







Context Encoders: Feature Learning by Inpainting
Introduction
在这这篇文章中,作者提出了Context Encoders,利用图像修复(Inpainting)的方法,学习图像中的上下文信息。图像是自监督学习中的常用思路,因为图像修复必然需要用到图像中不同部分的信息,在图像修复的同时,也得到了特征学习的目的。论文地址
本文的思路和方法相对比较容易理解,作者首先将图像中的随机区域丢弃,丢弃填补0像素值,之后利用encoder-decoder机构学习恢复原图,之后将修复的图像和原图共同输入到GAN中。在训练完成后,作者将encoder-decoder的部分参数作为预训练模型应用于其他的任务。方法的总体结构如下:

Method
Encoder-Decoder Pipeline
本文在这里使用的方法很简单。编码器基于Alexnet设计,后面接一个全连接层。全连接层和通常大家使用的稍有差别。因为该方法的任务是修复图像,就需要网络能够学习到图像中尽可能多区域的信息,也就是说感受也要覆盖全图,而且要让每个区域都具有连接关系。但是直接使用全连接层的话参数量很大,假设encoder出来的feature map的尺寸是 n × n × m n\times n\times m n×n×m, 那么全连接层的参数会变成 m 2 n 4 m^2n^4 m2n4。作者在这里是对特征图的每个通道,分别使用全连接层计算,需要计算 m m m次,每次的参数是 n × n n\times n n×n,总参数量是 m n 2 mn^2 mn2。decoder部分没有什么变化,使用上采样层对图像进行上采样,直至恢复到原图大小。
损失函数
损失函数由两部分构成,一部分是重构的损失函数,另一部分是对抗损失函数 (就不说了,太常见了现在)。重构损失函数如下:
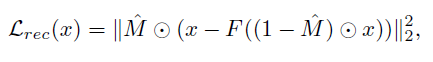
M
M
M表示被遮挡区域的掩膜,
F
F
F表示Context Encoder网络。
Experiments
为了验证特征学习的效果,作者在图像分类、目标检测和语义分割三个任务上进行了实验,数据集全部使用Pascal VOC 07。实验结果如下表所示:

该方法其实并没有取得特别优秀的性能,在三个任务上,只有分割的效果超出了其他的方法。所有的方法距离ImageNet预训练还有不小的差距。
Conclusion
该方法实际上思路非常简单,就是利用图像修复学习图像的特征,实际上作者的实验虽然说取得了一定的效果,但是提升很有限,尤其是对于检测任务,只比随机初始化提升了1个点。这里我现在的感觉是,将图像修复上色等任务作为pretext task,很容易出现局部极值,也就是说在自监督训练的过程中,网络过分关注了图像的纹理等低级别的特征,导致其缺乏泛化能力,在其他任务上无法取得一个较大的提升。















 4151
4151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









