







1、多值赋值
- 多值赋值语义
多值赋值看似简化了代码,但相互引用会让人产生困惑。多值赋值包含两层语义
(1)对左侧操作数中的表达式、索引值进行计算和确定,首先确定左侧的操作数地址,然后对右侧的赋值表达式进行计算,如果发现右侧的表达式计算引用了左侧的变量,则创建左侧变量的临时变量进行值拷贝,最后完成计算。
(2)从左到右依次赋值。
package main
import "fmt"
func main(){
x := []int{1,2,3}
i := 0
x[i],i = 2,x[i] //temp = x[0] x[0] = 2 i = temp i->1
fmt.Println(i,x)
}
- 执行结果:1 [2,2,3]
- 结果分析:先计算赋值语句(=)左右两侧 x[i] 中索引 i 的值,此时i=0,两个被赋值的变量是 i 和 x[0],两个赋值变量分别为2、x[0]。由于x[0]是左边的操作数,所以编译器会创建一个临时变量temp,即temp = x[0],然后从左到右依次执行赋值操作x[0] = 2 i = temp。
- 通过这种方式可以很好的写一个交换两个数值的程序
package main
import "fmt"
func main(){
a,b := 1,2
fmt.Println("a = ",a," b = ",b)
a,b = b,a //temp = a,a = b,b = temp
fmt.Println("a = ",a," b = ",b)
}
2、range复用临时变量
- 先上一段代码
package main
import "sync"
func main(){
wg := sync.WaitGroup{}
si := []int{1,2,3,4,5,6,7,8,9,10}
for i := range si {
wg.Add(1)
go func(){
println(i)
wg.Done()
}()
}
wg.Wait()
}
- 运行结果
9
9
9
9
9
9
9
9
9
9
程序没有达到我们的预期,而是全部打印9。有两点原因导致的:
(1)for range下的迭代变量 i 的值是共用的。
(2)main函数所在的goroutine和后续启动的goroutine存在竞争关系。
- 正确的写法是使用函数参数做一次数据复制,而不是闭包。
package main
import "sync"
func main(){
wg := sync.WaitGroup{}
si := []int{1,2,3,4,5,6,7,8,9,10}
for i := range si {
wg.Add(1)
//这里有一个实参到形参的值拷贝
go func(a int){
println(a)
wg.Done()
}(i)
}
wg.Wait()
}
- 执行结果:可以按照预期输出
- 总结:
其实for range复用迭代变量不能说是一个缺陷,而是Go的设计者为了性能而选择的一种设计方案。因为大多情况下for循环块里的代码是在同一个goroutine里运行的,为了避免空间的浪费和GC的压力,复用了range迭代时的临时变量。所以注意:在for循环下调用并发时要复制迭代变量后再使用,不要直接使用for的迭代变量。
3、defer陷阱
- 第一个副作用是对返回值的影响
- 第二个副作用是对性能的影响
(1)defer和函数返回值:defer中如果引用了函数的返回值,则因引用形式的不同会导致不同的结果。
package main
func f1()(r int){
defer func (){
r++
}()
return 0
}
func f2()(r int){
t := 5
defer func(){
t = t + 5
}()
return t
}
func f3()(r int){
defer func(r int){
r = r + 5
}(r)
return 1
}
func main(){
println("f1=",f1()) //f1=1
println("f2=",f2()) //f2=5
println("f3=",f3()) //f3=1
}
f1、f2、f3三个函数的共同点就是它们都是带命名返回值的函数,函数返回值都是变量r。
- 函数调用方负责开辟栈空间,包括形参和返回值的空间。
- 有名的函数返回值相当于函数的局部变量,被初始化为类型的零值。
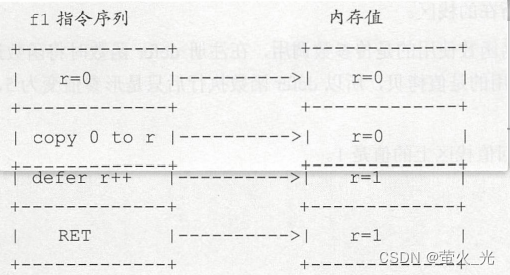
(1)分析f1函数,defer语句后面的匿名函数是对函数返回值r的闭包引用,f1的逻辑如下:
① r 是函数的有名返回值,分配在栈上,其地址又被称为返回值所在栈区。首先r先初始化为0。
② “return 0”会复制到返回值栈区,返回值 r 被赋值为0。
③ 执行defer语句,由于匿名函数对返回值 r 是闭包引用,所以 r++ 执行后,函数返回值被修改为1。
④ defer 语句执行完后RET返回,此时函数的返回值仍然为 1 。 - f1 的程序指令如下:
(2)f2的逻辑如下:
① 函数返回值 r 被初始化为 0。
② 创建局部变量 t ,并赋值为5。
③ 执行return t,将t的值 5 复制到返回值 r 所在的栈区。
④ defer语句后面的匿名函数是对局部变量 t 的闭包引用,t 被赋值为10。但是并不影响到 r。
⑤ 函数返回,此时函数返回值栈区上的值仍然是5。 - f2的程序指令如下:

(3)f3的逻辑如下:
① 函数返回值 r 被初始化为 0。
② 执行return 1,将1复制到 r 所在的栈区,此时 r = 1。
③ 执行defer,defer后面的匿名函数是对函数返回值 r 的闭包引用,此时使用的传参机制。在注册defer函数时将返回值 r 作为实参传进去,由于函数调用是值拷贝,所以defer函数执行后只是形参值变为5,对实参没有任何的影响。
④ 函数返回,此时返回栈区上的值是 1。 - f3的程序执行指令如下:r1为返回值,r2为匿名函数形参

综上所述:对于在defer的函数中返回有命名的函数返回值有三个步骤:
(1)执行return的值拷贝,将return语句返回的值复制到函数返回值栈区。(如果只有一个return,不带任何变量或值,则此步骤不做任何动作)
(2)执行defer语句,多个defer按照FIFO顺序执行。
(3)执行调整RET指令。
由此看出在defer中修改函数返回值不是一个明智的编程方法,在实际编程中应尽可能避免这种情况。还有一种彻底避免这种情况的发生的方法,就是在定义函数时使用不带有返回值名的形式。通过这种方法defer就不能直接引用返回值的栈区,也就避免了返回值被修改的问题。
package main
func f4() int {
r := 0
defer func(){
r++
}()
return r
}
func f5() int {
r := 0
defer func(i int){
i++
}(r)
return 0
}
func main(){
println("f4=",f4()) //f4=0
println("f5=",f5()) //f5=0
}
可以看到在函数返回值没有名字的前提下,不管defer如何操作,都不会改变函数的return的值。
4、切片
- nil切片和空切片
make([]int,0)与var a []int创建的切片是有区别的,前者的切片指针有分配,后者的切片指针为0。
package main
import "fmt"
import "reflect"
import "unsafe"
func main(){
var a []int
b := make([]int,0)
if a == nil {
fmt.Println("a is nil")
} else {
fmt.Println("a is not nil")
}
//虽然b的底层数组大小为0,但是切片不为nil
if b == nil {
fmt.Println("b is nil")
} else {
fmt.Println("b is not nil")
}
//使用反射reflect中的SliceHeader来获取切片运行时的数据结构
as := (*reflect.SliceHeader)(unsafe.Pointer(&a))
bs := (*reflect.SliceHeader)(unsafe.Pointer(&b))
fmt.Printf("len=%d,cap=%d,type=%d\n",len(a),cap(a),as.Data)
fmt.Printf("len=%d,cap=%d,type=%d\n",len(b),cap(b),bs.Data)
}
运行结果
a is nil
b is not nil
len=0,cap=0,type=0
len=0,cap=0,type=5537704
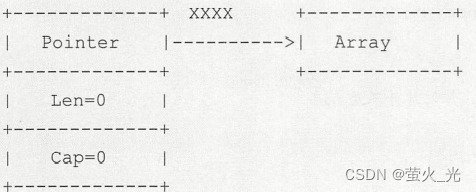
因此:var a []int 创建的切片是一个nil的切片(底层没有数组,指针指向nil)

make([]int,0)创建的是一个空切片(切片指针非空,但是指向的数组为空)
- 多个切片引用同一个底层数组引发的混乱
切片可以由数组创建,一个底层数组可以创建多个切片,这些切片共享同一个底层数组。使用append函数扩展切片的过程中可能会修改底层数组的元素,间接的影响到其他切片的值,也可能发生数组复制重建。
package main
import "fmt"
import "reflect"
import "unsafe"
func main(){
a := []int{0,1,2,3,4,5,6}
b := a[0:4] //0,1,2,3
as := (*reflect.SliceHeader)(unsafe.Pointer(&a))
bs := (*reflect.SliceHeader)(unsafe.Pointer(&b))
//a,b共享底层数组
fmt.Printf("a=v%,len=%d,cap=%d,type=%d\n",a,len(a),cap(a),as.Data)
fmt.Printf("b=v%,len=%d,cap=%d,type=%d\n",b,len(b),cap(b),bs.Data)
b = append(b,10,11,12) //0,1,2,3,10,11,12
//a,b继续共享底层数组,修改b会影响共享的底层数组,间接影响a
fmt.Printf("a=v%,len=%d,cap=%d\n",a,len(a),cap(a))
fmt.Printf("b=v%,len=%d,cap=%d\n",b,len(b),cap(b))
//len(b) = 7底层数组容量是7,此时需要重新分配数组,将原来数组中的元素复制到新的数组中,然后将新数组的首地址返回
b = append(b,13,14)
as = (*reflect.SliceHeader)(unsafe.Pointer(&a))
bs = (*reflect.SliceHeader)(unsafe.Pointer(&b))
//可以看到a和b指向的底层数组已经不同了
fmt.Printf("a=v%,len=%d,cap=%d,type=%d\n",a,len(a),cap(a),as.Data)
fmt.Printf("b=v%,len=%d,cap=%d,type=%d\n",b,len(b),cap(b),bs.Data)
}
运行结果:
a=[0,1,2,3,4,5,6],len=7,cap=7,type=842350575680
b=[0,1,2,3],len=4,cap=7,type=842350575680
a=[0,1,2,3,10,11,12],len=7,cap=7
b=[0,1,2,3,10,11,12],len=7,cap=7
a=[0,1,2,3,10,11,12],len=7,cap=7,type=842350575680
b=[0,1,2,3,10,11,12,13,14],len=9,cap=14,type=842350788720
- 总结:多个切片共享同一个底层数组,其中一个切片的append操作可能会引发如下两种情况:
- (1)append追加的元素没有超过底层数组的容量,此时append操作会直接操作共享的底层数组,如果其他切片有引用的数组被覆盖的元素,则会导致其他切片的值也隐式的发生变化。
- (2)append追加的元素加上原来的元素超过了底层数组的容量,此时append操作会重新申请新数组,并将原来的数组元素复制到新的数组,并返回新数组的首地址。
所以在使用切片的过程中尽量避免多个切片共享同一个底层数组,可以使用copy函数进行显式的复制。















 8830
8830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









