







记录一下科研训练 用的是EAST(检测)+CRNN(识别)
2022.10.27
参考了很多文章、文献、博客。。。
如有侵权,速速联系我==
有两个坑未填
East算法原理
典型的文本检测模型一般是会分多个阶段(multi-stage)进行,在训练时需要把文本检测切割成多个阶段(stage)来进行学习,这种把完整文本行先分割检测再合并的方式,既影响了文本检测的精度又非常耗时,对于文本检测任务上中间过程处理得越多可能效果会越差。
EAST(An Efficient and Accurate Scene Text Detector)是一种高效的文本检测方法,一般的深度学习检测方法通常都需要很多中间步骤,这样的话在训练期间就要对多个阶段进行调优,势必会非常消耗时间并且会影响最后的检测结果,而East框架则消除了许多的中间步骤直接对文本行进行预测,实现端到端文本检测,优雅简洁,检测的准确性和速度都有了进一步的提升。
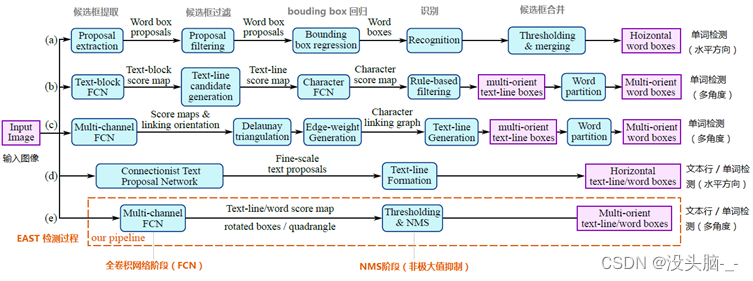
其中,abcd是几种常见的文本检测过程,典型的检测过程包括候选框提取、候选框过滤、bouding box回归、候选框合并等阶段,中间过程比较冗长。而e即是本文介绍的EAST模型检测过程,从上图可看出,其过程简化为只有FCN阶段(全卷积网络)、NMS阶段(非极大抑制),中间过程大大缩减,而且输出结果支持文本行、单词的多个角度检测,既高效准确,又能适应多种自然应用场景。
在ICDAR2015等公开数据集上的实验均证明EAST算法在精度和效率方面在当时取得了相当不错的成绩。因为EAST算法具有结构简洁、性能较好、输出的文本框也比较适合路牌场景中文本区域的检测等优点,所以选择EAST算法作为本文文本检测算法的基准。
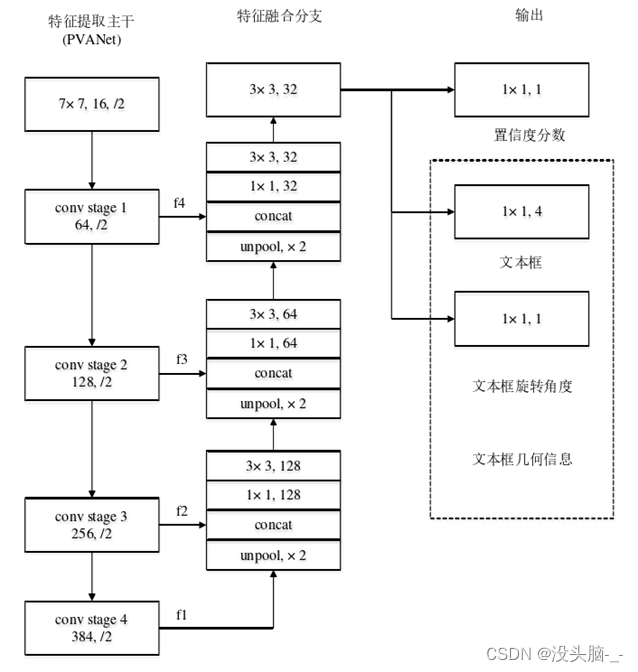
EAST模型的网络结构分为特征提取层、特征融合层、输出层三大部分。
1、特征提取层
基于PVANet(一种目标检测的模型)作为网络结构的骨干,分别从stage1,stage2,stage3,stage4的卷积层抽取出特征图,卷积层的尺寸依次减半,但卷积核的数量依次增倍,这是一种“金字塔特征网络”(FPN,feature pyramid network)的思想。通过这种方式,可抽取出不同尺度的特征图,以实现对不同尺度文本行的检测。
2、特征融合层
将前面抽取的特征图按一定的规则进行合并,这里的合并规则采用了U-net方法:
- 特征提取层中抽取的最后一层的特征图(f1)被最先送入unpooling层,将图像放大1倍
- 接着与前一层的特征图(f2)串起来(concatenate),然后依次作卷积核大小为1x1,3x3的卷积
- 对f3,f4重复以上过程,而卷积核的个数逐层递减,依次为128,64,32
- 最后经过32核,3x3卷积后将结果输出到“输出层”
3、输出层
最终输出以下5部分的信息,分别是:
score map:检测框的置信度,1个参数;
text boxes:检测框的位置(x, y, w, h),4个参数;
text rotation angle:检测框的旋转角度,1个参数;
text quadrangle coordinates:任意四边形检测框的位置坐标,(x1, y1), (x2, y2), (x3, y3), (x4, y4),8个参数。
East损失函数
总的损失函数如下所示:
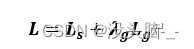
其中,表示分割图像背景和图像文本的分类损失,文本区域所在的部分表示1,非文本区域的背景部分表示0,即像素点的分类损失。L_g表示对应文本区域的像素点所组成的矩形框和矩形框角度的回归损失。λ_g表示两个损失之间的相关性,为了显示两个损失同等重要,将λ_g设置为1。
为了简化训练过程,分类损失使用平衡的交叉熵,公式如下: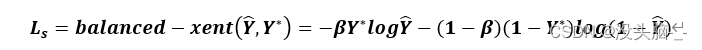
其中表示置信度的预测值,Y ̂表示置信度的真实值,Y^*参数是调制系数,参数β是调制系数,主要用来控制正负样本之间的比例。计算公式为:
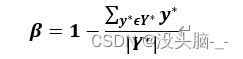
令L_AABB表示回归损失,旋转角度损失用L_θ表示:
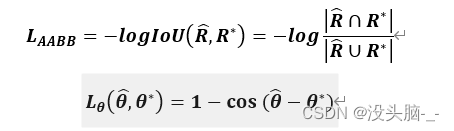
其中,预测出来的文本倾斜角度用(θ,) ̂表示,而文本矩形框真实的倾斜角度则用θ^*表示。让AABB表示从像素位置到文本矩形的上下左右4个边界的距离,令L_g为回归损失和旋转角度损失加权和,合称为几何损失,计算公式如下:
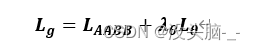
East算法代码
icdar.py数据预处理
#训练标签的生成
def generator(input_size=512, batch_size=32,
background_ratio=3./8,
random_scale=np.array([0.5, 1, 2.0, 3.0]),
vis=False):
# 获得训练集路径下所有图片名字
image_list = np.array(get_images())
print('{} training images in {}'.format(
image_list.shape[0], FLAGS.training_data_path))
# index :总样本数
index = np.arange(0, image_list.shape[0])
while True:
np.random.shuffle(index)
images = []
image_fns = []
score_maps = []
geo_maps = []
training_masks = []
for i in index:
try:
# 读取图片
im_fn = image_list[i]
im = cv2.imread(im_fn)
# print im_fn
h, w, _ = im.shape
# 读取标签txt
txt_fn = im_fn.replace(os.path.basename(im_fn).split('.')[1], 'txt')
if not os.path.exists(txt_fn):
print('text file {} does not exists'.format(txt_fn))
continue
# 读出对应label文档中的内容
# text_polys:样本中文字坐标
# text_tags:文字框内容是否可辨识
text_polys, text_tags = load_annoataion(txt_fn)
# 保存其中的有效标签框,并修正文本框坐标溢出边界现象
text_polys, text_tags = check_and_validate_polys(text_polys, text_tags, (h, w))
# 随机resize一下图片,并将text_polys中的坐标做等比例改变
rd_scale = np.random.choice(random_scale)
im = cv2.resize(im, dsize=None, fx=rd_scale, fy=rd_scale)
text_polys *= rd_scale
# random crop a area from image
# crop_area函数:圈出图中的某一块文字或者空区域,并生成其polys,即文本框标签数据
# 随机做一些无字符样本,也就是背景样本
if np.random.rand() < background_ratio:
# crop background
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=True)
# 图片里没找到纯背景就切换下一幅图
if text_polys.shape[0] > 0:
# cannot find background
continue
# pad and resize image
# 对得到的背景图片进行扩充至size=input_size
# score标签全为0,因为是背景
# 同理,geo标签全为0
new_h, new_w, _ = im.shape
max_h_w_i = np.max([new_h, new_w, input_size])
im_padded = np.zeros((max_h_w_i, max_h_w_i, 3), dtype=np.uint8)
im_padded[:new_h, :new_w, :] = im.copy()
im = cv2.resize(im_padded, dsize=(input_size, input_size))
score_map = np.zeros((input_size, input_size), dtype=np.uint8)
geo_map_channels = 5 if FLAGS.geometry == 'RBOX' else 8
geo_map = np.zeros((input_size, input_size, geo_map_channels), dtype=np.float32)
training_mask = np.ones((input_size, input_size), dtype=np.uint8)
# 另一部分作为正常样本
else:
im, text_polys, text_tags = crop_area(im, text_polys, text_tags, crop_background=False)
# 如果图片中本身就没有文字则跳过该样本
if text_polys.shape[0] == 0:
continue
h, w, _ = im.shape
# 填充,resize图像至设定尺寸
new_h, new_w, _ = im.shape
max_h_w_i = np.max([new_h, new_w, input_size])
im_padded = np.zeros((max_h_w_i, max_h_w_i, 3), dtype=np.uint8)
im_padded[:new_h, :new_w, :] = im.copy()
im = im_padded
# resize the image to input size
new_h, new_w, _ = im.shape
resize_h = input_size
resize_w = input_size
im = cv2.resize(im, dsize=(resize_w, resize_h))
# 将文本框坐标标签等比例修改
resize_ratio_3_x = resize_w/float(new_w)
resize_ratio_3_y = resize_h/float(new_h)
text_polys[:, :, 0] *= resize_ratio_3_x
text_polys[:, :, 1] *= resize_ratio_3_y
new_h, new_w, _ = im.shape
# 结合文本框真值标签生成score图和geo图
score_map, geo_map, training_mask = generate_rbox((new_h, new_w), text_polys, text_tags)
# 是否显示样本切割填充结果
if vis:
fig, axs = plt.subplots(3, 2, figsize=(20, 30))
axs[0, 0].imshow(im[:, :, ::-1])
axs[0, 0].set_xticks([])
axs[0, 0].set_yticks([])
for poly in text_polys:
poly_h = min(abs(poly[3, 1] - poly[0, 1]), abs(poly[2, 1] - poly[1, 1]))
poly_w = min(abs(poly[1, 0] - poly[0, 0]), abs(poly[2, 0] - poly[3, 0]))
axs[0, 0].add_artist(Patches.Polygon(
poly, facecolor='none', edgecolor='green', linewidth=2, linestyle='-', fill=True))
axs[0, 0].text(poly[0, 0], poly[0, 1], '{:.0f}-{:.0f}'.format(poly_h, poly_w), color='purple')
axs[0, 1].imshow(score_map[::, ::])
axs[0, 1].set_xticks([])
axs[0, 1].set_yticks([])
axs[1, 0].imshow(geo_map[::, ::, 0])
axs[1, 0].set_xticks([])
axs[1, 0].set_yticks([])
axs[1, 1].imshow(geo_map[::, ::, 1])
axs[1, 1].set_xticks([])
axs[1, 1].set_yticks([])
axs[2, 0].imshow(geo_map[::, ::, 2])
axs[2, 0].set_xticks([])
axs[2, 0].set_yticks([])
axs[2, 1].imshow(training_mask[::, ::])
axs[2, 1].set_xticks([])
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









