







Abstract
这篇文章也是解决MWP问题的。之前有看过其他的文章,比如MathDQN,T-RNN等,MathDQN是利用强化学习解决MWP问题,但实际上还是一个监督学习的模型,提取文本特征和数字对,预测数字对之间的操作符,然后和equation对比。许多生产树的模型也是怎么做。T-RNN则是利用equation生成表达式,T-RNN和之前的一些transformer,seq2seq的方法不太一样,那些方法都是直接生成表达式,而T-RNN是生成模板,然后填充,方法上有新颖的地方。本文的模型也是在方法上的创新,提出了一种基于目标驱动的方法。通过对表达式的分解完成对目标的分解。 树的分解其实很多文章都有,比如生成expression tree的模型和MathDQN都会对树做分解,但是他们的分解并没有什么实际的意义,只是为了操作方便,而本文的分解是有实际意义的,表达树的分解也对应着不同的子目标,提供了解释。
同时这篇文章也在Math23k上取得了很好效果,随着Math23k,doplion18k这些大型数据集的出现,以后要做这个问题可能都要在这些数据集上测试认可度才能高一点,毕竟Math word problem model一直以来的通病就是数据集小,泛化能力不强,出现了seq2seq这些模型之后泛化能力才好一些。
这篇文章刚看前面的时候就注意到goal-driven了,但是这篇文章的goal-driven本质上就是给expression tree加上一个文本text的解释,把树的每一个分支和文本对应起来。这篇文章倒是给了我一个启发,前面许多的模型,包括seq2seq这些generate equation的model在训练的时候都没有用到result,而label实际上是提供了result的,如果把result看成是final goal,如果能够把这个result利用起来,是不是也是一种goal-driven呢?这样也就能提出一种新的方法,这种方法还能利用上result。
Introduction
goal-driven model主要的对比对象还是seq2seq model。seq2seq model的优点,1.能够生成一些不在训练数据里面的表达式;比如 π \pi π。2.泛化能力更好。3.不需要特征工程。 但是缺乏了目标驱动。
那什么是目标驱动?
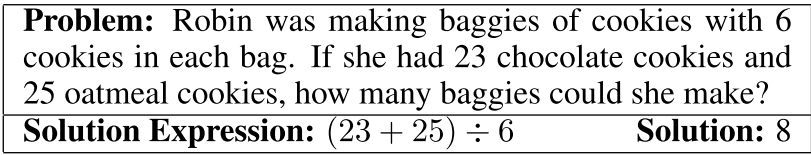
MWP问题如上图所示,会提供problem text和label,label包括equation和solution,也就是result。question是how many baggies作为第一个goal,接下来就是要对这个目标做分解,根据等式,左子树是23+25,右子树是6;左子树的goal是How many cookies?右子树的goal是How many cookie in each bag?

其实就是给expression tree加上某种解释,和seq2seq model主要不同就在于生成的方式不同,已经goal-driven model具有更好的可解释性。
contribution:
1.提出了一种生成表达式的新的方法。
2.模型的信息流上到下,下到上。
3.应用在大规模数据集Math23k上,并且表现比SOTA要好。
Model Structure
准备工作: 首先先要把文本中数值都替换成 N U M NUM NUM,因为这些文本中的数字我们并不关心,他可以替换成其他的数字都是可以的。然后准备词汇表, V o p V_{op} Vop表示操作符,±*/, V c o n V_{con} Vcon常数词汇表, π \pi π这些不会出现在text中的常量。 n p n_p np文本变量,比如上述题目的变量6,23,25。这三个词汇表共同组成 V d e c V^{dec} Vdec;另外,还需要对文本的word做编码。
设计树的结构: 每一个节点由三部分组成,目标向量goal vector
q
r
q_r
qr,token
y
y
y,subtree embedding
t
t
t,目标向量是用于生成token,token是用来确定是否要继续向下分解,embedding等会再提。

具体规则如上图。1.通过目标
q
0
q_0
q0预测出目标
q
1
q_1
q1,左子树比较特殊,只需要parent节点信息(当然还需要点上下文);在预测右子树的信息时需要parent和左子树的信息。论文中的解释是由于左子树构建的时候右子树没有构建好,所以理所应当用不着,但是右子树构建的时候左子树就已经构建好了,为了更完全的利用信息所以构建右子树的时候需要利用左子树的信息。但我个人觉得把,由于除法和减法是有顺序性的,这就说明两边的数字有时序关系,利用上左子树的信息可以帮助学习到这些时序信息。
Root Goal Generation
首先要做的是根节点的生成,文本信息自然要做编码。problem text通过一个双向的门单元GRU得到一系列的
h
i
s
h_i^s
his隐藏状态。那么Root Goal自然就是forward sequence的最后一个和backward sequence的第一个相加了。
h
s
→
=
G
R
U
(
h
s
−
1
→
,
x
s
)
h_s^\rightarrow = GRU(h_{s-1}^\rightarrow,x_s)
hs→=GRU(hs−1→,xs) forward的隐状态的参数是上一个隐状态和当前字符的embedding
x
i
x_i
xi。
Root Goal就是隐状态相加。
q
0
=
h
n
→
+
h
0
←
q_0 = h_n^\rightarrow + h_0^\leftarrow
q0=hn→+h0←
Token Prediction
接下来就是Token的预测,Token的预测还需要上下文的信息。上面已经分别求得forward和backward的隐向量的信息
h
s
→
,
h
s
←
h_s^\rightarrow,h_s^\leftarrow
hs→,hs←。
h
s
=
h
s
→
+
h
s
←
h_s = h_s^\rightarrow + h_s^\leftarrow
hs=hs→+hs←
c
=
∑
s
a
s
h
s
c = \sum_s a_s h_s
c=s∑ashs

a
s
a_s
as是一个注意力向量。这样就得到了context
c
c
c。
e
(
y
∣
P
)
e(y|P)
e(y∣P)是针对问题P下,token y的embedding。比如上述这个问题中词汇表
V
d
e
c
V^{dec}
Vdec一共有[=,-,*,\,6,23,25,
π
\pi
π]这几个token,我们通过一个一个embedding可以将这些token映射成向量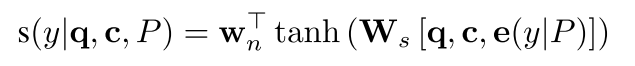
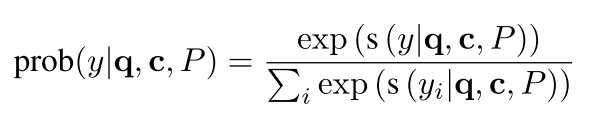

如果最后y是一个操作符,那么意味着就需要分解,如果y是一个数字,那么他就是一个叶子,到此为止。
Left Tree

y
^
\hat{y}
y^是parent预测出的操作符,剩下的按照公式即可。之前没怎么看过NLP这些门的网络,我也不太明白这些公式的来历。
Right Tree

right tree的做法和left tree差不多,只不过是加上了tree embedding。Tree embedding也很简单

如果token是操作符,那说明这是一个节点,需要结合左右子树,如果是字符,那么说是一个叶子节点,直接取数值embedding即可。
Training
极大似然估计训练:
J
=
∑
−
l
o
g
p
(
T
∣
P
)
=
∑
∏
t
=
1
m
p
r
o
b
(
y
t
∣
q
t
,
c
t
,
P
)
J = \sum -log p(T|P) = \sum\prod_{t=1}^m prob(y_t|q_t,c_t,P)
J=∑−logp(T∣P)=∑t=1∏mprob(yt∣qt,ct,P)
流程解释
首先要对问题做编码,先通过某种embedding的方法对文本的token做embedding,然后经过GRU生成隐藏状态,这些状态可以看成是上下文信息。利用隐状态生成根目标向量,根目标向量结合上下文信息就生成了token y,y的总数量是更具不同的问题而改变的,比如前面baggies的problem就是[=,-,*,\,6,23,25, π \pi π],会计算这8个符号的概率,取最大的作为token。如果是操作符,继续分解,如果是符号,那么就到此为止了。
左子树的生成和根节点是不一样的,但是上下文信息还是一样。右子树的生成需要带上左子树的信息,以此类推。树的生成过程是一个先序遍历的过程,每当到达了左边的左子树叶子,就生成subtree embedding,subtree embedding会用于右子树的生成。
Experiment
实验在Math23k上进行,对比实验


在大型数据集上取得的效果比当前SOTA要好,在小数据集上AllArith,seq2seq达到66.5%,而GTS达到69.5%。
Conclusion
这篇文章的动机主要还是来源于人类的目标驱动机制,为expression tree赋予了一个合理化解释。能够发在IJCAI上主要还是提出这种生成树的方法比较新颖,对比的DL模型也都是一步到位生成表达式。但其实个人觉得,文章并没有做到前面Figure 1展现的那样有较高的可解释性,主要的推理还是嵌入embedding里面

我初看这图还以为他能把操作符数字和文本对应起来,然后发现他把推理都embedding进了神经网络里面。其次,对比的方法应该和生成树的表达式方法对比,因为seq2seq model和GTS的生成方法根本不同,除了结果之外没有什么可比性。
这篇文章的idea我觉得非常有创新,虽然他的目标分解没有解释性,都是隐含在了神经网络的参数里面,但是通过目标构建的方法神经网络很可能和会把符号和text关联在一起,提高了problem text和equation的关联精细度。以往的seq2seq都是生成整一个equation,是整一个文本和equation的关联,这里是文本句子和equation中等式符号的关联,个人觉得关联性提高了,如果能在解释性上做出改进就更好了。















 2311
2311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









