







全连接神经网络在图像处理方面所遇到的困难
作为一幅图像,其中的信息维度通常是很高的。假设需要处理的是一幅1000×1000像素的RGB图像,那么输入层就需要有1000×1000*3个神经元,也就是说输入向量X的维度达到了3×10^6,如果神经网络的第1层(输入层可以视为第0层)有1000个隐藏单元(hidden units),那么W1就是一个大小为[1000, 3×10^6]的矩阵,其中含有30亿个参数。在参数如此巨大的情况下,难以获取足够数据防止神经网络的欠拟合。

经典全连接神经网络
因此我们需要一种运算方式来减小输入全连接网络的特征向量的维度。这种运算就是卷积运算。
卷积运算(Convolution)
图像处理领域的卷积运算是通过一个卷积核(例如一个f×f的矩阵)在n×n的图像上以一个像素为单位滑动,那么可以有(n-f+1)×(n-f+1)个滑动位置,这些滑动位置又构成了一个(n-f+1)×(n-f+1)的新图像。
新图像上的各像素值为卷积核与原图像对应像素值乘积之和。

原图像大小6×6,卷积核大小3×3,则输出图像大小为4×4
*事实上,在严格的数学意义上,上述运算被称为互相关(Cross-correlation)而不是卷积。真正的卷积需要进行的操作是先将卷积核做镜像的翻转(如下图所示的3×3卷积核,翻转的中心是左下到右上的对角线),之后再令原图像与翻转后的卷积核做对应的滑动乘积加和运算。不过在机器学习或深度学习领域,我们所说的卷积默认是不进行卷积核翻转操作的。

严格数学意义上的卷积运算
特殊的卷积核可以实现一些特定的图像处理功能,例如下面的卷积核就可以用来检测竖直的边缘线:
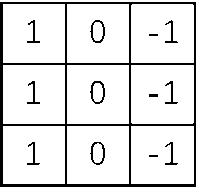
下图所示图像与这个卷积核做卷积运算后,其中间的竖直边缘线便被提取出来。

同时,我们也可以将这样一个卷积核中的f×f个像素值作为参数,收集希望卷积核实现的功能(例如识别斜45°的边缘线)的样本集,用前向和反向传播算法找到最有效的f×f个参数,你也就创造出了一个能够实现期望功能的卷积核。
基本卷积操作
1.Padding
在刚才讲述图像卷积时我们会发现,在经历过一次卷积后,原本n×n大小的图像缩水为了(n-f+1)×(n-f+1)大小,这限制了我们运算卷积的次数,因为图像会变得越来越小。
另外,位于原图像中心位置的像素点1可以参与f×f次的卷积运算,也就是说这些点的信息可以在输出图像的f×f个像素值中“保留”下来。而边缘位置的点2只参与了f次卷积运算,最极端的是位于角落的像素点3,它只能参与1次。这样,在经历多次卷积运算后,原图像边角处的像素信息就基本无法得到保留了。

为了解决这个问题,可以在卷积运算开始前在原图像外层额外填充一层像素(下图中蓝色的部分),使原图像大小变为(n+1)×(n+1)。习惯上,我们以0作为填充。

将填充像素的层数记为p=padding,上图中p即为1,如此再进行卷积运算后,输出图像的大小变为(n+2p-f+1)×(n+2p-f+1)。
常用的两种Padding方式:
- Valid convolution
- Same convolution
顾名思义,Valid即表示不进行Padding;Same表示进行Padding且输出图像大小与原图像一致,为此,n+2p-f+1=n,则p=(f-1)/2。
2.Strided convolution
卷积步幅,即卷积核在原图像上滑动一次所移动的像素。如下图所示的卷积步幅即为4。当然这样是为了方便演示,实际中应该是不会在中间空出像素不进行卷积运算的。

这时,输出图像的边长计算公式为: [n+2p−fs+1]\left[ \frac{n+2p-f}{s} +1 \right] ,其中括号表示如果不能整除(例如上图情况),则需要向下取整。
三维卷积
至此,我们已经了解了二维图像的卷积运算是如何进行的,但是对于图像处理来讲,图像信息通常是三维的(每个像素点包含RGB三通道值)。卷积核也需要相应地拓展维度,此时的卷积可以想象为下面的样子。

三个维度的名称分别为height×width×channels,卷积核与原图像的通道数必须保持一致。
需要注意的是,这样运算出的结果是一个4×4×1的矩阵。
具体运算规则:
将卷积核视为一个3×3×3的立方体,原图像可以看作一个6×6×3的槽。卷积核先放入原图像的左上角中,对应的27个数相乘后加和,得到输出图像矩阵(1,1)像素值,之后卷积核以一定步幅滑动,与二维卷积大同小异。

稍加思考可以发现,上述运算步骤可以分解为3个互不相关的二维卷积,得到3个4×4的输出图像。三维卷积的结果只是将这3个二维卷积输出结果叠加起来而已。
也由于不同通道间的互不相关,我们可以赋予卷积核上各通道以不同的功能。若如下图这样设置,我们的卷积核就具有识别原图像R通道内竖直边缘线的功能,同时对于G、B两通道不敏感;

而若如下设置,则卷积核就可以识别RGB三个通道的竖直边缘线

同时,这也解释了为什么卷积核与原图像的通道数为什么必须匹配。

试想我们使用了两个卷积核(如上图),一个用来检测竖直边缘,另一个用来检测水平边缘,这样我们得到了两个4×4的矩阵。将其叠放在一起,维度即为4×4×2,也就是说输出图像的通道数取决于使用的卷积核的个数。这样我们就可以检测原图像的多种特征,而这些特征都将体现在输出图像的各个通道中。
事实上,像这样用多个卷积核对一个多通道图像做卷积运算,最后得到一个新的多通道图像的计算过程,就构成了卷积层的一个单元。而像下图所示这样将若干个单元串在一起,就得到了一个简单但完整的卷积层。

图中符号定义
nH[i]n_{H}^{[i]} ,nW[i]n_{W}^{[i]} ,nC[i]n_{C}^{[i]}分别是每层图像的高、宽、通道数(原图像i=0),f[i+1], s[i+1], p[i+1]分别是作用于第i层图像的卷积核的边长、卷积步幅、Padding值,同时卷积核的个数决定了第i+1层图像的通道数nC[i+1]n_{C}^{[i+1]} 。
通常情况下,随着卷积层深度的增加,图像的长宽逐渐减小,而通道数逐渐增大。经过上面的卷积层,图像的特征量由39×39×3=4563减小为7×7×40=1960,之后就可以将这1960个特征量展开为一个长度为1960的向量,作为输入向量X传入全连接神经网络。或者会在这二者间加上一个池化层,这就涉及卷积神经网络的结构了。
卷积神经网络(CNN)结构
一个完整的卷积神经网络通常由三部分构成,分别是卷积层(Conv)、池化层(Pool)和全连接层(FC)。今天学习了卷积层的结构和工作方式,池化层将在之后学习。
作者:Erya
链接:https://zhuanlan.zhihu.com/p/328710162
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 2610
2610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









