







目录
一、python基础

1、tab补全
当在命令行输入表达式时,按下Tab键即可为任意变量(对象、函数等)搜索命名空间,与你目前已输入的字符进行匹配。enter
2、内省
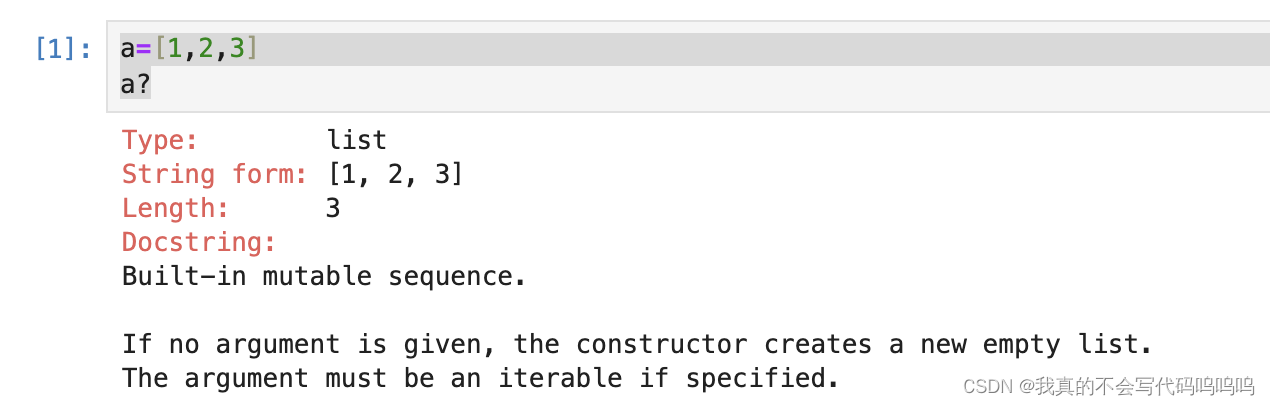
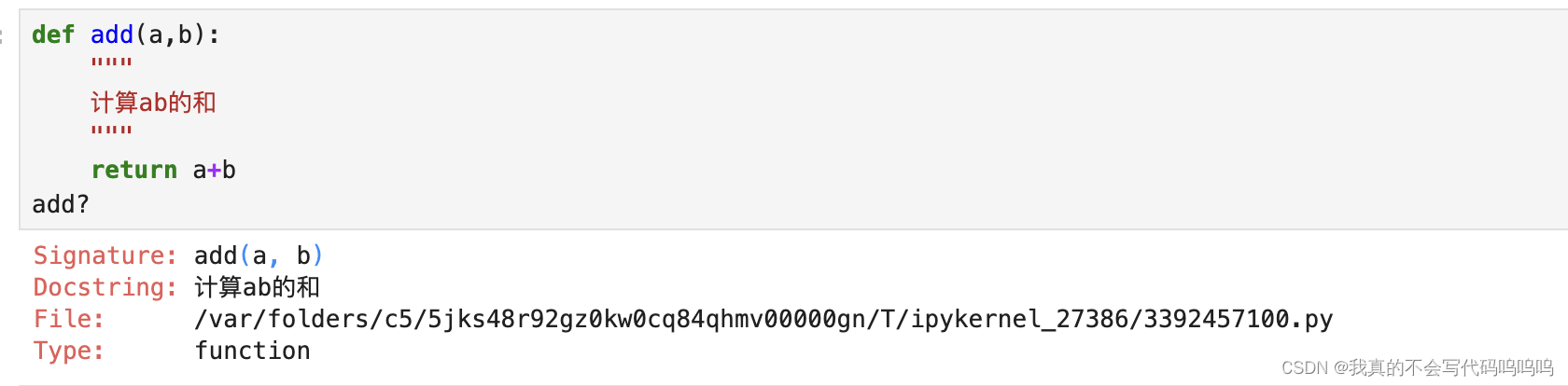
在一个变量名的前后使用问号(?)可以显示一些关于该对象的概要信息
3、分号

4、变量的绑定
将一个变量赋值给另外一个变量,实际指向的是一个地址。
赋值也被称为绑定,这是因为我们将一个变量名绑定到了一个对象上。已被赋值的变量名有时也会被称为被绑定变量。


5、判断对象类型
你可以使用isinstance函数来检查一个对象是否是特定类型的实例。




6、验证对象是否迭代器
验证一个对象如果实现了迭代器协议,那它一定是可以迭代的。对于很多对象来说,它包含了一个__iter__魔术方法,但使用iter函数是一个更好的、独立的方法。

7、is与==
- is:是判断两个变量是否指向相同的对象,也就是指向相同的地址。
- ==:则是比较两者的内容是否相同的。
8、标量
- “单值”类型有时被称为标量类型,我们在本书中称之为标量


9、转换符
你可以在字符串前面加一个前缀符号r,表明这些字符是原生字符

10、三元表达式

二、numpy
 1、生成ndarray
1、生成ndarray

(1)序列型对象转化数组

(2)嵌套等长列表转多维数组

(3)全0数组与全1数组构建
import numpy as np
np.ones()
np.zeros()
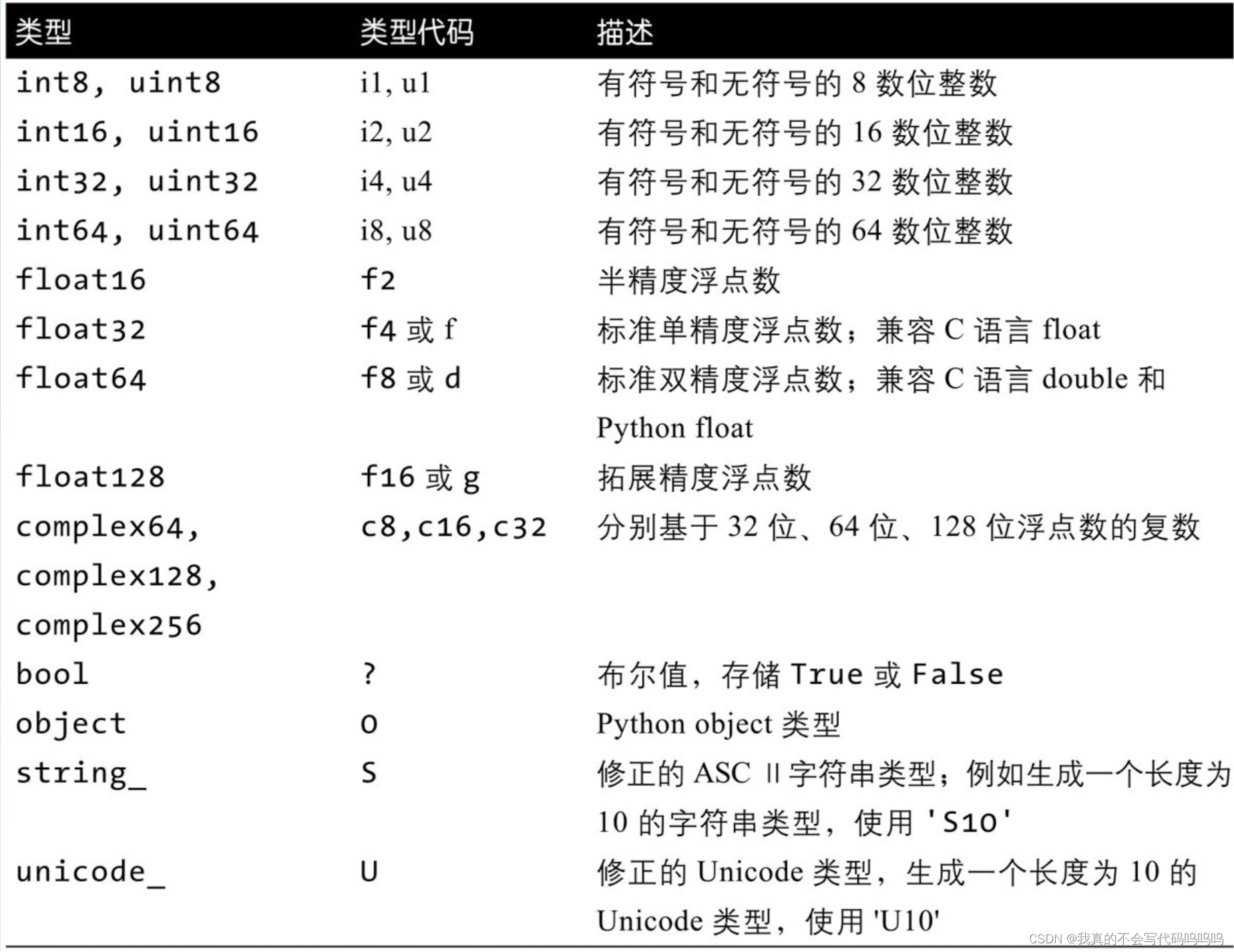
np.arrage()2、数组类型
3、数组类型的转化
astype函数

4、数组的计算

5、数组索引与切片
(1)切片赋值
例如arr[5:8] = 12,数值被传递给了整个切片,整个切换的数值均=12

(2)高维数组索引
一维数组与列表索引类似
在二维数组中,每个索引值对应的元素不再是一个值,而是一个一维数组。


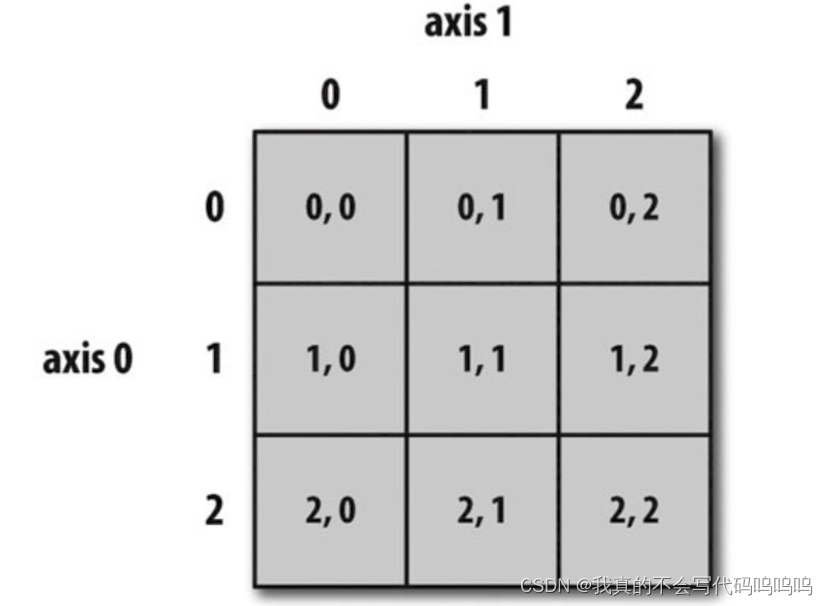
解析
(3)数组多维度切片
整个数组三行三列,分别对应0、1、2行与0、1、2列
- :2代表获取第0、1行
- 1: 代表获取1、2列


(4)数组索引切片混合

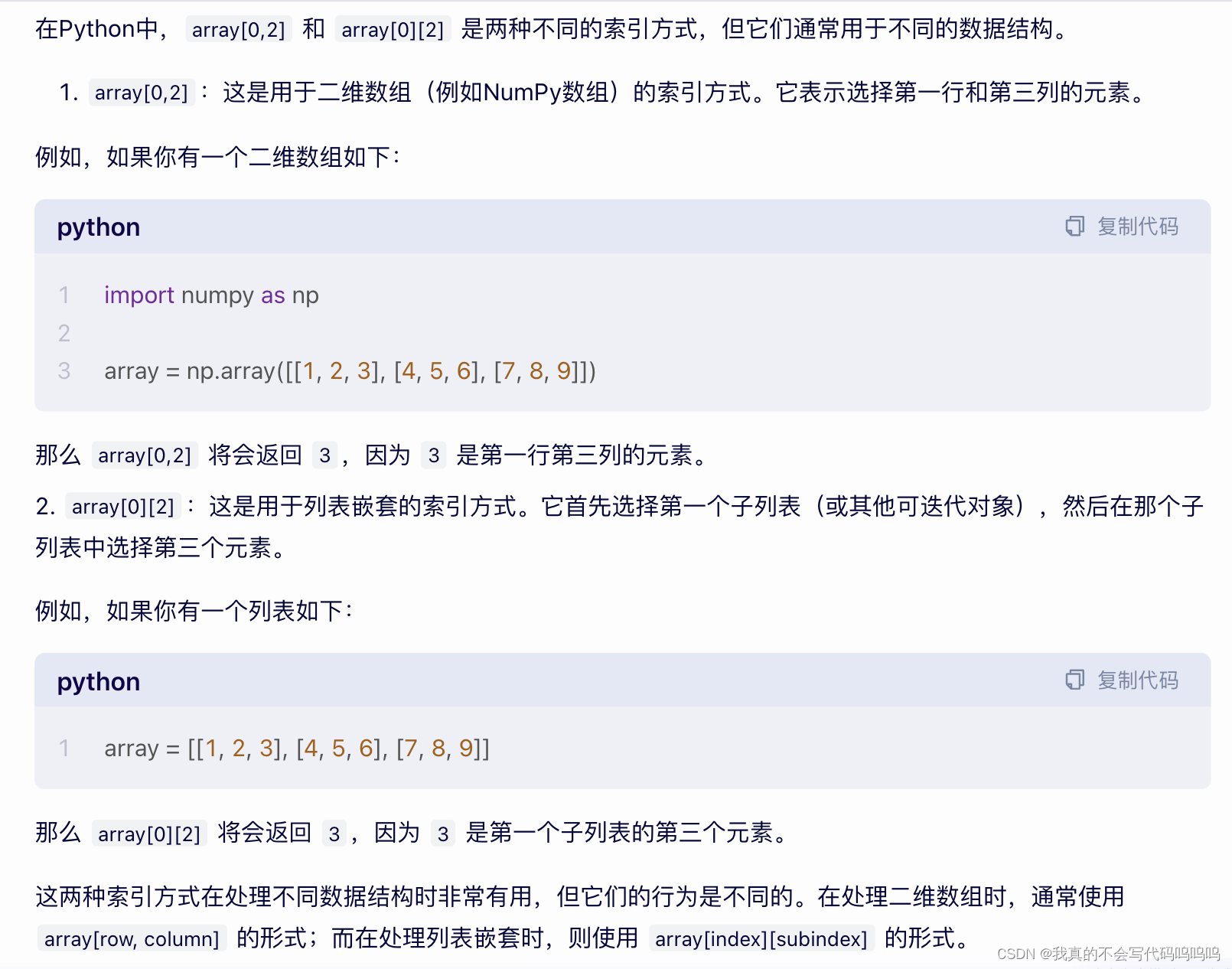
(5)布尔索引

- 数组的比较操作(比如==)可向量化。比较names数组和字符串’Bob’会产生一个布尔值组:

- 在索引数组时可以传入布尔值数组:

- 布尔取反:

- 数学操作符如&(and)和|(or):
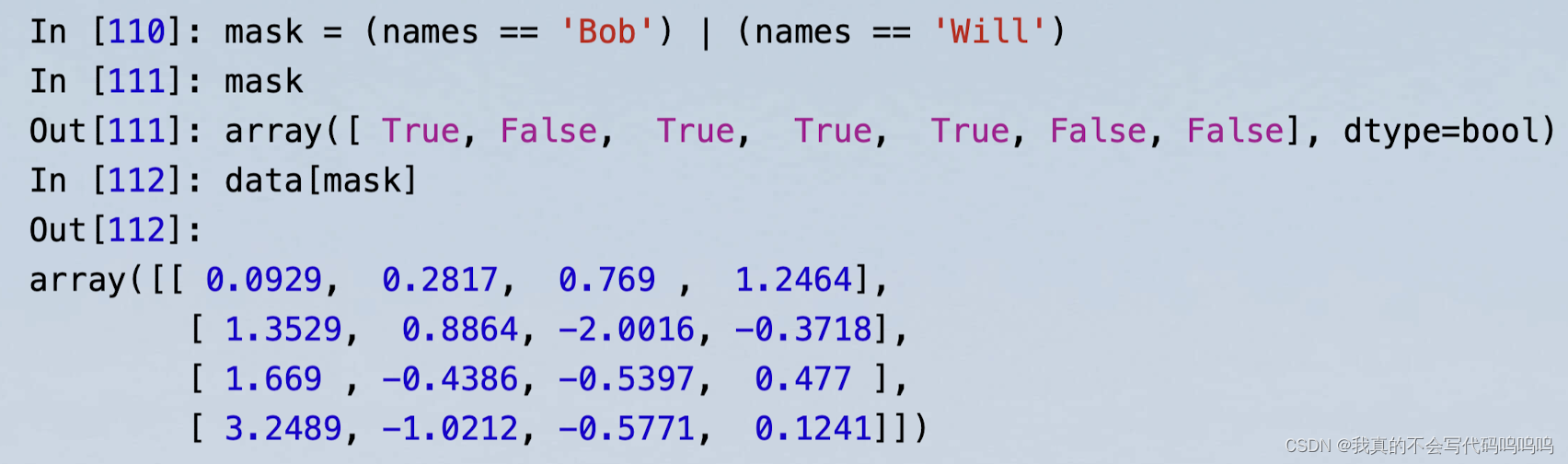
(6)神奇索引
- 神奇索引是NumPy中的术语,用于描述使用整数数组进行数据索引。
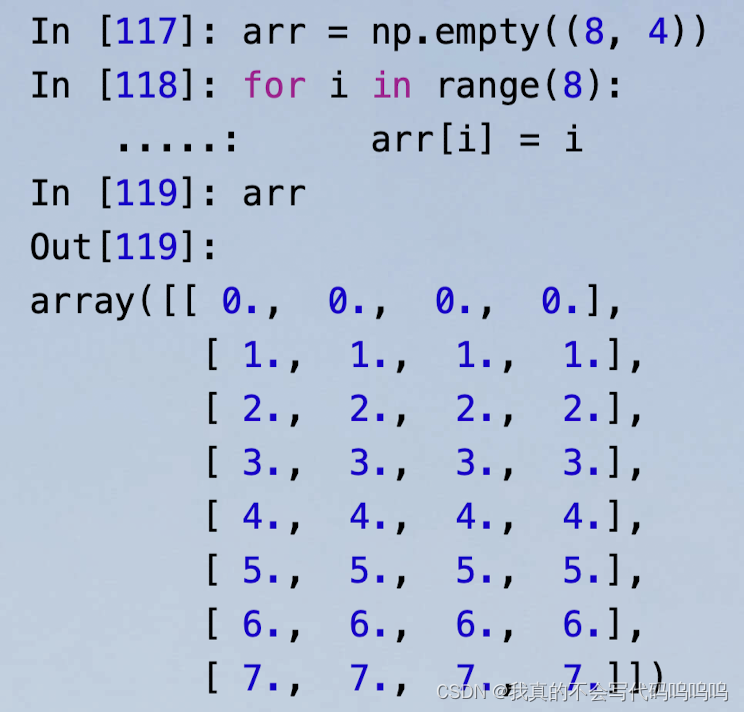
- empty函数:
选出一个符合特定顺序的子集,通过传递一个包含指明所需顺序的列表或数组来完成:
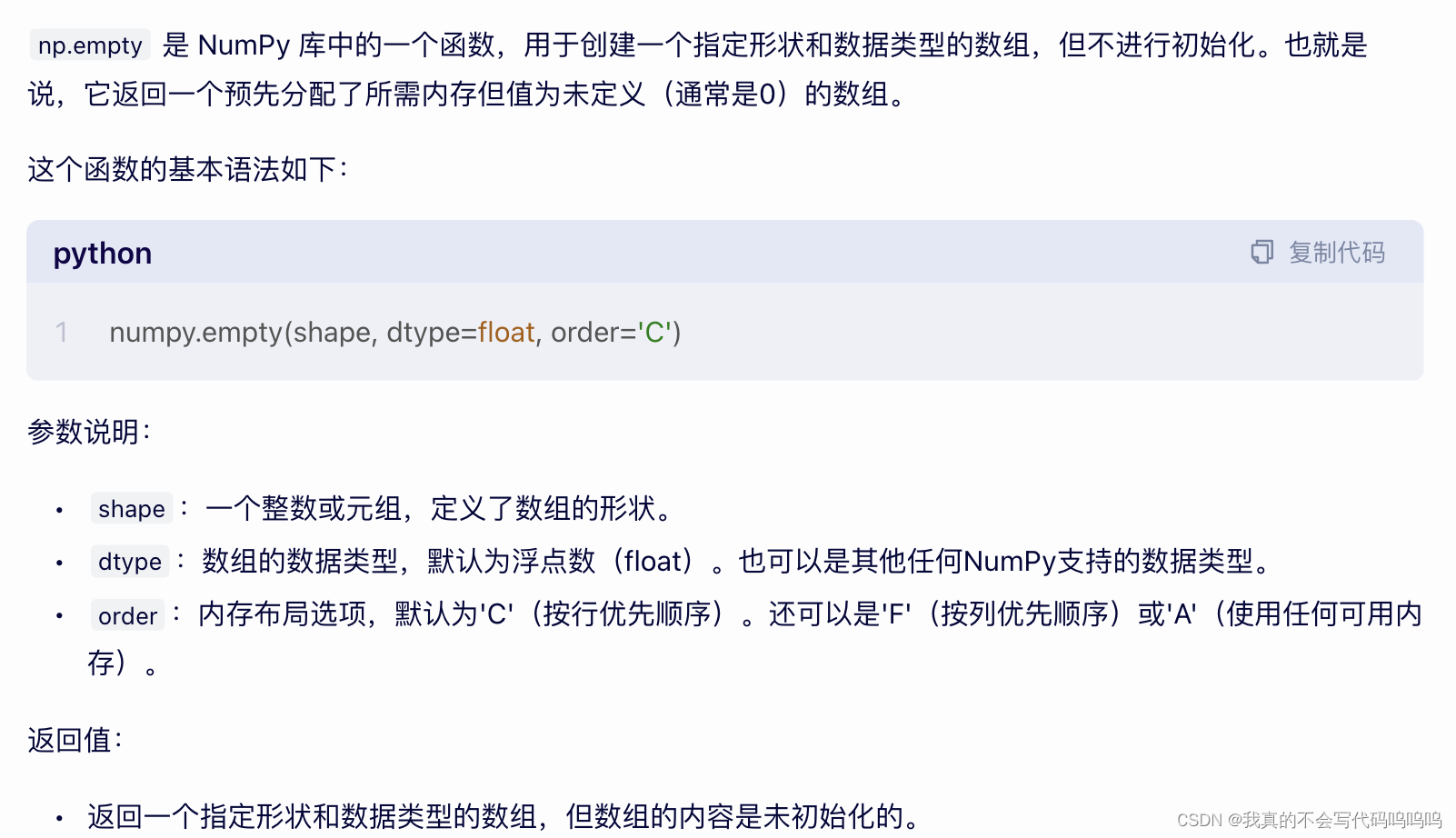
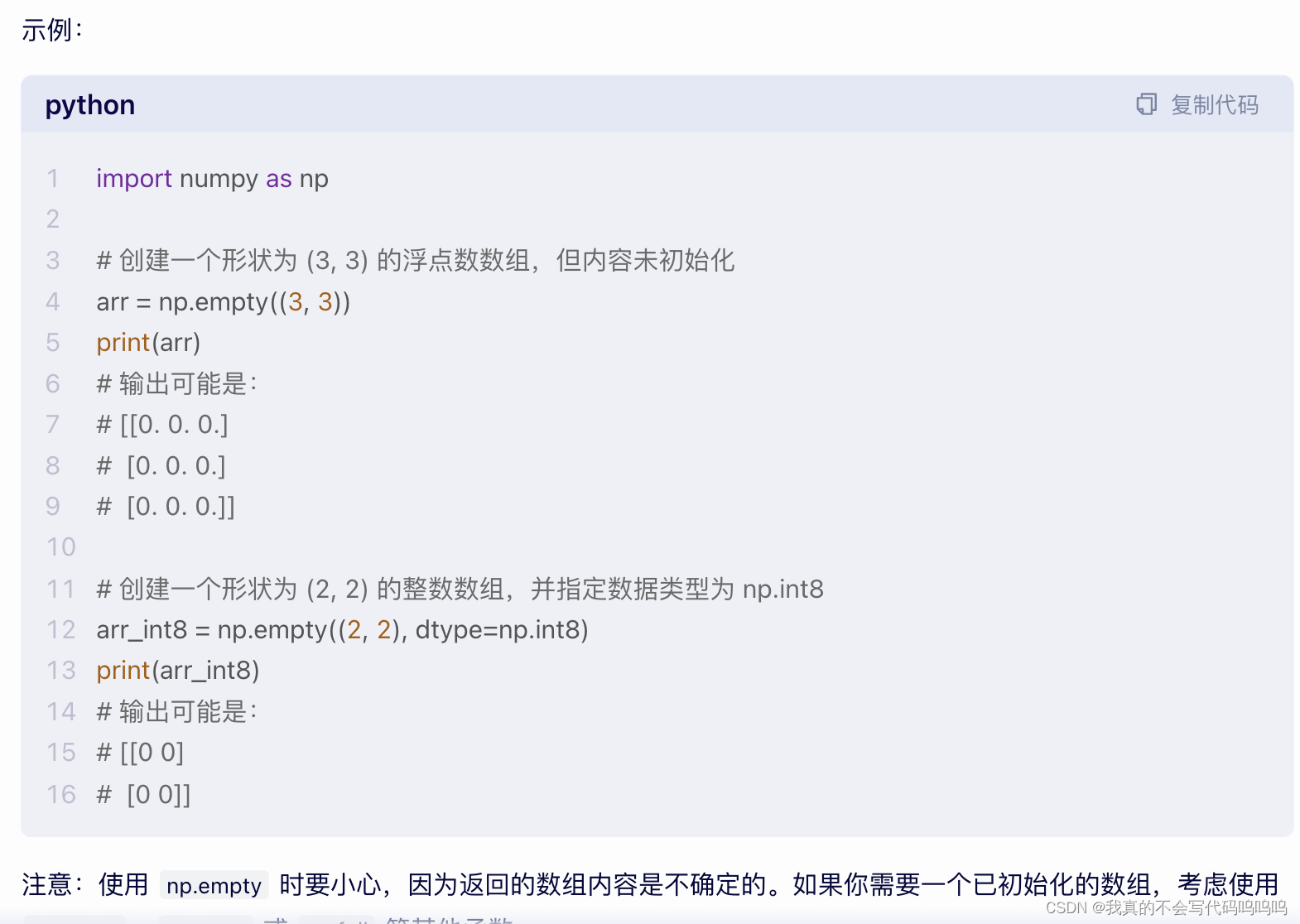
- 传入列表,获取对应的数据行

- 多个索引列表也可以

7、数组转置与换轴
(1)转置T属性

(2)矩阵内积

8、常用函数
语法为np.函数.(数组名...)


9、条件逻辑
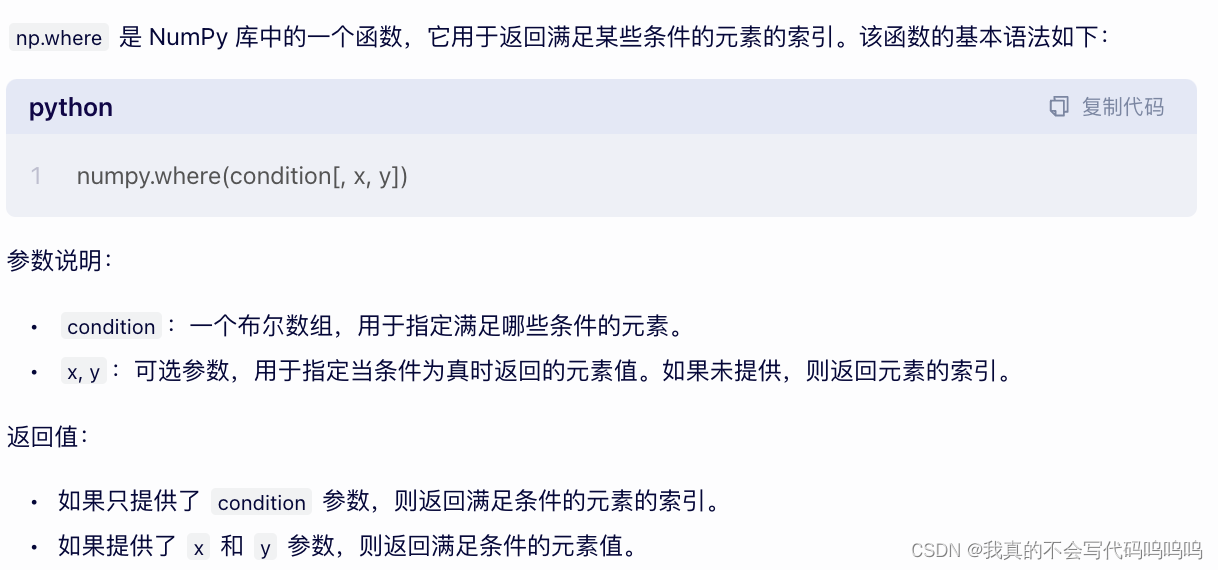
numpy.where函数是三元表达式x if condition else y的向量化版本。
基础数据
 (1)三元表达式
(1)三元表达式

(2)where函数
-
第一个参数为条件,第二三个参数为条件的真假赋值

10、数组统计方法

11、布尔值数组
对于布尔值数组,有两个非常有用的方法any和all。
any检查数组中是否至少有一个True,而all检查是否每个值都是True:

12、数据的集合操作

13、线性代数函数

14、随机数函数

三、pandas
1、series
- Series是一种一维的数组型对象,它包含了一个值序列(与NumPy中的类型相似),并且包含了数据标签,称为索引(index)。
- 默认生成的索引是从0到N-1(N是数据的长度),通过values属性和index属性分别获得Series对象的值和索引:


- 当你把字典传递给Series构造函数时,产生的Series的索引将是排序好的字典键。
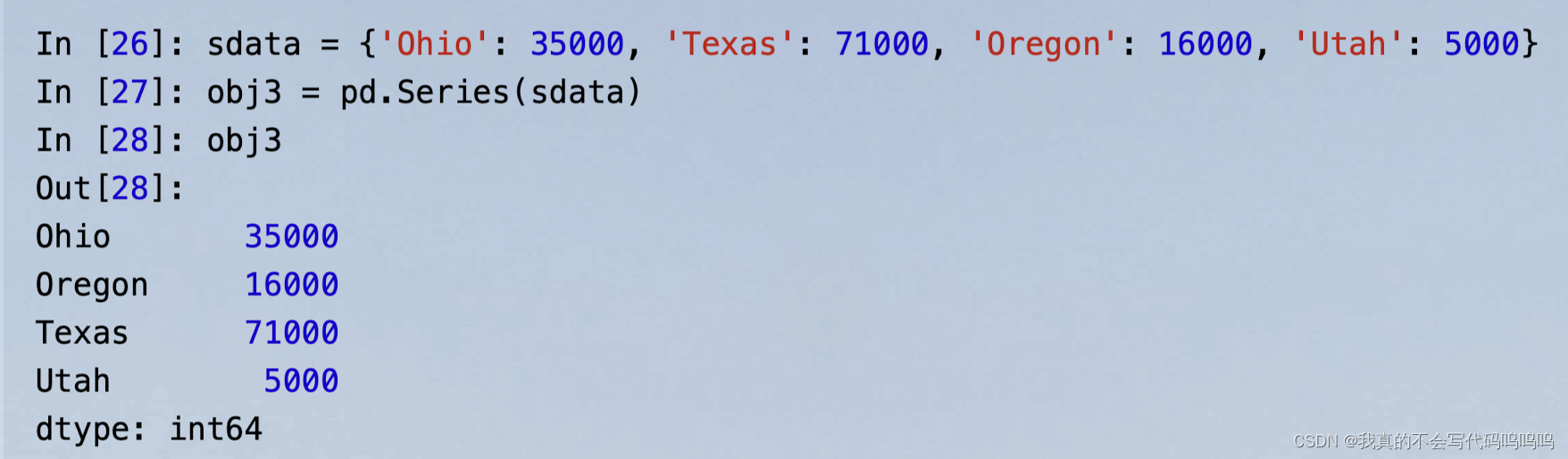
(1)索引
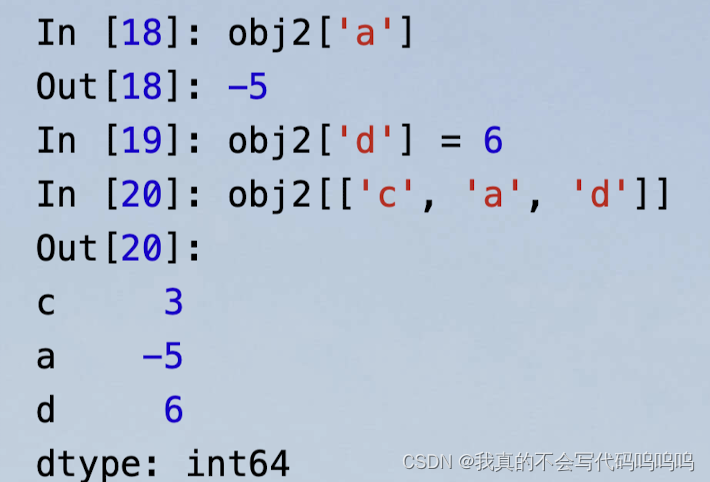
如果传入的索引与字典的key不一致,或者无法完全匹配,value会显示NAN
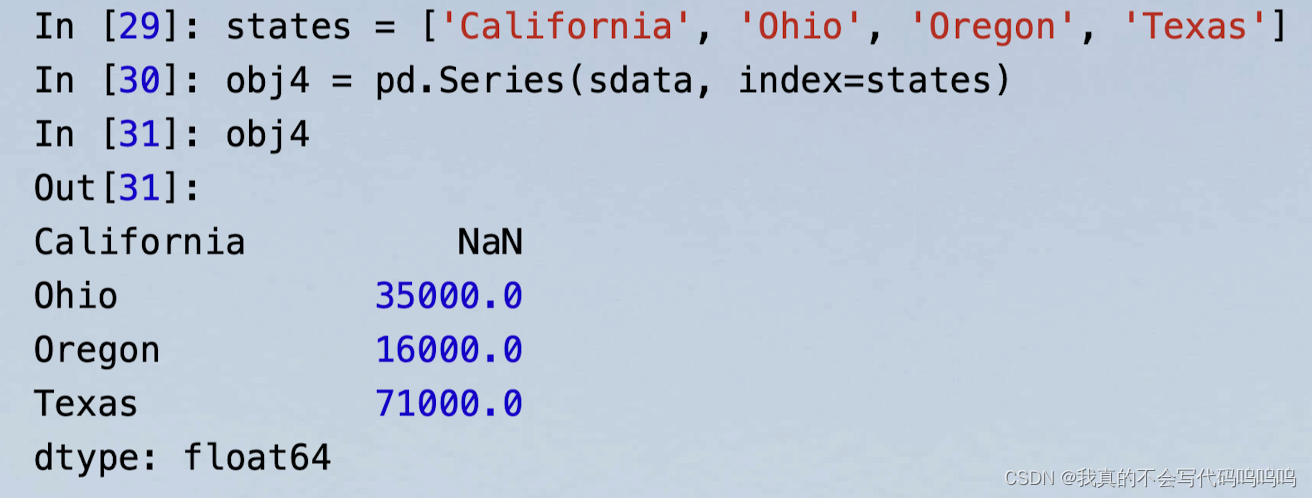
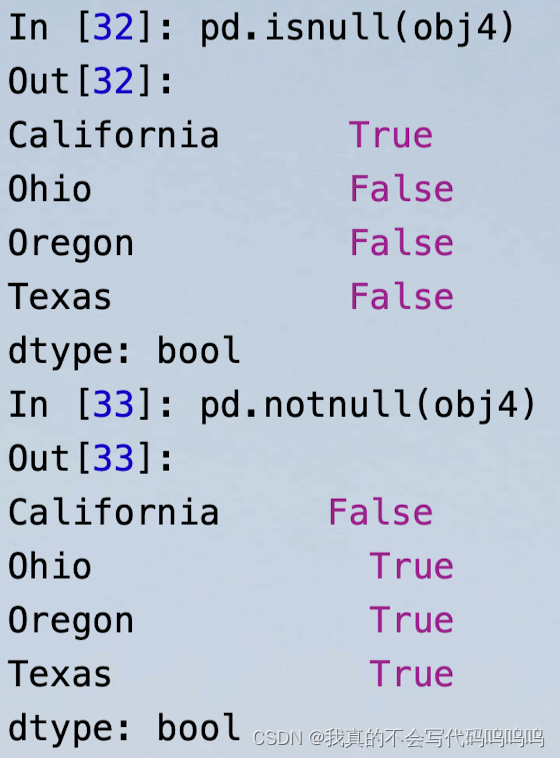
(2)缺失数据检查:
- 使用isnull和notnull函数来检查缺失数据:
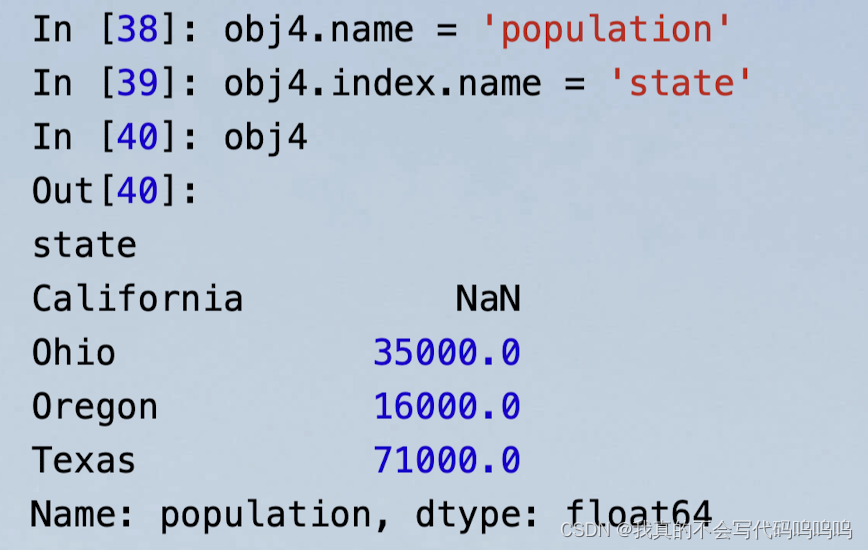
(3)name属性
- Series对象自身和其索引都有name属性
2、DataFrame
每一列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被视为一个共享相同索引的Series的字典
(1)构建DataFrame
- 最常用的方式是利用包含等长度列表或NumPy数组的字典来形成DataFrame:

- DataFrame中的一列,可以按字典型标记或属性那样检索为Series:
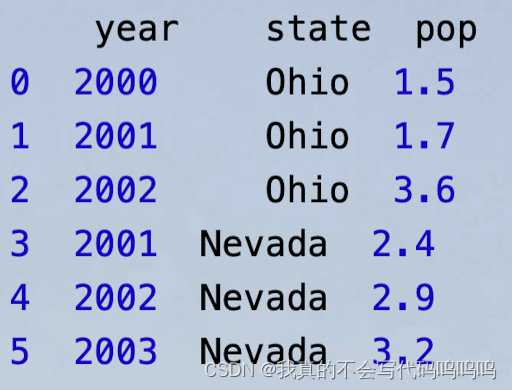
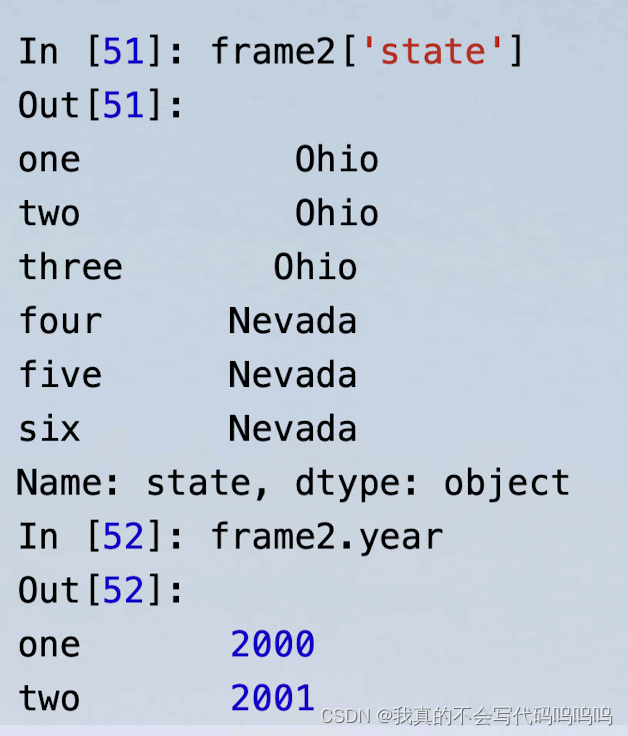
注:frame2[colunm]对于任意列名均有效,如果不存在该列,会自动加一列。但是frame2.column只在列名是有效的Python变量名时有效。
注:dataframe的一列就是series,列名就是series的name。series的index是dataframe的行名
注:当你将列表或数组赋值给一个列时,值的长度必须和DataFrame的长度相匹配。如果你将Series赋值给一列时,Series的索引将会按照DataFrame的索引重新排列,并在空缺的地方填充缺失值: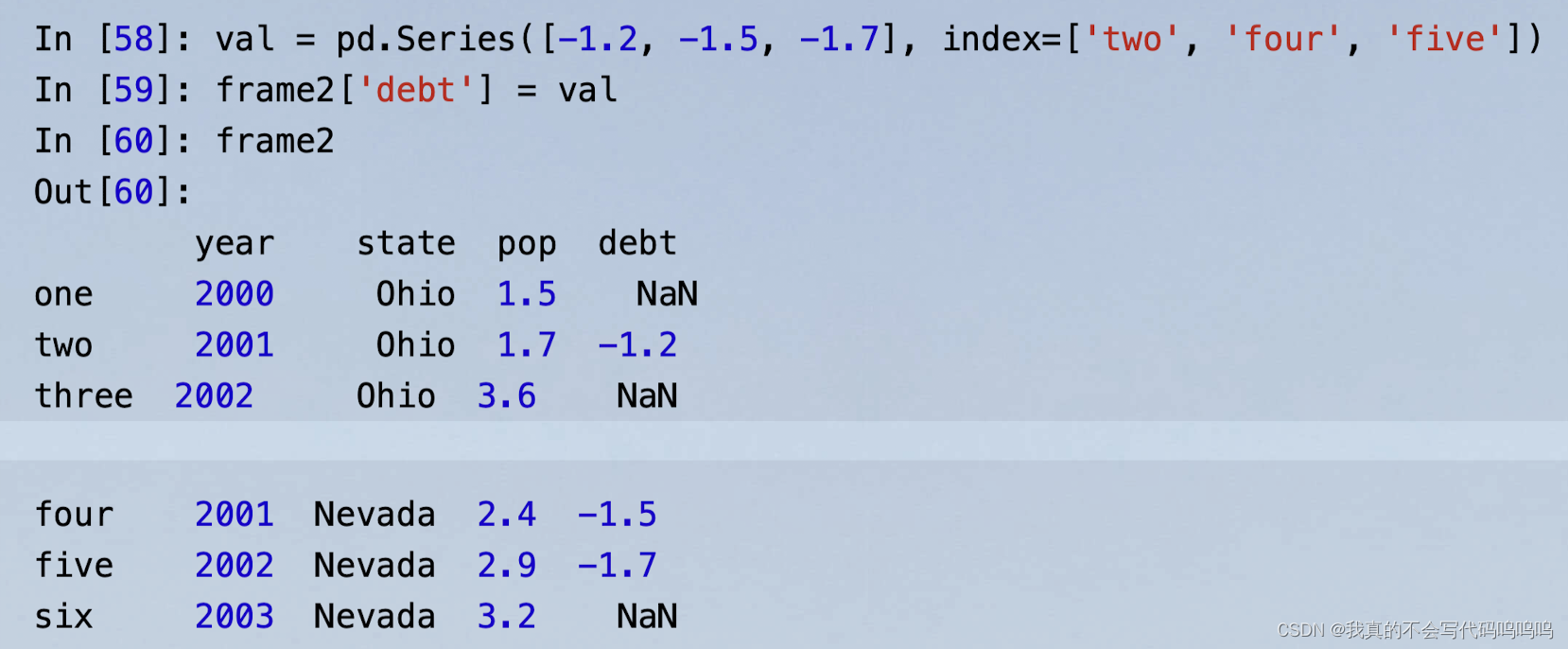
- 嵌套字典:如果嵌套字典被赋值给DataFrame, pandas会将字典的键作为列,将内部字典的键作为行索引:


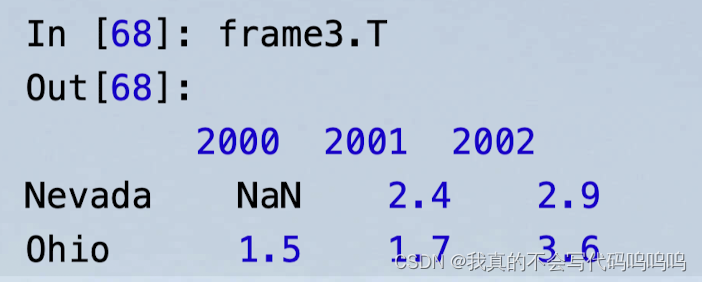
- 可使用类似NumPy的语法对DataFrame进行转置操作(调换行和列):

(2)索引对象
- 索引对象是不可变的,因此用户是无法修改索引对象的
![]()
- 查看索引:x.index x.columns

3、重建索引
(1)Series调用reindex方法时,会将数据按照新的索引进行排列,如果某个索引值之前并不存在,则会引入缺失值:


- method可选参数:允许我们使用诸如ffill等方法在重建索引时插值,ffill方法会将值前向填充
![]()
(2)在DataFrame中,reindex可以改变行索引、列索引,也可以同时改变二者。当仅传入一个序列时,结果中的行会重建索引:
列可以使用columns关键字重建索引:
4、删除条目
- 在调用drop时使用标签序列会根据行标签删除值(轴0)
![]()
- 你可以通过传递axis=1或axis='columns’来从列中删除值:
![]()
![]()
5、使用loc和iloc选择数据
特殊的索引符号loc和iloc。使用轴标签(loc)或整数标签(iloc),以NumPy风格的语法从DataFrame中选出数组的行和列的子集。

- loc:使用索引
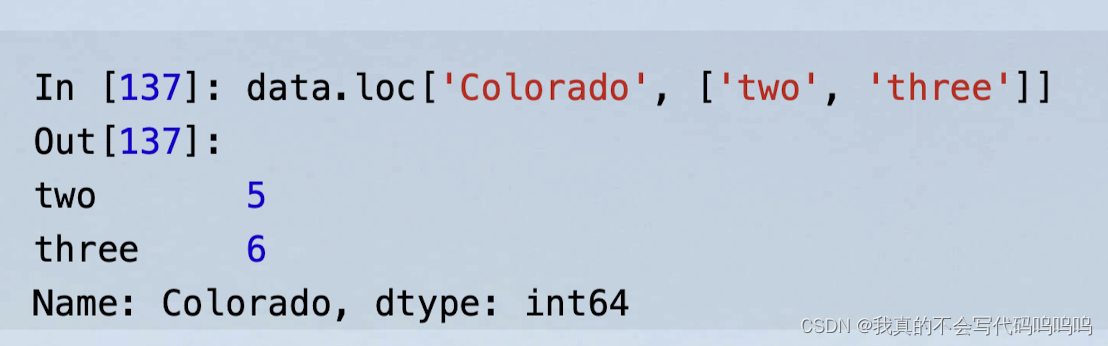
- iloc:使用整数
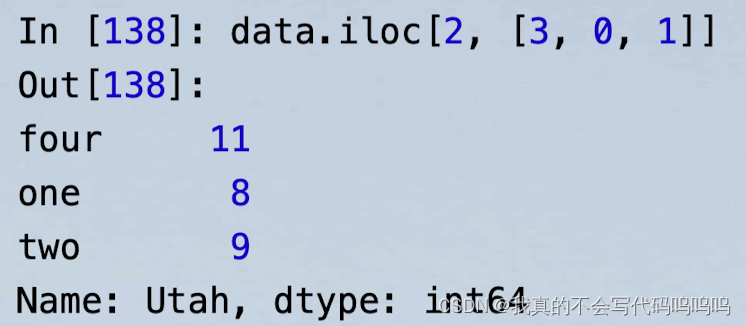
6、索引切片
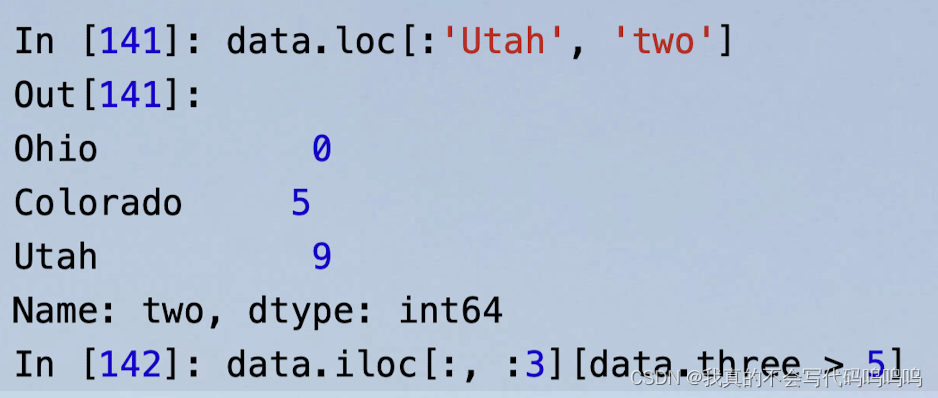
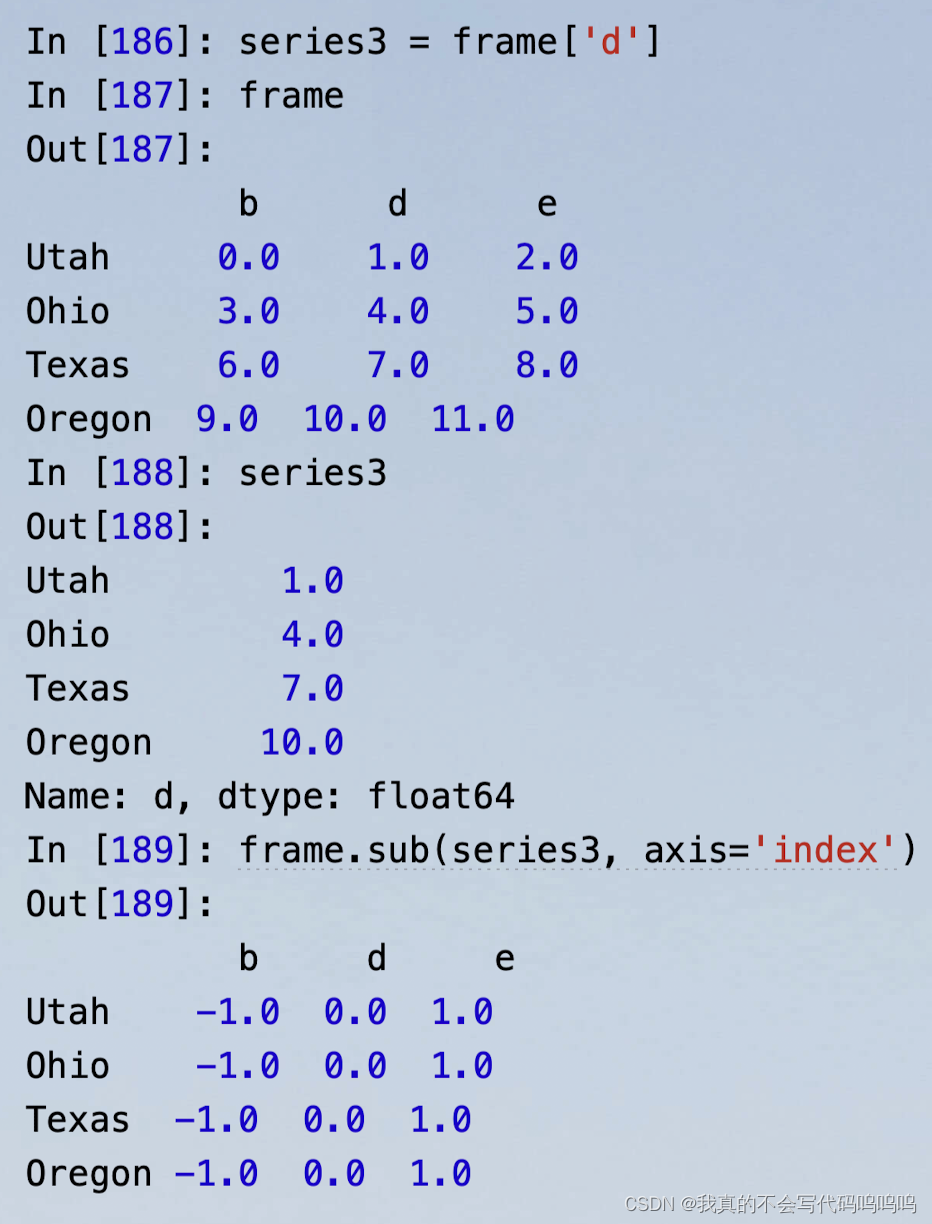
7、使用填充值的算术方法

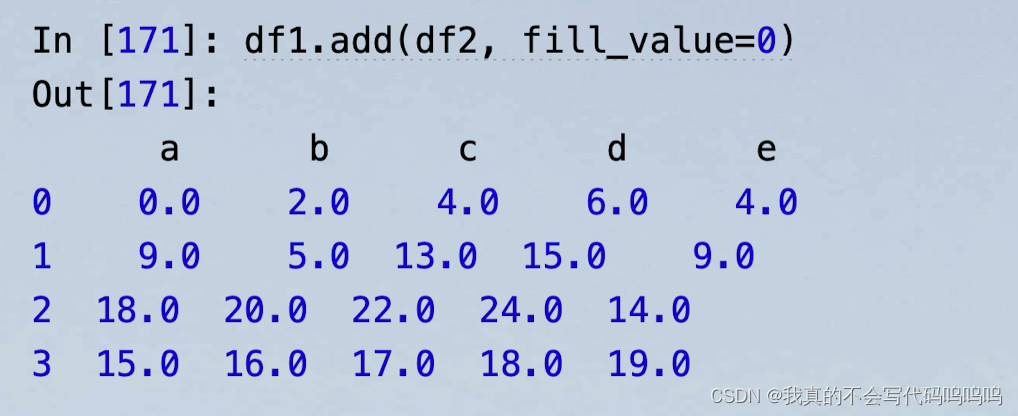
 8、广播机制
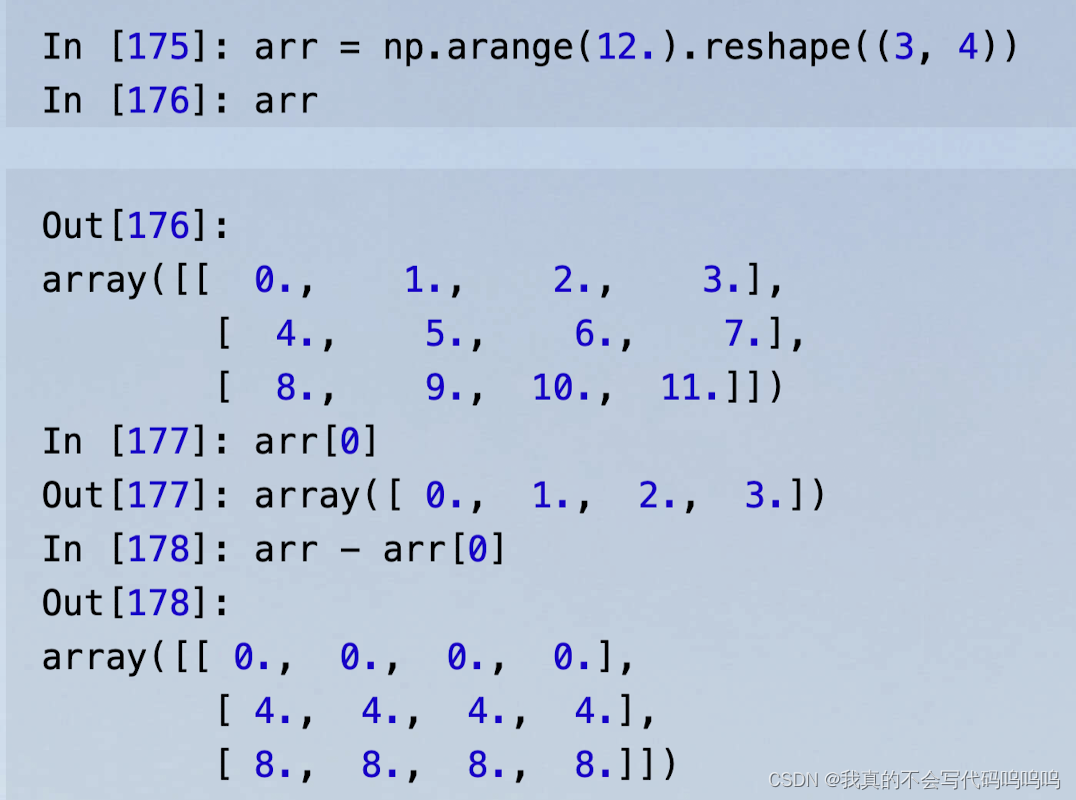
8、广播机制
当我们从arr中减去arr[0]时,减法在每一行都进行了操作。这就是所谓的广播机制,
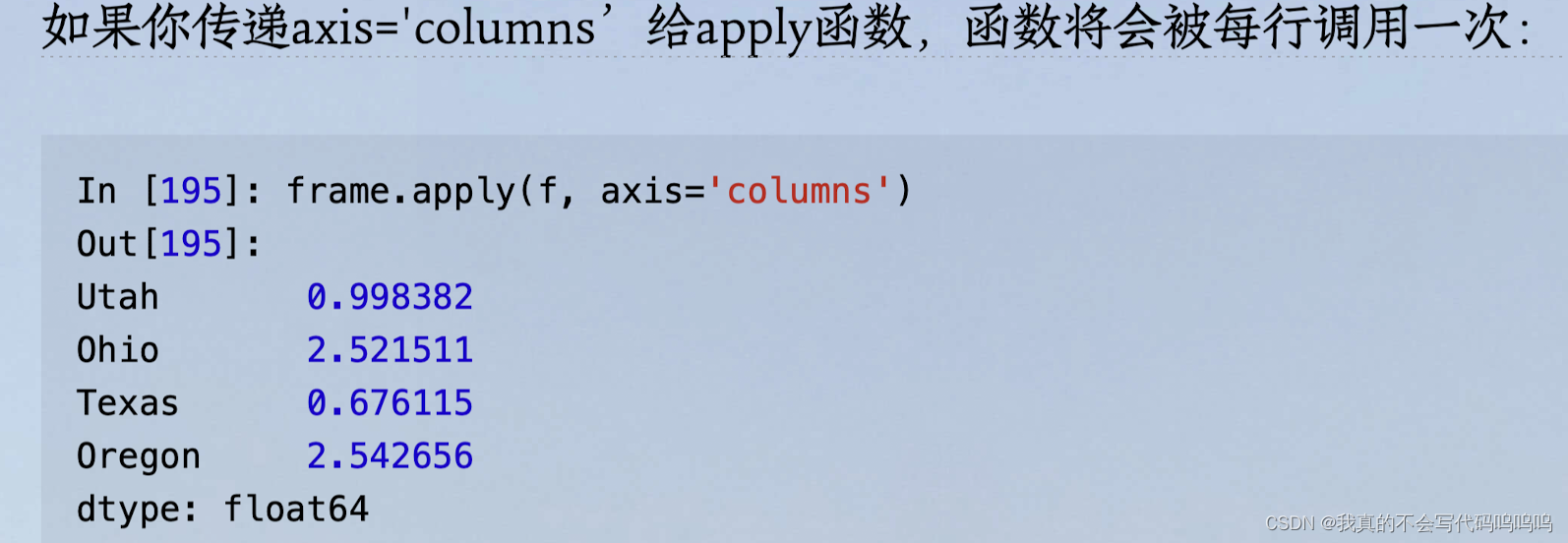
9、函数应用与映射
将函数应用到一行或一列的一维数组上。DataFrame的apply方法可以实现这个功能:
- Series对象 :apply() 方法的返回值是一个新的 Series 对象,其中每个元素都是通过将原始 Series 中的对应元素传递给自定义函数所得到的结果。
- DataFrame 对象:apply() 方法的默认行为是按列操作,如果按行操作,设置 axis 参数为 1。



总结:
apply()将一个函数作用于DataFrame中的行或列;
applymap()则作用于DataFrame中的每一个元素;
- np.nan函数
- 如果两个不等长的df相加,会出现很多NAN值,可使用add方法,和一个fill_value函数:
map()是一个Series的函数,DataFrame结构中无法使用map()。map()则是将函数作用于Series中的每一个元素。
10、排序和排名
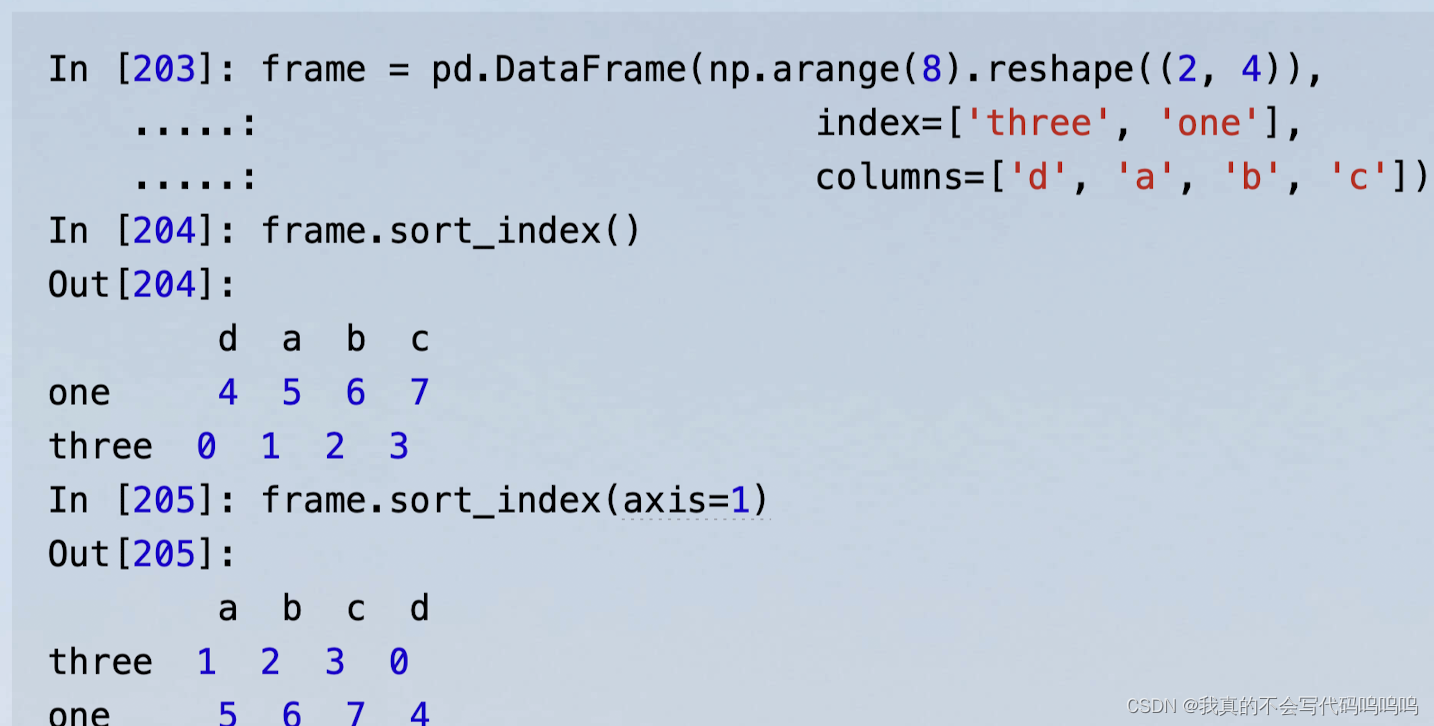
(1)按行列索引字典型排序
- 使用sort_index方法,该方法返回一个新的、排序好的对象。默认是按照行索引进行排序,当指定axis=1按照列索引排序,默认都是升序排序,设置ascending=False降序排列
(2)Series的值排序
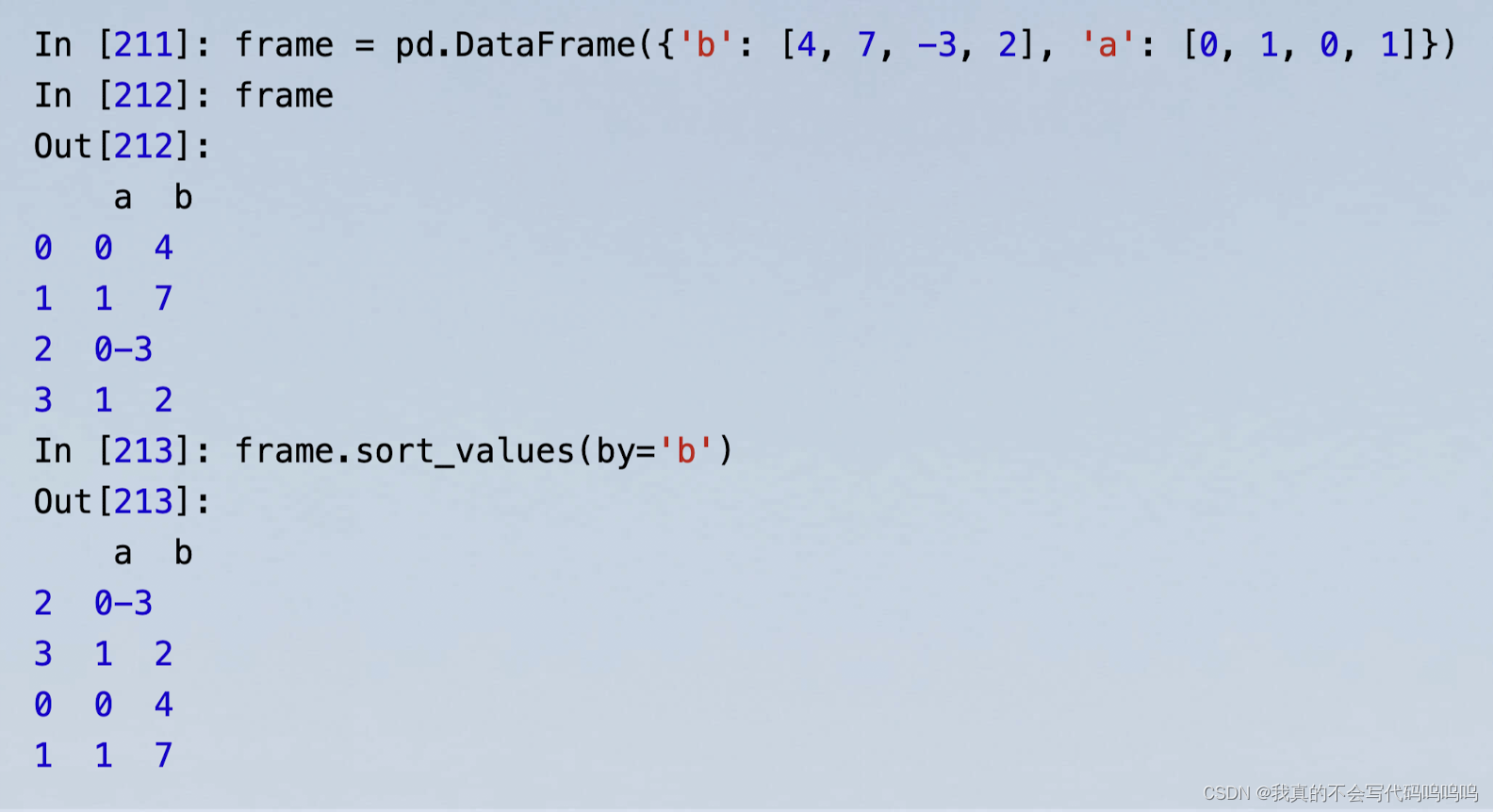
- 使用sort_values方法:默认情况下,所有的缺失值都会被排序至Series的尾部:
- 当对DataFrame排序时,你可以使用一列或多列作为排序键。为了实现这个功能,传递一个或多个列名给sort_values的可选参数by:
![]()

11、标签唯一性
索引的is_unique属性可以告诉你它的标签是否唯一
12、统计描述


13、数值唯一性
- unique,它会给出Series中的唯一值:

- value_counts计算Series包含的值的个数:
















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









