







改进聚合与更新策略的联邦推荐模型
FedFast: Going Beyond Average for Faster Training of Federated Recommender Systems
1、要解决的问题
传统的联邦学习框架中,模型是随机从服务器中选择用户来进行训练和更新而且在服务器端也只是通过简单的聚合操作来对合成全局模型。 这样会导致模型的参与者要投入大量精力进行训练并要与服务器端进行多次通信,而且这种框架所训练的推荐系统的准确度不高。【Faster】【Accurate】
2、之前对于此问题的研究
- 过去10年MF能够为CF算法提供一个很好的准确率,最近趋向与使用DNNs从多媒体数据获取额外信息来改进推荐算法,但是服务器从用户获得的数据时不稳定的。
- 了克服数据收集问题,联邦学习诞生了。尽管FL很有前景,但在RS上关注很少,但也有啥部分研究,比如基于元学习的、联邦协同过滤、改进准确率和模型大小的,他们大多都是在现有的FL模型提高准确率,但本文的方法提高收敛速度的。
- 现有只在选择可用用户子集进行加速训练,本文使用了一种更有效的样本采样方法来加速收敛。
- 本文使用隐式反馈的评分预测模型。
3、论文提到的解决该问题的关键思路
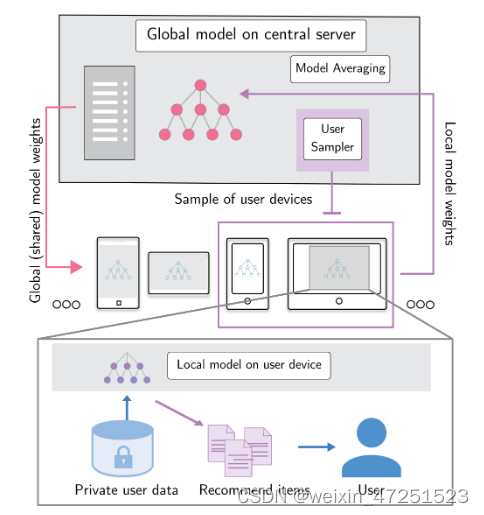
提出了新的用户采样机制(ActvSAMP)和模型更新机制(ActvAGG):先根据客户端的数据分布以及计算能力进行聚类,将客户端分成不同的簇,然后在每个簇内选取代表作为选中的待更新的客户端。之后进行模型更新,将更新的代表客户端的参数直接同步到同一簇内的其他客户端中。
4、算法模型
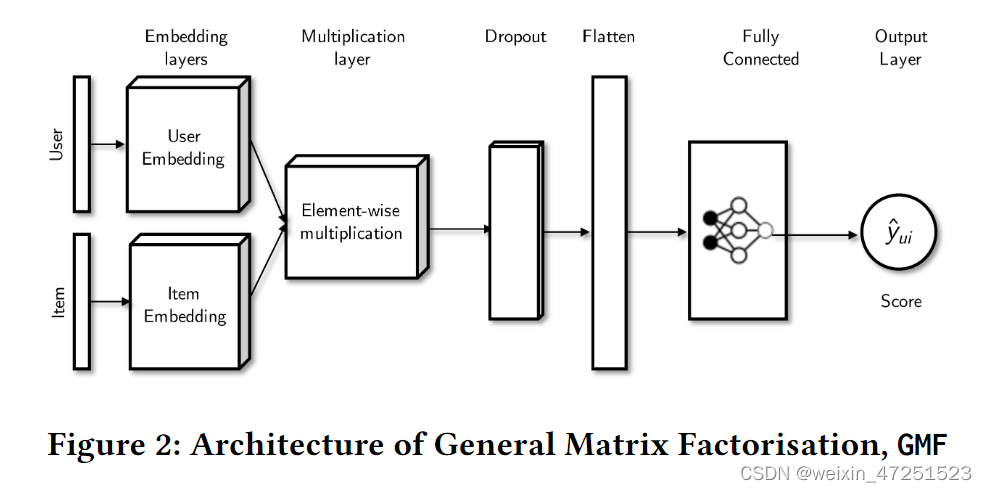
算法模型介绍
本文选择训练GMF模型,其中的参数为 w \ w w,将参数分为三部分:非embedding部分、item_embedding和user_embedding部分,算法一共训练t轮,每轮使用ActvSAMP选择一个代表用户集 S t \ S_t St, S t \ S_t St中有来自p个用户簇的m个代表用户。
算法1 整个模型的流程
涉及的参数:
w
0
\ w_0
w0表示初始化的权重,
w
t
\ w_t
wt表示第t轮训练后的参数集
P
0
\ P_0
P0表示初始的客户群分布,初始的客户群分布是根据用户的嵌入做聚类算法实现的
p
\ p
p表示将客户分为p个簇
S
t
\ S_t
St 第t轮训练中参与训练的代表客户集
m
\ m
m抽取出的客户数量

过程:
- 初始化参数 w 0 \ w_0 w0 P 0 \ P_0 P0 p \ p p
- 对客户集中K的客户进行聚类,生成一个初始的客户集群 G 0 \mathcal{G_0} G0(根据K-means聚类算法产生)
- 每轮更新的操作:
- 根据 m a x ( ⌈ α K ⌉ , 1 ) ) \ max(\lceil\alpha K \rceil,1)) max(⌈αK⌉,1))选取出要抽取的代表客户端数目m其中 α \alpha α表示的是抽取客户端的比例
- 使用ActvSAMP从分好簇的客户端中抽取本次训练的代表客户集 S t S_t St
- 对 S t S_t St中的每一个代表用户在他的本地端进行训练
- 每个代表用户k利用本地数据和本轮次的参数 w t w_t wt进行训练得到新的参数 w t + 1 w_{t+1} wt+1、 n k n_k nk
- γ = e − t \gamma=e^{-t} γ=e−t
- 使用ActvAGG进行参数的更新和聚合
10.循环步骤3-9直至模型收敛
算法2 ActvSAMP组件:根据已分好组的用户选出代表客户端集合
涉及的参数:
K
\ K
K 所有的用户集合
m
\ m
m抽取出的客户数量
G
\mathcal{G}
G 已经分好组的客户端集群(分组的过程不在这个组件)
S
S
S 组件生成的代表客户集

过程:
- 计算出分好的客户端集群中共有多少个客户端簇 p p p
- 从每个簇中随机选取 m / p m/p m/p个用户作为本簇的代表用户, S S S表示所有代表用户的集合
算法3 ActvAGG组件:进行参数的更新和聚合
涉及的参数:
S
\ S
S :第参与训练的代表客户端集合
w
0
\ w_0
w0 :上一轮的模型参数
n
k
\ n_k
nk: 客户端k上的样本数量
p
\ p
p : 将客户分为p个簇
返回值:
w
\ w
w :聚合后的模型参数
G
\mathcal{G}
G :已经分好组的客户端集群

过程:
整个过程分为四部分:非嵌入参数的更新、服务器端item_embedding的更新、代表客户端user-embedding的更新、从属客户端user-embedding参数的更新
- 对于非嵌入参数的更新
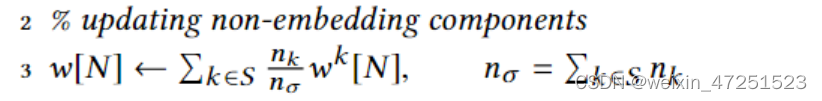
- 采用经典的FedAVG算法(non-embedding 表示网络中不负责embdding部分的网络,如figure2里的全连接网络)
- S中的每个代表客户在更新了自己的
w
k
[
N
]
w^k[N]
wk[N]后,直接根据自己的客户端的样本数作为权重进行聚合
- 对于物品嵌入参数的更新
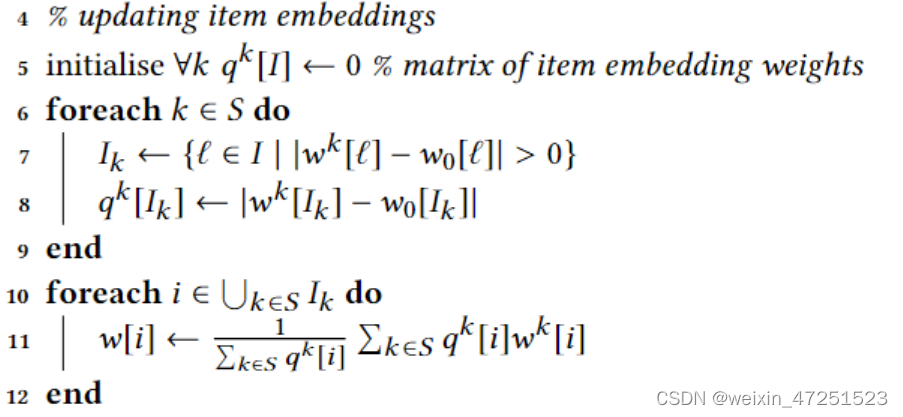
- 对于每一个用户k先初始化一个 q k [ I ] q^k[I] qk[I]矩阵表示物品嵌入矩阵
- 遍历S中的每一个代表用户k
a. 记录一个索引集合 I k I_k Ik 里面的每个元素 l \mathcal{l} l表示用户k对 l \mathcal{l} l的参数进行了更新(通过差值>0进行判断)
b. 用 q k [ I ] q^k[I] qk[I]来记录物品 I k I_k Ik中每个物品变化的绝对值作为更新的权重 - 更新
I
k
I_k
Ik中物品嵌入的值,遍历其中的每个物品
根据11行的公式更新物品嵌入,使用刚刚计算过的权重 q k [ I ] q^k[I] qk[I]来进行加权平均
- 对于代表用户用户嵌入的更新
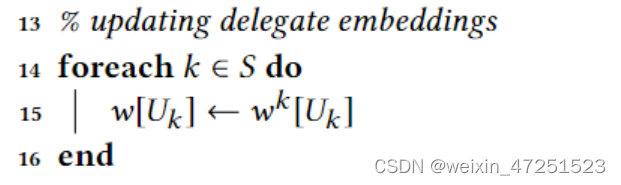
直接在客户端本地用所求出的本轮参数进行更新
- 对于每组中从属用户的用户嵌入更新

涉及到的参数 δ [ U s ] \delta[U_s] δ[Us]- 首先使用聚类函数重新生成簇(因为用户的嵌入每轮都在更新)
- 对于抽取的代表客户端集中的每一个用户k
a. 先找到k所在的用户簇 c k c_k ck
b. 对于 c k c_k ck中没被选到的从属用户s,用 δ [ U s ] \delta[U_s] δ[Us]表示从属用户s的权重,它是根据s所在的簇内所有代表用户的参数变化累加得到(!这里没有绝对值??) - 对于每个簇中没有被抽取的从属用户s
a.使用28行的公式进行更新
b. δ [ U s ] \delta[U_s] δ[Us]表示s所在的用户簇里代表用户的权重变化累加, ∣ c ⋂ S ∣ \vert c \bigcap S \vert ∣c⋂S∣表示在这个簇里被选中的代表客户端数量
c.更新思想是使用代表用户的加权平均值的参数变化量的 γ \gamma γ 倍加上从属用户原始的嵌入向量来更新从属用户的嵌入向量
5、实验
在实验中作者选择GMF模型作为实验模型并与BPR模型做对比。
理论上来说集中训练的GMF模型的效果将是使用FL改造的模型的效果的上限。
数据集
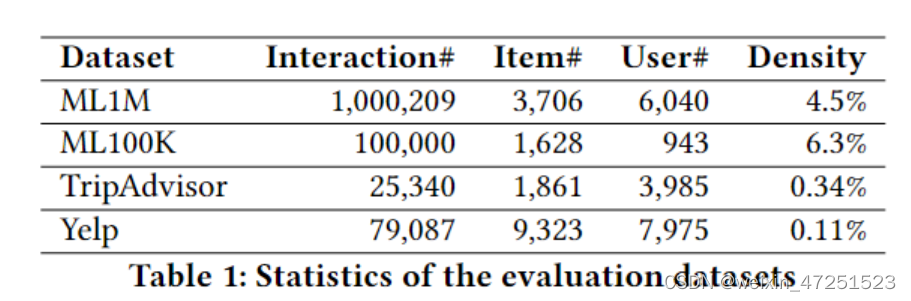
本文使用的数据集是:ML1M、ML00K、Yelp、TripAdvisor
数据集处理规则:
- 过滤掉交互数量少于5的用户
- 将评分转为0到1之间,转为隐式反馈
评估规则: - 使用leave-one-out方法,保留用户的交互项的最后一项为测试数据,并对用户负采样50个未交互的数据
- 使用HR(Hit Radio)和NDCG作为评估指标
问题设置
-
: Q1: FedFast能否在所有轮训练中始终优于FedAvg的推荐质量?
- Q2:在相同的推荐任务上,FedFast是否比FedAvg收敛得更快,以达到相似或更好的推荐精度?
- Q3:FedFast对它的超参数在收敛速度和推荐准确性方面有多敏感?
- Q4:ActvSAMP和ActvAGG对FedFast的贡献有多大?
- Q5:FedFast在不同的数据集上表现一致吗?
准确率(RQ1,RQ5)
本文使用GMF作为FedFast的基础模型,并且使用GMF的FedAVG和集中训练的GMF与BRP作为比较,实验结果如下:
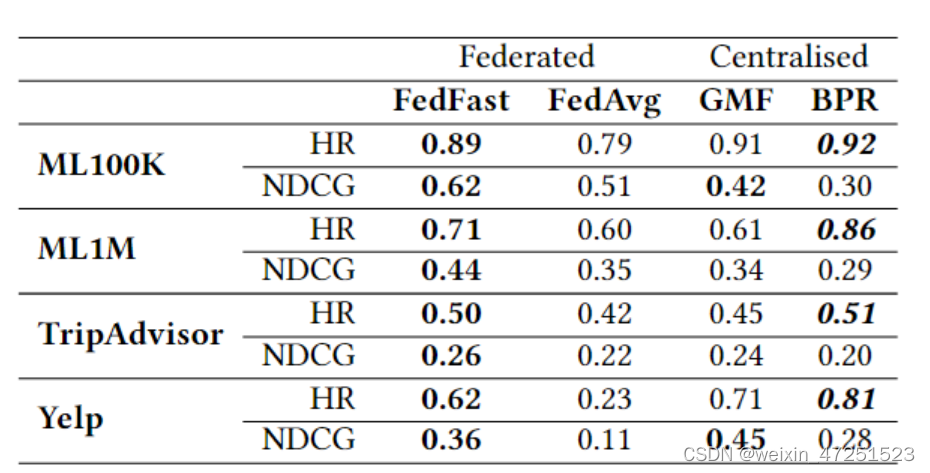
简单说明一下HR代表命中率也就是推荐准确率,NDCG代表归一化折扣累积增益,NDCG是一种常用的基于排名的衡量标准,它通过对数贴现排名来强调排名靠前的重要性。二者的数值越大代表模型效果越好。
有趣的是使用FedFast改造的GMF模型有的实验的效果比集中训练的GMF模型的效果差别不大甚至有的数据集前者的效果更好,同时与BPR模型的差距不大。并且使用FedFast的模型的效果比FedAvg的效果也要好得多。
收敛性分析(RQ2,RQ5)
FedFast的另一项收益就是可以降低模型迭代轮次这样就能减少通信资源的消耗。
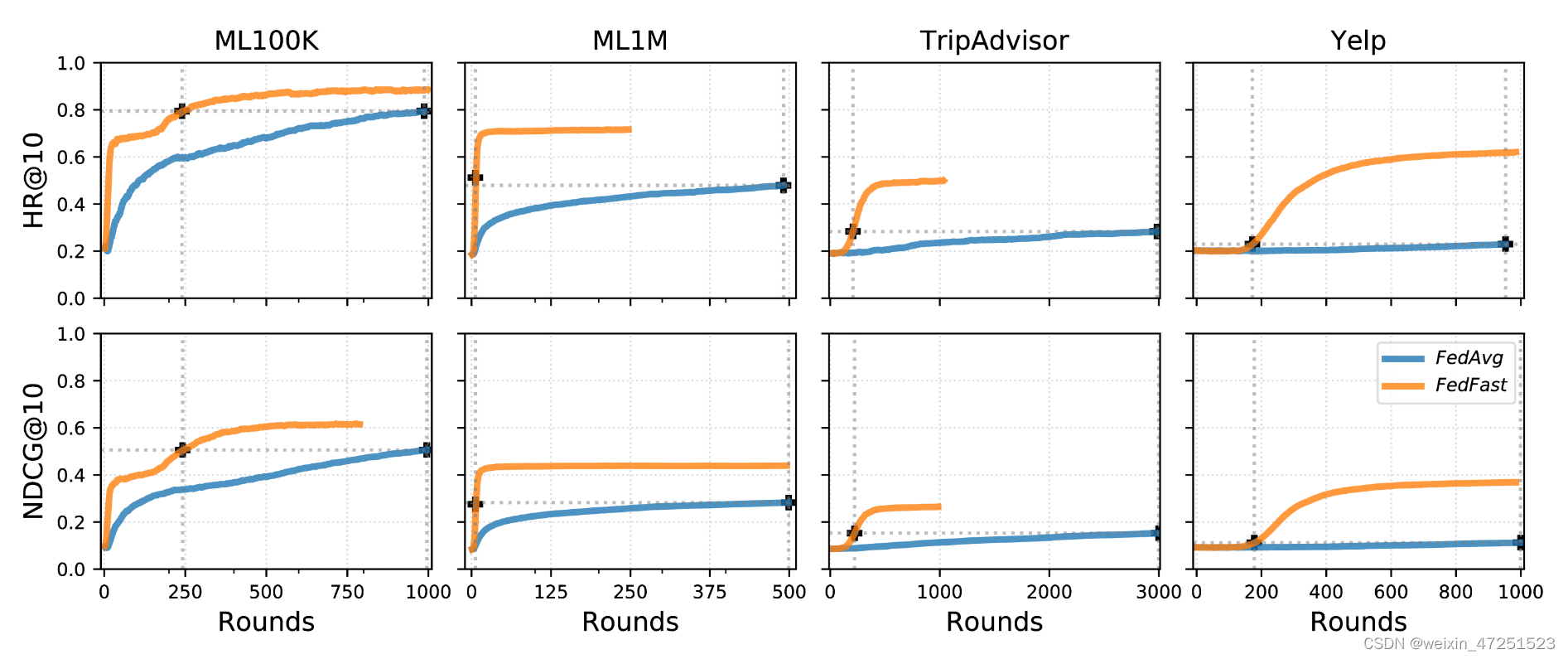
尽管FedAvg和FedFast都从相同的的HR@10开始,但是,FedFast能够以很快的速度收敛。
从上面实验结果我们可以很明显的看到,在相同迭代轮次的情况下FedFast的效果明显高于FedAvg并且在达到相同准确率的情况下FedFast能节省大量的迭代轮次。
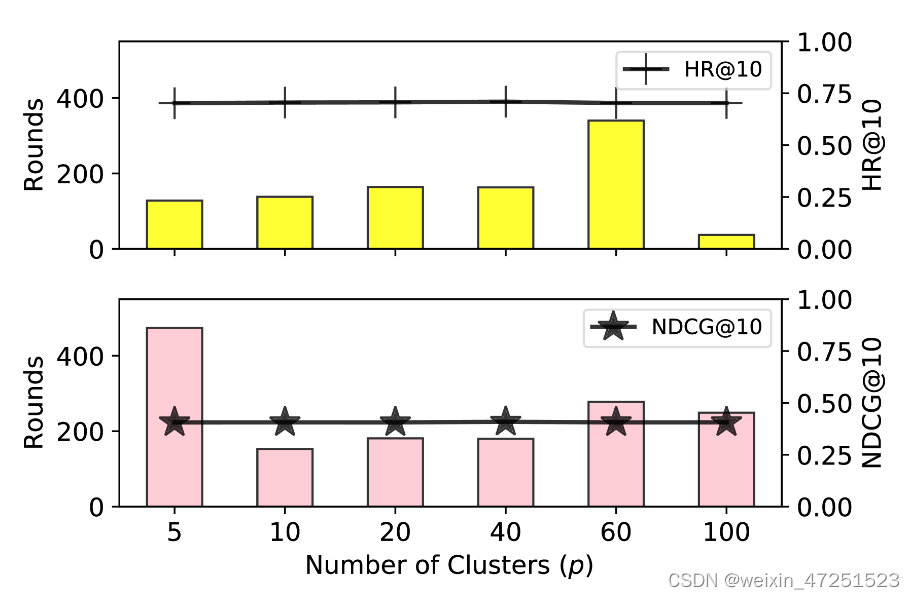
FedFast对集群数量的敏感性(RQ3)
作者为了探索超参数p(簇的个数)对模型的影响,当p取{5,10,20,40,60,100}对实验影响
分析ActvSAMP和ActvAGG对FedFast的影响(RQ4)
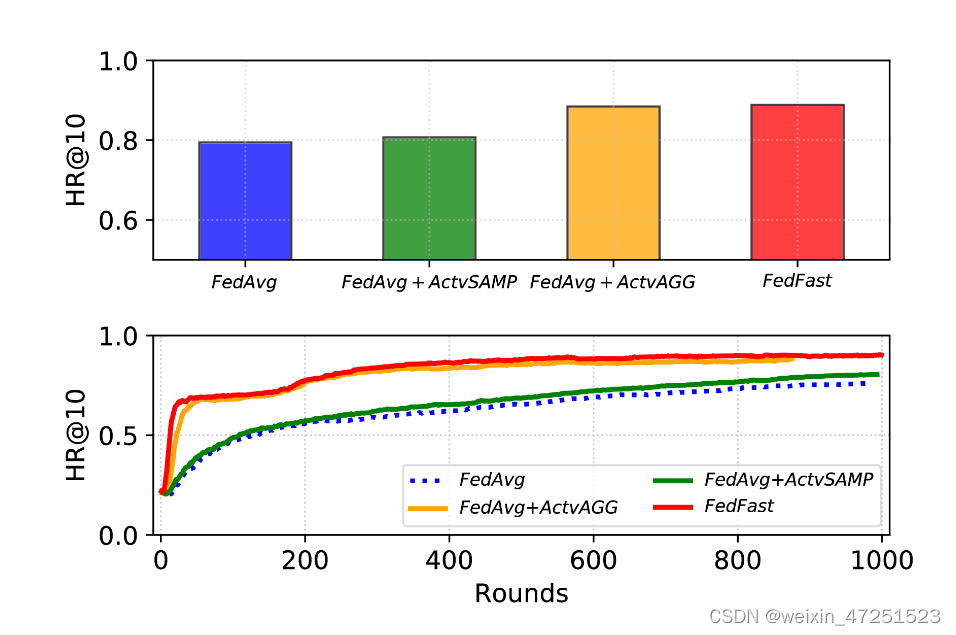
在ML100K数据集中,FedFast的单个组件对FedAvg的贡献是一种改进。FedAvg和FedAvg + ActvSAMP几乎一模一样。ActvAGG似乎对提高推荐质量和加速性能有更大的影响。
FedAvg结合ActvSAMP,对FedAvg几乎没有什么影响。这是因为尽管ActvSAMP小心地选择好的候选对象来训练模型,但是FedAvg的默认聚集策略丢弃了ActvSAMP引入的性能的最潜在增益。
6、一些问题
- 客户端如何分组?分组方法是K-means,初始分组是根据用户的User embedding具体看代码实现
- 客户端之间的通信
- 未找到开源代码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









