






一、摘要
本文提出一种基于上下文像素预测驱动的无监督视觉特征模型——一种经过训练的卷积神经网络,用于根据周围环境生成任意图像区域的内容。训练中遇到的两种损失:标准像素重建损失和重建加对抗损失。CE的学习表示不仅可以捕捉外观,还可以捕捉视觉结构的语义。
二、介绍
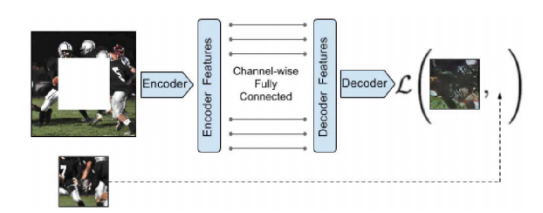
CE由一个编码器和一个解码器组成,编码器将图像的上下文捕获为紧凑的潜在特征表示、解码器来产生丢失的图像内容。
CE能解决更艰巨的任务,填充图像中大量缺失的区域,而且它无法从附近的像素中获得提示,这需要对场景有更深入的语义理解,并能在大的空间范围内合成高级特征。
重建损失(L2损失)捕获与上下文相关的缺失区域的整体结构,对抗损失具有从分布中选择特定模式的效果。
图像生成
CNN网络可以学习生成特定的对象类别(比如说椅子和面部)的新图像,但依赖于带有这些类别示例的大型标记数据集。相反,上下文编码器可以应用于任何无标记的图像数据集,并基于周围环境产生新图像。
图像修复和空洞填充
填充大洞通常是通过Scene completion(场景完成)来完成的,场景完成是指填充通过移除整个对象而留下的洞,并且它很难填充任意的洞。CE通常能够以参数化的方式修复语义上有意义的内容,并为基于最近邻的修复方法提供刚好的特征。
三、用于图像生成的上下文编码器
通过通道全连接层连接编码器和解码器很重要,这允许解码器中的每个单元对整个图像内容进行推理。
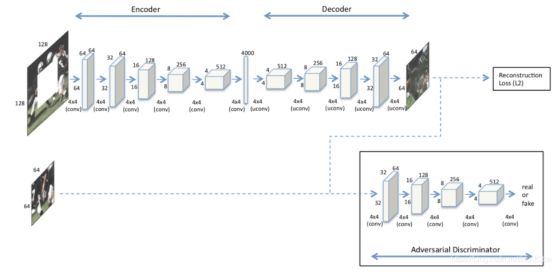
一种适用于固定大小比例、固定形状的修复(128x128到64x64):
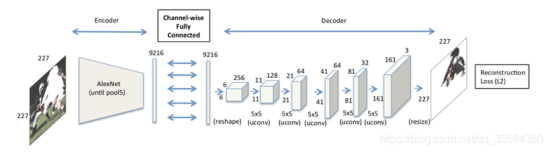
一种适用于不固定大小,不固定形状的修复(原图大小到原图大小):输入图像的大小是227*227,经过五个卷积层(卷积层后跟一个激活函数层,两个卷积层经过一次池化层)输出维度为6*6*256,网络是用随机初始化的权重“从头开始”训练上下文的。
如果编码器架构仅限于卷积层,则信息无法直接从特征图的一个角传播到另一个角,因为卷积层将所有的特征图连接在一起,但不直接连接特定特征图内的所有位置,本文的信息传播由全连接层或内积层处理,其中所有的激活层都直接相连。但是全连接层将导致参数数量激增,提出了通道式全连接层。
通道式全连接层
该层本质上是一个具有组的全连接层,在每个特征图的激活层中传递信息。是一系列具有学习滤波器的五个上卷积层(每层具有整流线性单元激活函数),与全连接层不同,它没有连接不同特征图的参数,只在特征图内传播信息,m个特征图大小为n*n,参数为,而全连接层所需参数
上卷积是一种产生更高分辨率的图像。
损失函数
L2损失负责捕获缺失区域的整体结构以及上下文的一致性,但倾向于将预测中的多种模式平均在一起。对抗损失试图使预测看起来真实,并具有从分布中选择特定模式的效果。
L2损失:
![]()
M是二进制掩码,破损位置值为1,输入像素值为0。L2(或L1)损失通常更喜欢模糊的解决方案,而不是高度精确的纹理。因为L2损失预测分布的平均值更“安全”,最小化了平均像素误差,但导致平均图像模糊。我们通过添加对抗性损失来缓解这个问题。
对抗损失:
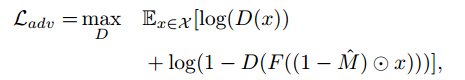
条件GAN不容易训练上下文预测任务,因为鉴别器D容易利用生成区域和原始上下文的感知不连续来容易地将预测样本与真实样本进行分类。所以只对上下文的生成器(而不是鉴别器)进行条件反射。而且当生成器不以噪声向量为条件时,结果有所改善。
四、实验细节
在caffe和torch中实现,使用随机梯度下降求解器ADAM进行优化。用恒定的均值填充被屏蔽输入图像中的缺失区域。用相同内核大小和步幅的卷积替换所有池化层,网络的整体步幅保持不变,结果更精确。在分类中,池化层提供了空间不变性,这可能不利于基于重建的训练。
五、创新点
通道式全连接层
这里就有点像分类问题了,分类问题总是先用卷积层、池化层进行特征提取,最后压缩到一维向量,利用全连接层得到分类结果。这里全连接层所起到的作用就是整合全局所有位置的特征信息,或者说,全连接层屏蔽了特征在location上的差异,进行了全局的整合,但全连接层同样存在一个众所周知的问题:参数太太太太多了,于是提出了通道式全连接层。
对抗损失
重建损失最小化了平均像素误差,导致平均图像很模糊,对抗损失+重建损失使图像修复结果大大提升。















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









