







Transitive Invariance for Self-supervised Visual Representation Learning
Introduction
这篇文章的作者就包括何凯明,文章的思路和Contrast Loss的思路很像,就是保证网络对于相似图像提取出出来的特征要尽可能相近,对于相差较大的图像提取的特征要尽可能远离。至于相近图像和相异图像如何确定呢,作者提出了一种基于图的方法(感觉这个有炒概念的嫌疑,实际上是用聚类和跟踪来做的)。论文地址。
Method
作者从视频数据中截取图像切片,之后将图像切片分为两种类型,第一种是inter-instance,不同实例但是具有相同的角度或者场景;第二种是intra-instance,相同的实例但是可能角度场景等不同。作者认为这两类在网络中都应该具有相似的特征。
为了区分出这两种切片,作者提出了一种基于图的方法,将切片作为图中的节点,然后对应以上两种类型,就会有两种边,如图所示:
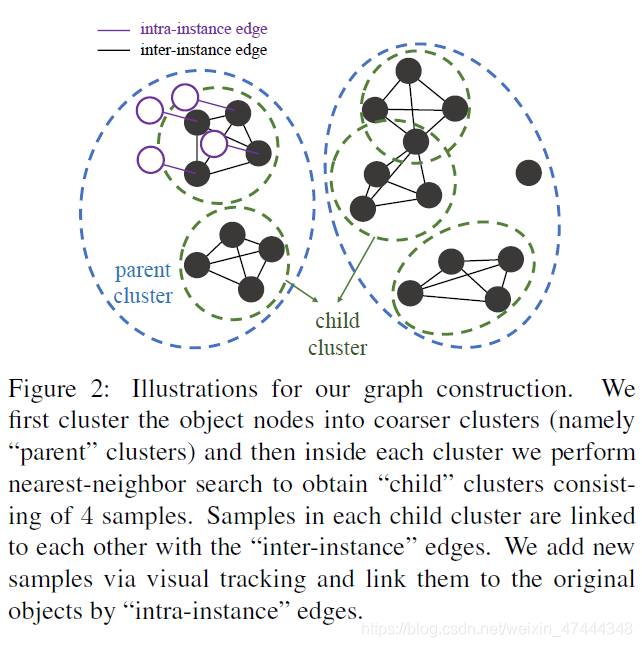
这两种边的确定方式下面会介绍
Inter-instance Edges via Clustering
作者首先训练自监督学习网络,这里训练的网络不是最终的结果,这里的网络是为了提取一个初步的特征,用于聚类确定Inter-instance Edges。自监督网络这里使用了自监督学习(三)Unsupervised Visual Representation Learning by Context Prediction中介绍的方法。之后利用pool5层输出的特征对图像切片进行聚类,这里采用了层次聚类的方法,确定Inter-instance Edges。
Intra-instance Edges via Tracking
这里作者是采用了视频中不同帧的数据确定Intra-instance Edges。
Learning with Transitions in the Graph
假设一个节点的集合是{A,B,A’,B’},其中<A,B>之间是inter-instance edge连接的,而<A,A’>和<B,B’>是通过intra-instance edge连接的,那么<A,B’>、<A’,B>和<A’,B’>经过网络都应该获得相似的特征。这个关系如图所示:


在实际的操作中,作者构建了一个三输入的孪生网络,每次接受三个输入,如下图所示:
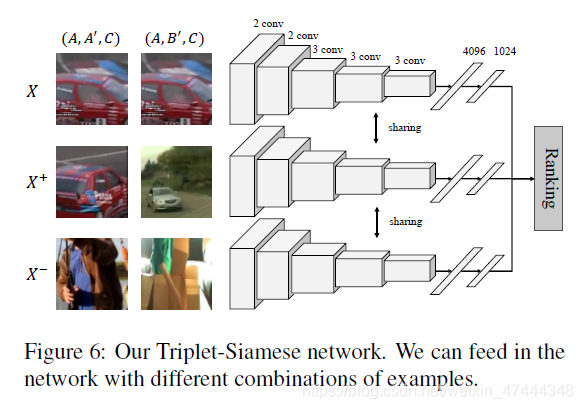
<
X
X
X,
X
+
X^+
X+>表示inter-instance或者intra-instance连接的图像,这里成为正样本。而
X
−
X^-
X−是与他们都没有连接关系的样本,表示负样本。网络训练的损失函数如下:
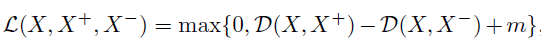
这里,D就是表示两个样本之间的距离,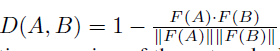
X
−
X^-
X−在这里可以理解为一个第三方变量,或者理解为中间状态等,总之是因为只限制
X
X
X和
X
+
X^+
X+会导致网络提取出固定不变的特征,所以需要第三方的输入进行约束。
Experiments
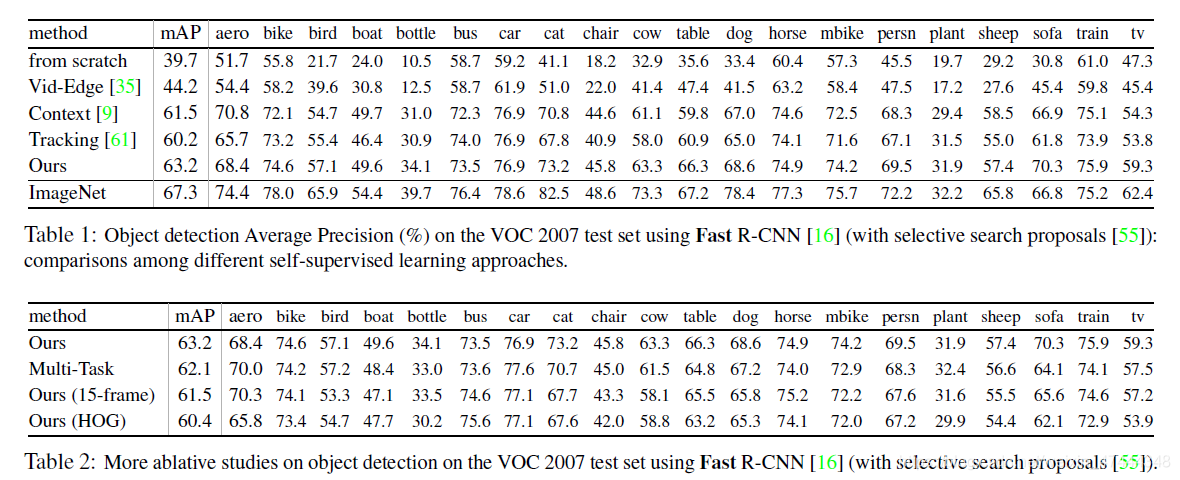
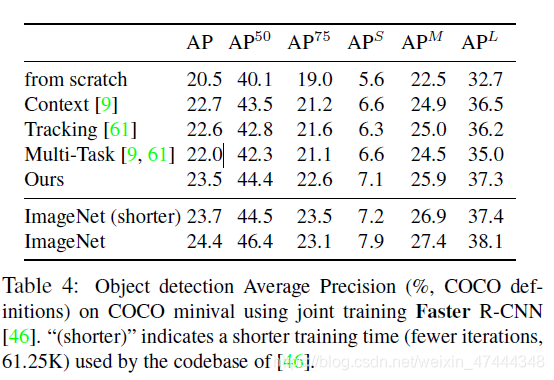
作者在Voc07上进行了检测的实验,效果不错。而且在COCO数据集上的实验,已经非常接近ImageNet的效果了。















 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









