









23年9月来自新加坡国立大学的论文“NExT-GPT: Any-to-Any Multimodal LLM“。
多模式大语言模型(MM-LLM)大多受制于仅输入端多模态理解的限制,无法以多模态生成内容。由于人类总是通过各种方式感知世界并与人交流,开发能够以任何方式接受和传递内容的任意-对-任意MM-LLM对人类级人工智能至关重要。为了填补这一空白,本文提出一个端到端通用任意-对-任意MM-LLM系统,即NExT GPT。将LLM与多模态适配器和不同的扩散解码器连接起来,使NExT-GPT能够感知文本、图像、视频和音频的任意组合输入并生成输出。
通过现有训练有素的高性能编码器和解码器,NExT-GPT只用某些投影层的少量参数(1%)进行调整,这不仅有利于低成本的训练,还有利于方便地扩展到更潜在的模态上。此外,引入模态-切换指令调整(MosIT),并为MosIT手工筛选了一个高质量的数据集,在此基础上,NExT-GPT能够进行复杂的跨模态语义理解和内容生成。总的来说,该研究展示了建立一个能够建模通用模态的统一人工智能代理的可能性,为社区中更多类似人类的人工智能研究铺平了道路。
如图所示,NExT-GPT包括三层。首先,用已建立的编码器对各种模态输入进行编码,其中这些表示通过投影层投影到LLM可理解的、类似语言的表示中。其次,利用现有的开源LLM作为核心来处理输入信息,进行语义理解和推理;LLM不仅直接生成文本token,而且还生成唯一的“模态信号”token,用作指令去指示解码层是否而且以什么模态的内容相应地输出。第三,生成的具有特定指令的多模态信号,在投影后,发送到不同的编码器,并最终生成相应模态的内容。
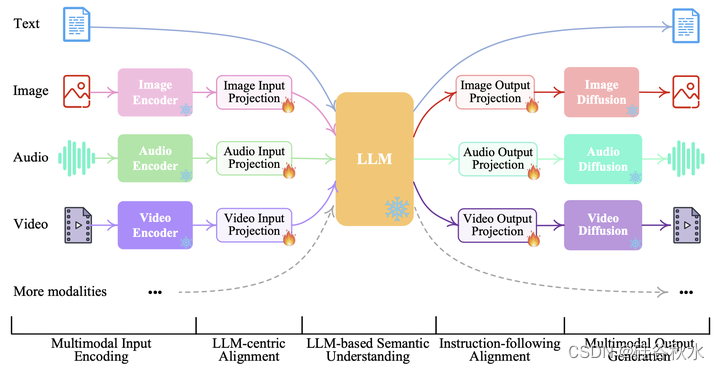
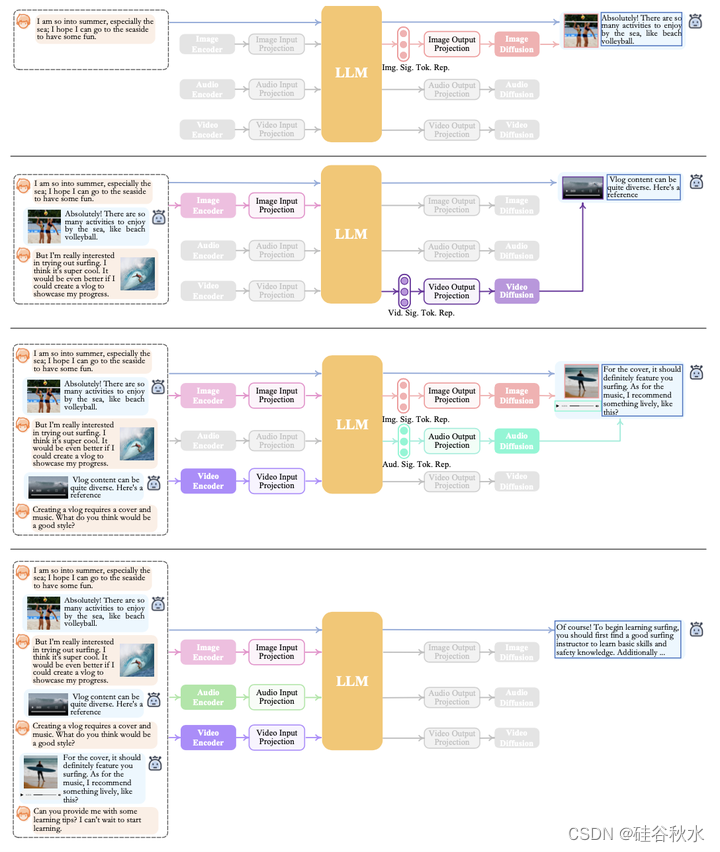
NExT-GPT由三个主要层次组成:编码阶段、LLM理解和推理阶段以及解码阶段。
多模态编码阶段。首先,用现有的成熟模型对各种模态输入进行编码。对于不同的模态,有一组编码器的替代方案,例如,Q-Former[43]、ViT[19]、CLIP[65]。这里利用ImageBind[25],一个跨六种模态的统一高性能编码器。使用ImageBind,可以省去管理大量异构模态编码器的麻烦。然后,通过线性投影层,不同的输入表示被映射为LLM可理解的类似语言表示。
LLM理解和推理阶段。LLM被用作NExT-GPT的核心智体,从技术上讲,选择Vicuna2[12],一种开源的基于文本的LLM,广泛用于现有的MM-LLM[77103]。LLM将来自不同模态的表示作为输入,并对输入进行语义理解和推理。直接输出的是1)文本响应,以及2)每个模态的信号token,这些信号token用作指令,去指示解码层是否生成多模态内容以及生成什么内容。
多模式生成阶段。接收来自LLM的具有特定指令的多模态信号(如果有的话),基于Transformer的输出投影层将信号token表示映射到多模态解码器可以理解的表示中。从技术上讲,选择当前现成的不同模态生成的潜在条件扩散模型,即用于图像合成的Stable Diffusion(SD)[68]、用于视频合成的Zeroscope[8]和用于音频合成的AudioLDM[51]。信号表示被馈送到用于内容生成的条件扩散模型所具备的条件编码器中。
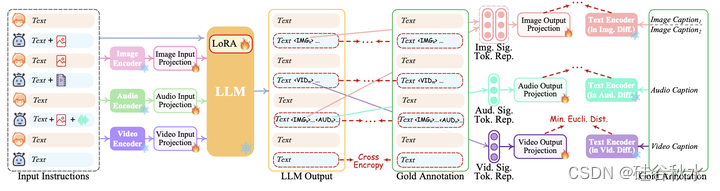
为了弥合不同模态特征空间之间的差距,并确保对不同输入的流畅语义理解,NExT-GPT进行对齐学习至关重要。由于设计的松耦合系统主要有三层,因此只需要更新编码端和解码端的两个投影层。如图所示是编码-解码的对齐学习示意图。
在编码端,根据现有MM LLM的常见实践,考虑将不同的输入多模态特征与文本特征空间对齐,为了实现对齐,从现有的语料库和基准中准备“X-caption”对数据,其中“X”代表图像、音频或视频。强制LLM针对字幕生成每个输入模态的字幕。如上图(a)所示。
在解码端,集成了来自外部资源的预训练条件扩散模型。主要目的是使扩散模型与LLM的输出指令保持一致。然而,在每个扩散模型和LLM之间执行全尺度对齐过程将带来显著的计算负担。或者,在这里探索一种更有效的方法,在解码侧进行指令-跟从对齐,如上图(b)所示。
具体而言,由于各种模态的扩散模型仅以文本表征输入为条件。这种条件与系统中LLM的模态信号token显著不同,这导致扩散模型对LLM指令的准确解释存在差距。因此,最小化LLM的模态信号token表示(在每个基于Transformer的投影层之后)与扩散模型的条件文本表示之间的距离。由于仅用文本条件编码器(扩散主干被冻结),因此学习仅基于纯字幕文本,即没有利用任何视觉或音频资源。这也确保了高度轻量级的训练。
尽管编码端和解码端都与LLM对齐,但在实现整个系统忠实地遵循和理解用户指令并生成所需多模态输出目标方面仍然存在差距。为了解决这一问题,进一步的指令调优(IT)[97,77,52]是增强LLM能力和可控性所必需的。它涉及使用“(INPUT,OUTPUT)”对来额外训练整体MM-LLM,其中“INPUT”表示用户指令,“OUTPUT”表示符合给定指令的所需模型输出。从技术上讲,采用LoRA[32]使NExT-GPT中的一小部分参数能够在指令调优(IT)阶段与两层投影同时更新。如下图所示,当IT对话样本被输入系统时,LLM重建并生成输入的文本内容(并用多模态信号token表示多模态内容)。优化是基于标注和LLM的输出进行的。除了LLM调整,还微调了NExT-GPT的解码端。将由输出投影编码的模态信号token表示与由扩散条件编码器编码的多模态字幕表示对齐。从而,全面的调整过程更加接近了和用户之间忠实有效互动的目标。

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









