







在这一节主要是介绍一下横向联邦学习的一般范式,并介绍一下在FLGo中是如何实现这一流程的。
1 传统横向联邦学习范式
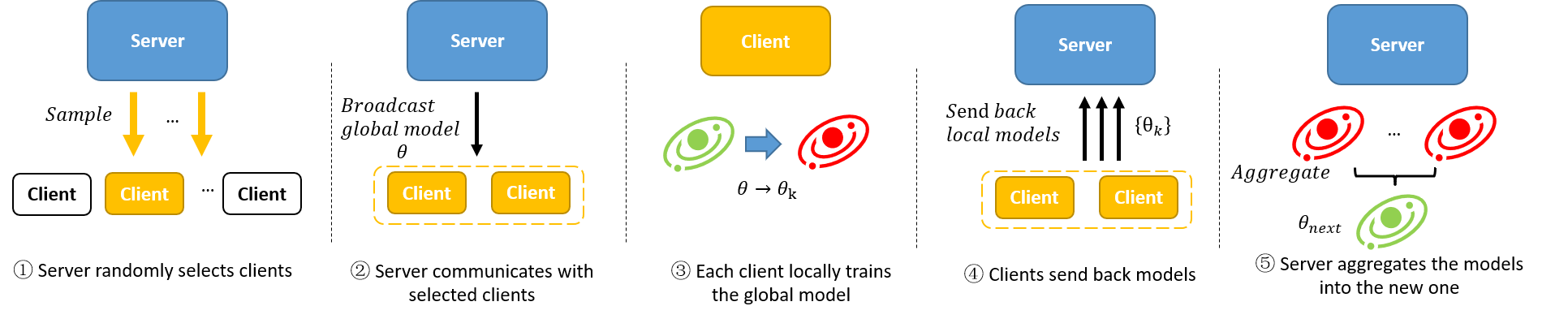 在传统的横向联邦学习场景中,服务器负责协同各个客户端来共同训练一个全局模型。在每次迭代中,1)服务器首先从客户端中采样一个客户端集合;2)客户端将全局模型广播给被选中的客户端代表;3)被选中的客户端在收到服务器传来的全局模型之后,利用自身数据在本地进行训练;4)客户端将自身训练训练的模型发送给服务器;5)在服务器端根据客户端传来的模型进行聚合,更新全局模型。整个算法流程如上图所示,现有的联邦学习方法通常是改进上述的一个或多个流程来达到公平性或鲁棒性等的目的。
在传统的横向联邦学习场景中,服务器负责协同各个客户端来共同训练一个全局模型。在每次迭代中,1)服务器首先从客户端中采样一个客户端集合;2)客户端将全局模型广播给被选中的客户端代表;3)被选中的客户端在收到服务器传来的全局模型之后,利用自身数据在本地进行训练;4)客户端将自身训练训练的模型发送给服务器;5)在服务器端根据客户端传来的模型进行聚合,更新全局模型。整个算法流程如上图所示,现有的联邦学习方法通常是改进上述的一个或多个流程来达到公平性或鲁棒性等的目的。
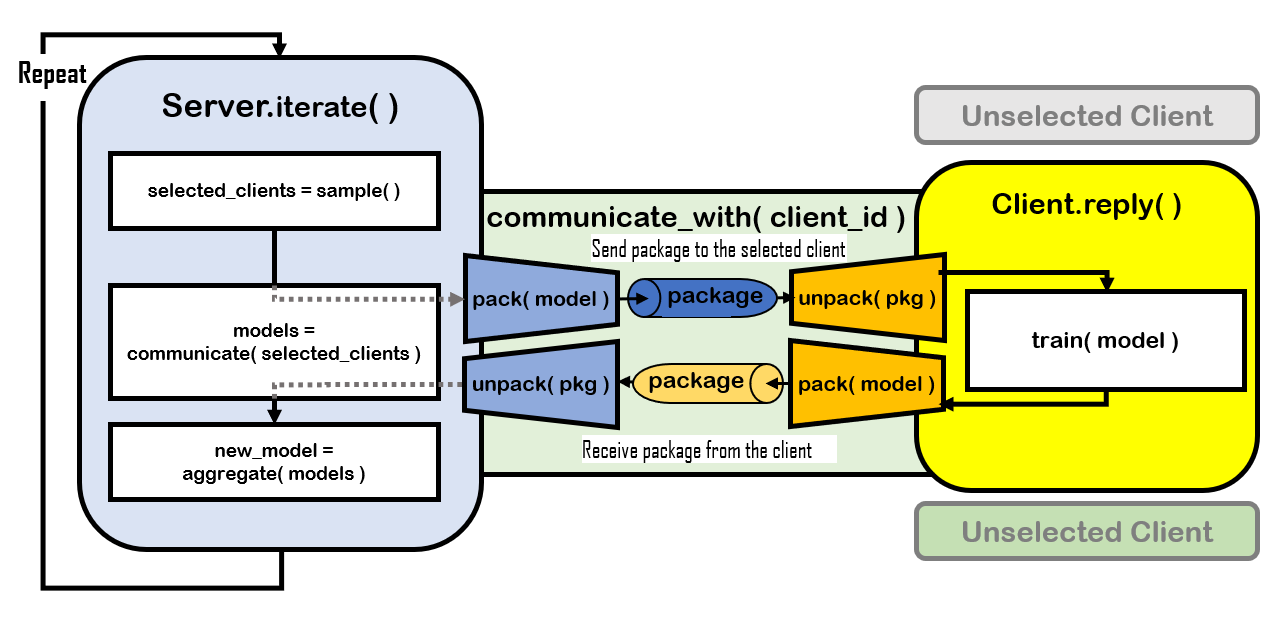
上述过程对应在FLGo中的实现如图2所示。
2 具体实现流程
服务器端: Server.iterate
首先,FLGo的横向联邦中的Server有一个run函数,它使用一个for循环来迭代所有的通信轮数。在每次循环中,Server会首先调用自己的iterate方法。因此iterate方法就涵盖了服务器在一轮通信中的所有动作。iterate不接收输入,它的返回值是在这次迭代中模型是否被更新(Bool)。一个标准的iterate方法的标准实现如下(flgo.algorithm.fedbase.iterate):
def iterate(self):
"""
The standard iteration of each federated communication round that contains three
necessary procedure in FL: client selection, communication and model aggregation.
Returns:
False if the global model is not updated in this iteration
"""
# sample clients: Uniform sampling as default
self.selected_clients = self.sample()
# training
models = self.communicate(self.selected_clients)['model']
# aggregate: pk = ni/sum(ni) as default
self.model = self.aggregate(models)
return len(models) > 0
①服务器采样客户端: Server.sample
在每轮iteration中,服务器首先通过self.sample()函数来对客户端进行采样,该方法的返回值是一个整型列表,表示被采样到的用户索引(ID)。在代码中实现了三种采样方式全采样、MD采样、均匀采样,以及是否考虑当前用户可用性的变种(默认全体用户都是始终可用的,后面在系统异构性里会细讲)。采样函数的默认实现如下:
def sample(self):
r"""
Sample the clients. There are three types of sampling manners:
full sample, uniform sample without replacement, and MDSample
with replacement. Particularly, if 'available' is in self.sample_option,
the server will only sample from currently available clients.
Returns:
a list of the ids of the selected clients
Example:
```python
>>> selected_clients=self.sample()
>>> selected_clients
>>> # The selected_clients is a list of clients' ids
```
"""
all_clients = self.available_clients if 'available' in self.sample_option else [cid for cid in
range(self.num_clients)]
# full sampling with unlimited communication resources of the server
if 'full' in self.sample_option:
return all_clients
# sample clients
elif 'uniform' in self.sample_option:
# original sample proposed by fedavg
selected_clients = list(
np.random.choice(all_clients, min(self.clients_per_round, len(all_clients)), replace=False)) if len(
all_clients) > 0 else []
elif 'md' in self.sample_option:
# the default setting that is introduced by FedProx, where the clients are sampled with the probability in proportion to their local_movielens_recommendation data sizes
local_data_vols = [self.clients[cid].datavol for cid in all_clients]
total_data_vol = sum(local_data_vols)
p = np.array(local_data_vols) / total_data_vol
selected_clients = list(np.random.choice(all_clients, self.clients_per_round, replace=True, p=p)) if len(
all_clients) > 0 else []
return selected_clients
② 服务器广播模型: Server.pack & Client.unpack
通信的过程是通过函数communicate(client_ids: list[int], mtype: str, asynchronous: bool)实现,这个方法负责服务器和客户端之间一个完整的通信来回,也就是它把信息打包好后广播给选中的用户列表,然后返回这些用户所返回的包裹。在这一步中只需要实现服务器将全局模型广播给被选中的客户端,所以只用了Server.pack(client_id) 和 Client.unpack() 两个方法来实现这一过程
class Server:
def pack(self, client_id, mtype=0, *args, **kwargs):
"""
Pack the necessary information for the client's local training.
Any operations of compression or encryption should be done here.
:param
client_id: the id of the client to communicate with
:return
a dict that only contains the global model as default.
"""
return {
"model" : copy.deepcopy(self.model),
}
class Client:
def unpack(self, received_pkg):
"""
Unpack the package received from the server
:param
received_pkg: a dict contains the global model as default
:return:
the unpacked information that can be rewritten
"""
# unpack the received package
return received_pkg['model']
通信的信息应该是以 dict的形式进行传输。服务器将全局模型打包(pack)并传送给客户端,客户端收到后进行拆包(unpack).
客户端: Client.reply
After clients receiving the global models, the method Client.reply will automatically be triggered to model the clients’ behaviors. The implementation of reply is as follows:
在客户端收到服务器传输的全局模型后,客户端会自动的执行 本地的Client.reply 方法,reply函数就定义了横向联邦中用户收到包裹之后的行为。该函数的默认实现如下:
def reply(self, svr_pkg):
r"""
Reply a package to the server. The whole local_movielens_recommendation procedure should be defined here.
The standard form consists of three procedure: unpacking the
server_package to obtain the global model, training the global model,
and finally packing the updated model into client_package.
Args:
svr_pkg (dict): the package received from the server
Returns:
client_pkg (dict): the package to be send to the server
"""
model = self.unpack(svr_pkg)
self.train(model)
cpkg = self.pack(model)
return cpkg
③ 本地训练: Client.train
本地训练通过 Client.train方法来实现,该方法将接收到的全局模型作为输入,利用客户端的本地数据进行训练。在客户端本地的训练方法都是在这定义的,该函数的默认实现如下:
def train(self, model):
r"""
Standard local_movielens_recommendation training procedure. Train the transmitted model with
local_movielens_recommendation training dataset.
Args:
model (FModule): the global model
"""
model.train()
optimizer = self.calculator.get_optimizer(model, lr=self.learning_rate, weight_decay=self.weight_decay,
momentum=self.momentum)
for iter in range(self.num_steps):
# get a batch of data
batch_data = self.get_batch_data()
model.zero_grad()
# calculate the loss of the model on batched dataset through task-specified calculator
loss = self.calculator.compute_loss(model, batch_data)['loss']
loss.backward()
if self.clip_grad>0:torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=self.clip_grad)
optimizer.step()
return
train函数默认接收的第一个参数必须是模型。self.calculator是在构造函数中被初始化的,它的类型为TaskCalculator,来自所使用的benchmark模块。这里的get_optimizer、get_batch_data、compute_loss都是直接由calculator或是基于calculator来实现的。因此很多魔改本地训练目标函数的方法都可以通过修改train函数来实现。(还没看懂这句话)
④ 客户端上传: Client.pack & Server.unpack
这一步主要实现客户端将训练好的本地模型上传到服务器,具体是通过 Client.pack(*args, **kwargs) 和 Server.unpack(packages_list)实现的,这一通信过程和②类似。与过程②不同的是,这次服务器是作为接收方,接收来自不同客户端的包,Server.unpack 将上传的包解压缩为一个dict返回,dict和不同客户端的包共享同一个密钥。( Modification on the content of upload-communication should be implemented in Client.pack that returns a dict as a package each time.??)
class Server:
def unpack(self, packages_received_from_clients):
"""
Unpack the information from the received packages. Return models and losses as default.
:param
packages_received_from_clients:
:return:
res: collections.defaultdict that contains several lists of the clients' reply
"""
if len(packages_received_from_clients)==0: return collections.defaultdict(list)
res = {pname:[] for pname in packages_received_from_clients[0]}
for cpkg in packages_received_from_clients:
for pname, pval in cpkg.items():
res[pname].append(pval)
return res
class Client:
def pack(self, model, *args, **kwargs):
"""
Packing the package to be send to the server. The operations of compression
of encryption of the package should be done here.
:param
model: the locally trained model
:return
package: a dict that contains the necessary information for the server
"""
return {
"model" : model,
}
⑤ 模型聚合: Server.aggregate()
最后一步是服务器通过 Server.aggregate(models: list)方法,将从客户端接收到的模型聚合为一个新的全局模型,在代码中提供了四种聚合方式,
def aggregate(self, models: list, *args, **kwargs):
r"""
Aggregate the locally trained models into the new one. The aggregation
will be according to self.aggregate_option where
pk = nk/n where n=self.data_vol
K = |S_t|
N = |S|
-------------------------------------------------------------------------------------------------------------------------
weighted_scale |uniform (default) |weighted_com (original fedavg) |other
==========================================================================================================================
N/K * Σpk * model_k |1/K * Σmodel_k |(1-Σpk) * w_old + Σpk * model_k |Σ(pk/Σpk) * model_k
Args:
models (list): a list of local_movielens_recommendation models
Returns:
the aggregated model
Example:
```python
>>> models = [m1, m2] # m1, m2 are models with the same architecture
>>> m_new = self.aggregate(models)
```
"""
if len(models) == 0:
return self.model
nan_exists = [m.has_nan() for m in models]
if any(nan_exists):
# If all models have NaN values, raise an error
if all(nan_exists):
raise ValueError("All the received local models have parameters of nan value.")
# If some models have NaN values, remove them from the aggregation list
self.gv.logger.info('Warning("There exists nan-value in local models, which will be automatically removed from the aggregatino list.")')
new_models = []
received_clients = []
for ni, mi, cid in zip(nan_exists, models, self.received_clients):
if ni: continue
new_models.append(mi)
received_clients.append(cid)
self.received_clients = received_clients
models = new_models
# Calculate the local data volumes and total data volume
local_data_vols = [c.datavol for c in self.clients]
total_data_vol = sum(local_data_vols)
# Perform aggregation based on the selected aggregation option
if self.aggregation_option == 'weighted_scale':
# Calculate the weights based on data volumes
p = [1.0 * local_data_vols[cid] / total_data_vol for cid in self.received_clients]
K = len(models)
N = self.num_clients
# Aggregate models with weighted scale method
return fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)]) * N / K
elif self.aggregation_option == 'uniform':
# Aggregate models with uniform method
return fmodule._model_average(models)
elif self.aggregation_option == 'weighted_com':
# Calculate the weights based on data volumes
p = [1.0 * local_data_vols[cid] / total_data_vol for cid in self.received_clients]
w = fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)])
return (1.0 - sum(p)) * self.model + w
else:
# Calculate the weights based on data volumes
p = [1.0 * local_data_vols[cid] / total_data_vol for cid in self.received_clients]
sump = sum(p)
p = [pk / sump for pk in p]
return fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)])
聚合函数虽然很重要,但因为相同的代码段可以放在iterate中去写,大多数时候该函数不需要重写甚至不需要被调用。该函数默认接收模型数组,返回聚合后的模型。值得一提的是FLGo中将所有nn.Module模型进一步封装成了FModule类,使不同的模型可以直接加减乘除,因此可以保证跟伪代码的一致性,使得实现idea更加方便。此外也提供了一些模型的算子,例如加权平均、取范数、拉成tensor等。















 7464
7464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









