







这篇论文最近被TCSVT接收,其主要任务为视频文本检索,并主要针对于视频特征表示学习。由于人们阅读时,通常会首先阅读概述,然后在进行精读,受这一阅读策略的启发,本文提出了一种视频特征学习方法(RIVRL)来表示视频, 它包含两个分支:一个预览分支和一个精读分支,顾名思义,预览分支用来捕捉视频的概述信息,精读分支用来捕捉视频中更加深层次的信息。
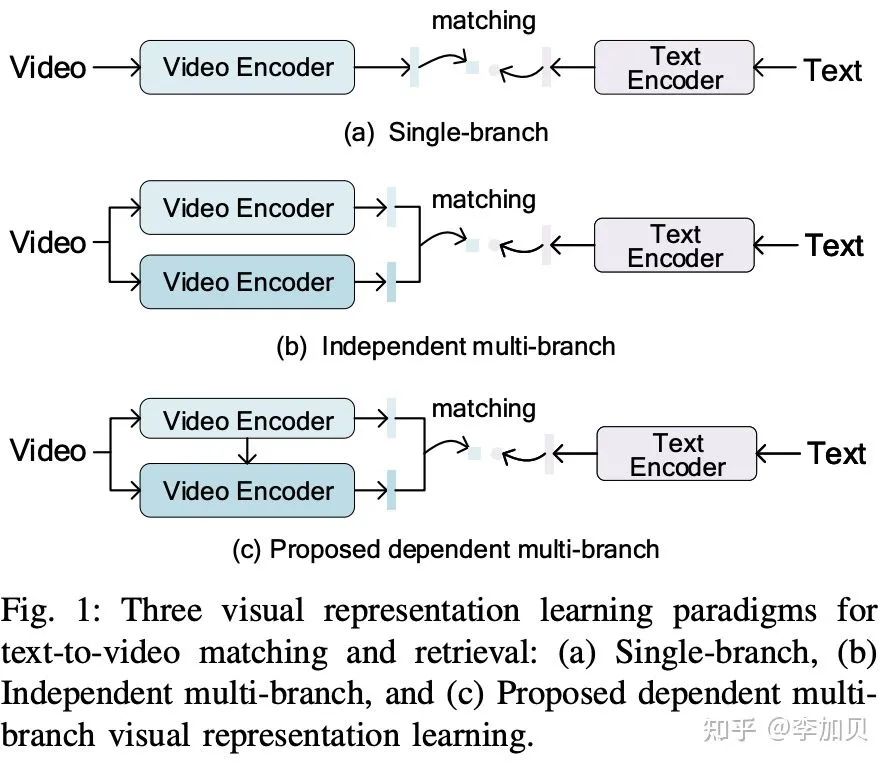
然而在该任务中,如图1所示,类似的视频特征学习的多分支范式往往都是独立的,然而作者认为,尽管这种方法取得了很好的性能,但作者认为这样的独立多分支范式是次优的。根据作者的观察,当两个分支独立学习时,两分支都倾向于学习视频中的主要对象,而忽略它具体的关键细节。因此,为了加强多个分支之间的互补性,作者设计了预览感知注意力,使得精读分支可以感知到预览分支所捕捉到的视频的概述信息,以捕捉视频中更加精确且细粒度的视频信息。
Method
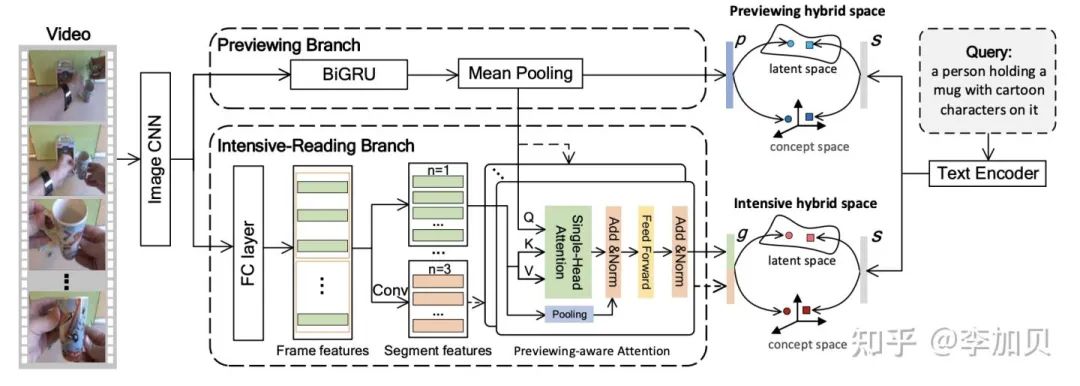
Previewing Branch
该分支主要用来捕捉视频中的概述信息,是一个轻量级的分支,通过双向GRU来提取一个序列特征
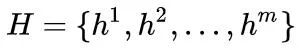
,然后将其进行平均池化得到一个向量特征 ,
Intensive-Reading Branch
该分支主要用来学习更深次的视频特征信息,受n-gram语言模型的启发,作者将n个连续的帧作为一个视频片段,其主要通过使用一个特定大小的滑动窗口将视频划分成一个片段序列,作者这里使用了多个不同大小的滑动窗口,进一步得到了多个不同长度的片段特征序列,作为多粒度的特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









