







踩坑背景:
代码来源低光照增强CVPR2019论文《EnlightenGAN: Deep Light Enhancement without Paired Supervision》,该文章以笔者浅显的学习背景愿称之为“SOTA之一,最好的GAN-based方法”,故尝试对该文献源代码进行学习运行,如有不当请路过的大佬多多批评指正。
本文实验记录不涉及重新训练,仅基于论文作者提供的网络预训练权重进行代码测试和运行。文章中涉及的各路大佬的指导贴均指出引用原网址。
运行环境:Windows11系统、 Anconda3自定义虚拟环境pytorch_envs
注:本文将有关资源均上传百度网盘进行分享,深深共情那些无法科学上网的科研搭子们(致敬永远404的Google Drive),自己淋过雨,伞能撑尽撑……资源整合目录如下(括号内为源下载网址,目录末尾给出整合资源的网盘链接):
- 论文作者开源Git-Hub代码(https://github.com/VITA-Group/EnlightenGAN)
- VGG pretrained model(https://drive.google.com/file/d/1IfCeihmPqGWJ0KHmH-mTMi_pn3z3Zo-P/view?usp=sharing)
提示:下载完成后将权重文件“vgg16.weight”添加至代码根目录文件夹“models”下 - Testing process pretrained model(https://drive.google.com/file/d/1AkV-n2MdyfuZTFvcon8Z4leyVb0i7x63/view?usp=sharing)
提示:在代码根目录下新建文件夹,建立路径“./checkpoints/enlightening”,下载完成后将权重文件“200_net_G_A.pth”添加至“enlightening”下 - Testing data(https://drive.google.com/open?id=1PrvL8jShZ7zj2IC3fVdDxBY1oJR72iDf) (including LIME, MEF, NPE, VV, DICP)
提示:在代码根目录下新建文件夹,建立路径“./test_dataset”,下载完成后将两个压缩包解压至“test_dataset”中,分别为testA和testB,根据作者README中的要求testB需自行添加至少一张图片确保程序运行
README给出了部分网盘资源链接,在(https://github.com/TAMU-VITA/EnlightenGAN/issues/28)讨论区里,但在笔者满怀希望的尝试后均已失效,特做此分享。
网盘资源:
https://pan.xunlei.com/s/VNvMcQMJTIttMAYjskm5FkVdA1?pwd=v87g# 提取码:v87g
坑前准备
注:根据检索到的各路大佬指导贴,进行的一些避坑举措
- script.py文件中将 …/final_dataset 更改为./ final_dataset,然后在代码根目录下创建一个文件夹 final_dataset,然后把数据trainA和trainB放入到里面(此条与代码训练有关,在此仅做记录,trainA和trainB作者提供的源网址404辽,因此未包括在上文资源整合的网盘链接中)
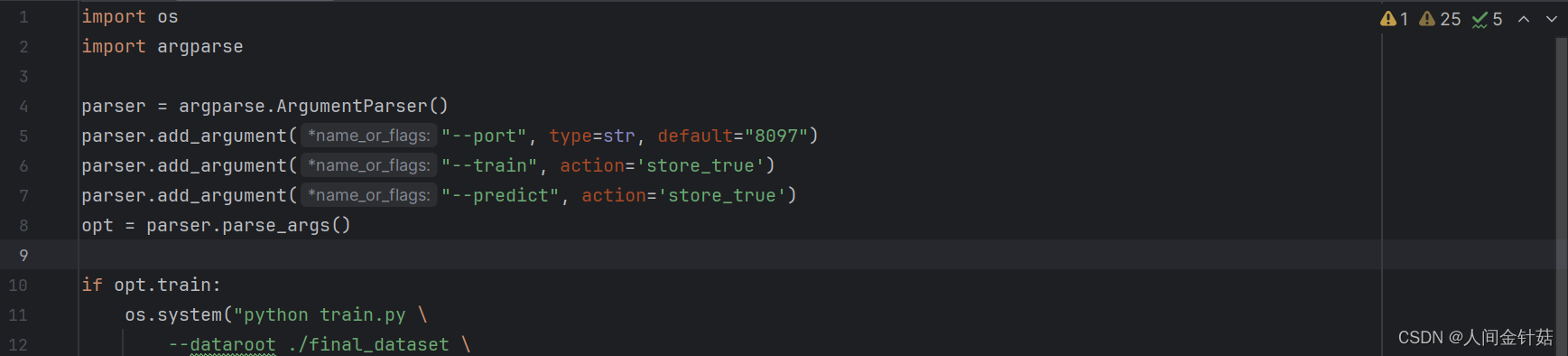
- script.py文件中将opt.train:os.system()中的–gpu_ids 0,1,2 更改为 --gpu_ids 0(若实验电脑配置为1块GPU按此设置,源代码中是利用三块Nvidia 1080Ti同时进行训练)
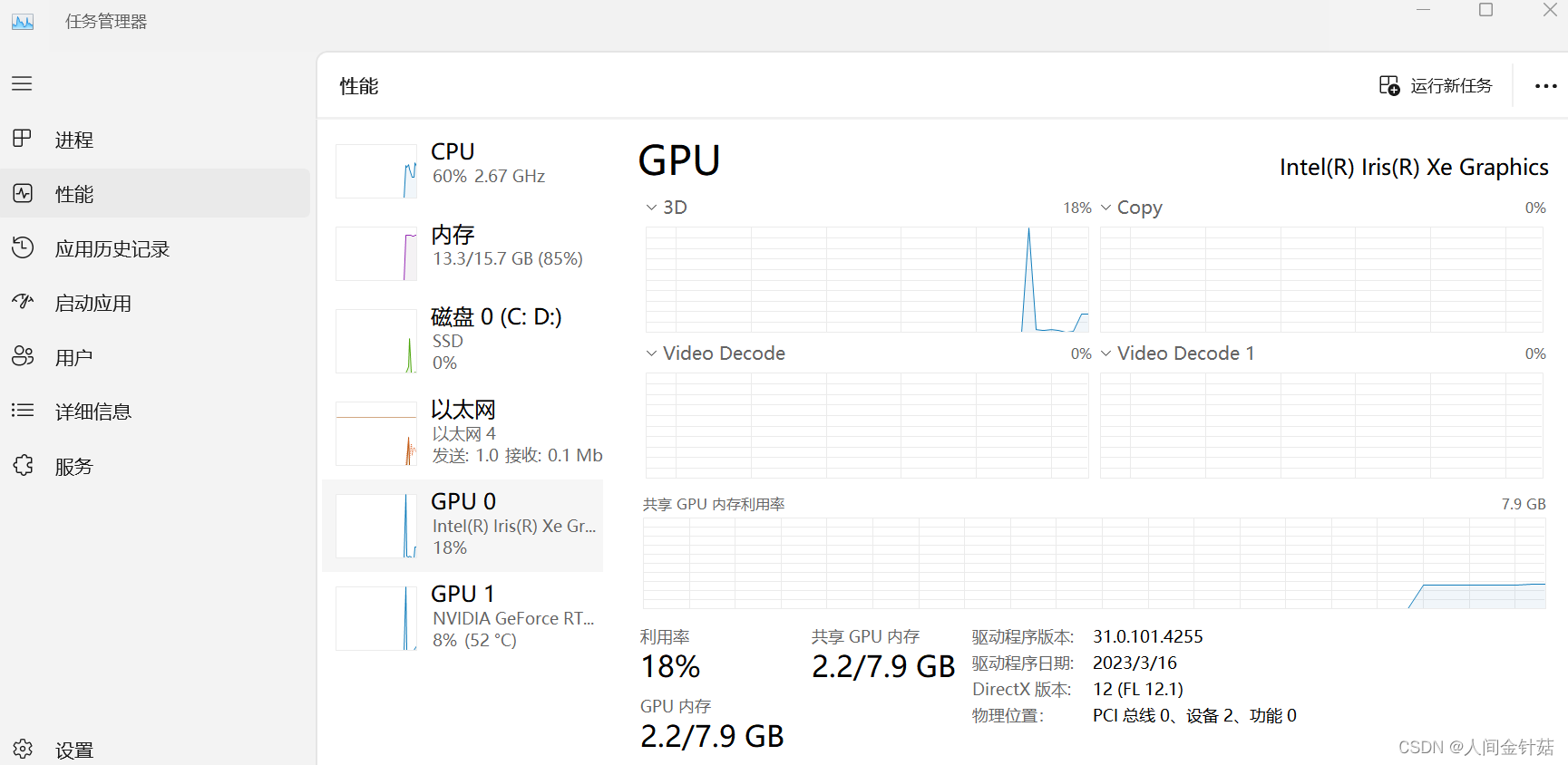
电脑GPU配置查看方法:在任务栏右键打卡任务管理器,在“性能”一栏查看GPU数目
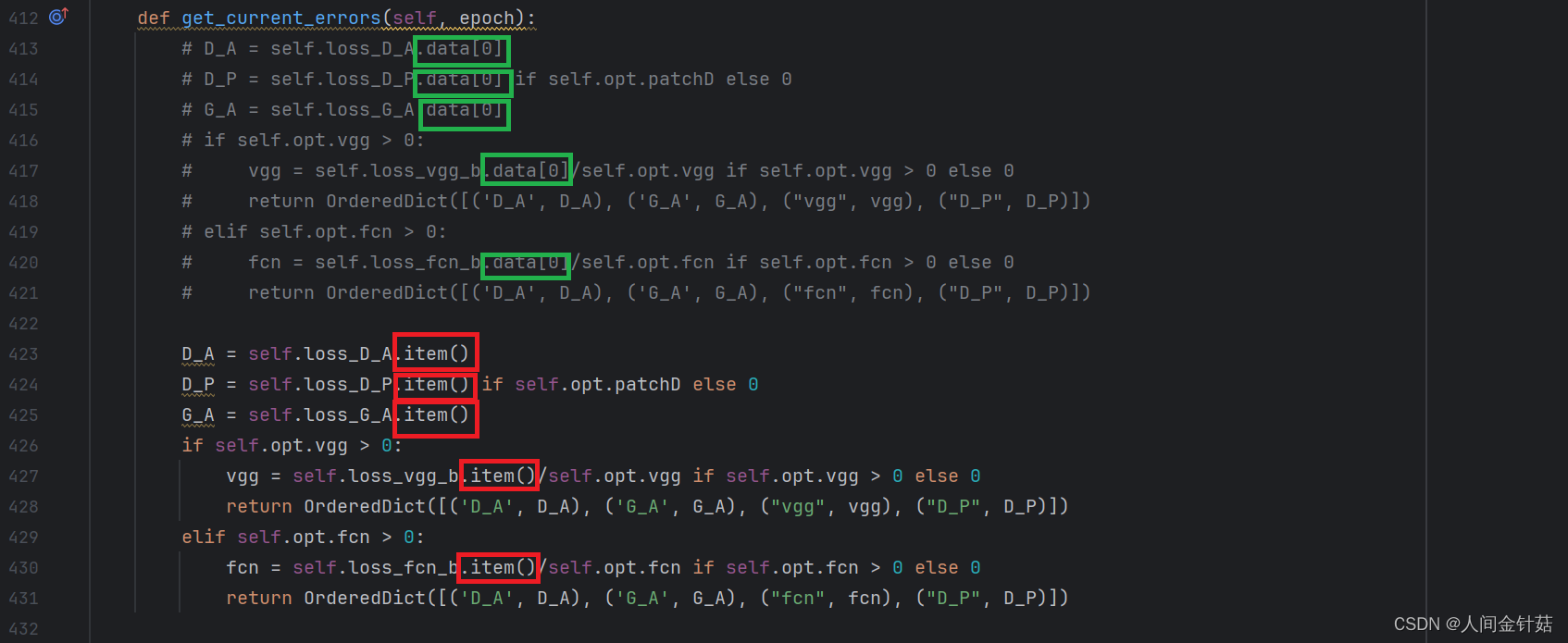
- 在single_model.py文件中将函数get_current_errors中的data[0]改为item(),一共有5处需要修改绿色框为未修改前的示意,红色框为修改后的最终代码。
4.根据实验电脑配置不同可能会遇到的经典错误: RuntimeError: CUDA out of memory.,将script.py中的opt.train:os.system()参数--batchSize改小,根据自己电脑的配置量力而行,注意是batchSize不是patchSize。
特此鸣谢大佬指导贴(排名不分先后):
EnlightenGAN的运行环境搭建和训练自己的数据
EnlightenGAN训练复现记录
EnlightenGAN的代码运行过程问题记录
EnlightenGAN 开源代码运行
一号坑:Downloading scripts, this may take a little while
做过坑前准备后,按照论文作业README中测试代码的操作执行,在代码根目录中打开终端运行python -m visdom.server -port=8097(Linux系统执行nohup python -m visdom.server -port=8097)
特别注意:无论是训练还是测试代码均需先进行此代码运行,进行可视化,其中“port=8097”要与script.py文件中
parser.add_argument("--port", type=str, default="8097")中的端口命名一致
踩坑全貌:笔者在代码根目录右键直接打开终端时运行python -m visdom.server -port=8097代码时,出现以下问题
PS D:\4-Program\data_enhance\EnlightenGAN-master> python -m visdom.server -port=8097
Checking for scripts.
Downloading scripts, this may take a little while
尝试解决:
- 根据指导贴找到当前conda环境对应虚拟环境的visdom包下(示例路径:“D:\Anaconda3\envs\pytorch_envs\Lib\site-packages\visdom\server”,其中“pytorch_envs”为笔者自定义使用的虚拟环境名称)的run_server.py文件,将文件中
download_scripts_and_run函数下的download_scripts()注释掉,即# download_scripts()。 - 对visdom文件下的static文件进行替换,预防出现目标网址空白蓝屏的问题。即将下文标注指导贴链接中的压缩包解压进行static同名文件的替换。
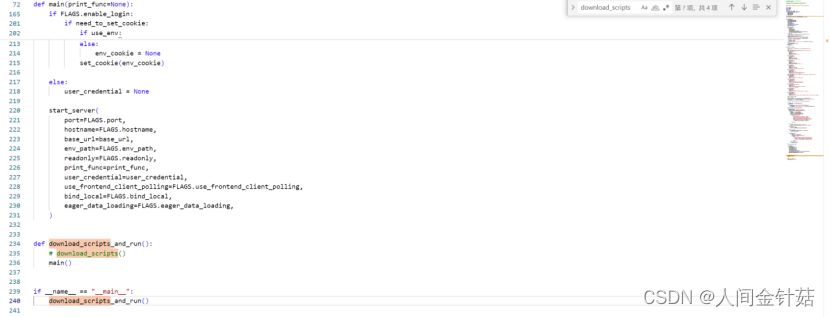
出坑纪念:
但尝试后仍发现问题未解决。且在代码根目录右键打开的windows PowerShell中直接使用activate激活虚拟环境无反应(尚未搞清楚原因)。用Win+R打开cmd运行代码后也出现同款问题,在反复尝试后终于发现!
- 一定要用
activate激活对应虚拟环境,因为上述操作仅针对于使用的虚拟环境进行,直接运行上述操作不起作用导致问题无法解决 - 一定要
cd到代码根目录路径,如涉及跨盘需在路径前加/d

出现红框中的内容即表示出坑成功!可在浏览器中复制打开网址 http://localhost:8097查看后续代码运行的可视化结果
二号坑:python scripts/script.py --predict相关报错
1号报错:
无论是训练还是测试代码均需运行代码python -m visdom.server -port=8097,否则会报错如下,报错关键词“目标计算机积极拒绝,无法连接”、“Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.”
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=8097): Max retries exceeded with url: /env/main (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001855F442970>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。'))
[WinError 10061] 由于目标计算机积极拒绝,无法连接。
on_close() takes 1 positional argument but 3 were given
Visdom python client failed to establish socket to get messages from the server. This feature is optional and can be disabled by initializing Visdom with `use_incoming_socket=False`, which will prevent waiting for this request to timeout.
……
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
2号报错:
成功爬出一号坑后,根据论文作者要求新打开一个终端(完成路径转换和虚拟环境激活)运行python scripts/script.py --predict进行数据的测试。如需测试自己的数据,将数据替换掉路径./test_dataset/test A下的数据即可。而后报错如下:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
该报错原因是windows下测试时,子进程递归创建导致的,需要修改程序入口,具体做法是,在predict.py中,把要运行的代码段放进if __name__ == '__main__':中:
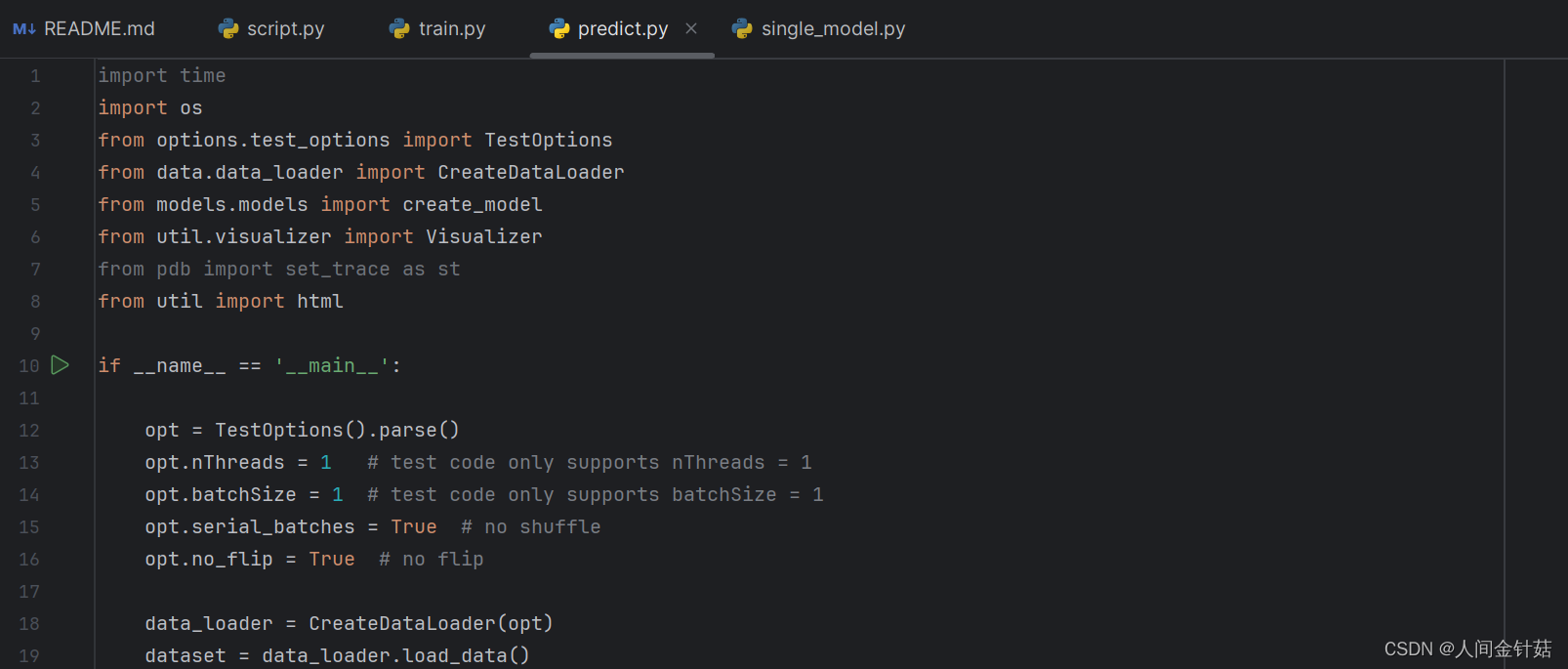
指导贴来源:EnlightenGAN 开源代码运行
3号报错:
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
原因是程序默认都在同一个卡上跑,所以会出现内存不足的情况,解决方法除了将batchSize继续减小,或可以考虑在predict.py代码开头加上如下代码,为该代码的运行指定一个可用的GPU卡。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
未解之谜
运行成功后的结果将保存在根目录下的“.\ablation\enlightening\test_200\images”文件路径下,但在测试代码中visdom可视化始终蓝屏无显示,经其他代码测试visdom显示功能正常,因此怀疑是作者在测试数据时可能未进行可视化显示,但由于笔者个人学习经验有限,尚不确定,请路过的各位大佬如有清楚原因或做过类似代码复现的多多指教。
爬坑完结撒花o( ̄▽ ̄)ブ~希望自己不成熟的经验能够帮助到有需要的大家
再次鸣谢其中涉及指导贴的各位大佬作者!















 5762
5762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









