







 本文详细介绍了Apache Druid在Shopee的工程实践,包括Coordinator负载平衡算法、增量元数据管理和Broker结果缓存的优化,以及定制化需求开发,如基于位图的精确去重算子和灵活的滑动窗口函数。通过这些优化,Druid在Shopee的性能和稳定性得到了显著提升。
本文详细介绍了Apache Druid在Shopee的工程实践,包括Coordinator负载平衡算法、增量元数据管理和Broker结果缓存的优化,以及定制化需求开发,如基于位图的精确去重算子和灵活的滑动窗口函数。通过这些优化,Druid在Shopee的性能和稳定性得到了显著提升。
本文首发于微信公众号“Shopee技术团队”。
摘要
Apache Druid 是一款高性能的开源时序数据库,它适用于交互式体验的低延时查询分析场景。本文将主要分享 Apache Druid 在支撑 Shopee 相关核心业务 OLAP 实时分析方面的工程实践。
随着 Shopee 业务不断发展,越来越多的相关核心业务愈加依赖基于 Druid 集群的 OLAP 实时分析服务,越来越严苛的应用场景使得我们开始遇到开源项目 Apache Druid 的各种性能瓶颈。我们通过分析研读核心源码,对出现性能瓶颈的元数据管理模块和缓存模块做了相关性能优化。
同时,为了满足公司内部核心业务的定制化需求,我们开发了一些新特性,包括整型精确去重算子和灵活的滑动窗口函数。
1. Druid 集群在 Shopee 的应用
当前集群部署方案是维护一个超大集群,基于物理机器部署,集群规模达 100+ 节点。Druid 集群作为相关核心业务数据项目的下游,可以通过批任务和流任务写入数据,然后相关业务方可以进行 OLAP 实时查询分析。
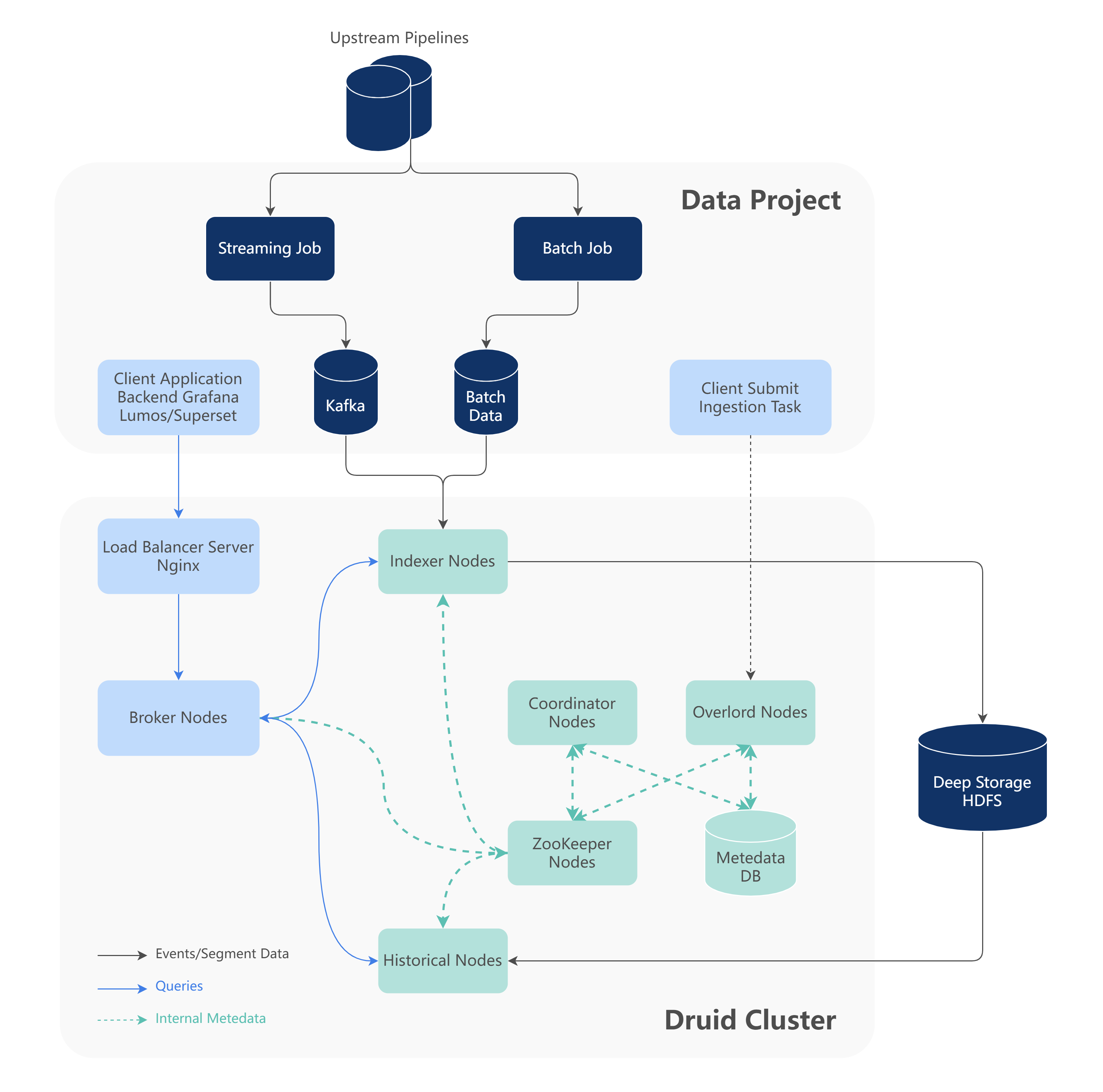
2. 技术优化方案分享
2.1 Coordinator 负载平衡算法效率优化
2.1.1 问题背景
我们通过实时任务监控报警发现,很多实时任务因为最后一步 segment 发布交出(Coordinate Handoff)等待超时失败,随后陆续有用户跟我们反映,他们的实时数据查询出现了抖动。
通过调查发现,随着更多业务开始接入 Druid 集群,接入的 dataSource 越来越多,加上历史数据的累积,整体集群的 segment 数量越来越大。这使得 Coordinator 元数据管理服务的压力加大,逐渐出现性能瓶颈,影响整体服务的稳定性。
2.1.2 问题分析
Coordinator 一系列串行子任务分析
首先我们要分析这些串行是否可以并行,但分析发现,这些子任务存在逻辑上的前后依赖关系,因此需要串行执行。通过 Coordinator 的日志信息,我们发现其中一个负责平衡 segment 在历史节点加载的子任务执行超级慢,耗时超过 10 分钟。正是这个子任务拖慢了整个串行任务的总耗时,使得另一个负责安排 segment 加载的子任务执行间隔太长,导致前面提到的实时任务因为发布阶段超时而失败。
通过使用 JProfiler 工具分析,我们发现负载平衡算法中使用的蓄水池采样算法的实现存在性能问题。分析源码发现,当前的蓄水池采样算法每次调用只能从总量 500 万 segment 中采样一个元素,而每个周期需要平衡 2000 个 segment。也就是说,需要遍历 500 万的列表 2000 次,这显然是不合理的。

2.1.3 优化方案
实现批量采样的蓄水池算法,只需要遍历一次 500 万的 segment 元数据列表,就能完成 2000 个元素的采样。优化之后,这个负责 segment 负载平衡的子任务的执行耗时只需要 300 毫秒。Coordinator 串行子任务的总耗时显著减少。
Benchmark 结果

Benchmark 结果对比发现,批量采样的蓄水池算法性能显著优于其他选项。
社区合作
我们已经把这个优化贡献给 Apache Druid 社区,详见 PR。
2.2 增量元数据管理优化
2.2.1 问题背景
当前 Coordinator 进行元数据管理的时候,有一个定时任务线程默认每隔 2 分钟从元数据 MySQL DB 中全量拉取 segment 记录,并在 Coordinator 进程的内存中更新一个 segment 集合的快照。当集群中 segment 元数据量非常大时,每次全量拉取的 SQL 执行变得很慢,并且反序列化大量的元数据记录也需要很大的资源开销。Coordinator 中一系列 segment 管理的子任务都依赖于 segment 集合的快照更新,所以全量拉取 SQL 的执行太慢会直接影响到整体集群数据(segment)可见性的及时性。
2.2.2 问题分析
我们首先从元数据增删改的角度,分 3 种不同的场景分析 segment 元数据的变化情况。
元数据增加

dataSource 的数据写入会生成新的 segment 元数据,而数据写入方式主要分为批任务和 Kafka 实时任务。Coordinator 的 segment 管理子任务及时感知并管理这些新增加的 segment 元数据,对于 Druid 集群写入数据的可见性非常关键。通过 Druid 内部自带 metric 指标,分析发现 segment 单位时间内的增量远远小于总量 500w 的记录数。
元数据删除
Druid 可以通过提交 kill 类型的任务来清理 dataSource 在指定时间区间内的 segment。kill 任务会首先清理元数据 DB 中的 segment 记录,然后删除 HDFS 中的 segment 文件。而已经 download 到历史节点本地的 segment,则由 Coordinator 的 segment 管理子任务负责通知清理。
元数据更改
Coordinator 的 segment 管理子任务中有一个子任务会根据 segment 的版本号,标记清除版本号比较旧的 segment。这个过程会更改相关元数据记录中代表 segment 是否有效的标志位,而已经 download 到历史节点本地的旧版本 segment
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









