







1. Spark 架构
Spark 遵循主从架构,即集群中由一个主服务器和若干个从服务器组成。
Spark 架构基于两个抽象:
- RDD:弹性分布式数据集
- DAG:有向无环图
1.1 Spark 运行架构
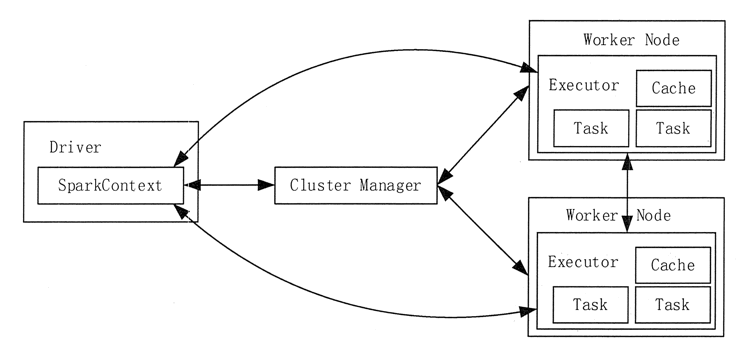
Spark 运行架构中包括:
- 集群资源管理器(Cluster Manager)
- Spark 驱动节点(Driver)
- 若干个工作节点(Worker Node)
1.2 Spark 组件
🌟 Application:
Spark Application 包含了一个 Driver 及多个 Executor。
🌟 Driver:
Spark 驱动节点,Driver 运行 Spark Application 的 main() 方法,创建SparkContext。SparkContext 负责和 Cluster Manager 通信,进行资源申请、任务分配和监控等。
Driver 在 Spark 作业执行时负责:
- 将用户程序转换为作业(Job)
- 在 Executor 之间调度任务(Task)
- 跟踪 Executor 的执行情况
- 通过 UI 展示查询 运行情况
🌟 Cluster Manager:
Cluster Manager 在 Standalone 模式中为 Master 节点,在 YARN 模式中为 Hadoop YARN Cluster Manager,在 Mesos 中为 Mesos Cluster Manager。Cluster Manager 负责声请和管理在 Worker Node 上运行应用所需的资源。
🌟 Executor:
Executor 为集群上的工作节点(Worker Node)中的 JVM 进程,负责运行 Task。Spark Application 启动时,Executor 被同时启动,并且伴随整个 Spark Application 的生命周期。
Executor 的两个核心功能:
- 负责运行组成 Spark Application 的 Task,并将结果返回给 Driver
- Executor 通过自身的块管理器(Block Manager)为 Application 中要求缓存的 RDD 提供内存存储(RDD 是直接缓存在 Executor 进程内,一次任务可以在运行时利用缓存数据加速运算)
🌟 Master & Worker:
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能。Master 是一个进程,负责资源的调度和分配,并进行集群的监控等职责;Worker 也是一个进程,一个 Worker 运行在集群中的一台服务器上,由 Master 分配资源对数据进行并行处理和计算。
Master 相当于 YARN 的 RM,Worker 相当于 YARN 的 NM
🌟 Application Master:
Hadoop 用户向 YARN 集群提交 Application 时,提交程序中包含 Application Master,用于向资源管理器申请执行任务的资源容器 Container,运行用户自己的任务(Job),监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
ResourceManager 和 Driver 之间的解耦合靠的就是 Application Master!
1.3 有向无环图
DAG(Directed Acyclic Graph):有向无环图,是由点和线组成的拓扑图,具有方向且不会闭环。运行每个 Applicaiotn 都会构建基于 Stage(TaskSet)的 DAG。
根据 RDD 之间的依赖关系(宽、窄依赖)将不同的 DAG 划分成不同的 Stage 。对于窄依赖,partition 的转换工作在 stage 中完成计算;对于宽依赖,由于存在 shuffle,只能在上一层 RDD 处理完成后,才能开始接下来的计算,所以宽依赖时划分 stage 的依据。
1.4 任务划分
RDD 任务可划分为:Application、Job、Stage、Task。
Application:初始化一个 SparkContext时,即生成一个 Application
Job:一个 Action 算子就会生成一个 Job
Stage:根据 RDD 之间的依赖关系将不同的 Job 划分成不同的 Stage ,遇到一个宽依赖则划分一个 Stage
Task:Stage 是一个 TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个 Task
2. 运行流程
1️⃣ Step1:构建 Spark Application 运行环境,启动 SparkContext;
2️⃣ Step2:SparkContext 向 Cluster Manager 注册,并申请 Executor 资源;
3️⃣ Step3:Master 根据 SparkContext 资源申请的要求和 Worker 心跳周期报告的信息决定在哪个 Worker 上分配资源,在相应的 Worker 上获取资源后,启动 StandaloneExecutorbackend;
4️⃣ Step4:StandaloneExecutorBackend 向 SparkContext 注册;
5️⃣ Step5:SparkContext 将 Application 分发给 Executor;
6️⃣ Step6:SparkContext 解析 Application ,构建 DAG 图,并交给 DAG Scheduler 分解成多个 Stage,
7️⃣ Step7:SparkContext 把每个 TaskSet(任务集)发送给 Task Scheduler (任务调度器);
8️⃣ Step8:Executor 向 SparkContext 申请 Task,Task Scheduler 将 Task 发放给 Executor;同时,SparkContext 将应用程序代码发放给 Executor;
9️⃣ Step9:Task 在 Executor 上由 StandaloneExecutorBackend 运行,StandaloneExecutorBackend 会建立 Executor 线程池,开始执行Task;
1️⃣0️⃣ Step10:执行结果将反馈给 Task Scheduler,然后再反馈给 DAG Scheduler;
1️⃣1️⃣ Step11:Task 运行完毕后写入数据,SparkContext 向 ClusterManager 注销并释放所有资源。
















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











