






目录
1 DeepSeek-V3
DeepSeek V3模型的核心架构和技术特点体现在以下几个方面:
混合专家架构(MoE):DeepSeek-V3采用了混合专家架构,这种架构通过将模型分解为多个专家网络,并在每个输入上动态选择最合适的专家进行计算,从而在保持高性能的同时大幅降低了计算资源的消耗。例如,DeepSeek-V3拥有6710亿个参数,但在每个词元激活时仅使用370亿个参数,这种稀疏激活机制使得模型在推理时更加高效。
多头潜在注意力机制(MLA):该机制通过低秩联合压缩,减少了推理过程中的键值缓存需求,提高了推理效率。与传统的多头注意力机制相比,MLA在保持性能的同时,显著降低了内存占用和计算复杂度。
无辅助损失的负载均衡策略:在混合专家架构中,专家负载均衡是一个关键问题。DeepSeek通过动态调整路由偏置的方式,解决了专家负载不均的问题,避免了因使用辅助损失而导致的性能退化,从而确保了模型训练和推理的稳定性和高效性。
多词元预测(MTP)训练目标:与传统的单词元预测相比,MTP训练目标允许模型在一次前向传播中预测多个词元,这不仅提高了模型的训练效率,还显著提升了模型在多个任务上的表现,为推测性解码等推理优化提供了支持。
FP8混合精度训练:DeepSeek支持FP8精度的计算和存储,这一技术大幅降低了训练过程中的GPU内存需求和存储带宽压力,使得大规模模型的训练更加可行和高效。
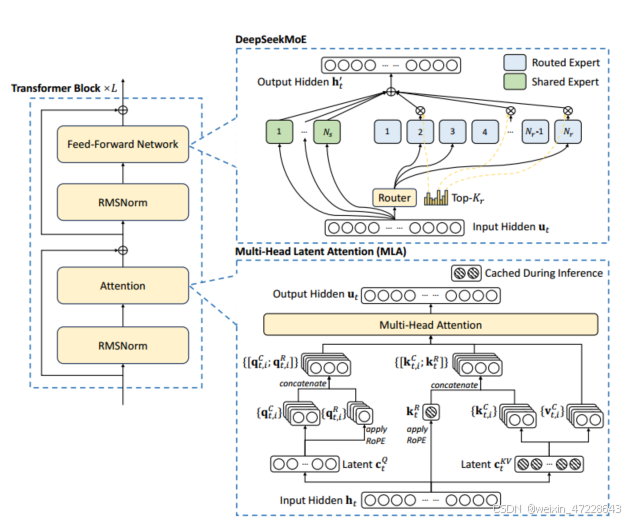
deepseek主体仍然采用transformer架构,但对其attention模块和FFN模块分别进行了改进。
1.1 多头潜在注意力机制MLA
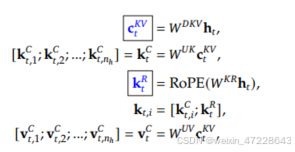
在注意力方面,deepseek采用Multi-Head Latent Attention(MLA)机制,其核心是对注意力键和值进行低秩联合压缩,以减少推理时的KV cache(键值缓存)。
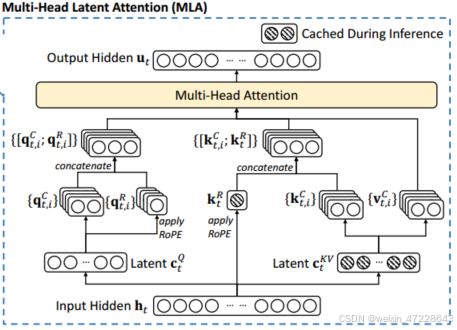
对于输入h_t,通过向下投影矩阵映射到潜在向量,再通过向上投影矩阵映射到多维度的向量,并对q和k进行旋转位置编码ROPE,将位置编码分别级联到相应的q和k,该注意机制仅需要缓存图中带阴影部分的向量,使得KV缓存显著减少,同时保持与标准多头注意力相当的性能,其具体表达式如下:
最终,注意力q、k,v组合产生最终的注意力输出,即
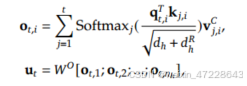
1.2 混合专家架构MOE
对于前馈网络(FFN),DeepSeek-V3采用了DeepSeekMoE架构。
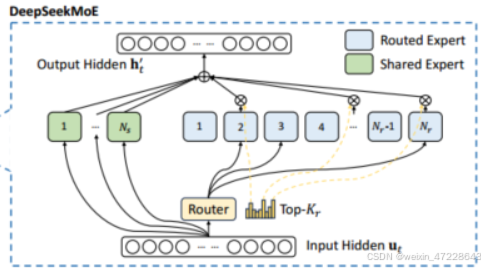
绿色框为N_s个共享专家,所有输入都会调用该专家,蓝色框为N_r个路由专家,每次根据输入与键的亲和度选出关联性最高的k个专家调用。即
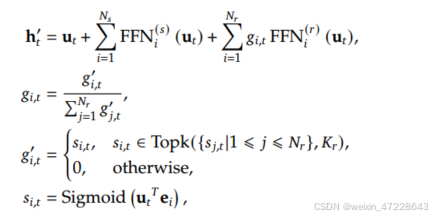
1.3 负载均衡
对于MoE架构,不平衡的专家负载将导致路由崩溃,并在具有专家并行性的场景中降低计算效率。为了在负载平衡和模型性能之间实现更好的权衡,我们开创了一种无冗余损失的负载平衡策略来确保负载平衡。具体来说,我们为每个专家引入了一个偏差项𝑏𝑖,并将其添加到相应的亲和度得分中。
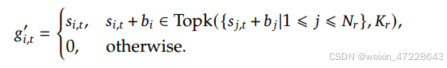
需要注意的是,偏置项仅用于路由。与FFN输出相乘的门控值仍然来自原始的亲和力得分𝑠𝑖𝑡。在训练过程中,我们不断监控每个训练步骤的整个批次的专家负载。在每一步结束时,如果对应的专家过载,我们将减少偏置项,𝛾如果对应的𝛾专家欠载,我们将增加偏置项,其中𝛾是一个超参数,称为偏置更新速度。通过动态调整,DeepSeek-V3在训练过程中保持平衡的专家负载,并且比通过纯辅助损失来鼓励负载平衡的模型实现更好的性能。
1.4 多词元预测MTP
MTP使用多个顺序模块预测多个额外的tokens。第k个MTP模块由共享的embedding层、共享输出头、TRM块、投影矩阵组成。
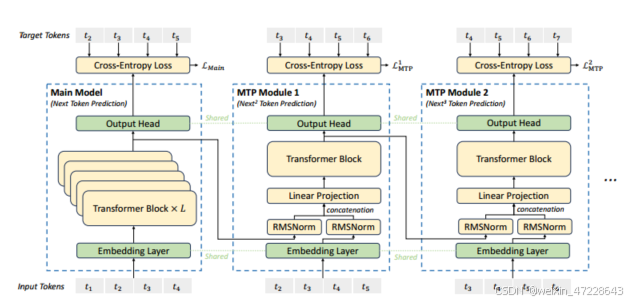
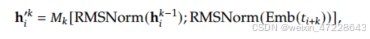
最后以h作为输入,共享输出头将计算第n个附加预测tokens的概率分布:
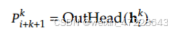
对于每个MTP模块,计算其交叉熵损失,即

最后计算所有MTP损失的平均值,并乘以加权因子,以获得整体MTP的损失,这是deepseekV3的额外训练目标。
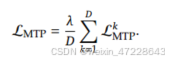
MTP策略主要是为了提高主模型的性能,因此在推理过程中,我们可以直接丢弃MTP模块,主模型可以独立正常工作。此外,我们还可以将这些MTP模块重新用于推测解码,以进一步改善生成延迟。
2 DeepSeek-R1
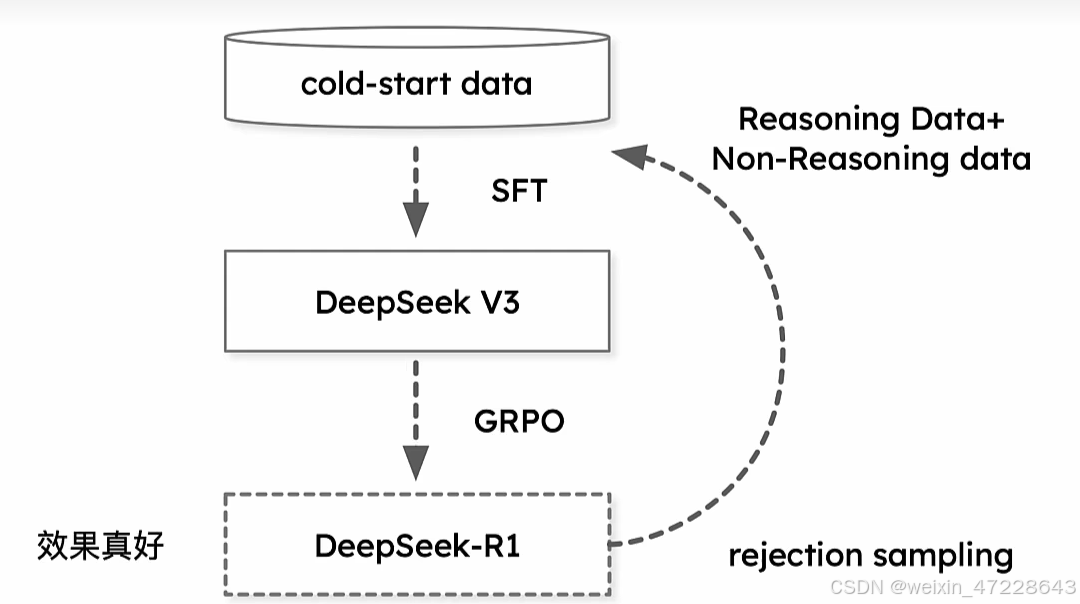
在deepseekV3基础上进行后训练。基于基础模型的大规模强化学习·我们直接将强化学习应用于基础模型,而不依赖监督微调(SFT)作为初始步骤。这种方法允许模型探索解决复杂问题的思想链(CoT),从而开发了DeepSeek-R1-Zero。DeepSeek-R1-Zero是一种通过大规模强化学习(RL)训练的模型,没有监督微调(SFT)作为初步步骤,展示了卓越的推理能力。通过强化学习,DeepSeek-R1-Zero自然会出现许多强大而有趣的推理行为。然而,它遇到了可读性差,语言混合等挑战。为了解决这些问题并进一步增强推理性能,我们引入了DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeekR 1实现了与OpenAI-o 1相当的性能。
以前的工作严重依赖于大量的监督数据来提高模型性能。在这项研究中,我们证明了即使不使用监督微调(SFT)作为冷启动,也可以通过大规模强化学习(RL)显着提高推理能力。此外,通过包含少量冷启动数据,可以进一步提高性能。在以下部分中,我们提出:(1)DeepSeek-R1-Zero,它直接将RL应用于基础模型,而无需任何SFT数据;(2)DeepSeek-R1,它从检查点开始应用RL,并通过数千个长思想链(CoT)示例进行微调。
2.1 DeepSeek-R1-Zero
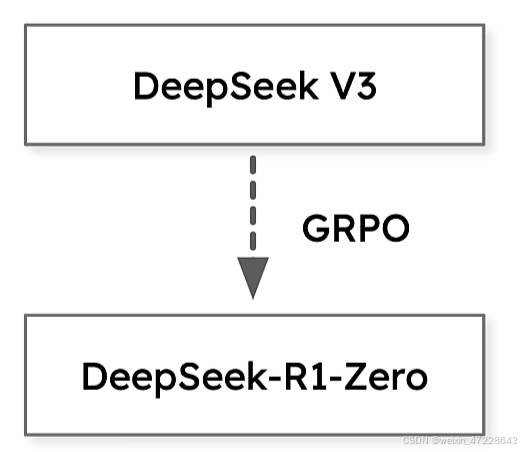
DeepSeek-R1-Zero整体训练流程如上图。其直接使用强化学习,无需任何SFT数据,这里用的强化学习是Group Relative Policy Optimization(GRPO)算法,它丢掉了与policy模型大小相同的critic模型,并从组得分中估计baseline。具体来说,对于每个问题,GRPO从旧策略策略模型中抽取一组输出{o1,o2,· · ·,oG},然后通过最大化以下目标来优化策略模型:
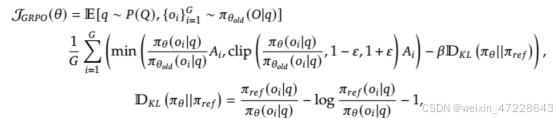
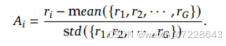
奖励模型是训练信号的来源,决定了强化学习的优化方向,采用了基于规则的奖励系统,包括准确性奖励和格式奖励:
准确性奖励模型评估响应是否正确。例如,在具有确定性结果的数学问题的情况下,模型需要以指定格式(例如,在框内)提供最终答案,从而实现可靠的基于规则的正确性验证。类似地,对于LeetCode问题,编译器可以用于基于预定义的测试用例生成反馈。
格式奖励:除了准确性奖励模型之外,我们还采用了格式奖励模型,该模型强制模型将其思维过程置于“”和“”标签之间。
助手首先在脑海中思考推理过程,然后向用户提供答案。推理过程和答案分别包含在和标签中,即推理过程在这里答案在这里。
2.2 DeepSeek-R1
受到DeepSeek-R1-Zero的鼓舞,两个自然的问题出现了:1)通过将少量高质量数据作为冷启动,可以进一步提高推理性能或加速收敛吗?2)我们如何训练一个用户友好的模型,不仅可以产生清晰连贯的思想链(CoT),而且还可以展示强大的通用能力?为了解决这些问题,我们设计了DeepSeek-R1。由四个阶段组成,概述如下。
- 冷启动
与DeepSeek-R1-Zero不同的是,为了防止从基础模型开始RL训练的早期不稳定冷启动阶段,对于DeepSeek-R1,我们构建并收集了少量的长CoT数据来微调模型作为初始RL actor。为了收集这些数据,我们探索了几种方法:以长CoT的少镜头提示为例,直接提示模型生成详细的答案,并进行反思和验证,以可读格式收集DeepSeek-R1 Zero输出,并通过人工注释器的后处理来细化结果。 - 面向推理的强化学习
在根据冷启动数据对DeepSeek-V3-Base进行微调后,我们应用了与DeepSeek-R1-Zero相同的大规模强化学习训练过程。该阶段的重点是增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及定义明确的问题和明确的解决方案。在训练过程中,我们观察到CoT经常表现出语言混合,特别是当RL提示涉及多种语言时。为了减轻语言混合的问题,我们在RL训练期间引入语言一致性奖励,其被计算为CoT中目标语言单词的比例。 - 拒绝采样和监督微调
当面向推理的强化学习收敛时,我们利用产生的检查点为下一轮收集SFT(Supervised Fine-Tuning)数据。与主要关注推理的初始冷启动数据不同,这个阶段合并了来自其他领域的数据,以增强模型在编写,角色扮演和其他通用任务中的能力。 - 适用于所有场景的强化学习
为了进一步使模型与人类偏好保持一致,我们实现了第二个强化学习阶段,旨在提高模型的有用性和无害性,同时改善其推理能力。
2.3 GRPO算法原理
LLM中主流的RLHF方向分为两大路线:
- 以PPO为代表的on policy路线
强化学习中的 PPO(Proximal Policy Optimization) 是 OpenAI 提出的一种策略优化算法,它在保证策略更新稳定性的同时,提高了训练效率和易用性。PPO 属于 基于策略梯度(Policy Gradient) 方法的一种改进。PPO 的目标是 在策略更新时防止“走太远”,从而避免训练不稳定或崩溃的问题。它通过一种 剪切(Clipping)策略 或 KL散度惩罚 来控制更新幅度。 - 以DPO为代表的off policy路线
DPO 不再通过“最大化奖励”来训练,而是直接通过人类的偏好对比来优化模型的策略。
PPO最大化以下函数:
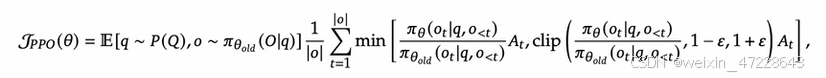
其中,Πθ和Πθold表示当前和旧的策略模型,q和o表示从问题数据集和旧策略数据集采样的问题和输出,At是优势,clip是裁剪函数,用于稳定策略更新的幅度,防止幅度过大。
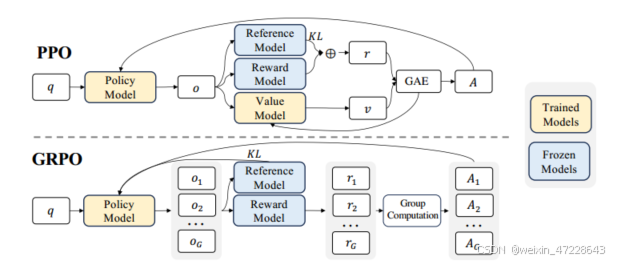
由于PPO中使用的值函数通常是与策略模型大小相当的另一个模型,因此它带来了大量的内存和计算负担。此外,在RL训练期间,值函数被视为计算方差减少优势的基线。而在LLM上下文中,通常只有最后一个令牌被奖励模型分配奖励分数,为了解决这个问题,如图4所示,我们提出了组相对策略优化(GRPO),它避免了像PPO中那样需要额外的值函数近似,而是使用多个采样输出的平均奖励,更具体地说,对于每个问题𝑞,GRPO从旧策略中抽取一组输出{𝑜1,𝑜2,· · ·,𝑜𝐺}𝜋𝜃𝑜𝑙𝑑,然后通过最大化以下目标来优化策略模型:
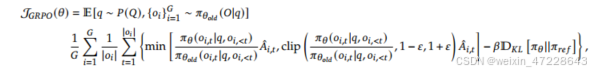
其中,𝜀和𝛽是超参数,𝐴𝑖,𝑡仅基于每个组内输出的相对奖励计算的优势。GRPO利用的组相对方式来计算优势,与奖励模型的比较性质非常一致,因为奖励模型通常是在同一问题的输出之间的比较数据集上训练的。还要注意,不是在奖励中添加KL惩罚,GRPO通过直接将训练策略和参考策略之间的KL偏差添加到损失中来进行正则化,从而避免了复杂的𝐴𝑖,𝑡计算。
KL散度是用来衡量两个概率分布之间差异的“距离度量”。
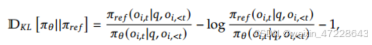
参考:https://www.bilibili.com/video/BV1dHw4e8E3e/?spm_id_from=333.1296.top_right_bar_window_history.content.click&vd_source=342608b137921d7af176a2c07667a8fc
https://www.bilibili.com/video/BV18iNBehEwq?spm_id_from=333.788.videopod.sections&vd_source=342608b137921d7af176a2c07667a8fc


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









