







-
机器学习系统的设计
解决这样一个问题,我们首先要做的决定是如何选择并表达特征向量X。我们可以选择一个由100个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为1,不出现为0),尺寸为100×1。
为了构建这个分类器算法,我们可以做很多事,例如:
收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本
基于邮件的路由信息开发一系列复杂的特征
基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
为探测刻意的拼写错误(把watch 写成w4tch)开发复杂的算法
非常难决定应该在哪一项上花费时间和精力,作出明智的选择,比随着感觉走要更好
每当我研究机器学习的问题时,我最多只会花一天的时间,就是字面意义上的24小时,来试图很快的把结果搞出来,即便效果不好。坦白的说,就是根本没有用复杂的系统,但是只是很快的得到的结果。即便运行得不完美,但是也把它运行一遍,最后通过交叉验证来检验数据。一旦做完,你可以画出学习曲线,通过画出学习曲线,以及检验误差,来找出你的算法是否有高偏差和高方差的问题,或者别的问题。在这样分析之后,再来决定用更多的数据训练,或者加入更多的特征变量是否有用。
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势
-
类偏斜的误差度量
类偏斜情况表现为我们的训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。
例如我们希望用算法来预测癌症是否是恶性的,在我们的训练集中,只有0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有0.5%。然而我们通过训练而得到的神经网络算法却有1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。
查准率(Precision)和查全率(Recall) 我们将算法预测的结果分成四种情况:
1. 正确肯定(True Positive,TP):预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为假
3. 错误肯定(False Positive,FP):预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为真
则:查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。

查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比0.5更大的阀值,如0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:
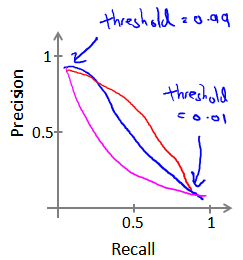
我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算F1 值(F1 Score),其计算公式为: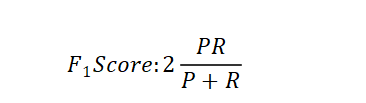 可以调节权重
可以调节权重
选择使得F1值最高的阀值。















 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









