










在使用百度飞桨下PaddleOCR2.6训练识别部分时,官方教程在项目下./doc/doc_ch/recognition.md,详细介绍了识别训练,具体过程可以参照此md文件
说一下遇到的问题,ICDAR2015数据格式如下:
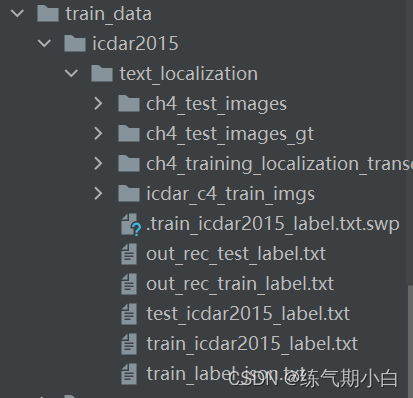
两个out.txt文件是输出的,原有的.txt文件虽然集合了图片路径和标注信息,但给的路径是相对路径,在训练识别部分时会报错,imgs does not exist 很让人崩溃是不是。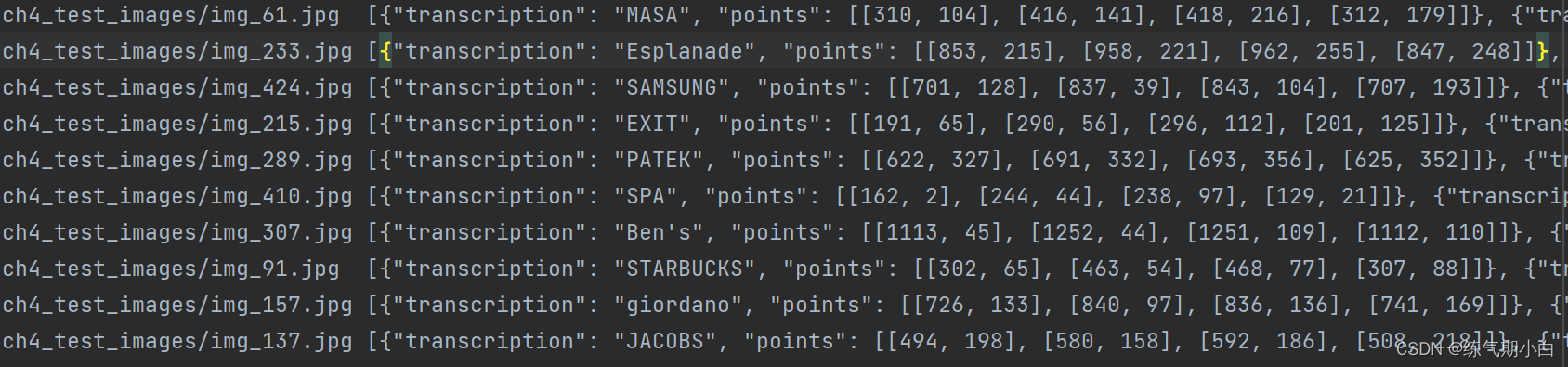
在官方转换数据格式代码的基础上做出修改,路径在./ppocr/utils/gen_label.py,官方代码:
import os
import argparse
import json
def gen_rec_label(input_path, out_label):
with open(out_label, 'w') as out_file:
with open(input_path, 'r') as f:
for line in f.readlines():
tmp = line.strip('\n').replace(" ", "").split(',')
img_path, label = tmp[0], tmp[1]
label = label.replace("\"", "")
out_file.write(img_path + '\t' + label + '\n')
def gen_det_label(root_path, input_dir, out_label):
with open(out_label, 'w') as out_file:
for label_file in os.listdir(input_dir):
img_path = root_path + label_file[3:-4] + ".jpg"
label = []
with open(
os.path.join(input_dir, label_file), 'r',
encoding='utf-8-sig') as f:
for line in f.readlines():
tmp = line.strip("\n\r").replace("\xef\xbb\xbf",
"").split(',')
points = tmp[:8]
s = []
for i in range(0, len(points), 2):
b = points[i:i + 2]
b = [int(t) for t in b]
s.append(b)
result = {"transcription": tmp[8], "points": s}
label.append(result)
out_file.write(img_path + '\t' + json.dumps(
label, ensure_ascii=False) + '\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--mode',
type=str,
default="rec",
help='Generate rec_label or det_label, can be set rec or det')
parser.add_argument(
'--root_path',
type=str,
default=".",
help='The root directory of images.Only takes effect when mode=det ')
parser.add_argument(
'--input_path',
type=str,
default="D:/Learn/paddleocr2.6/train_data/icdar2015/text_localization/test_icdar2015_label.txt",
help='Input_label or input path to be converted')
parser.add_argument(
'--output_label',
type=str,
default="out_rec_test_label.txt",
help='Output file name')
args = parser.parse_args()
if args.mode == "rec":
print("Generate rec label")
gen_rec_label(args.input_path, args.output_label)
elif args.mode == "det":
gen_det_label(args.root_path, args.input_path, args.output_label)
修改之后的代码:
import os
import argparse
import json
def collect_paths_and_annotations(input_path, output_label, mode):
with open(output_label, 'w') as out_file:
with open(input_path, 'r') as f:
for line in f.readlines():
tmp = line.strip().split('\t')
img_path, annotations = tmp[0], tmp[1]
img_path = os.path.abspath(img_path) # Convert to absolute path
img_path = img_path.replace("\\", "/") # Convert to Unix-style path
if mode == "rec":
# In rec mode, annotations are the labels directly
out_file.write(f"{img_path}\t{annotations}\n")
elif mode == "det":
# In det mode, annotations are in JSON format, so we parse them
annotations = json.loads(annotations)
annotations_str = json.dumps(annotations, ensure_ascii=False)
out_file.write(f"{img_path}\t{annotations_str}\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--mode',
type=str,
default="rec",
help='Generate rec_label or det_label, can be set rec or det')
parser.add_argument(
'--input_path',
type=str,
default="D:/Learn/paddleocr2.6/train_data/icdar2015/text_localization/train_icdar2015_label.txt",
help='Input_label or input path to be converted')
parser.add_argument(
'--output_label',
type=str,
default="D:/Learn/paddleocr2.6/train_data/out_rec_train_label.txt",
help='Output file name')
args = parser.parse_args()
collect_paths_and_annotations(args.input_path, args.output_label, args.mode)这样把原有的相对路径.txt文件转换成绝对路径

问题解决!
顺便一提opencv-python版本兼容的问题,最新版本opencv会和项目有一定冲突,经过实验,发现以下版本最好
pip install opencv-python==4.6.0.66顺利训练!















 7463
7463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









