
if(!root) return;
if(k<root->val) delHelper(root->left,k);
else if(k>root->val) delHelper(root->right,k);
else{//k==root->val
//找左子树最大
if(root->left && root->right){
TreeNode* tmp=root->left;
while(tmp->right) tmp=tmp->right;
root->val=tmp->val;//赋值
//去左子树删
delHelper(root->left,tmp->val);
}
else{
//TreeNode* tmp=root;
root=(root->left)?root->left:root->right;
//delete tmp;
}
}
}
};
四:变式中序遍历
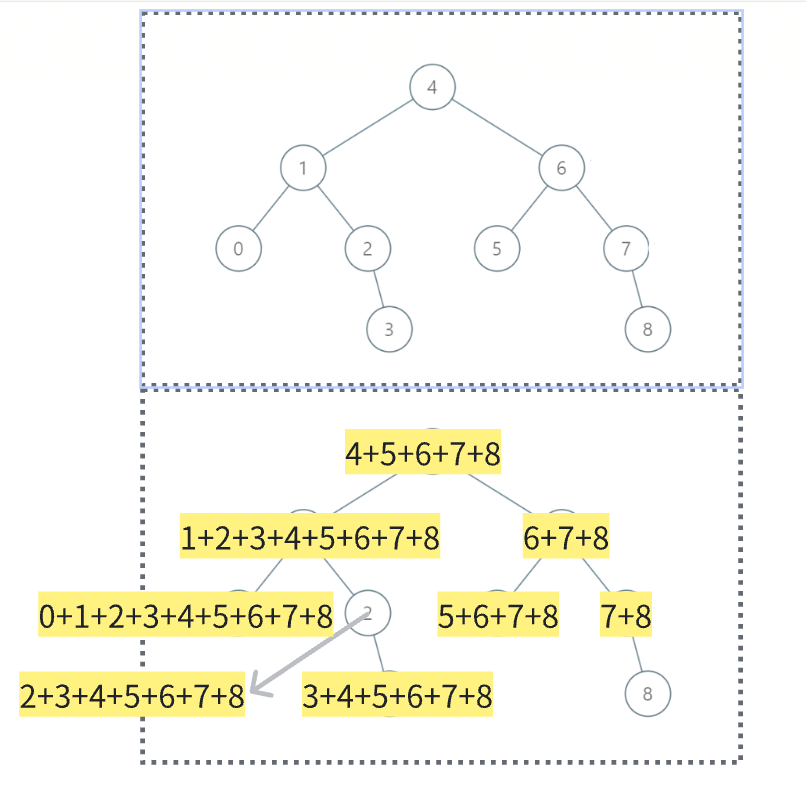
类别数组:
[1,2,3,4,5]->[15,14,12,9,5]其实就是:后一个等于前一个之和
这里其实就是:后一个值是累加前一个,但是顺序是:右根左
递归解法:
类似中序遍历,但是顺序为:
右根左定义一个全局变量sum,在中间位置进行值的更改
class Solution {
public:
TreeNode* convertBST(TreeNode* root) {
rightToLeft(root);
return root;
}
private:
int sum=0;
void rightToLeft(TreeNode* root){
if(!root) return;
//递归右子树
rightToLeft(root->right);
//中间:更改值
sum+=root->val;
root->val=sum;
//递归左子树
rightToLeft(root->left);
}
};
非递归解法:
TreeNode* convertBST(TreeNode* root) {
stack<TreeNode*> sta;
TreeNode* p=root;//指向根结点
int sum=0;
while( p|| !sta.empty()){
if(p){
sta.push(p);
p=p->right;
}else{
p=sta.top();
sta.pop();
//累加
sum+=p->val;
p->val=sum;
//向左
//p这个指向很重要
p=p->left;
}
}
return root;
}
while可以更改
while (p || !sta.empty()) { while (p) { sta.push(p); p = p->right; } p = sta.top(); sta.pop(); // 累加 sum += p->val; p->val = sum; // 向左 // p这个指向很重要 p = p->left; }
五:验证二叉搜索树
判断依据就是:左子树不能比当前值大,右子树不能比当前值小
这种解法是错误的,因为只能证明:当前结点的左节点比他小,右节点比它大,但是顾虑不到前面
也就是说:只能满足局部
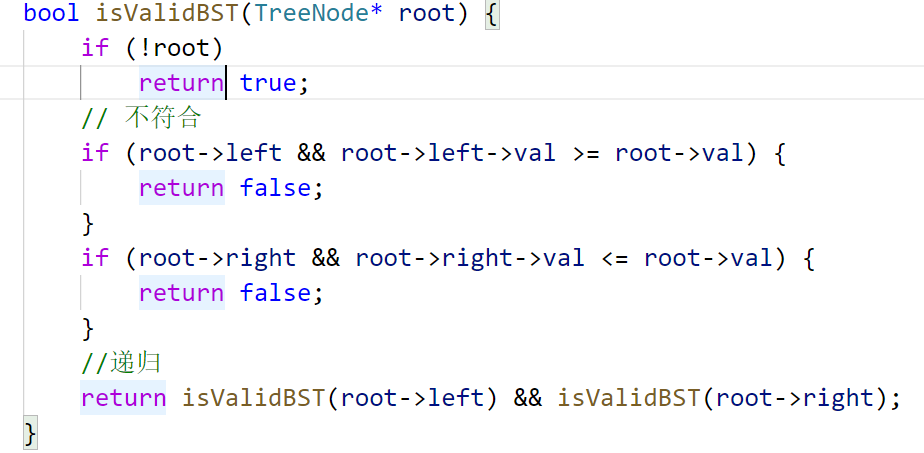
解题:
重新定义一个函数,传入两个参数上界和下界,这样每次递归就会考虑上一次的结果
由于测试用例数据大,这里用long
class Solution {
public:
bool isValidBST(TreeNode* root) {
return bstHelper(root,LONG_MIN,LONG_MAX);
}
private:
//root->val的范围:(lower,higher)
bool bstHelper(TreeNode* root,long lower,long higher){
if(!root) return true;
//不符合条件
if(root->val <=lower || root->val >=higher){
return false;
}
return bstHelper(root->left,lower,root->val)\
&&bstHelper(root->right,root->val,higher);
}
};
二分查找
二分查找的步骤:
能使用二分查找的前提:
- 数据结构具备单调性
- 存在上下界
- 能够通过索引快速访问
典型的就是传入数组,返回查到的数组下标

二分查找模板
int search(vector<int>& nums, int target) {
if(nums.size()==0) return -1;
int l=0;
int r=nums.size()-1;
while(l<=r){
int mid=(l+r)/2;
if(nums[mid]==target){
return mid;
}else if(nums[mid]<target){
l=mid+1;
}else{
r=mid-1;
}
}
return -1;
}
二分查找扩展
二分查找不光可以找相等的,还可以找:第一个小于等于或者第一个大于等于或者第一个等于
也就是说:查找第一个大于33,那么33可能并不在给定数组内,这时候区间包不包含mid就需要判断了
第一个或最后一个等于
第一个等于【1,4,4】
等于的时候也要缩小r,如果r恰好在等于前一个位置时说明找到了,此时l==r
然后运行一次,把l值+1即可
int firstEqual(vector<int>& arr,int target){
int l = 0;
int r = arr.size() - 1;
//闭区间:[l,...,r]
while(l<=r){
int mid = (l + r) / 2;
//等于时候也要缩小r才能找到第一个等于
if(arr[mid]>=target){
r = mid - 1;
}else{
l = mid + 1;
}
}
//l值对应正确的结果
if(l <arr.size() && arr[l]==target){
return l;
}else{
return -1;
}
}
最后一个等于思路类似,只是要不断扩大l,使得l指向第一个大于目标值的位置
int lastEqual(vector<int>& arr,int target){
int l = 0;
int r = arr.size() - 1;
while(l<=r){
int mid = (l + r) >> 1;
if(arr[mid] <= target){
l = mid + 1;
}else{
r = mid - 1;
}
}
if(r>=0 && arr[r]==target){
return r;
}else{
return -1;
}
}
第一个>=和最后一个<=
这里是不是纯等号,也就是即使目标值不在数组内也有正确结果
所以:
r>=0 && arr[r]==target,l <arr.size() && arr[l]==target两个判断不需要了
这个和寻找第一个等于的唯一的区别就是:
不需要判断(
L < arr.length && arr[L] == key)因为如果不存在
等于target值的话,我们返回第一个>的元素即可
int firstLargeEqual(vector<int>& a,int target){
int l = 0;
int r = a.size() - 1;
while(l<=r){
int mid = (l + r) / 2;
//第一个=,缩小r
if(a[mid]>=target){
r = mid - 1;
}else{
l = mid + 1;
}
}
return l;
}
-
最后一个
<=的这个
寻找最后一个等于的唯一的区别就是:最后我们不需要判断 (
R >= 0 && arr[R] == key)因为如果不存在
等于target的话,我们返回最后一个<的元素即可;这里没有判断越界(
R >= 0),因为如果整个数组都比target要大,数组更左边一个就是-1
int lastSmallEqual(vector<int>& a,int target){
int l = 0;
int r = a.size() - 1;
while(l<=r){
int mid = (l + r) / 2;
//最后一个<=,扩大l
if(a[mid]<=target){
l = mid + 1;
}else{
r = mid - 1;
}
}
return r;
}
找前驱后继:第一个大于,最后一个小于
<第一个大于>
if(arr[mid] >= target)改成了if(arr[mid] > target),因为我们不是要寻找= target的
//第一个大于也就是:后继
int firstLarge(vector<int>& arr,int target){
int l = 0;
int r = arr.size() - 1;
while(l<=r){
int mid = (l + r) / 2;
//缩小r
if(arr[mid]>target){
r = mid - 1;
}else{
l = mid + 1;
}
}
return l;
}
<最后一个小于>
就是
arr[mid] <= target改成了arr[mid] < target,因为我们要寻找的不是=的
int lastSmall(vector<int>& arr,int target){
int l = 0;
int r = arr.size() - 1;
while(l<=r){
int mid = (l + r) / 2;
//最后一个小于,扩大l
if(arr[mid]<target){
l = mid + 1;
}else{
r = mid - 1;
}
}
return r;
}
总结
第一个...的总结
最后返回的都是
L;
- 如果是寻找
第一个等于的
if( arr[mid] >= tar) R = mid - 1,且最后要判断L 的合法以及是否存在target;
- 如果是寻找第一个大于等于
key的,
if(arr[mid] >= tar) R = mid - 1,但是最后直接返回L;
- 如果是寻找第一个大于
key则
if(arr[mid] > tar) R = mid - 1,最后返回L ;
最后一个...的总结
最后返回的都是
R;第一个
if判断条件都是L的操作,也就是去右边寻找;
- 寻找
最后一个等于
if(arr[mid] <= tar) L = mid + 1; 不过最后要判断R的合法性以及是否存在target;
- 如果是寻找最后一个 小于等于
key的,
if(arr[mid] <= tar) L = mid + 1;不过最后直接返回R;
- 如果是寻找最后一个 小于
key的,则
if(arr[mid] < key) L = mid + 1 ,最后返回R;
二分力扣题
求相等范围
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
this->nums=nums;
this->target=target;
int u=firstEqual();
int v=lastEqual();
return {u,v};
}
private:
vector<int> nums;
int target;
//firstEqual
int firstEqual(){
int l=0;
int r=nums.size()-1;
while(l<=r){
int mid=(l+r)/2;
//缩小r
if(nums[mid]>=target){
r=mid-1;
}else{
l=mid+1;
}
}
return (l<nums.size()&&nums[l]==target)?l:-1;
}
//lastEqual
int lastEqual(){
int l=0;
int r=nums.size()-1;
while(l<=r){
int mid=(l+r)/2;
//扩大l
if(nums[mid]<=target){
l=mid+1;
}else{
r=mid-1;
}
}
return (r>=0 && nums[r]==target)?r:-1;
}
};
可以合并到一起
vector<int> searchRange(vector<int>& nums, int target) { vector<int> ans; int l=0; int r=nums.size()-1; int mid; //第一个>= while(l<=r){ mid=(l+r)>>1;//向下取整 if(nums[mid]>=target){ r=mid-1; }else{ l=mid+1; } } int ret=(l<nums.size()&&nums[l]==target)?l:-1; ans.push_back(ret); //最后一个<= l=0; r=nums.size()-1; while(l<r){ mid=(l+r+1)>>1;//向上取整 if(nums[mid]<=target){ l=mid; }else{ r=mid-1; } } ret=(r>=0 && nums[r]==target)?r:-1; ans.push_back(ret); return ans; }
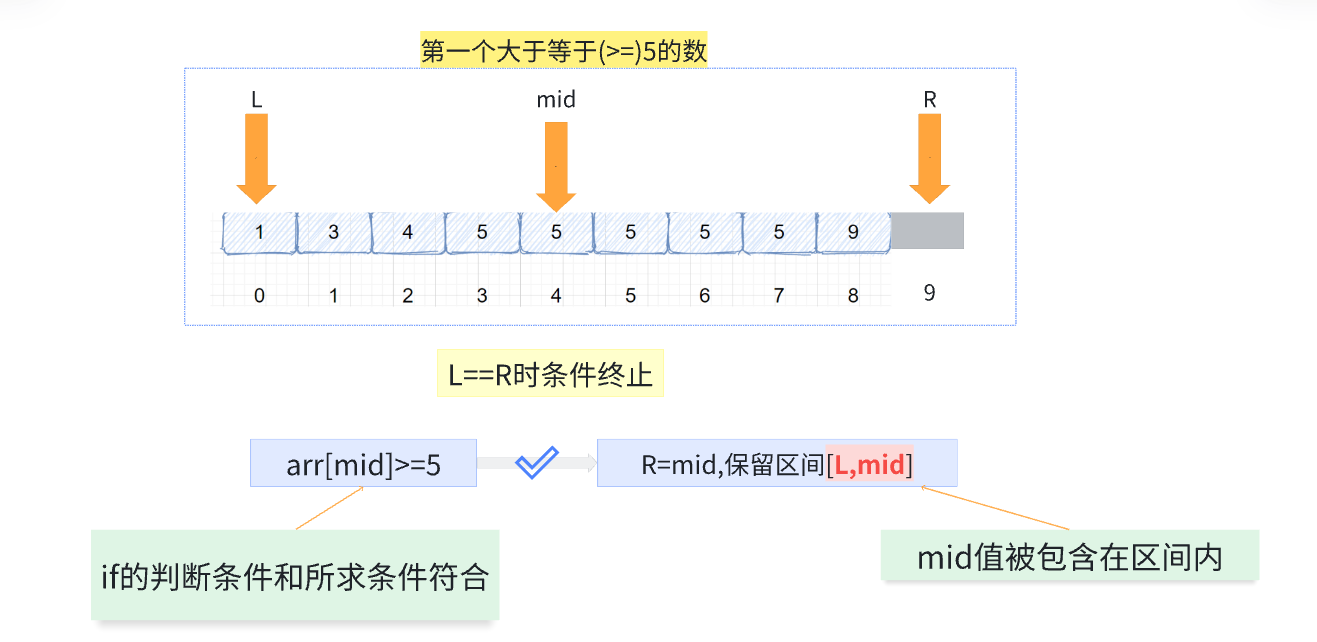
方法二:区间包含mid
R初始化在不存在位置,因为如果整个数组都<目标值,L最会会停在不合理位置
如果只有两个数,mid向下取整得到当前L位置:
-----如果mid对应值符合>=,R左移动,下一次跳出循环
-----如果mid对应值不符合>=,L右移到R位置,下一次跳出循环
//找到第一个>= int firstEqual(vector<int>& nums,int target){ //1:初始化r在最右端下一个 int l=0; int r=nums.size(); //2:l==r终止 while(l<r){ int mid=(l+r)/2; if(nums[mid]>=target)//满足条件 r=mid; else l=mid+1; } return l;//r }
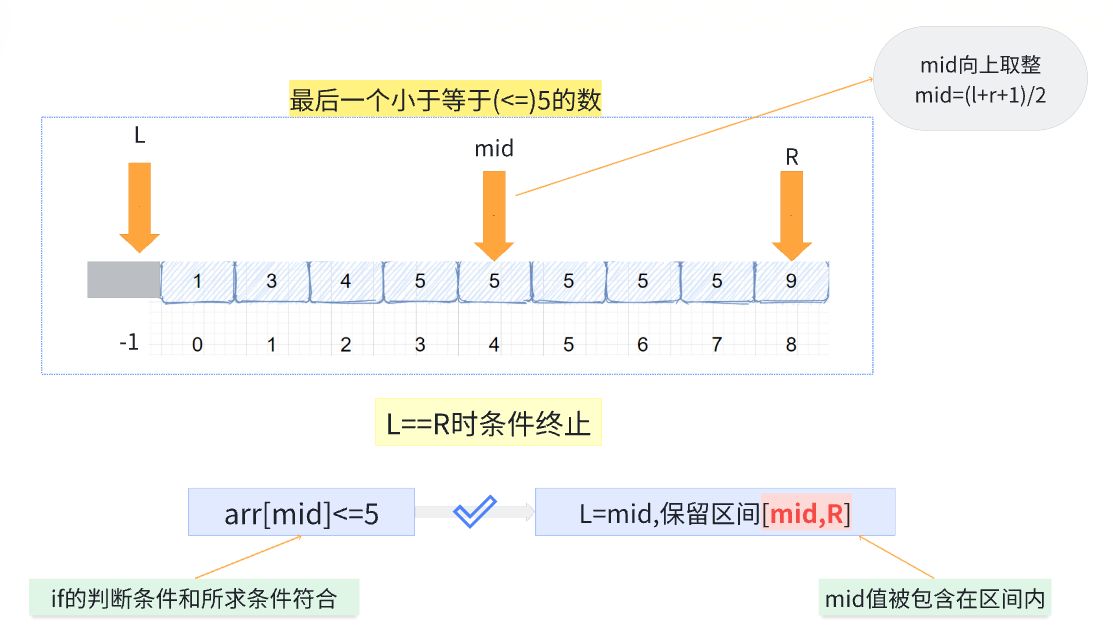
如果数组全是>目标值,R不断左移,最后停在L的不合理位置
这里如果只有两个数那么向上取整,因为每次满足<=条件L移动到mid,但是mid向下取整会造成死循环
[a,b]向上取整,mid会取b,如果mid对应值不满足<=:L右移到R的位置,满足:R移动到L,此时都满足返回条件
//找到最后一个<= int lastEqual(vector<int>& nums,int target){ 1:初始化l在最左端上一个 int l=-1; int r=nums.size()-1; while(l<r){ int mid=(l+r+1)/2;//注意向上取整 if(nums[mid]<=target){ l=mid; }else{ r=mid-1; } } return r; }
解答:
vector<int> searchRange(vector<int>& nums, int target) {
vector<int> ans;
int l=0;
int r=nums.size();
int mid;
//第一个>=
while(l<r){
mid=(l+r)>>1;//向下取整
if(nums[mid]>=target){
r=mid;
}else{
l=mid+1;
}
}
ans.push_back(r);
//最后一个<=
l=-1;
r=nums.size()-1;
while(l<r){
mid=(l+r+1)>>1;//向上取整
if(nums[mid]<=target){
l=mid;
}else{
r=mid-1;
}
}
ans.push_back(r);
if(ans[0]>ans[1]){
return {-1,-1};
}
return ans;
}
好处:
- 当l==r时候返回,返回l和r一样
- 因为l和r初始化一个非法位置,所以不需要额外判断合法性
- 判断条件和题目相求的不等号相同
注意一下mid包含在区间,而且分为向上取整和向下取整
x的平方根
使用二分查找,题目要求舍去小数部分,相当于找一个<=数。
题目转化成:从0~x中找到一个值v,使得
v*v<=x既然是<=,注意模板:
- mid向上取整
- 维护[mid,r]的范围
int mySqrt(int x) {
//二分查找一个数v,使得v*v <= x
long l=0;
long r=x;
while(l<r){
long mid=(l+r+1)>>1;//mid向下取整
if(mid*mid <= x){//满足条件<=
l=mid;
}else{
r=mid-1;
}
}
return r;
}
使用long是为了防止
int*int溢出


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









