







图的遍历是指对图中所有结点和边进行一次且仅一次的访问操作。图的遍历可以分为深度优先遍历(DFS)和广度优先遍历(BFS)。
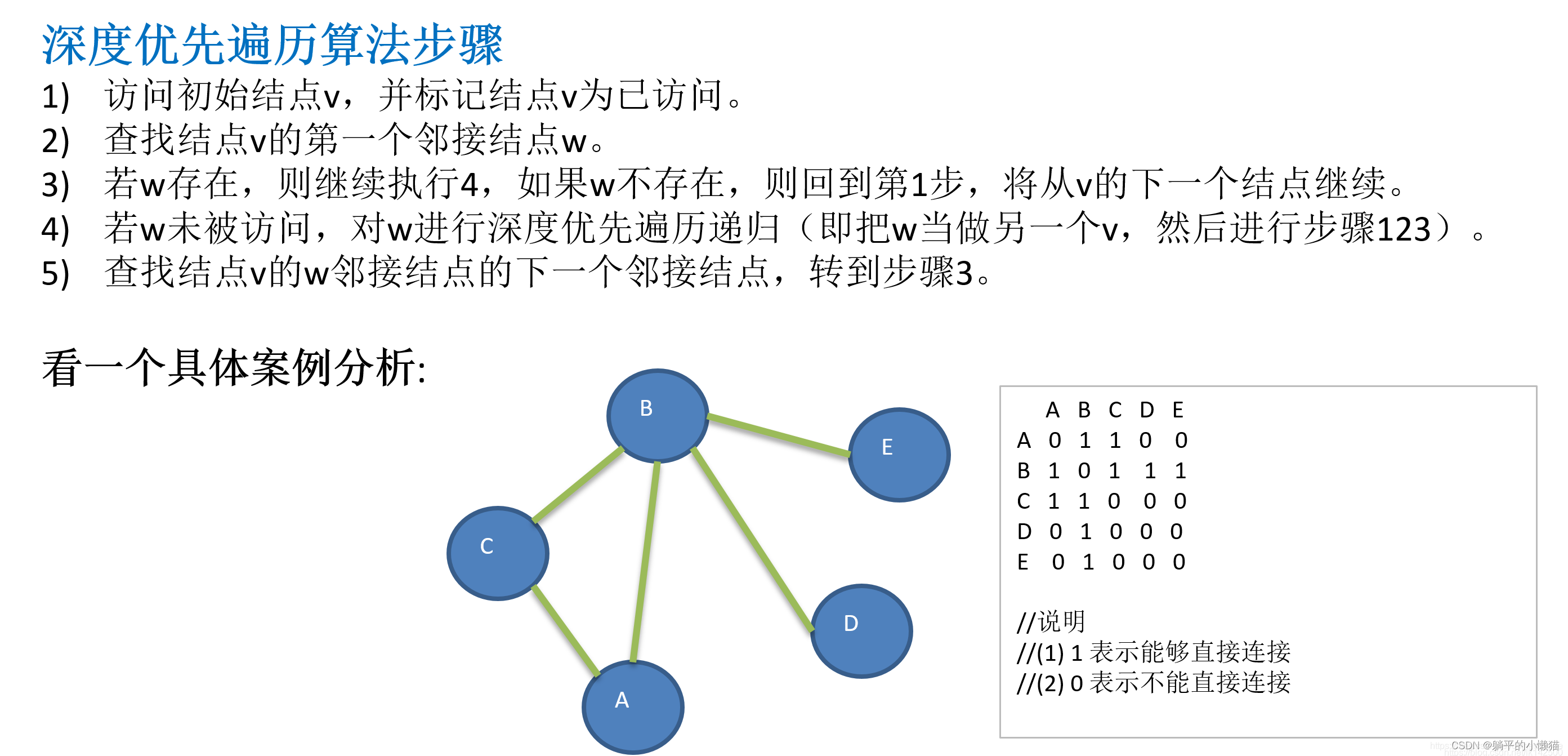
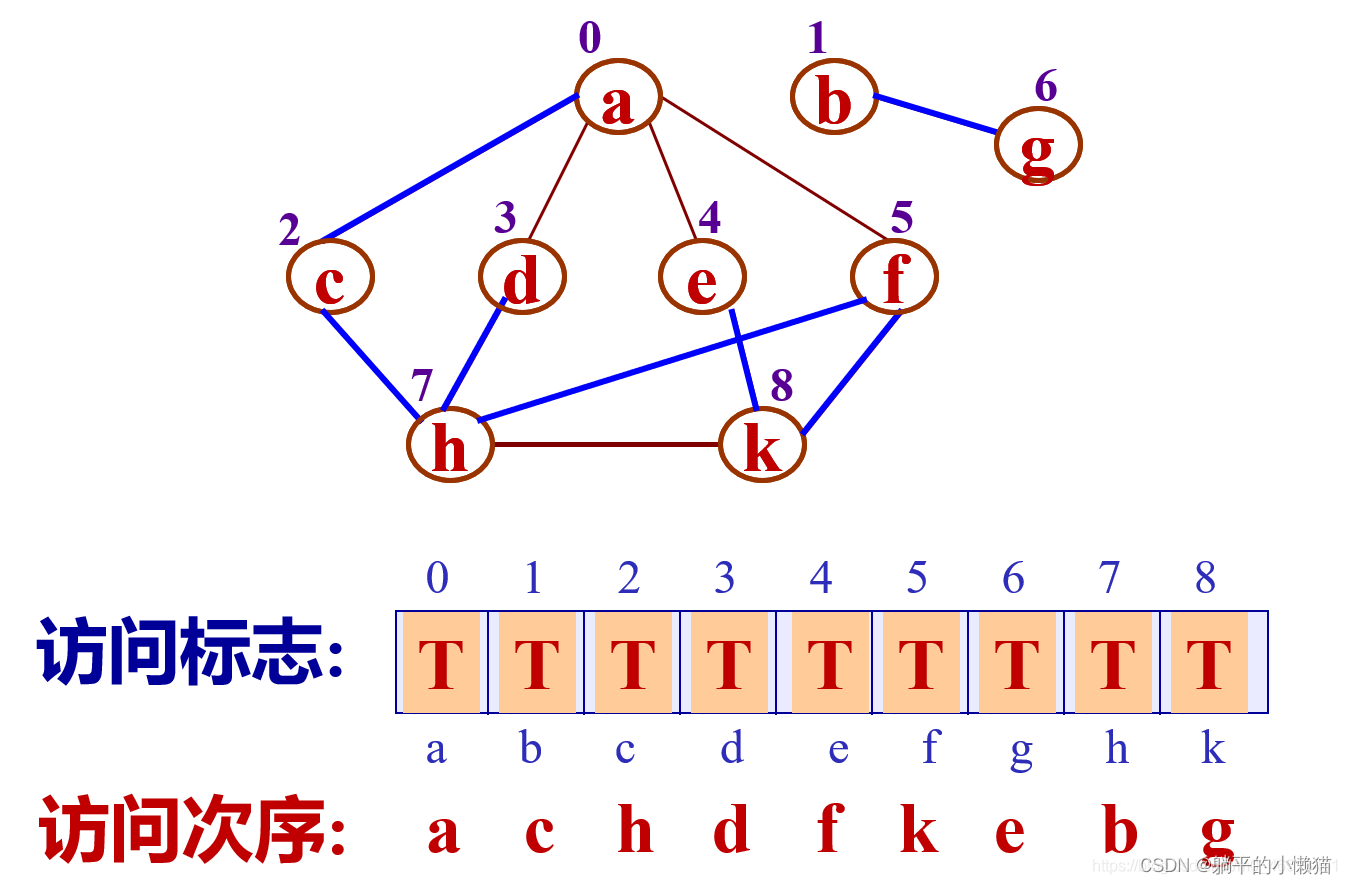
深度优先遍历采用栈实现,其基本思路是从图的某一结点出发,深度优先遍历该节点的所有邻接点,再依次对每个邻接点进行深度优先遍历。在遍历过程中,需要记录已经访问过的结点,避免重复访问。深度优先遍历是一种先纵向遍历到底再回溯的方法。
广度优先遍历采用队列实现,其基本思路是从图的某一结点出发,访问其所有邻接点,然后按照宽度遍历该结点的下一层邻接点。在遍历过程中,同样需要记录已经访问过的结点,避免重复访问。广度优先遍历是一种逐层遍历的方法,可以得到最短路径的长度。
图的遍历算法是图算法中最常用的算法之一,广泛应用于网络路由、迷宫寻路、社交网络分析等领域。
一、C 图的遍历 源码实现及详解
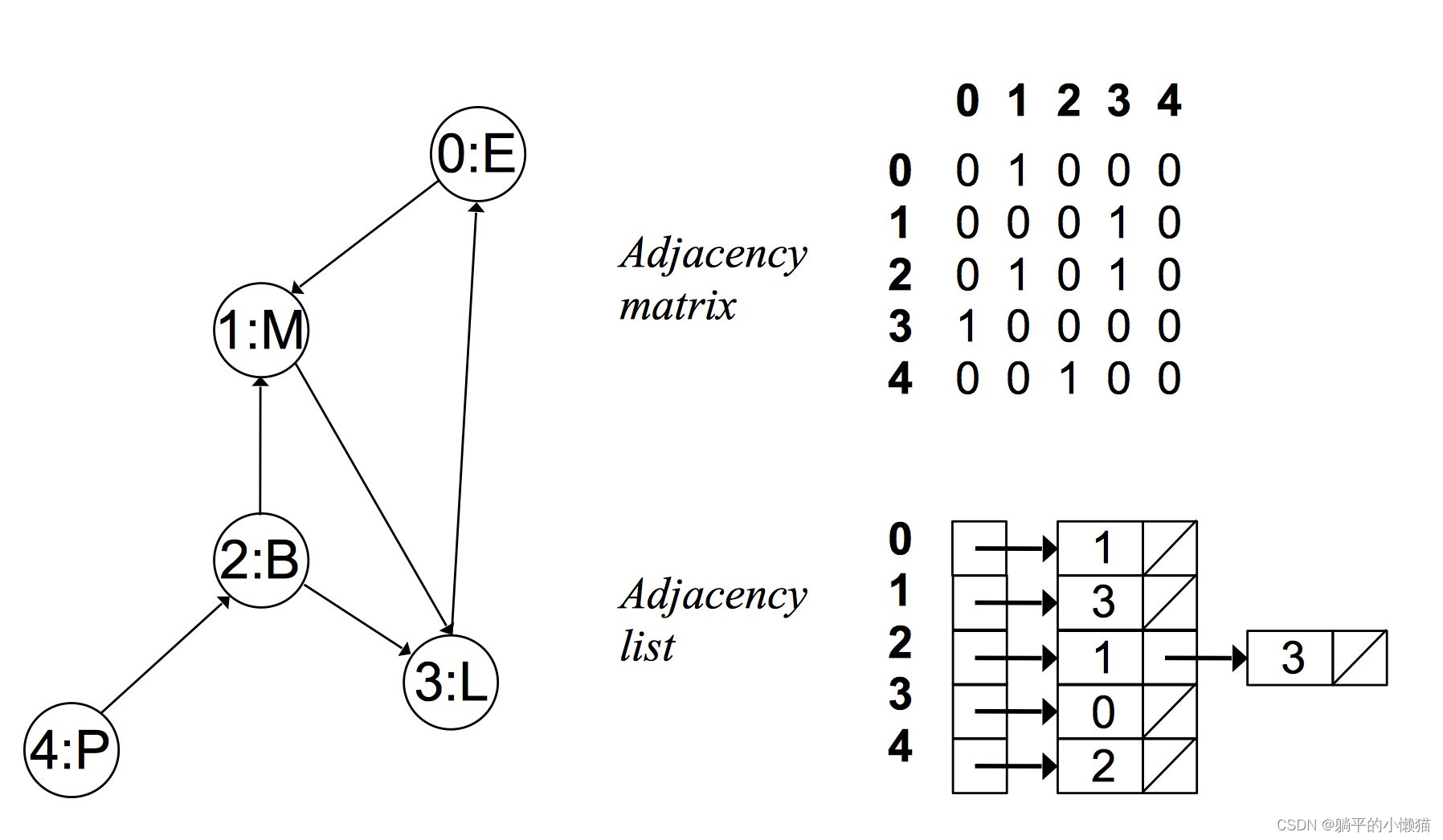
C语言中可以使用邻接矩阵或邻接表来表示图,不同的数据结构在遍历图的时候有着不同的算法实现。以下是邻接表表示图的遍历算法实现:
- 深度优先遍历(DFS):
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTICES 20
typedef struct node{
int vertex;
struct node* next;
} node;
int visited[MAX_VERTICES];
void DFS(node** adjacencyList, int vertex) {
visited[vertex] = 1;
printf("%d ", vertex);
node* ptr = adjacencyList[vertex];
while (ptr != NULL) {
int u = ptr->vertex;
if (visited[u] == 0) {
DFS(adjacencyList, u);
}
ptr = ptr->next;
}
}
int main() {
node* adjacencyList[MAX_VERTICES];
int noOfVertices, noOfEdges;
printf("Enter the number of vertices in the graph: ");
scanf("%d", &noOfVertices);
printf("Enter the number of edges in the graph: ");
scanf("%d", &noOfEdges);
for (int i = 0; i < noOfVertices; i++) {
adjacencyList[i] = NULL;
visited[i] = 0;
}
int vertex1, vertex2;
for (int i = 0; i < noOfEdges; i++) {
printf("Enter vertices for edge %d: ", i + 1);
scanf("%d%d", &vertex1, &vertex2);
node* newNode1 = (node*) malloc(sizeof(node));
newNode1->vertex = vertex2;
newNode1->next = adjacencyList[vertex1];
adjacencyList[vertex1] = newNode1;
node* newNode2 = (node*) malloc(sizeof(node));
newNode2->vertex = vertex1;
newNode2->next = adjacencyList[vertex2];
adjacencyList[vertex2] = newNode2;
}
int startingVertex = 0;
printf("Depth First Traversal, starting from vertex %d: ", startingVertex);
DFS(adjacencyList, startingVertex);
printf("\n");
return 0;
}
- 广度优先遍历(BFS):
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTICES 20
typedef struct node{
int vertex;
struct node* next;
} node;
int visited[MAX_VERTICES];
void BFS(node** adjacencyList, int startingVertex) {
visited[startingVertex] = 1;
printf("%d ", startingVertex);
int queue[MAX_VERTICES], front = -1, rear = -1;
queue[++rear] = startingVertex;
while (front != rear) {
int u = queue[++front];
node* ptr = adjacencyList[u];
while (ptr != NULL) {
int v = ptr->vertex;
if (visited[v] == 0) {
printf("%d ", v);
visited[v] = 1;
queue[++rear] = v;
}
ptr = ptr->next;
}
}
}
int main() {
node* adjacencyList[MAX_VERTICES];
int noOfVertices, noOfEdges;
printf("Enter the number of vertices in the graph: ");
scanf("%d", &noOfVertices);
printf("Enter the number of edges in the graph: ");
scanf("%d", &noOfEdges);
for (int i = 0; i < noOfVertices; i++) {
adjacencyList[i] = NULL;
visited[i] = 0;
}
int vertex1, vertex2;
for (int i = 0; i < noOfEdges; i++) {
printf("Enter vertices for edge %d: ", i + 1);
scanf("%d%d", &vertex1, &vertex2);
node* newNode1 = (node*) malloc(sizeof(node));
newNode1->vertex = vertex2;
newNode1->next = adjacencyList[vertex1];
adjacencyList[vertex1] = newNode1;
node* newNode2 = (node*) malloc(sizeof(node));
newNode2->vertex = vertex1;
newNode2->next = adjacencyList[vertex2];
adjacencyList[vertex2] = newNode2;
}
int startingVertex = 0;
printf("Breadth First Traversal, starting from vertex %d: ", startingVertex);
BFS(adjacencyList, startingVertex);
printf("\n");
return 0;
}
在这些算法实现中,我们使用了邻接表来表示图,并使用DFS和BFS算法遍历了图。DFS算法保证了对于每个节点,每个邻接边只被访问了一次,算法的时间复杂度为O(V + E),其中V是顶点数,E是边数。BFS算法同样保证了每个邻接边只被访问了一次,并且在遍历过程中可以求出每个节点到起始节点的最短路径,算法的时间复杂度为O(V + E)。
二、C++ 图的遍历 源码实现及详解
以下是C++中图的遍历的源码实现及详解:
定义一个Graph类,包含以下成员变量和成员函数:
class Graph {
private:
int V; //顶点数
list<int>* adj; //邻接表
//深度优先遍历
void DFS(int v, bool visited[]);
public:
Graph(int v);
~Graph();
//添加边
void addEdge(int v, int w);
//广度优先遍历
void BFS(int s);
//深度优先遍历
void DFS();
};
Graph类的构造函数和析构函数:
//构造函数
Graph::Graph(int v) {
V = v;
adj = new list<int>[v];
}
//析构函数
Graph::~Graph() {
delete[] adj;
}
Graph类的addEdge函数,用于添加一条边:
void Graph::addEdge(int v, int w) {
adj[v].push_back(w);
adj[w].push_back(v);
}
Graph类的BFS函数,用于广度优先遍历:
void Graph::BFS(int s) {
//创建一个标记数组,初始值都是false
bool* visited = new bool[V];
for (int i = 0; i < V; i++) {
visited[i] = false;
}
//创建一个队列
list<int> queue;
//标记起点为访问过的,并将起点放入队列中
visited[s] = true;
queue.push_back(s);
//遍历队列
while (!queue.empty()) {
//取出队列首元素并访问
s = queue.front();
cout << s << " ";
queue.pop_front();
//遍历邻接表,将未访问过的邻居放入队列中
for (auto i = adj[s].begin(); i != adj[s].end(); i++) {
if (!visited[*i]) {
visited[*i] = true;
queue.push_back(*i);
}
}
}
delete[] visited;
}
Graph类的DFS函数,用于深度优先遍历:
void Graph::DFS(int v, bool visited[]) {
//标记当前点为已访问过
visited[v] = true;
cout << v << " ";
//遍历邻接表,递归访问未访问过的邻居
for (auto i = adj[v].begin(); i != adj[v].end(); i++) {
if (!visited[*i]) {
DFS(*i, visited);
}
}
}
void Graph::DFS() {
//创建一个标记数组,初始值都是false
bool* visited = new bool[V];
for (int i = 0; i < V; i++) {
visited[i] = false;
}
//遍历所有未访问过的点
for (int i = 0; i < V; i++) {
if (!visited[i]) {
DFS(i, visited);
}
}
delete[] visited;
}
以上就是C++中图的遍历的源码实现及详解。
三、java 图的遍历 源码实现及详解
图是一种非线性数据结构,它具有许多实际应用。图的遍历是指从指定的起始顶点开始访问图中的所有顶点。常用的两种遍历方式为深度优先遍历和广度优先遍历。下面分别介绍这两种遍历方式的源码实现及详解。
深度优先遍历(DFS)
深度优先遍历是一种先序遍历方式,即从起点开始,访问一条路径上的所有顶点直到无法继续为止,然后回溯到之前的顶点,继续访问其他路径。这种遍历方式通常使用递归实现。
以下是深度优先遍历的核心代码:
public void dfs(int v, boolean[] visited) {
visited[v] = true;
System.out.print(v + " ");
for (int w : adj[v]) {
if (!visited[w]) {
dfs(w, visited);
}
}
}
其中,v表示当前顶点的编号,visited是一个布尔数组,表示每个顶点是否已经被访问过。adj是一个邻接表,表示各个顶点之间的关系。
具体实现过程如下:
- 将当前顶点
v标记为已访问; - 输出当前顶点
v; - 遍历
v的所有邻居顶点w:- 如果
w未被访问过,则递归访问w。
- 如果
使用样例:
public void testDfs() {
Graph g = new Graph(5);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(0, 4);
g.addEdge(1, 3);
g.addEdge(2, 3);
g.addEdge(3, 4);
g.dfs(0);
}
输出结果为:
0 1 3 2 4
广度优先遍历(BFS)
广度优先遍历是一种按层遍历方式,即从起点开始,先访问所有与其相邻的顶点,然后继续访问与这些顶点相邻的所有顶点,以此类推,直到遍历完所有顶点为止。这种遍历方式通常使用队列实现。
以下是广度优先遍历的核心代码:
public void bfs(int s) {
boolean[] visited = new boolean[V];
LinkedList<Integer> queue = new LinkedList<>();
visited[s] = true;
queue.add(s);
while (queue.size() != 0) {
s = queue.poll();
System.out.print(s + " ");
for (int w : adj[s]) {
if (!visited[w]) {
visited[w] = true;
queue.add(w);
}
}
}
}
其中,s表示起始顶点的编号,visited是一个布尔数组,表示每个顶点是否已经被访问过。adj是一个邻接表,表示各个顶点之间的关系。
具体实现过程如下:
- 将起始顶点
s标记为已访问,并将其入队; - 当队列不为空时,取出队首元素
s,并输出; - 遍历
s的所有邻居顶点w:- 如果
w未被访问过,则将其标记为已访问,并将其入队。
- 如果
使用样例:
public void testBfs() {
Graph g = new Graph(5);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(0, 4);
g.addEdge(1, 3);
g.addEdge(2, 3);
g.addEdge(3, 4);
g.bfs(0);
}
输出结果为:
0 1 2 4 3
以上是深度优先遍历和广度优先遍历的源码实现及详解。需要注意的是,在实际应用中,图的遍历可以使用多种数据结构和算法实现,具体实现方式需根据具体情况进行选择。















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









