







文章目录
前言
今天开始阅读OCR 文本检测模型 - EAST论文, 这里做下笔记。
论文标题: EAST: An Efficient and Accurate Scene Text Detector
Abstract
本论文之前的文本检测方法效果不错,但是在有挑战性的场景中,即使使用深度学习模型,检测效果也是不佳。这是因为检测性能不是仅仅受单一指标影响,而是多个阶段相互作用的结果。论文提出了一种简单高效的自然场景文件检测模型,速度快,准确性高。这个模型用一个单一的神经网络,直接在一完整图像上预测文字或文本行,包括任意角度和四边形,祛除了不需要的中间步骤,比如单词f分割,候选区域合并。这个模型让我们可以把更多的精力花费在损失函数以及深度网络结构的设计上。通过在ICDAR2015, COCO-Text 和MSRA-TD500数据集上进行实验,证明了论文模型在准确性和效率上的sate-of-the-art。
论文成果:在720p 图像上,F-score : 0.7820, 检测速度:13.2fps
1. 介绍(Introduction)
从ICDAR等竞赛以及2016年NIST发表的TRAIT可以看出,自然场景文本信息的提取与理解变得越来越重要和流行。
文本检测(text detection)作为后续处理的前提条件,在文本信息提取与理解中扮演了重要角色。先前的文本检测方法在这一领域表现出色。文本检测的核心是设计出可以把文本从背景中显著区分出来的特征。传统方法中,特征是由人工设计的,而深度学习方法则直接中数据中训练获得。
然而,已有的方法,不论是传统方法,还是CNN, 都是由几个步骤顺序执行从而实现文本检测。这就导致检测结果可能不是最优的,而且需要耗费更长的时间来完成。因此,现有方法的准确性与效率仍没有达到预期效果。
论文提出的文本检测 pipeline 由2个步骤完成,速度快且准确率高。
步骤1: 使用全卷积网络(fully convolutional network, FCN)模型,直接对单词或文本行进行预测,去除了多余的且执行速度慢的中间步骤;
步骤2:对预测的文本(预测结果可以是带有角度的矩形框,也可以是任意四边形)进行非极大值抑制(Non-Maximum Suppression, NMS)并输出最终结果。
实验结果:
- ICDAR 2015, F-score=0.7829 , 多尺度测试 F-score=0.8072;
- MSRA-TD500, F-score=0.7608;
- COCO-Text, F-score=0.3945;
精度上胜过之前的SOTA(state-of-the-art), 但是检测速度更快(Titan-X GPU, 720p 分辨率图像,在性能最好的模型上速度达到13.2fps,在最快的模型上达到16.8fps)。
论文贡献总结:
a. 提出的场景文本检测由2个步骤组成:FCN和NMS。FCN对文本区域直接预测,去除冗杂和浪费时间的中间步骤。
b. 论文提出的pipeline易于生成单词级别或者文本行级别的预测结果,针对不同的应用,可以选择生成旋转矩形(rotated boxes)或者任意四边形(quadrangles)作为最终的文本预测输出。
c. 论文提出的算法模型在精度和速度上超过已有的SOTA。
2. 相关工作(Related Work)
场景文本检测与识别一直都是计算机视觉任务中比较活跃的研究方向,研究方法主要包括:基于人工特征的传统方法和基于深度学习的方法。
传统方法主要依靠人来设计特征。笔触宽度变换(Stroke width transform, SWT)和最大稳定极值区域(Maximally Stable Extremal Regions, MSER)通过边缘检测或者极值区域提取的方法来确定候选文字。Zhang 等人利用文本的局部对称属性来设计了多种文本区域检测特征。FASText是一个fast 文本检测系统,它应用并改进了FAST关键点检测器来提取笔触信息。然而,这些传统方法不论在识别精度还是适应性方面都落后于基于深度卷积网络的方法,特别是在有挑战性的场景中,比如低分辨率(low resolution), 几何畸变(geometric distortion)。
基于卷积神经网络的场景文本检测渐渐成为主流。但是现有的方法都是基于多个步骤来完成的,比如为过滤掉假阳性(false positive)结果的后处理过程,候选区域的整合过程,多个单一文本形成文本行过程和单一文本分割过程。这些步骤都需要进行穷举调整,这就造成了次优的结果,并且造成整个检测过程消耗更多的时间。
论文提出的基于深度FCN的方法直接对单词或文本行进行检测,移除了额外的中间过程,可以进行end-to-end训练与优化,如图Fig.2所示。

3. 方法(Methodology)
论文的核心部分是一个神经网络模型,用它可以直接从一整张图像上预测出是否存在文本以及文本的几何形状。这个模型采用FCN来预测单词或文本行,去除了中间步骤,比如候选区域选择,文本行区域形成以及单词分割。后处理过程仅保留了阈值处理以及NMS处理。论文命名这一网络模型为EAST,即高效且准确的文本检测模型(Efficient And Accuracy Scene Text detection)。
3.1 文本检测过程(Pipeline)
完整的pipeline如Fig.2(e)所示。算法沿用了DenseBox的设计,输入一张图像,输出pixel级别的表示文本的分数(score map)以及定位(geometry)的多通道结果。
其中一个输出通道表示预测分数(score map),像素值在 [ 0 , 1 ] [0,1] [0,1]范围内,其它输出通道用来表示包含文本的几何框。
论文应用两个几何形状来表示文本区域,旋转矩形(roated box, RBOX)和任意四边形(Quadrangle, QUAD),并分别为它们设计了各自的损失函数。阈值处理应用于每一个预测文本区域,如果预测分数高于阈值,则保留,否则丢弃。阈值化结果后经过NMS处理输出最终的文本检测结果。
3.2 网络设计(Network Design)
在设计文本检测网络时有几点需要考虑。首先是文本区域的大小是多变的,对于大的文字需要更深层的网络特征来预测,对于小的文字则需要浅层的网络输出特征来预测。因此,文本检测网络首先要满足不同大小文字检测的需求。HyperNet虽然可以满足这一需求,但是计算量大。论文则采用U-shape逐渐合并特征图的方法,即从深层到浅层逐渐合并。论文模型结构如图Fig.3所示。

这个模型由三部分组成:主干(stem)-特征提取,分支(branch) - 特征融合,输出层。
主干(stem)是一个卷积与池化层交叉的卷积网络,该网络在ImageNet数据集上进行预训练。从stem中提取出4级feature maps, 分别为 f 1 , f 2 , f 3 , f 4 f_{1}, f_{2}, f_{3}, f_{4} f1,f2,f3,f4, 这4级feature maps的大小分别是输入图像大小的 1 / 32 , 1 / 16 , 1 / 8 , 1 / 4 1/32, 1/16, 1/8, 1/4 1/32,1/16,1/8,1/4。Fig.3中PVANet作为特征提取网络,论文也采用VGG16模型进行实验,特征图分别采用 pooling-2 到 pooling-5 的输出。
分支(branch)使用如下公式来进行特征融合:
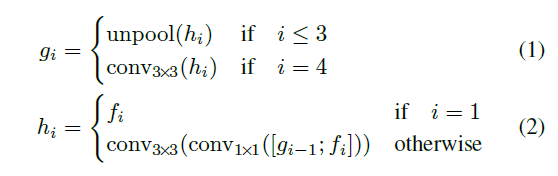
公式中 h i h_{i} hi表示融合后的特征图,融合采用按通道拼接的方法。首先, h 1 = f 1 h_{1}=f_{1} h1=f1, 然后 h 1 h_{1} h1经过上采样并与 f 2 f_{2} f2按通道拼接,最后经过1x1,3x3卷积得到 h 2 h_{2} h2,重复同样的过程依次得到 h 3 h_{3} h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









