









 文章介绍了PyTorch的torchvision库中的transforms模块,包括数据预处理、标准化、数据裁剪(如CenterCrop、RandomCrop、RandomResizedCrop)、翻转和旋转、ColorJitter等数据增强技术,以及如何自定义transforms。通过实例演示了如何在实际项目中运用这些技术来提升模型的鲁棒性。
文章介绍了PyTorch的torchvision库中的transforms模块,包括数据预处理、标准化、数据裁剪(如CenterCrop、RandomCrop、RandomResizedCrop)、翻转和旋转、ColorJitter等数据增强技术,以及如何自定义transforms。通过实例演示了如何在实际项目中运用这些技术来提升模型的鲁棒性。
目录
一、torchvision:计算机视觉工具包
torchvision下的transforms方法是常用的图像预处理方法, 安装Pytorch的时候便安装了这个torchvision。 torchvision的主要的模块如下:
torchvision.transforms: 常用的图像预处理方法, 比如标准化,中心化,旋转,翻转等操作torchvision.datasets: 常用的数据集的dataset实现, MNIST, CIFAR-10, ImageNet等torchvision.models: 常用的模型预训练, AlexNet, VGG, ResNet, GoogLeNet等。
二、transforms的原理
2.1 利用transforms进行预处理的原理
总的来说呢大致的逻辑关系可以如下图表示:

从图上可以发现,利用transforms进行预处理是在__ getitem __实现的。
2.2 数据标准化
下面以数据预处理机制中的数据标准化方法:transforms.Normalize
功能:逐channel的对图像进行标准化。output = (input - mean)/ std

-
mean:各通道的均值
-
std:各通道的标准差
-
inplace:是否原地操作
为例来看看transforms方法掉调用过程。
这个参数就不用解释了吧。 好吧, 再进行调试一下,看看是怎么变的吧:
(这里我用的是Pycharm编译器)首先在__ getitem 中如下代码处打断点,

然后执行step into(F7)进入transforms.py以查看执行情况, 这里的 call 就是调用我们自定义的transforms方法。
在 call __函数中执行step over(F8)到下图所示处的**t:Normalize(…)**处时候,再次执行step into(F7)后便进入了module.py
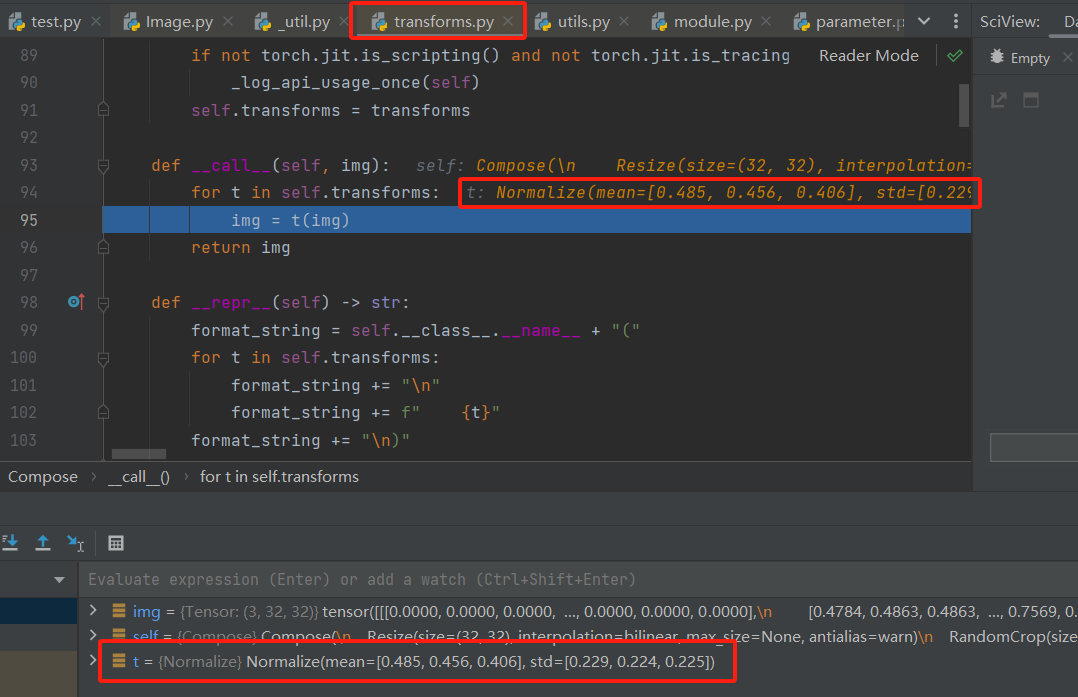
在module.py反复执行step over(F8)到如下位置处时,再执行step into(F7)进入这个函数。
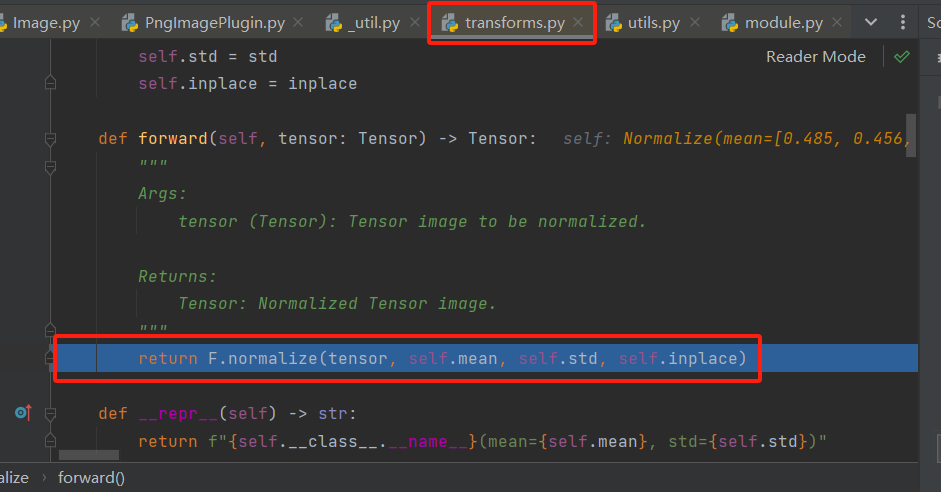
在functional.py中执行step over(F8)到如下位置处时,再执行step into(F7)便能够进入到pytorch中的normalize方法啦。
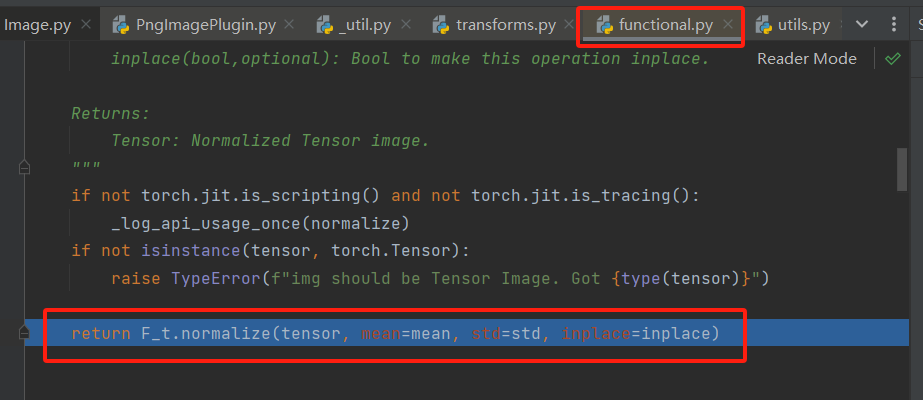
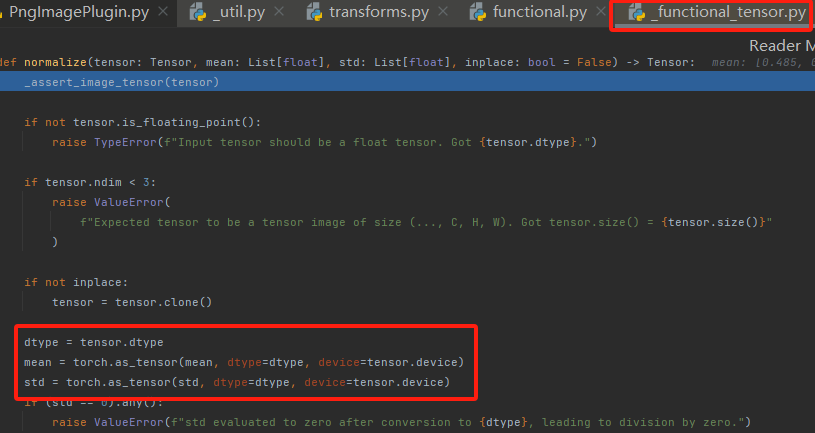
以上只是一个简要的debug过程,也是楼主我一个小小复习过程~如果想了解normalize的具体实现过程的话可以查阅torchvision-normalize文档哦!
三、数据增广
大型数据集是成功应用深度神经网络的先决条件。 图像增广(这里我们是以图片为例)在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 此外,应用图像增广的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
3.1 transforms—数据裁剪
(1)transforms.CentorCrop
功能: 图像中心裁剪图片
- size:所需裁剪图片尺寸,如果比原始图像大了, 会默认填充0。
(2)transforms.RandomCrop
功能:从图片中随机裁剪出尺寸为size的图片

- size:所需裁剪图片尺寸
- padding:设置填充大小
(当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d) - pad_if_need:若图像小于设定size,则填充。
- padding_mode:填充模式,有4种模式。
(constant:像素值由fill设定。
edge:像素值由图像边缘像素决定。
reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]) - fill:constant时,设置填充的像素值
(3)RandomResizedCrop
功能:随机大小、长宽比裁剪图片

- size:所需裁剪图片尺寸
- scale:随机裁剪面积比例,默认(0.08,1) (在0.08-1之间选择一个比例进行裁剪)
- ratio:随机长宽比,默认(3/4,4/3)
- interpolation:插值方法 (对于尺寸小于size的进行插值填充)参数(代表选用的插值方法)如下:
PIL.Image.NEAREST
PIL.Image.BILINEAR
PIL.Image.BICUBIC
(4)FiveCrop &(5)TenCrop
功能:在图像的上下左右及中心裁剪出尺寸为size的5张图片,TenCrop还在这5张图片的基础上再水平或者垂直镜像得到10张图片

-
size:所需裁剪图片尺寸
-
vertical_flip:是否垂直翻转
3.2 transforms——翻转和旋转
(1)RandomHorizontalFlip & (2)RandomVerticalFlip
功能:依概率水平(左右)或垂直(上下)翻转图片
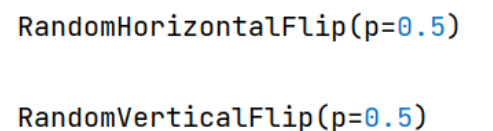
- p:翻转概率
(3)RandomRotation()
功能:随机旋转图片

- degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a, b)时,在(a, b)之间选择旋转角度 - resample:重采样方法
- expand:是否扩大图片,以保持原图信息
- center:旋转点设置,默认中心旋转
(1)pad
功能:对图片边缘进行填充
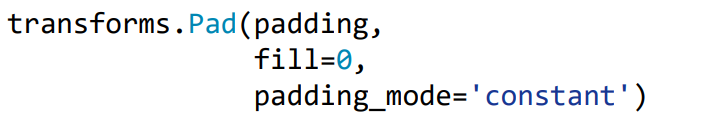
- padding:设置填充大小,参数如下:
当为a时,上下左右均填充a个像素
当为(a,b)时,上下填充b个像素,左右填充a个像素
当为(a,b,c,d)时,左,上,右,下分别填充a,b,c,d - padding_mode:填充模式,有四种模式,constant、edge、reflect和symmetric(具体可以向上查阅)padding_mode的优先级高于fill
- fill:constant时, 设置填充的像素值,(R,G,B)or(Gray)
- padding_mode:优先级高于fill
(2)ColorJitter
功能:调整亮度、对比度、饱和度和色相, 这个是常用方法。
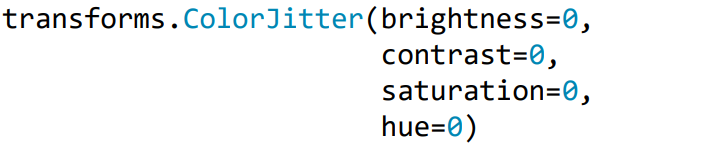
- brightness:亮度调整因子,参数如下:
当为a时,从[max(0,1-a),1+a]中随机选择
当为(a,b)时,从[a,b]中选择 - contrast:对比度参数,同brightness
- saturation:饱和度参数,同brightness
- hue:色相参数,参数如下:
当为a时,从[-a,a]中选择参数,注:0<=a<=0.5
当为(a,b)时,从[a,b]中选择参数,注:-0.5<=a<=b<=0.5
(3)Greyscale
功能:将图片转换为灰度图

- num_output_channels: 输出的通道数。只能设置为 1 或者 3 (如果在后面使用了transforms.Normalize,则要设置为 3,因为transforms.Normalize只能接收 3 通道的输入)
(4)RandomGreyscale
功能:依概率将图片转换为灰度图

- num_output_channels:输出通道数,只能设1或3
- p:概率值,图像被转换为灰度图的概率,当p=1,则等价于Greyscale
(5)RandomAffine
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转,平移,缩放,错切和翻转

- degrees:旋转角度设置
- translate:平移区间设置,如(a,b),a设置宽(width),b设置高(height),图像在宽维度平移的区间为 -img_width * a < dx < img_width * a
- scale:缩放比例(以面积为单位)
- fill_color:填充颜色设置
- shear:错切角度设置,有水平错切和垂直错切,参数如下:
若为a,则仅在x轴错切,错切角度在(-a,a)之间
若为(a,b),则设置x轴角度,b设置y的角度
若为(a,b,c,d),则a,b设置x轴角度,c,d设置y轴角度 - resample:重采样方式,参数有NEAREST、BILINEAR、BICUBIC
(6)RandomErasing
功能:对图像进行随机遮挡(即使图片被遮挡了部分,人也能识别图片大致是什么,为了提高机器的识别能力可以适当输入部分被遮挡的图片作为训练集)

- p:概率值,执行该操作的概率,参数如下:
- scale:遮挡区域的面积
- ratio:遮挡区域长宽比
- value:设置遮挡区域的像素值,(R,G,B)or(Grey)

注意事项:执行Erasing是对tensor进行操作的,故需要把输入转为张量的类型 ,transforms.ToTensor()
推荐阅读文献:Random Erasing Data Augmentation
(7)transforms.lambda
功能:用户自定义lambda方法
- lambd:lambda匿名函数,参数如下:
lambda [arg1[,arg2,…,argn]] : expression
由于TenCrop输出的结果是元组tuple类型,故需要对输出结果转换为张量tensor,就可以用到lambda函数
stack将返回的张量进行拼接,输出为4D的张量,stack会创建一个维度将张量进行拼接
测试代码
transforms.TenCrop(200, vertical_flip=True),
transforms.Lambda(lambda crops: torch.stack([transforms.Totensor()(crop) for crop in crops])),
上述代码的流程可以如下叙述:在列表解释式[transforms.Totensor()(crop) for crop in crops]中,有一个循环for crop in crops,该循环对每一个元素crop执行操作transforms.Totensor()(crop)(crops是一个元组tuple,每个元素的数据类型是PIL.image)然后将每个crop转化成了张量tensor,最后将这些转化后的tensor拼接到了一起成为一个list后返回。transforms.Lambda的输出为4D的张量。
transforms——transforms方法选择操作
(1)transforms.RandomChoice
功能:从一系列transforms方法中随机挑选一个

(2)transforms.RandomApply
功能:依据概率执行一组transforms操作
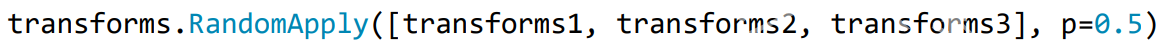
(3)transforms.RandomOrder
功能:对一组transforms操作打乱顺序

至此,关于Pytorch的transforms操作基本了解了大概, 具体细节还是需要看官方文档。 虽然Pytorch提供了很多的transforms方法, 但是在实际工作中,可能需要自己的项目去自定义一些transforms方法,那么如何才能定义自己的方法呢?
4.5 自定义transforms方法
上面的Debug中我们就看到了在Compose这个类里面调用了一系列的transforms方法:
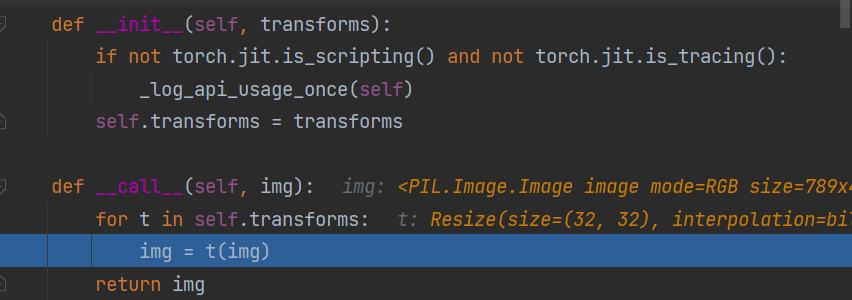
我们调用了Compose里面的__ call __里的transforms方法执行一个for循环,每次挑取一个方法进行执行。 也就是说transforms方法仅接收一个参数,返回一个参数,然后就是for循环中,上一个transforms的输出正好是下一个transforms的输入,所以数据类型要注意匹配。
我们可以发现,上述方法是对每一张图片串联地执行一些列图像处理的操作,但最后只得到了一张图片,看似并没有得到过多的信息。但是我们可以发散地想想,如果我们将串联改为并联处理,不就可以同时得到更多的图片以增强鲁棒性(robust)了吗。
于是乎,我们可以将原来的图片拷贝几张,然后分别对每个图片执行不同的图片处理操作,便得到了不同的增强过后的图片啦。此外我们还可以将数据增强过程和构建Dataloader的过程分开:即先通过transform技术做一些数据增强的图片,比经过裁剪,旋转, 变换等得到多张图片,然后将这些图片直接保存到数据目录中去。 然后再读取吗,相当于把经过处理的图像直接当独立的训练集数据存入到了Dataset中去(可以理解为不告诉机器这几个处理后的图片有相同的label,让机器自己去学)。
举个栗子吧,正如人民币二分类demo中100张一块的图片,仅根据上述代码执行的话,最终得到的还是100张一块的图片,图片数量并没有增多。 由于100张1块的人民币几乎是相同的,但每张人民币经过数据增强,就得到了100张不同形态的人民币,通过这个方式增加形态和鲁棒性,便正如上边提到的。
但如果更换别的数据集,并且将二分类任务改成多分类任务,例如用鲜花数据集做一个分类任务,这时候如果数据集里有100张形态不一样的花, 此时如果同时用上述两个方法做数据增强,并不会显著改善模型效果,此时应该单独采用其中一种方案。
下面给出一个自定义transforms的结构:

图像增强的方法有很多,但主要的目的还是为了增强鲁棒性,为此需要遵循的的是:数据增强策略原则: 让训练集与测试集更接近:
- 空间位置上: 可以选择平移
- 色彩上: 灰度图,色彩抖动
- 形状: 仿射变换
- 上下文场景: 遮挡,填充
四、总结
以上几节便是简要地学习了一下Pytorch的数据模块和实现了一个小demo:本节了解了基本的transforms图像增强方法,并通过一个人民币二分类的demo复习了一下debug的流程,在debug中简要了解了transforms的流程。
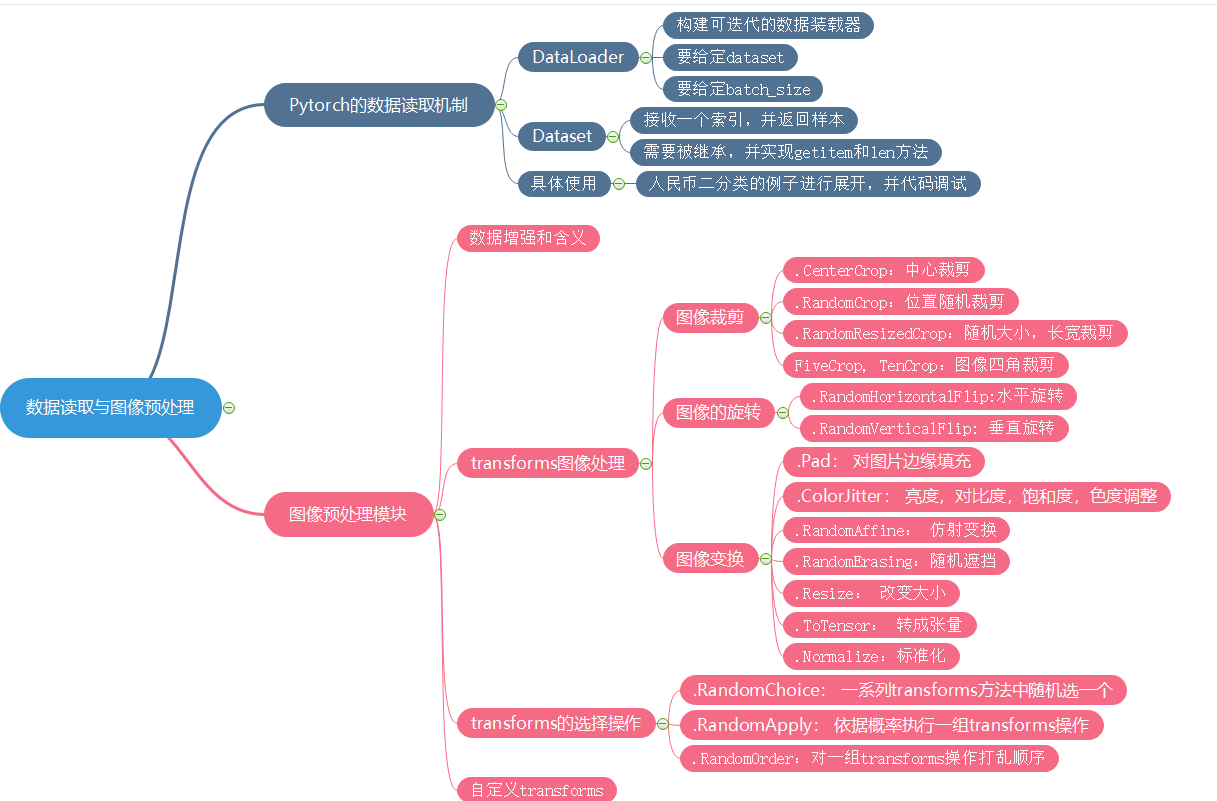
下面的思维导图可以较好地复述这几节的内容,方便以后查看学习(这个图画得真好呀,要好好地给原作者点赞喵~o( =∩ω∩= )m):


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









