







Abstract
这篇文章是发表在AAAI 2021。
MWP问题一直都是当成full-supervised task来完成,把表达式当成是label,problem description当成是训练数据,而solution只是在test的时候才会用到。那么在full-supervised的情况下就会出现train-test discrepancy,训练的时候使用的是equation,测试的时候使用的是solution。而且full-supervised所需要的数据标注也需要时间。同时,一个问题会对应多种不同的解释,而如果只用一个equation那只能得到一种解释,无法使得model更进一步理解problem text。 事实上我个人认为,multi-equation应该是这个模型准确率能得到很好提升的重要原因。以上提出的三点就是论文模型的动机。本文提出的weak supervised方法能有效的解决这三个问题,1.测试集和训练集的数据训练方法和测试方法一致。2.可以产生多给solution。3.不再需要标注equation。
本文model要解决的问题和full supervised不太一致,full-supervised解决的是带有表达式的数据,problem text + equation + solution。而weak supervised只有problem text + solution,这样不需要equation表达式,而且去掉了强监督equation。没有了强监督的学习,model自然要探索多条equation的路径,这样就会出现多个解。没有equation帮助model训练,那么model也只能用solution训练,这样discrepancy也就消失了。
这篇文章的内容和周志华老师组的一篇《Bridging machine learning and logical reasoning by abductive learning》的框架方法一致,也是我目前正在做的idea,被人捷足先登了。目前这篇发在2021AAAI的组之前还有一篇《Closed Loop Neural-Symbolic Learning via Integrating Neural Perception, Grammar Parsing, and Symbolic Reasoning》也是用了这个框架,ideal基本不变,就是换了一个更大的数据而已。
Model

方法大致框架如上,事实上很多weak supervised问题都可以利用这种方式完成。首先,利用Goal-driven方法生成树,注意这里的生成是无标签生成,所以大概率生成的树是错误的,然后利用fixing maechanism机制根据solution修补这棵树,修补完成后的树当成pesudo-label训练Goal-driven模型即可。
这种方法比较适合一些有中间状态的问题,比如MWP问题中间就有一个equation作为中间状态。这个中间状态就可以利用abdutive reasoning或其他的推断方法修补。
这里的Goal-driven方法就是前面一篇a goal-driven method解决MWP的方法
https://blog.csdn.net/weixin_47474348/article/details/114365934
这篇文章主要的贡献是提出了Learning by fix的方法,简称LBF。其实就是溯因推理。
LBF
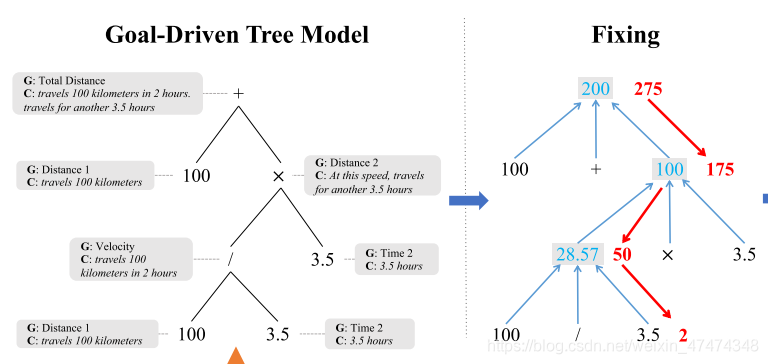
当goal-driven方法推导出一条等式之后,会去计算这个等式的solution,看看这个solution是否和label中的solution是一致的,如果不一致则需要修正,修正的结构很简单,比如上图275是正确答案,那么逆推下来即可。但是逆推是会有很多答案的,比如可能是左边的100出错,也可能是右边的100出错,所以会产生许多种答案。
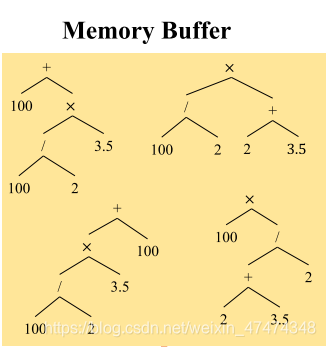
所以,LBF还为每一个problem准备了一个memory buffer,存储每一个problem text通过LBF推导后产生的结果。在利用pesudo-label训练的时候,memory buffer种对于这个问题的所有pesudo-label的equation都会用于训练。也就是说,一个问题可以训练很多次。训练的loss function也是和goal driven一样。
Experiments
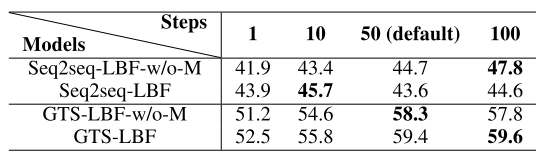
数据集使用的是Math23k,2w多个数据集。Goal-driven模型使用seq2seq和MAPO模型替换,而后面监督部分用LBF替换:
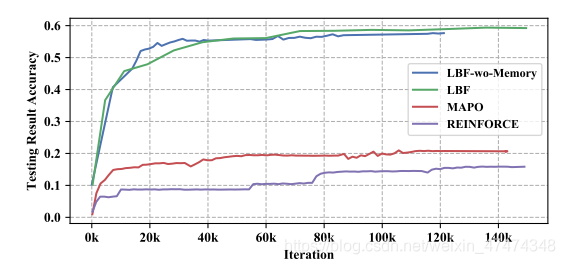
在无监督的情况下还能达到59.6%的准确率。
Conclusion
这篇文章使用weak-supervised的方法解决了MWP问题,并使用LBF框架提升准确率。事实上LBF框架这个团队一早就提出来了。而且整个weak-supervised的框架在17年周志华老师的团队就提出过,所有在模型上个人觉得贡献不大。能够发到AAAI主要原因应该还是第一个使用weak-supervised方法解决大佬MWP问题,并且是在Math23k这样大的数据集上还能达到59.6%的准确率。
简单来说,这篇文章的model也可以理解成通过DL识别,Reasoning修补的过程,所以也属于DL结合reasoning的模型,如果我做早点就好了。
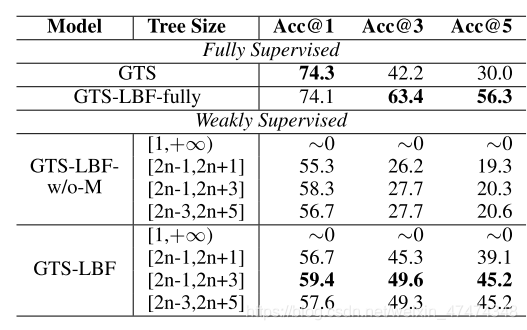
goal-driven在full-supervised方法下能达到74%的准确率,而weak-supervised中goal-driven+lBF如果只选择memory-buffer的top 1来训练最高能到60%,所以multi-equation的训练机制到底有没有效果还需要进一步确定。如果能设计一个评估函数评定pesudo-lebel的好坏可能更好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









