






一、前言
自然语言处理的主导范式包括对一般领域数据的大规模预训练和对特定任务或领域的适应。当我们预训练更大的模型时,重新训练所有模型参数的传统微调变得不太可行。以GPT-3 175 B为例,部署许多独立的微调模型实例,每个实例都有175 B参数,这是非常昂贵的。我们提出了低秩自适应,或LoRA,其冻结预训练的模型权重并将可训练的秩分解矩阵注入到Transformer架构的每一层中,大大减少了下游任务的可训练参数数量。LoRA的性能与完全微调相当或优于完全微调。在GPT-3和GPT-2上调整模型质量,尽管具有更少的可训练参数,更高的训练吞吐量,并且没有额外的推理延迟。
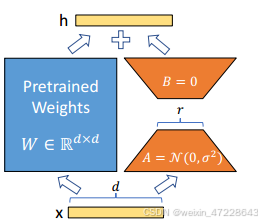
学习的过参数化模型实际上存在于低内在维度上。我们假设语言模型自适应中的更新矩阵也具有低“内在秩”,从而导致我们提出的低秩自适应(LoRA)方法。
LoRA允许我们通过注入和优化密集层更新的秩分解矩阵来间接训练神经网络中的每个密集层,同时保持原始矩阵冻结,如图所示。(即,图中的r可以是1或2)即使在满秩(即,d)高达12288时也足够,使得LoRA既有空间效率又有计算效率。
二、LoRA优势
- 一个预先训练好的模型可以共享,用于为不同的任务构建多个小的LoRA模块。我们可以将共享的原始模型保存在VRAM中,并通过替换图1中的矩阵A和B来高效切换任务,这显著降低了存储需求和任务切换开销。
- 它使训练更有效,并将硬件进入障碍降低了3倍,因为在使用自适应优化器时,我们不需要计算梯度或维护大多数模型参数的优化器状态。相反,我们只优化注入的低秩矩阵,它们的参数要少得多。
- 其简单的线性设计允许我们在部署过程中将更新矩阵与原始权重合并,不会引入推理延迟。
- LoRA与现有技术正交,可以与其中许多技术(如前缀调整)结合使用。我们在附录D中提供了
三、方法原理
- 更新矩阵的低秩约束。一个典型的神经网络包含许多执行矩阵乘法的密集层。这些层中的权重矩阵被允许具有满秩。然而,当适应特定任务时,Aghajanyan等人[1]表明,预训练的语言模型具有低“内在维度”,尽管进行了低维重新参数化,仍然可以有效地学习。受此观察的启发,我们想知道在适应下游任务时,权重的更新是否也具有低“内在秩”。对于预先训练的权重矩阵W0,我们通过用低秩分解来约束其更新。在训练期间,W0被冻结并且不接收梯度更新,而A和B包含可训练参数。请注意,W 0和BA都与相同的输入相乘,并且它们各自的输出向量按坐标求和。对于h = W0x,我们修改的前向传递:
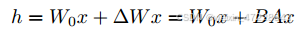
对A使用随机高斯初始化,对B使用零,因此在训练开始时,W = BA为零。 - 权重衰减到预训练权重。我们注意到LoRA的权重衰减行为与完全微调不同。具体而言,在A和B上执行通常的权重衰减类似于衰减回预训练权重,这已被研究为对抗“灾难性遗忘”的潜在有效形式的正则化。
- 权重衰减:在优化时,加一个惩罚项,倾向于让权重变小。
- 衰减到预训练权重:不仅是让权重接近0,而是让变化(LoRA参数)尽量小,相当于让整个模型偏好留在预训练的表示附近。
- 正则化优势:避免过拟合,保护预训练模型积累的知识,同时允许小范围内针对新任务的调整。
- 没有额外的推理延迟。在部署过程中,我们可以显式计算W = W0 +BA,并像往常一样执行推理。当我们需要切换到另一个下游任务时,我们可以通过减去BA然后添加不同的B0A0来恢复W0。这会导致峰值内存使用量略有增加,并增加不超过单个模型前向传递的模型切换延迟。关键是,我们在推理期间不引入任何额外的等待时间。
3.1 应用到transformer
原则上,我们可以将LoRA应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。在Transformer架构中,自注意力模块中有四个权重矩阵。(Wq; Wk; Wv; Wo)和MLP模中的两个。我们将Wq(或Wk,Wv)作为维度dmodel × dmodel的单个矩阵,尽管输出维度通常被切割成注意力头,但我们将我们的研究限制在仅改变下游任务的注意力权重,并冻结MLP模块(因此它们在下游任务中没有被训练),因为将LoRA应用于后者导致给定相同秩r的可训练参数的数量是4倍。
- 给定有限的参数预算,我们应该使用LoRA来适应哪些类型的权重,以获得下游任务的最佳性能?与调整具有较大秩的单一类型权重相比,更可取的是调整更多的权重矩阵。论文中调整qv层效果最佳。
- LoRA的最优秩r是多少?增加r并不能覆盖更有意义的子空间,这表明低秩自适应矩阵是足够的。无论 r=8 还是 r=64,最终权重变化矩阵的**主导方向(最大的几个奇异值对应的奇异向量)**几乎是一样的。而其他方向可能包含训练期间积累的大部分随机噪声,这些方向如果让它们存在,反而可能导致过拟合或者模型性能下降。
- 实质:微调权重变化的矩阵,其奇异值谱(SVD spectrum)是长尾快速衰减的;只有头部几维(top-k singular directions)很重要,后面都是noise;低秩近似 = 保留重要部分,自动丢弃噪声。
- 适应性矩阵△W与W相比如何?与随机矩阵相比,△W与W具有更强的相关性,表明△W放大了W中已经存在的一些特征。其次,△W只放大W中未被强调的方向,而不是重复W的顶部奇异方向。第三,放大因子相当大:21.5 约为6.91/0.32,(r = 4)。这表明,低-秩自适应矩阵潜在地放大了在一般预训练模型中学习但未强调的特定下游任务的重要特征。
论文:《LoRA: Low-Rank Adaptation of Large Language Models》

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









