










2021年。
摘要
本文研究小模型的自监督学习。我们的实证研究表明,虽然广泛使用的对比自监督学习方法在大模型训练方面取得了很大的进步,但在小模型训练中效果并不理想。为了解决这个问题,我们提出了一种新的学习范式,称为自我监督蒸馏(SEED),我们利用一个更大的网络(作为教师)以自我监督的方式将其代表性知识转移到一个更小的体系结构(作为学生)中。我们没有直接从未标记的数据中学习,而是训练一个学生编码器来模拟教师在一组实例上推断的相似性分数分布。我们发现,SEED极大地提高了小型网络在下游任务上的性能。与自我监督基线相比,SEED在EfficientNet-B0上将top-1的准确率从42.2%提高到67.6%,在ImageNet-1k数据集上的MobileNetV3上从36.3%提高到68.2%。
1.介绍
我们推测参数较少的较小模型无法有效地学习具有大量数据的实例级区分表示。
为了应对这一挑战,我们将知识提炼(KD)(Buciluˇa等人,2006年;Hinton等人,2015年)注入到自我监督学习中,并提出将自我监督提炼(称为SEED)作为一种新的学习范式。也就是说,以自我监督的方式训练较大的教师网络,并提取较小的学生网络。SEED没有直接对较小的模型进行自我监督训练,而是首先以自我监督的方式训练一个较大的模型(作为老师),然后将知识提取到较小的模型(作为学生)。请注意,传统的蒸馏是用于监督学习的,而这里的蒸馏是在无任何标记数据的自我监督设置下进行的。监督蒸馏可以表述为训练学生在教师模型预测的课堂上模拟概率质量函数。然而,在无监督的知识提取环境中,类的分布不是直接可以实现的。因此,我们提出了一种简单而有效的自监督蒸馏方法。与(He et al.,2020;Wu et al.,2018)类似,我们维护了一个数据样本队列。给定一个实例,我们首先使用教师网络获得其与队列中所有数据样本以及实例本身的相似性分数。然后对学生编码器进行训练,模拟教师在这些数据样本上推断的相似性分数分布。
我们的贡献可以总结如下:
1.我们是第一个解决小模型自监督视觉表征学习问题的人。
2.我们提出了一种自监督蒸馏(SEED)技术,在没有任何标记数据的情况下,将知识从大模型转移到小模型。
3.通过提出的蒸馏技术(SEED),我们显著提高了小模型上最先进的自监督学习模型的性能。
4.我们详尽地比较了各种蒸馏策略,以证明SEED在多种环境下的有效性。
2.相关工作
见原文
3.方法
3.1知识蒸馏的前期准备
3.2视觉表征的自监督蒸馏
与监督蒸馏不同,SEED的目标是将知识从大模型转移到小模型,而不需要标记数据,这样小模型中的学习表示可以用于下游任务。受对比SSL(self-supervised-learning)的启发,我们提出了一种基于对比实例队列上实例相似性分布的简单提取方法。
与He et al.(2020)类似,我们维护了一个实例队列,用于存储来自教师的数据样本编码输出。给定一个新样本,我们使用教师和学生模型计算其与队列中所有样本的相似性分数。我们要求学生计算的相似性分数分布与教师计算的相似性分数分布相匹配,其公式为最小化学生和教师的相似性分数分布之间的交叉熵(如图2所示)。
特别地,对于一幅图像的随机增强的view xi,首先将其映射并标准化为特征向量: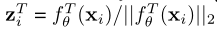 ,
,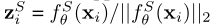 ,其中,zTi和zSi∈RD,fTθ和fSθ分别表示教师和学生的编码器。令D=[d1,d2,…,dK]表示实例队列,K是队列长度,dj是从教师编码器得到的特征向量。与对比学习框架类似,D在“先进先出”策略下随着蒸馏的进行而逐步更新。也就是说,我们将教师推断的当前批次的视觉特征排队,并在迭代结束时将最早看到的样本出队。注意,队列D中的维护样本大多是随机的,与目标实例xi无关。最小化学生和教师基于D计算的相似度分数分布之间的交叉熵与随机选择的样本xi进行软对比,而不直接与教师编码器对齐。为了解决这个问题,我们将教师嵌入(zTi)添加到队列中,形成D+=[d1…dK,dK+1],其中dK+1=zTi。
,其中,zTi和zSi∈RD,fTθ和fSθ分别表示教师和学生的编码器。令D=[d1,d2,…,dK]表示实例队列,K是队列长度,dj是从教师编码器得到的特征向量。与对比学习框架类似,D在“先进先出”策略下随着蒸馏的进行而逐步更新。也就是说,我们将教师推断的当前批次的视觉特征排队,并在迭代结束时将最早看到的样本出队。注意,队列D中的维护样本大多是随机的,与目标实例xi无关。最小化学生和教师基于D计算的相似度分数分布之间的交叉熵与随机选择的样本xi进行软对比,而不直接与教师编码器对齐。为了解决这个问题,我们将教师嵌入(zTi)添加到队列中,形成D+=[d1…dK,dK+1],其中dK+1=zTi。
让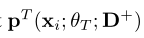 表示提取的教师特征zTi和由教师模型计算的dj(j=1,…,K+1)(教师编码器的特征向量)之间的相似性分数,其计算公式如下:
表示提取的教师特征zTi和由教师模型计算的dj(j=1,…,K+1)(教师编码器的特征向量)之间的相似性分数,其计算公式如下:

其中,τT是教师的温度参数。我们用()T表示教师网络中的特征,用(·)表示两个特征之间的内积。 同样,让pS(xi;θS,D+)表示学生模型计算的相似性分数,其定义为:

其中,τS是学生的温度参数。我们的自监督蒸馏可以表述为最小化教师PT(xi;θt,D+)和学生PS(Xi,θS,D+)的相似性分数之间的交叉熵,在所有的实例xi上,即:

由于教师网络是预先训练和冻结的,因此在训练学生网络的过程中队列特征是一致的。pTj值越高,施加在pSj上的权重就越大。由于l2标准化,在softmax标准化之前,zTi和d K+1之间的相似性得分保持恒定1,这是pTj中最大的。因此,p S K+1的权重是最大的,可以仅通过调整τT的值进行调整。通过最小化损失,zSi的特征可以与zTi对齐(z是对于每个样本图像的标准化特征向量),同时与D中其他不相关的图像特征进行对比。我们在附录A.5中进一步讨论了这两个目标与我们的学习目标之间的关系。
与Info-NCE 损失的关系:当τT→ 0时,pT的softmax函数平滑地接近一个热向量,其中pTK+1等于1,所有其他值均为0。在这种极端情况下,损失变成:

这与基于对比的自监督学习中广泛使用的Info-NCE损失(Oord et al.,2018)类似(见附录A.6中的讨论)。
4.实验
4.1预训练
教师网络的自监督预培训。默认情况下,我们使用MoCo-V2(Chen等人,2020c)对教师网络进行预培训。接下来(Chen等人,2020a),我们使用ResNet作为具有不同深度/宽度的网络主干,并在平均池化后在编码器末端附加多层感知器(MLP)层(两个线性层和一个ReLU(Nair&Hinton,2010)激活层)。最后一个特征尺寸的尺寸是128。除非明确规定,否则由于计算限制,所有教师网络都经过200个epoch的预训练。由于我们的蒸馏独立于教师预训练算法,因此我们还展示了教师网络的其他自我监督预训练模型的结果,例如SWAV(Caron等人,2020年)、SimCLR(Chen等人,2020a)。
学生网络上的自监督蒸馏。我们选择了多个可学习参数较少的较小网络作为学生网络:MobileNet-v3-Large(Howard等人,2017年)、EfficientNet-B0(Tan&Le,2019年)和层数较少的较小ResNet(ResNet-18,34)。与教师网络的预培训类似,我们在学生网络的基础上增加了一个MLP层。我们的蒸馏使用标准SGD优化器进行训练,动量为0.9,重量衰减参数为1e-4,持续200个epoch。初始学习率设置为0.03,并由余弦衰减调度器(Nair&Hinton,2010)更新,具有5个预热阶段和256个批量。在等式4中,教师温度设置为τT=0.01,学生温度设置为τS=0.2。K的队列大小为65536。在以下小节和附录中,我们还展示了不同超参数值的结果,例如τT和K。
4.2微调和评估
为了验证自我监督蒸馏的有效性,我们选择评估学生编码器在几个下游任务中的表现。我们首先在ImageNet ILSVRC2012(Deng等人,2009)数据集上报告了其线性评估和半监督线性评估的性能。为了测量蒸馏带来的特征可转移性,我们还对其他任务进行评估,包括VOC07(Everingham等人)和MS-COCO(Lin等人,2014)数据集上的目标检测和分割。最后,我们比较了蒸馏学习和普通自监督对比学习在不同领域数据集线性分类任务中的可转移性。
4.3消融实验
…后文见原文
5.结论
自监督学习以其从未标记的大规模数据中学习的卓越能力而闻名。然而,小型体系结构上SSL预训练的一个关键阻抗来自于其识别大量实例的能力较差。我们没有直接从未标记的数据中学习,而是提出了一种新的自监督学习范式SEED,它通过自监督蒸馏从一个更大的SSL预训练模型中学习表示。我们在大量实验中表明,SEED有效地解决了小型模型自监督学习的弱点,并在小型体系结构的各种基准上取得了最先进的结果。















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









