







Abstract
Bert是对纯文本做的预处理语言模型,而现有的很多数据集是半结构化的,如表格等等。所以文章提出了TaBert模型,这个模型能够学习如何表达文本语句和半结构化的表格。并在WikiTableQuestion和Spider上取得良好的效果。
Introduction
目前已经出现了一些基于大规模数据预训练的语言模型Bert了,但是对于一些结构化的数据,我们没办法用预训练语言模型,比如基于数据库的QA问题,这种场景下最重要的还是理解表格,将表格的内容和question中的实体相对应。解决这种带半结构化数据的semantic parse问题有三个难点,有一部分信息是存储在表格里面的,目前的一些语言模型BERT没办法对表格encoding。其次这些表格可能带有很多的行列,特别是SQL语句中的表格行列可能包含很多,如果全部编码可能会带来内存上的负担。而且这类任务的utterance和table会有很大的联系,还需要注意将表格和语句联系在一起。 文章提出的Tabert也是为了解决这些问题,同时提出了content snapshots技术,提出出最相关的行列做encoding。
Our key insight is that although semantic parsers are highly domain-specific, most systems rely on representa- tions of input utterances and the table schemas to facilitate subsequent generation of DB queries, and these representations can be provided by TABERT, regardless of the domain of the parsing task
作者认为可以将Tabert做为一种通用性的encoder,在SPIDER任务上预训练,然后再Tabert任务上使用。他们觉得这种原因是大多数的系统都是依赖这种输入输出的形式来促进查询,但其实这种说法不太准确,文章中提到semi-structured semantic parser是domain-specific的,一种特定领域的,但是就WikiTableQuestion来看,表格和question涉及到了方方面面,体育国家政治各个方面,我觉得这个才是能够泛化通用的原因,因为很多semi-structured semantic parser的数据集涉及到的知识范围太广。
Background
semantic parser的任务分为很多种的,有将语句parsing成特定逻辑形式的,比如CS224上讲的一些解析器,对语句做句法句法分析,提取出关键信息。或者是结合database将statement解析成SQL,这种属于结构化数据。还有半结构化的数据,普通的表格。
Masked Language Models
这段主要是介绍Bert,Bert是将一段文本中的某一个词去了,利用语言模型对去掉词语的位置预测,在大规模的语料库下完成这个任务。
Tabert
给定语句utterance u和表格table T,我们需要根据表格和语句预测出相应的logic form。Tabert首先是创建content snapshot。 snapshot是选择在表格中和输入语句最相关的行,然后把所有相关的行线性化,每一行都和question拼接在一起形成新的字符串,然后输入transformer,然后按行输出向量。然后这些输出的编码全部输入到vertical self- attention layers中去,最后从pooling layer中输出即可。讲道理我单看他这个也没太看明白。
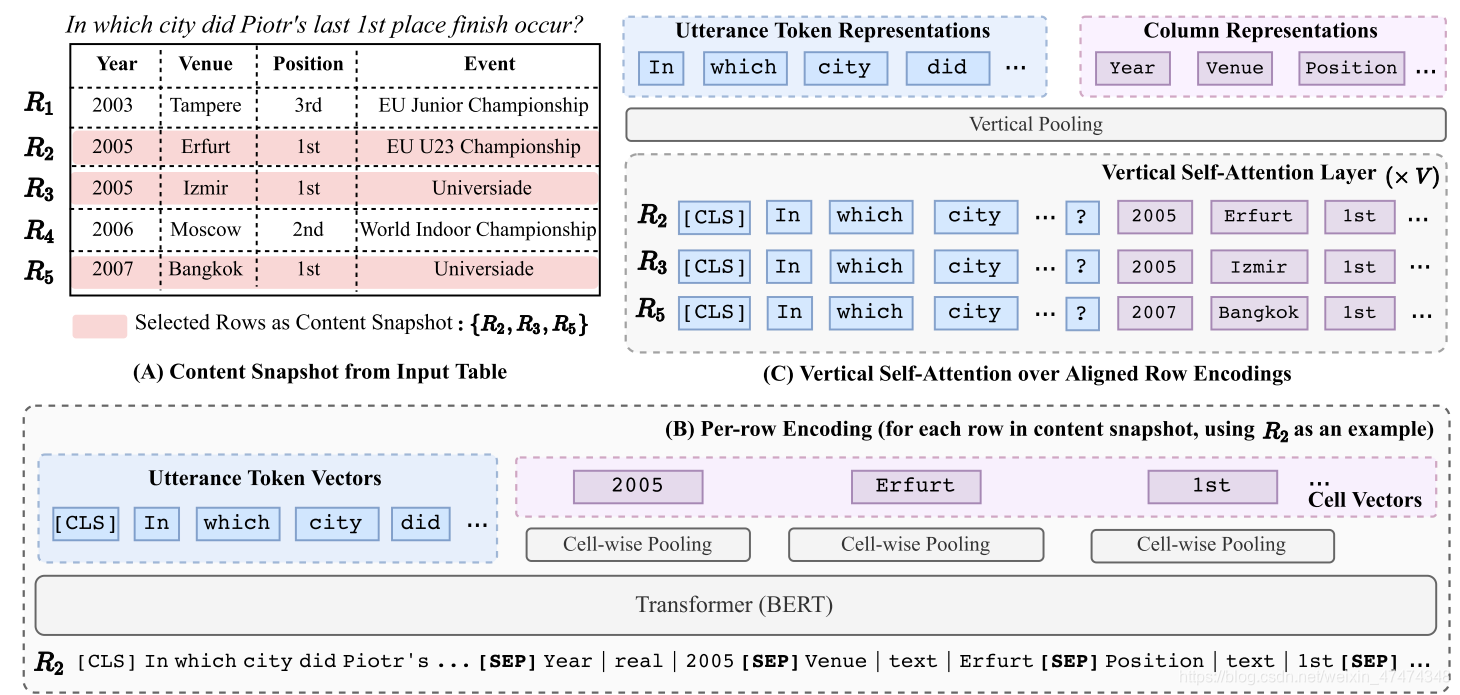
这个图是从下到上看,之前一直上往下没看懂。
Content Snapshot
这项技术有两个创新的点,第一个点是不但用上了列名,还用上了行名,但是这不是很正常的吗?文章说表格内容包含的信息比列名要多,然后这是他的motivation?另外文章还提到DB的表格行列很多,如果全部做encoding会造成资源的负担,所以只寻找几行做encoding。这也是motivation之一。
model使用了一些策略选择最相关的行,选择和utterance有n-gram重叠率最高的行。当k=1的时候,这说明只有一行是最相关的,但是很多情况下,输出的答案是和很多行相关的,如果只有一行相关那么可能不太准确,这个时候就找和最相关的这行最相关的其他行,这样选择出snapshot。
Row Linearization
线性化比较简单。

Vertical Self-Attention Mechanism
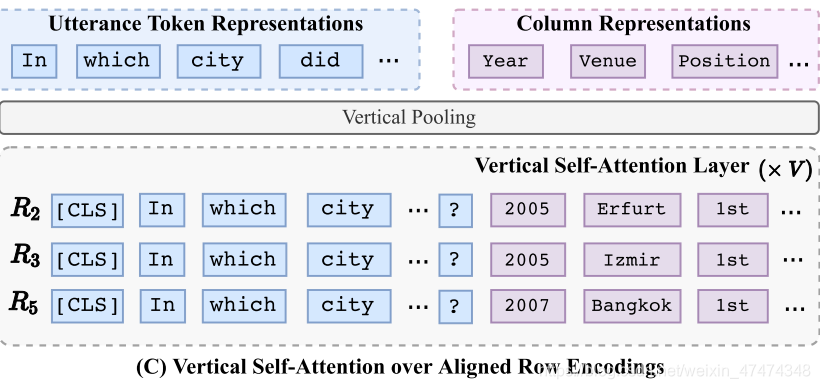
经过Bert后输出的行表达是独立的,因为都是一个一个的输出,但是很多情况下行与行之间是有联系的,所以使用vertical self-Attention引入各个行之间的联系。
Utterance and Column Representations
column的表达是通过对将经过vertical self-attention layer的vector做一个mean pooling的组合得到。utterance的表达是也是相似的计算。
PreTraining
这篇文章出来的时候海没有大规模的半结构化数据的语料,所以文章是使用网上存在的一些表格最为替代的数据。首先从Wikipedia和WDC收集表格和相关的语句,一共包含2660w个样例。对于utterance的表达训练我们使用标准的Masked Language Modeling objective训练。 作者认为,一列表达应该包含这一列的概况信息和这一列中与语句相关单元的信息,所以作者提出了Masked Column Prediction,mask掉一些列的名字和数据类型,让程序对表格的名字和数据类型做预测。给定一共列表达,model需要从表达中预测相应的name和type。然后使用Cell Value Recovery目标函数来确保经过vertical self-attention layer后单元内的数据能够保存下来。所以model会根据cell vector,也就是线性化经过Bert后的向量预测value,比如Year real 2005是第二行第一个单元的数据,model会预测2005。
整体的训练主要还是使用类似于Mask的思想,还是采样AE的思想,从破损的数据集中恢复。
Experiments
实验只关注了WikiTableQuestion,MAPO+TaBert比之前高了5.4%,做到52.3%。效果还是很好的,这个数据集比较难,提升5个百分点算很多了,并且在这么多的任务上都超越了sota。
Conclusion
这个Tabert的模型有点像是拼接在一起,很多motivation没有什么例子说明。比如answer和表格的多行有关系,在WikiTableQuestion中,有些只是hop就能查找出答案,不一定是和多行有关系,只有那些count这种函数才会和多行相关。另外,snapshot选择和utterance相关的行没有用到什么特别的选择方式,都是选择overlap最高的行,但实际上有些缩写和全写不能够overlap上的。另外如果没有出现在table中那么查找相关的行会起到相反的作用。
在训练的时候还是沿用的AE的思想,在无监督训练TaBert这段的motivation个人觉得很棒,确实是有助于理解表格,这样学出的vector不但包含了表格列名和类型,单元格的信息也包含了。
而事实上,Bert+MAPO我sample出的很多错误样例是没有结合上表格的,所以还是很大提升空间的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









