







介绍
Meta提出的ImageBind是一种学习跨六种不同模态(图像、文本、音频、深度、热和IMU数据)联合嵌入的方法。它实际上利用了大规模视觉语言模型,并通过与图像配对将零样本功能扩展到一种新的模态。
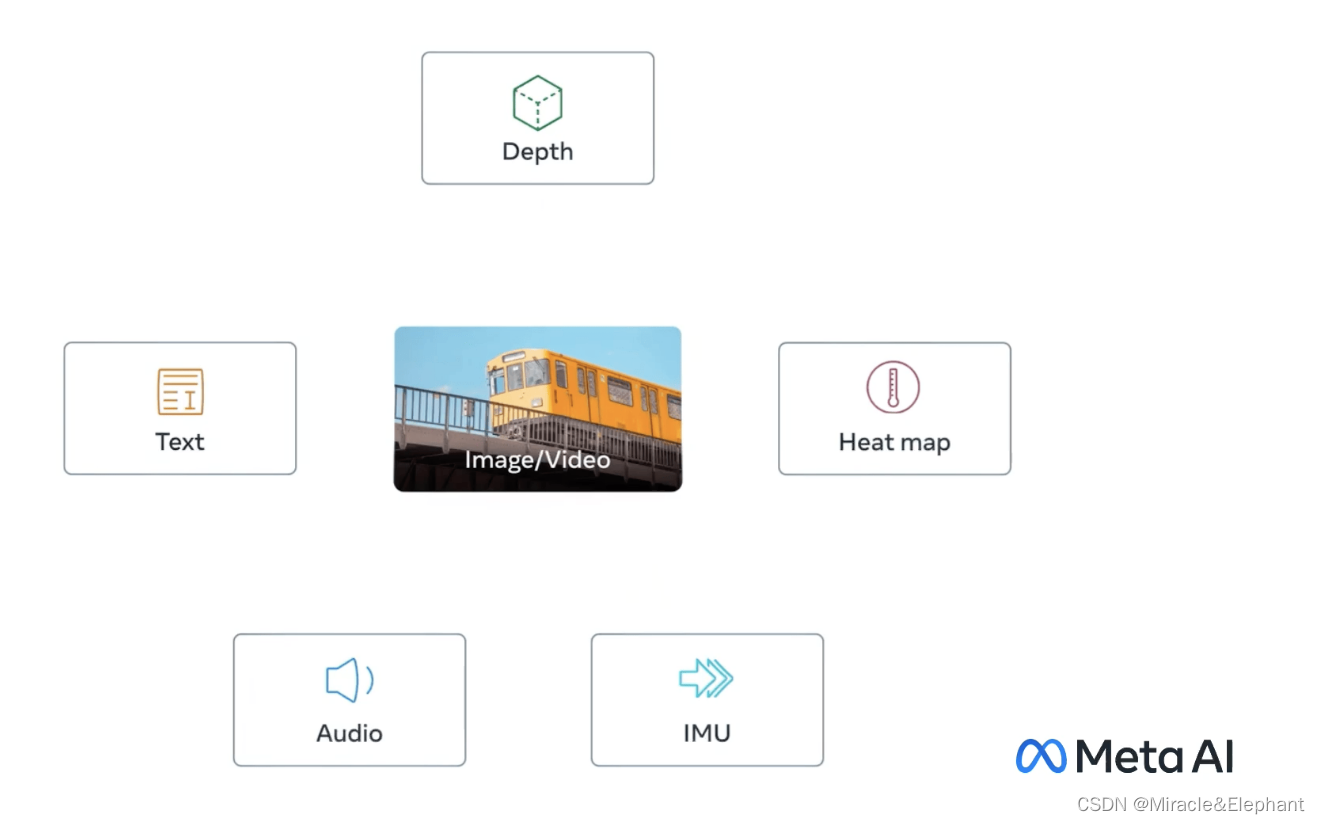
人天生具有多种感官,能同时感受到视觉、听觉、触觉。同时人的记忆也存在多种感受的记忆,望梅止渴,通过视觉引发味觉感受。
多模态的模型意图是训练一个具有多种类型输入的模型,并且能够输出对多重感官带来的知觉。
涉及到的一个关键问题是数据的标注和对其问题,需要输入多类型的数据,标注是个难题,ImageBind的方法是以图片数据作为核心数据,其他的数据与其对其,这样就解决了多种数据之间的对其问题。
文字在模型的训练过程中扮演者重要角色,文字可以作为提示词存在,并且问题包含的信息是显示的,明确的。
论文中提出模型在训练后,在one-shot的不同测试中,表现出乎意料。即使只使用对(I,M1)和(I,M2)进行训练,在嵌入空间中观察到对齐两对模态(M1,M2)的突发行为。【I 代表image, M 代表其他模态数据】,这一发现实现了未标注信息的对齐,对于模型高级功能的训练具有重要意义,减少了数据标注的工作量。
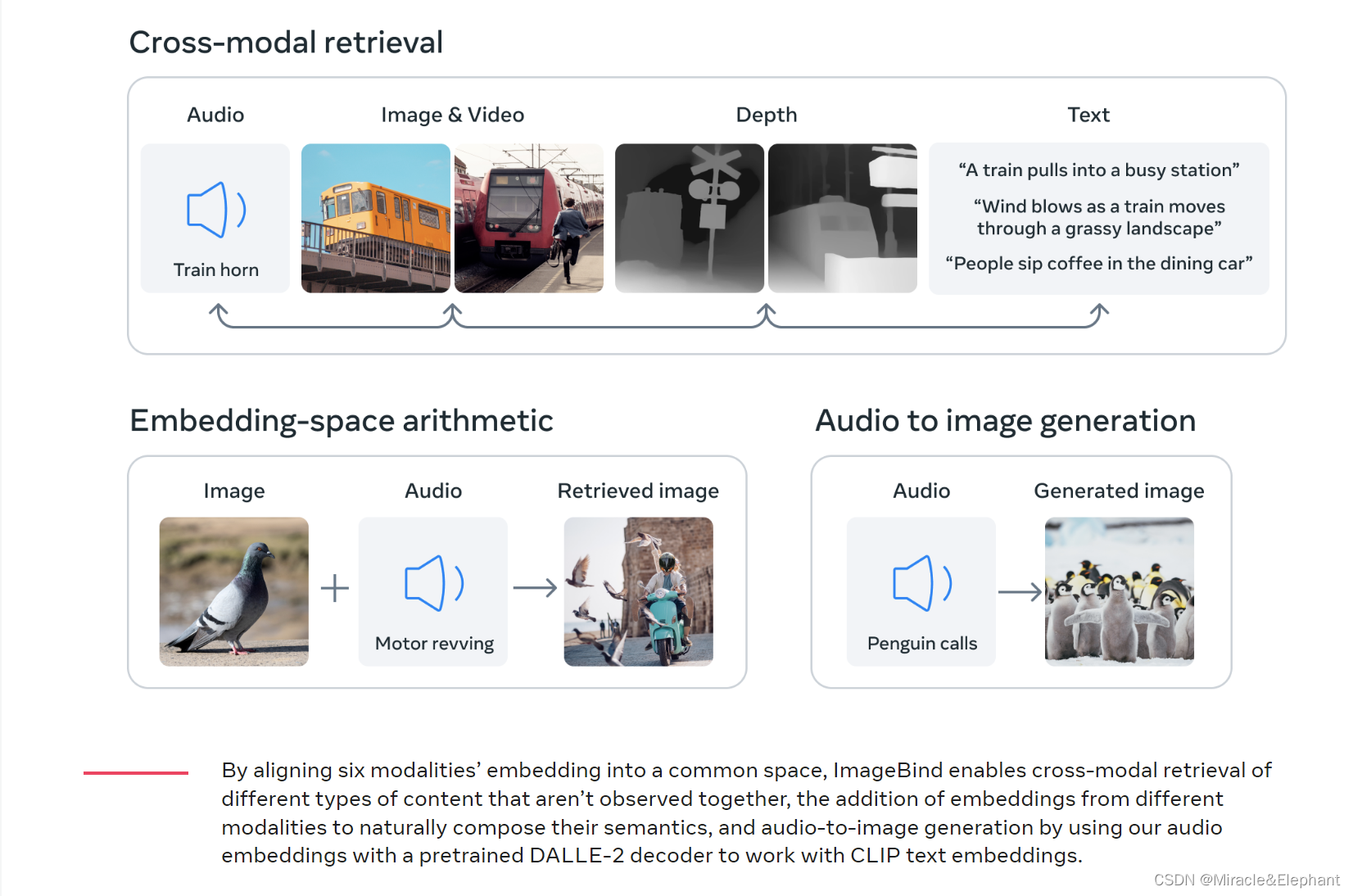
输入的数据包括深度,这是一个特别的地方,不是简单的2维图片,增加模型的感知维度。
模型的输入可以是多种数据的叠加,输出也是多样的,例如输入图像和声音,输出图像,输入声音输出图像。
由于输入是轻量级标注输入,模型的功能显得更加强大。
来源
官网项目介绍:
https://imagebind.metademolab.com/demo
用法
图片生成音频
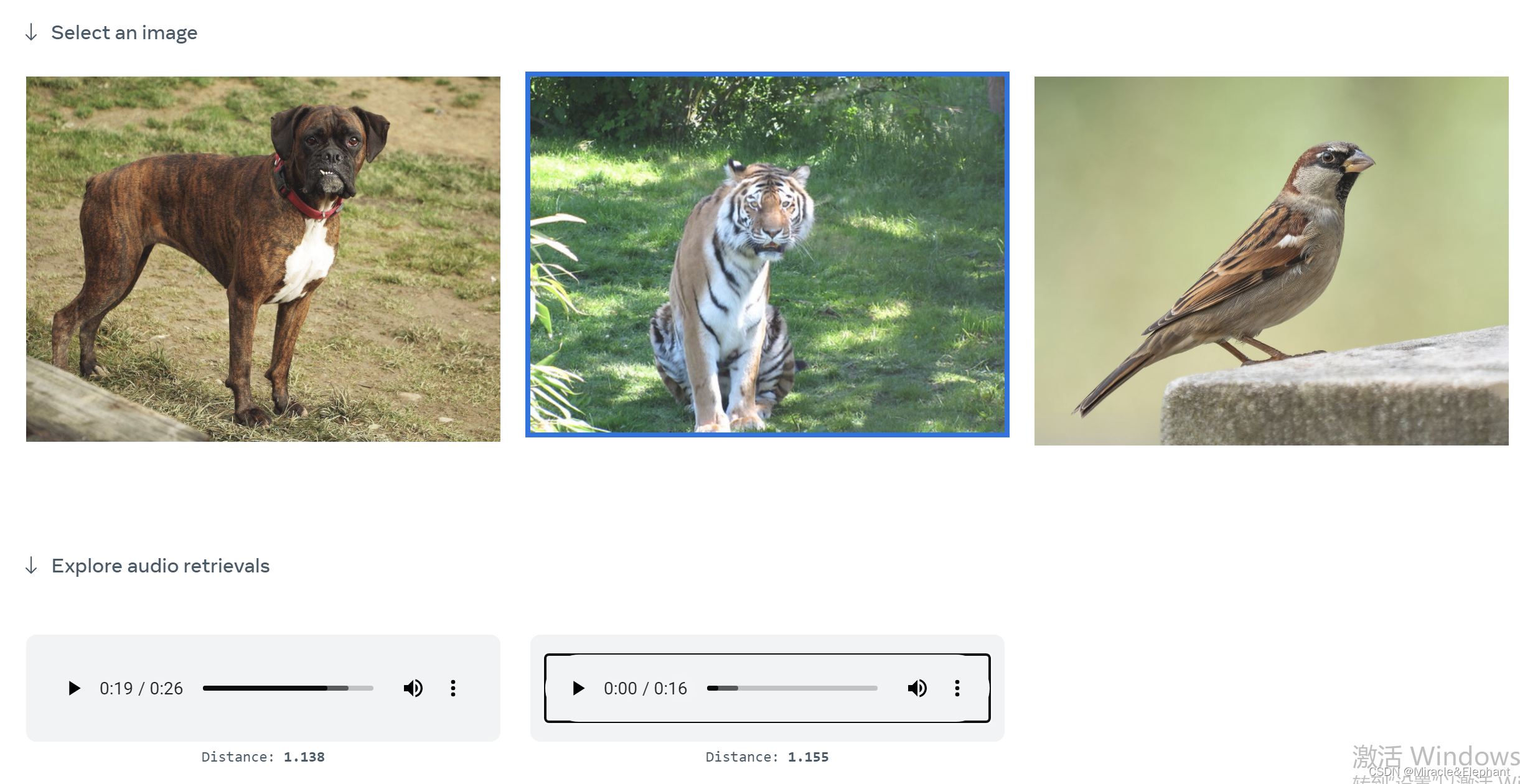
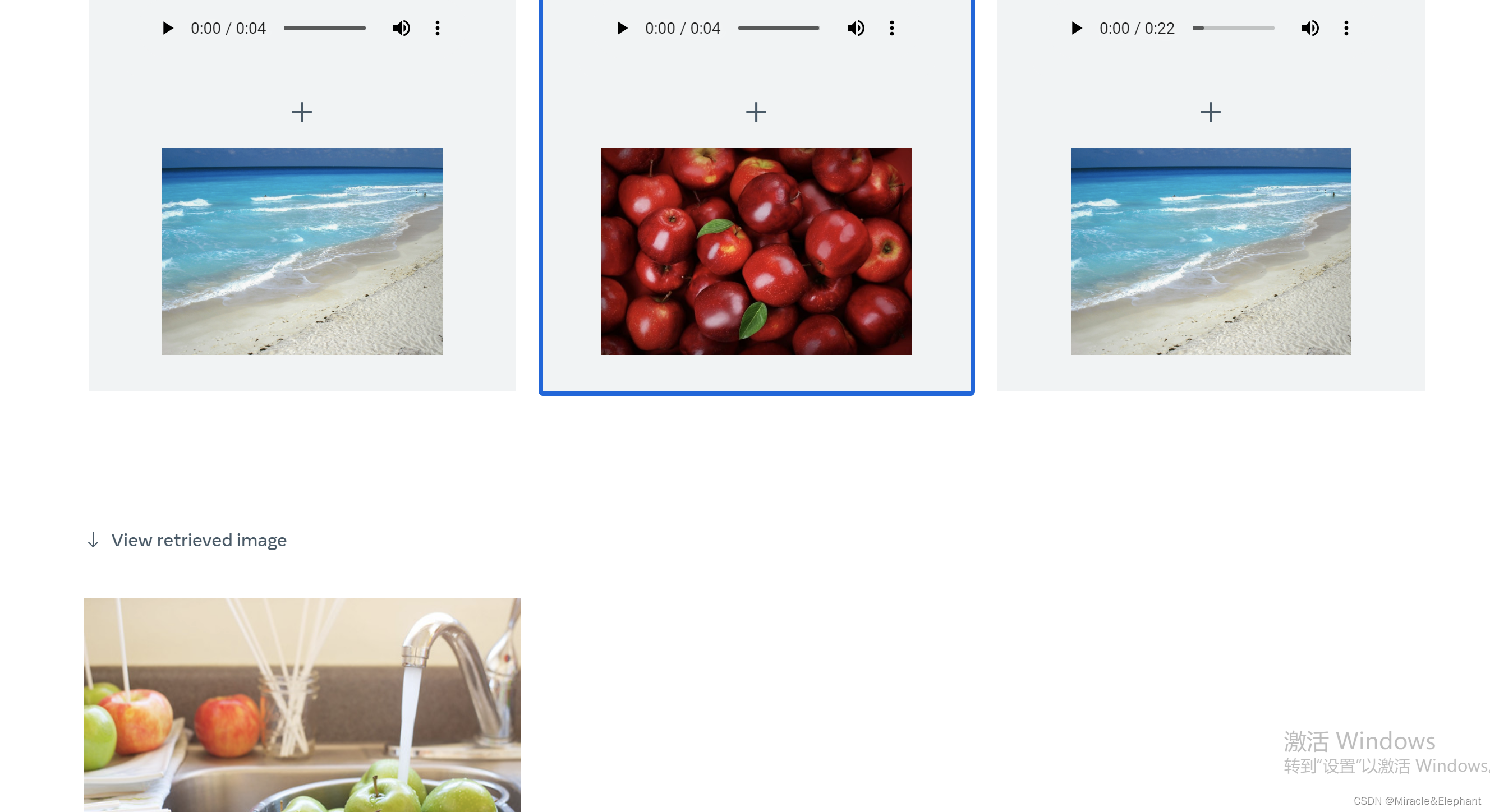
音频+图片生成图片
体会
论文中还提出,模型的这种功能类似翻译的功能,翻译模型能对没有见过的语句进行翻译。
后续的研究中应该会出现更多one-shot能力强大的模型,同时模型的多重感知能力会远超人类。
















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











