







Transaction Control Language 事务控制语言
事务的ACID属性
1、原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2、 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3、隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
4.持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
事务的创建:
- 隐式: 事务没有明显的开启和结束语句标记
这里可以看到msyql默认是开启自动提交事务的

比如insert update delete语句 都是单独的一个事务
- 显式:事务具有明显的开启和结束语句标记
前提是必须先禁用自动提交的功能
SET autocommit=0; #关闭自动提交事务
START TRANSACTION; #开启事务 可选的,可以不写,不写也会开
SQL 1;
SQL 2;
....
# 结束事务
COMMIT; #提交事务 成功则提交
ROLLBACK; #回滚事务 失败则回滚
事务隔离机制
对于同时运行的多个事务,当这些事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种并发问题:
- 脏读
对于两个事务,A事务读取到了已经被B事务更新但还没有被提交的数据之后,若B事务回滚,A事务读取到的数据就是临时且无效的
- 不可重复读
对于两个事务,A事务读取了一个字段,然后B更新了这个字段,之后 A在次读取同一个字段,值就不同了。简单来说就是,同一个事务中,多次查询的结果不一样。
- 幻读
对于两个事务,A事务从表中读取了一个字段,然后B事务在表中插入了一下新的行之后,A事务再次读取,就会多出几行
数据库事务的隔离性:数据库系统必须具有隔离并发运行各个事务的能力,使它们不好相互影响,避免各种并发问题
事务隔离级别
读未提交(read uncommitted):
允许事务读取未被其他事务提交的数据,脏读
读已提交(read committed)
只允许事务读取已经被其他事务提交的数据,可以避免脏读。
可重复读(repeatable read)
确保事务多次从同一个字段读取到的数据是一样的。在这个事务持续期间,禁止其他事务对这个字段进行更新。可以避免脏读和不可重复读
串行化(serializable)
确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务读对该表执行插入,更新,删除操作,所以并发问题都可以避免,但性能十分低下
Mysql支持4种事务隔离级别, 默认的事务隔离级别为:repeatable read ,可重复读
Oracle 支持两种事务隔离级别,读已提交数据(read committed) 和 串行化(serializable) 默认为 读已提交数据(read committed)
mysql 查看当前隔离级别:
select @@tx_isolation;

可以看到 当前默认的隔离级别为 可重复读,这里面为了演示,所以把隔离级别更改为 读未提交
set session transaction isolation level read uncommitted;

源数据:
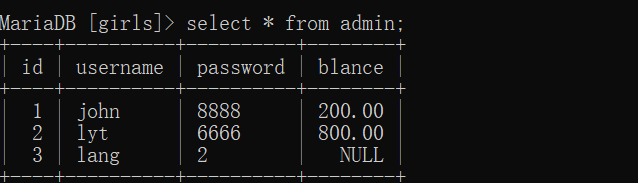
-
读未提交产生脏读 演示:
这里使用A事务对数据进行修改,但是没有提交。

这时,B事务就会访问到 A数据修改但是未提交的脏数据: 万一A事务回滚了,数据又不一样了


-
读已提交隔离级别下可以避免脏读:
把AB事务的隔离级别设置为读已提交


读已提交这个隔离级别,虽然避免了脏读,但是不可重复读 以及幻读的现象还是有的

- 可重复读 :
修改隔离级别为 repeatable read:
A事务:

B事务

savepoint保存点
SET autocommit=0;
START TRANSACTION;
DELETE FROM admin WHERE id = 1;
SAVEPOINT a; #设置保存点
DELETE FROM admin WHERE id = 3;
ROLLBACK a ; #回滚到a点
也就说。id为1的会被删除,id为3的会回滚。
视图
含义:一种虚拟存在的表。和普通表一样使用。
musql 5.1出现的新特性。是通过表动态生成的数据 只保存了sql逻辑,不保存查询结果。
应用场景:
- 多个地方用到同样的查询结果
- 该查询结果使用的sql语句较复杂
比如说现在有一条比较长的sql。而且又经常使用,比如下面这条,我们就可以给它创建视图
- 创建视图
SELECT
e.`last_name`,
d.`department_name`
FROM
`employees` e
JOIN `departments` d
ON e.`department_id` = d.`department_id`
WHERE last_name LIKE '%Gee%' ;
# 创建视图 语法:
create view 视图名
as
查询语句;
#使用:
select * from 视图名字;
# 创建视图
CREATE VIEW v1 AS
SELECT
e.`last_name`,
d.`department_name`
FROM
`employees` e
JOIN `departments` d
ON e.`department_id` = d.`department_id` ;
# 当我们需要使用时
SELECT * FROM v1 WHERE last_name LIKE '%Gee%' ;
- 视图的修改:
# 方式一:
create or replace view 视图名
as
查询语句
# 方式二:
alter view 视图名
as
查询语句
- 视图的删除
drop view 视图1,视图2;
- 视图的查看
desc 视图名称;
show create view 视图名称
- 实例
# 创建视图emp_v1, 要求查询电话号码以’011‘ 开头的员工姓名和工资以及邮箱;
CREATE OR REPLACE VIEW emp_v1 AS
SELECT last_name,salary,email
FROM employees
WHERE phone_number LIKE '011%';
SELECT * FROM emp_v1;
# 创建视图emp_v2,要求查询部门的最高工资高于1200的部门信息
CREATE OR REPLACE VIEW emp_v2 AS
SELECT MAX(salary) mx_dep, e.department_id
FROM `employees` e
GROUP BY e.department_id
HAVING MAX(salary) > 12000
SELECT d.* ,m.mx_dep FROM `departments` d
JOIN emp_v2 m
ON m.department_id = d.department_id
视图同时支持增删改,并且会影响到原始表,所以我们一般会对视图进行权限设置
















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









