







目录
数据清洗与准备
1、缺失值
(1)Na与NaN
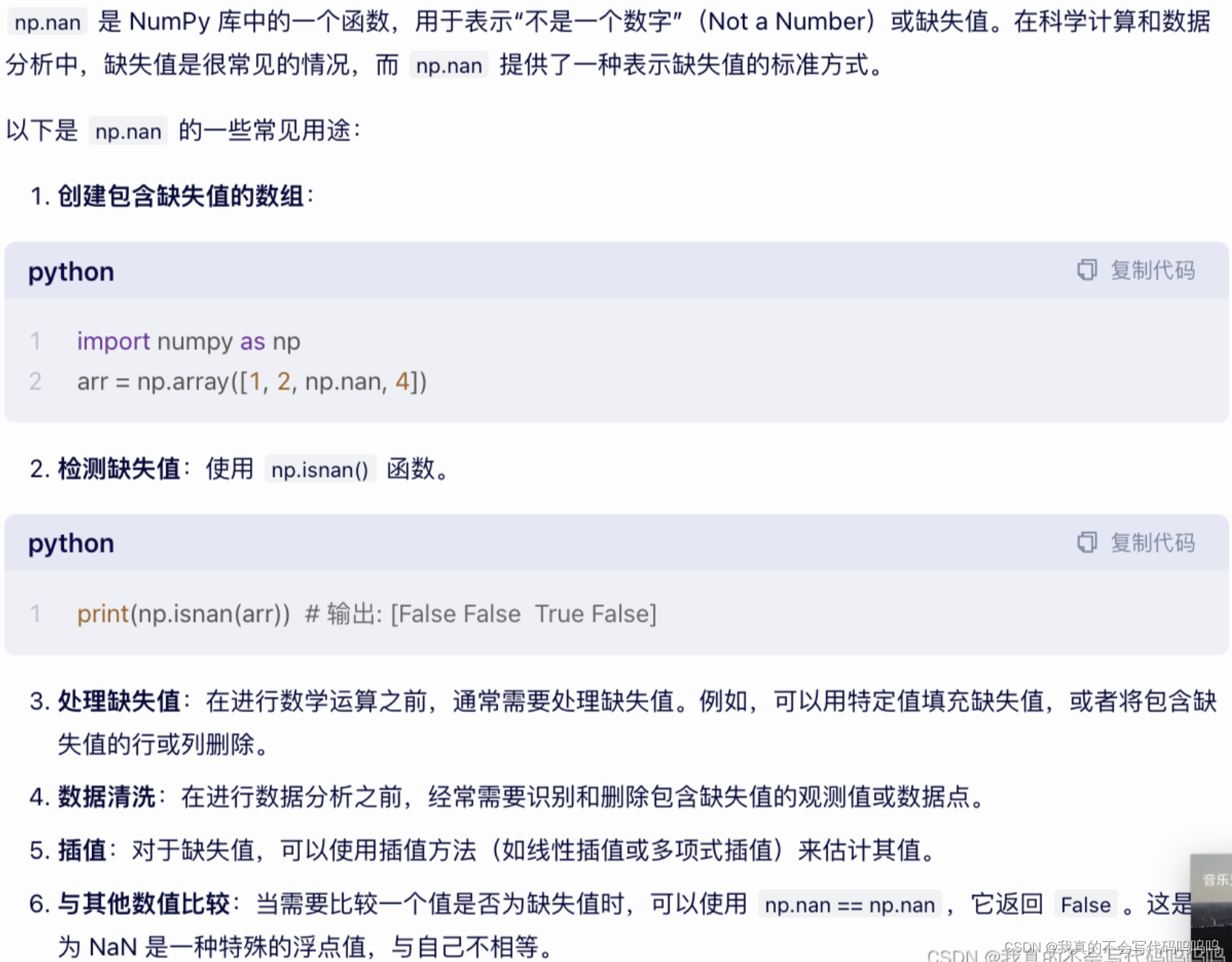
对于数值型数据,pandas使用浮点值NaN(Not a Number来表示缺失值)
Python内建的None值在对象数组中被当作NA处理

(2)np.nan函数
2、缺失值处理

(1)notnull函数

(2)dropna函数
- Series对象:返回Series中所有的非空数据及其索引值

- DataFrame对象:默认情况下会删除包含缺失值的行,传入how='all’时,将删除所有值均为NA的行;
注:如果要用同样的方式去删除列,传入参数axis=1:

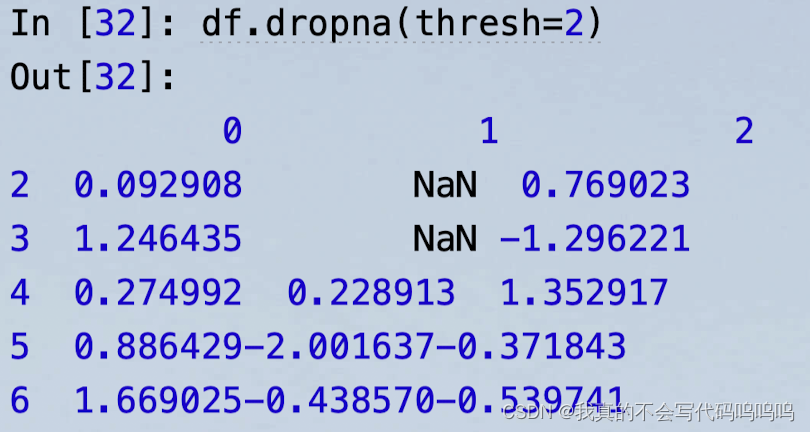
假设你只想保留包含一定数量的观察值的行。你可以用thresh参数来表示:
(3)补全缺失值fillna
fillna方法来补全缺失值。调用fillna时,可以使用一个常数来替代缺失值:
注:method='ffill':将NaN值用上一个值填充,method='backfill'使用下一个值填充上一个NaN值

用0填充
![]()
在调用fillna时使用字典,你可以为不同列设定不同的填充值
![]()
平均数填充

3、数据转换
(1)重复值问题
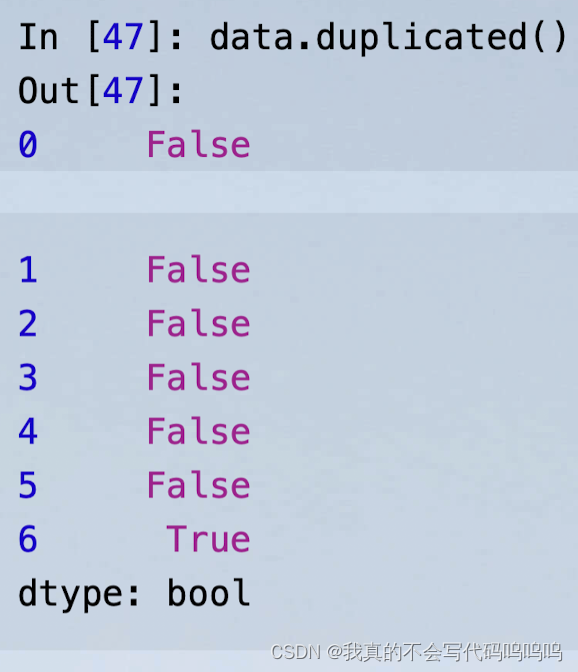
- duplicated方法:返回的是一个布尔值Series,反映的是每一行是否存在重复(与之前出现过的行相同)情况
- drop_duplicates方法:返回的是DataFrame,内容是duplicated返回数组中为False的部分

注:duplicated和drop_duplicates默认都是保留第一个观测到的值。传入参数keep='last’将会保留最后一个
这些方法默认都是对列进行操作。你可以指定数据的任何子集来检测是否有重复。
假设我们有一个额外的列,并想基于’k1’列去除重复值:

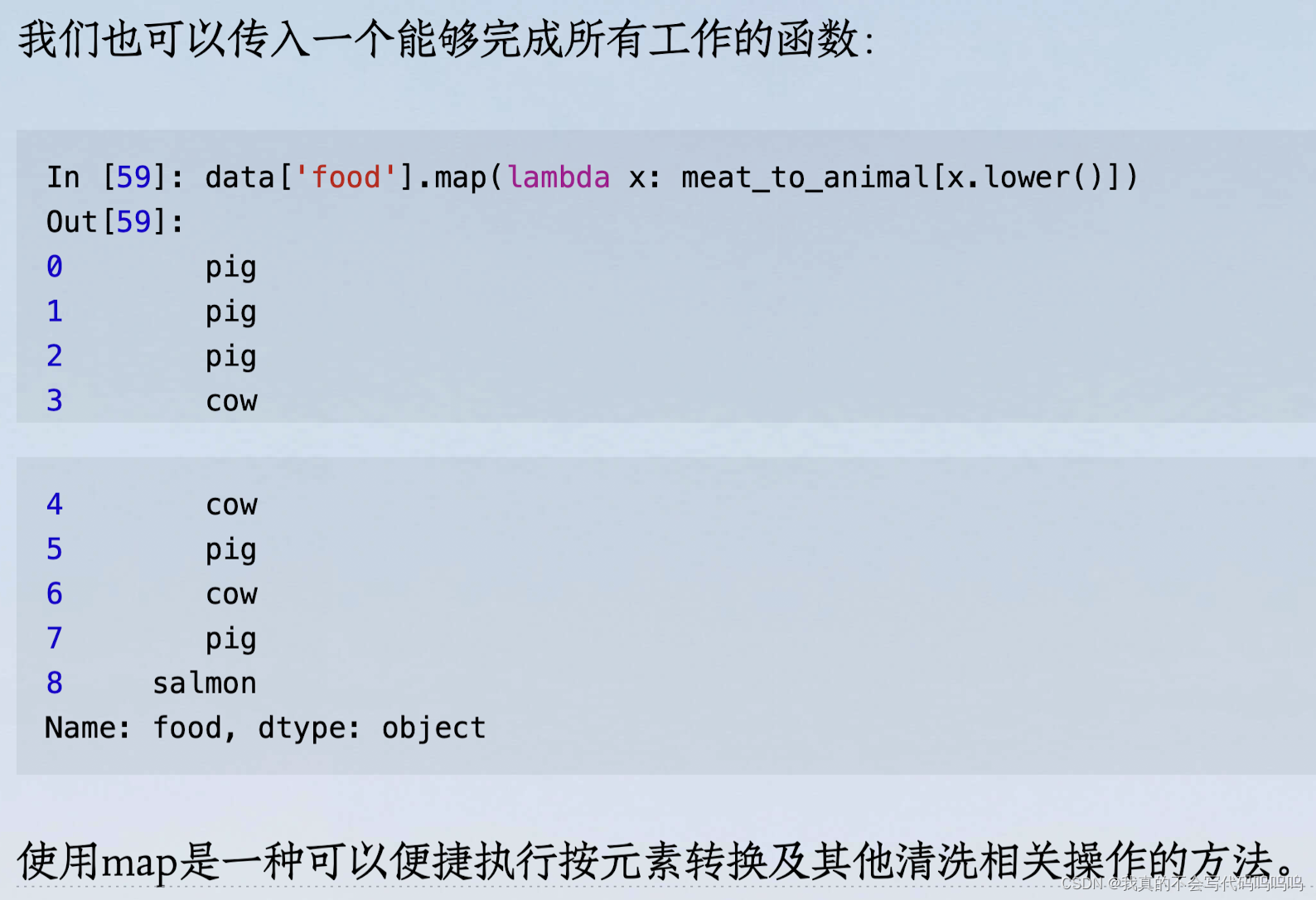
(2)函数/映射转换
基于DataFrame中的数组、列或列中的数值进行一些转换
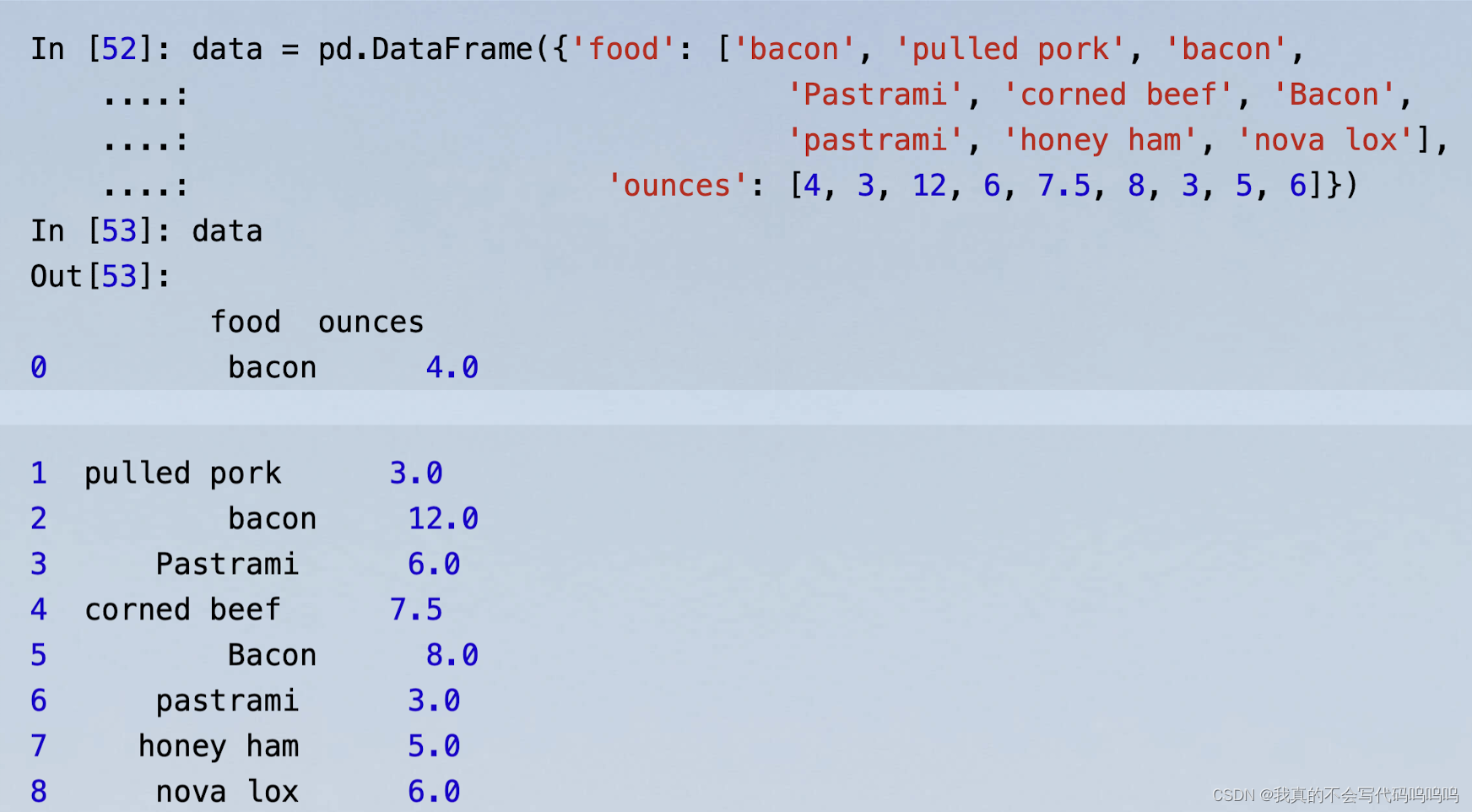
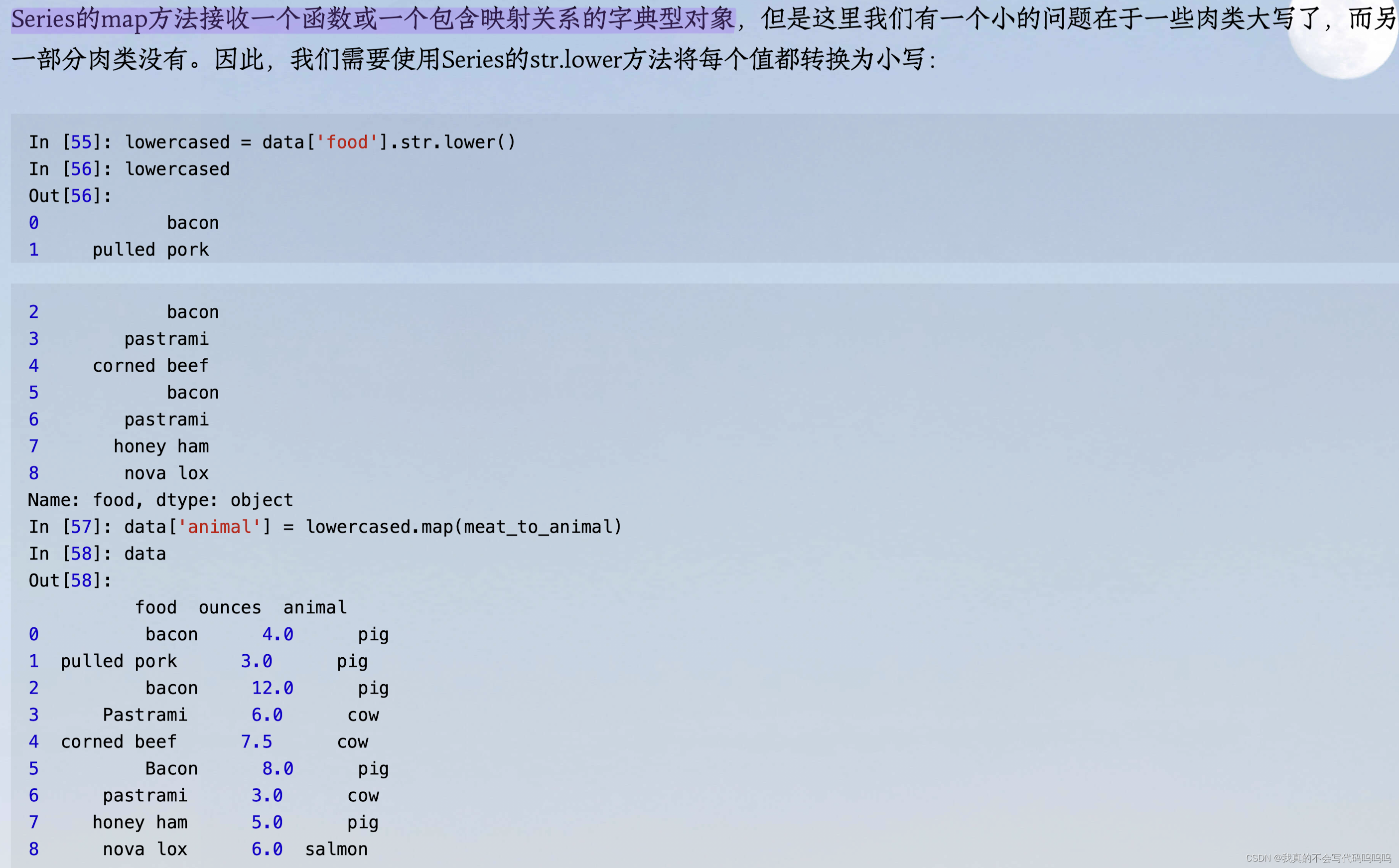
- dataframe对象数据如下:data有两列数据food、ounces。其中food列数据名称存在大小写
- 处理目标:添加一列数据,作为food的动物来源,如honey ham(秘制火腿)来源于猪pig。
- 处理方法:先添加一列字典型数据,存储food与映射的动物来源;然后,将该字典型数据与原data数据通过映射方式进行匹配,并添加列。

其他方式
map函数

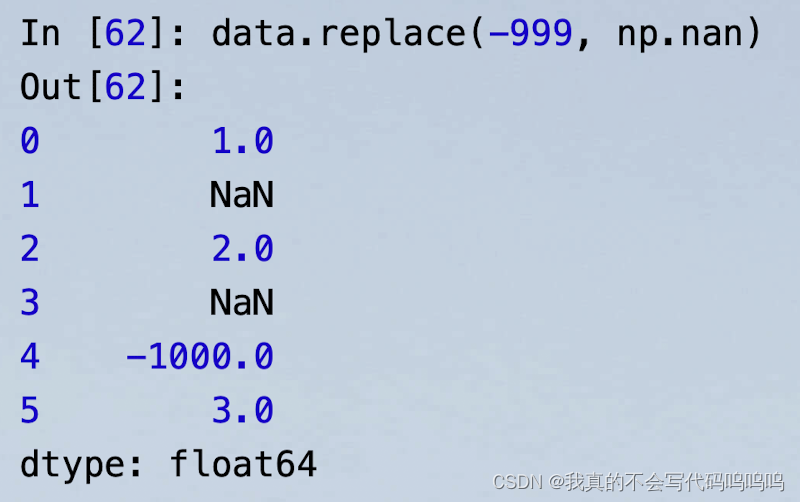
(3)替代值
replace函数:


注:data.replace方法与data.str.replace方法不同,data.str. replace是对字符串进行按元素替代
案例:




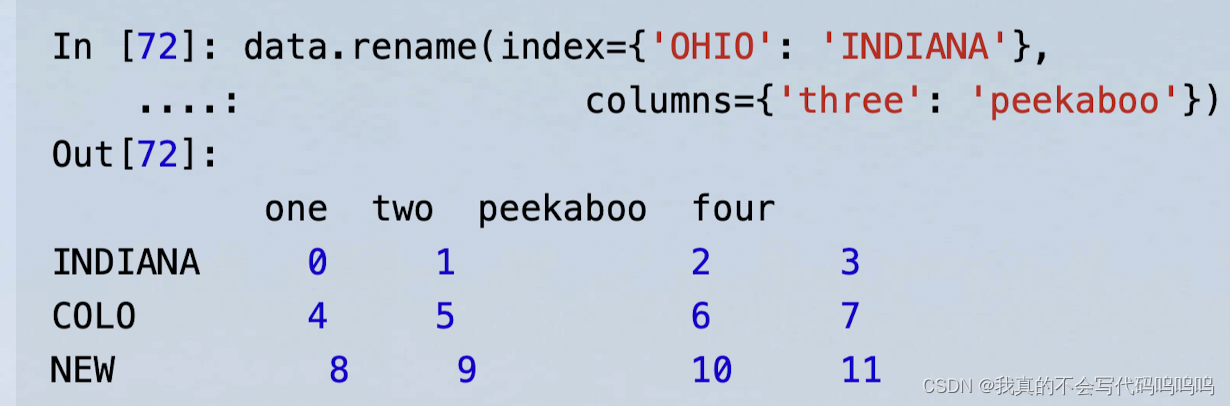
(4)重命名轴索引
- 通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带有不同标签的对象。你也可以在不生成新的数据结构的情况下修改轴。

- 将轴标签字符串转为大写


- rename函数
title() 方法返回"标题化"的字符串:所有单词都是以大写开始,其余字母均为小写,语法为str.title()

rename可以结合字典型对象使用,为轴标签的子集提供新的值
(5)离散化和分箱
连续值经常需要离散化,或者分离成”箱子“进行分析
- cut函数



pandas返回的对象是一个特殊的Categorical对象。你可以将它当作一个表示箱名的字符串数组;它在内部包含一个categories(类别)数组,它指定了不同的类别名称以及codes属性中的ages(年龄)数据标签:
一共4个箱子,默认lable为0,1,2,3代替。0代表第一组(18,25)...
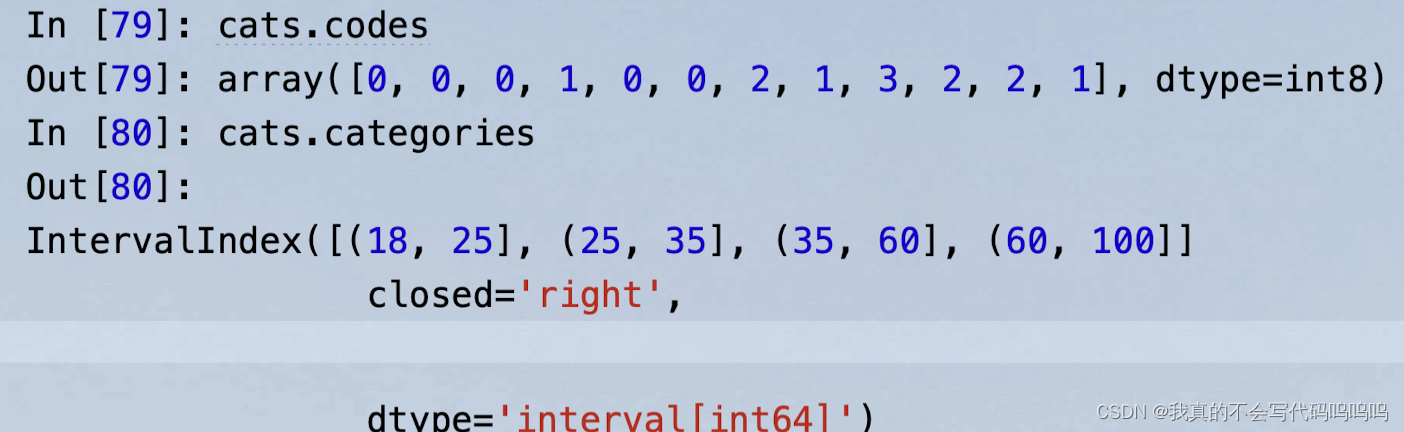
- pd.value_counts(cats):是对pandas.cut的结果中的箱数量的计数。


如果你传给cut整数个的箱来代替显式的箱边,pandas将根据数据中的最小值和最大值计算出等长的箱。precision=2的选项将十进制精度限制在两位。

- qcut函数
cut将根据值本身来选择箱子均匀间隔,qcut是根据这些值的频率来选择箱子的均匀间隔。
qcut是一个与分箱密切相关的函数,它基于样本分位数进行分箱。取决于数据的分布,使用cut通常不会使每个箱具有相同数据量的数据点。由于qcut使用样本的分位数,你可以通过qcut获得等长的箱:


4、检测和过滤异常值

- 找出一列中绝对值大于三的值:
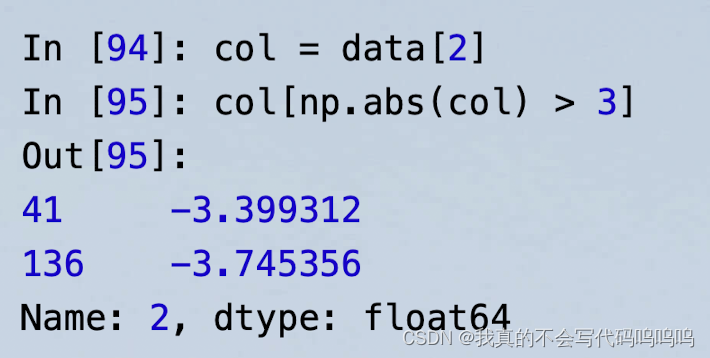
要选出所有值大于3或小于-3的行,你可以对布尔值DataFrame使用any方法。
data[(np.abs(data) > 3).any(axis=1)
- 下面代码限制了-3到3之间的数值:
语句np.sign(data)根据数据中的值的正负分别生成1和-1的数值。
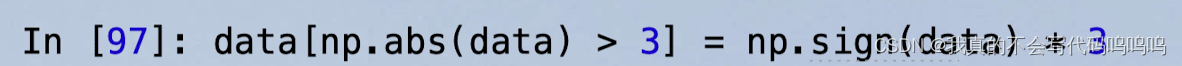
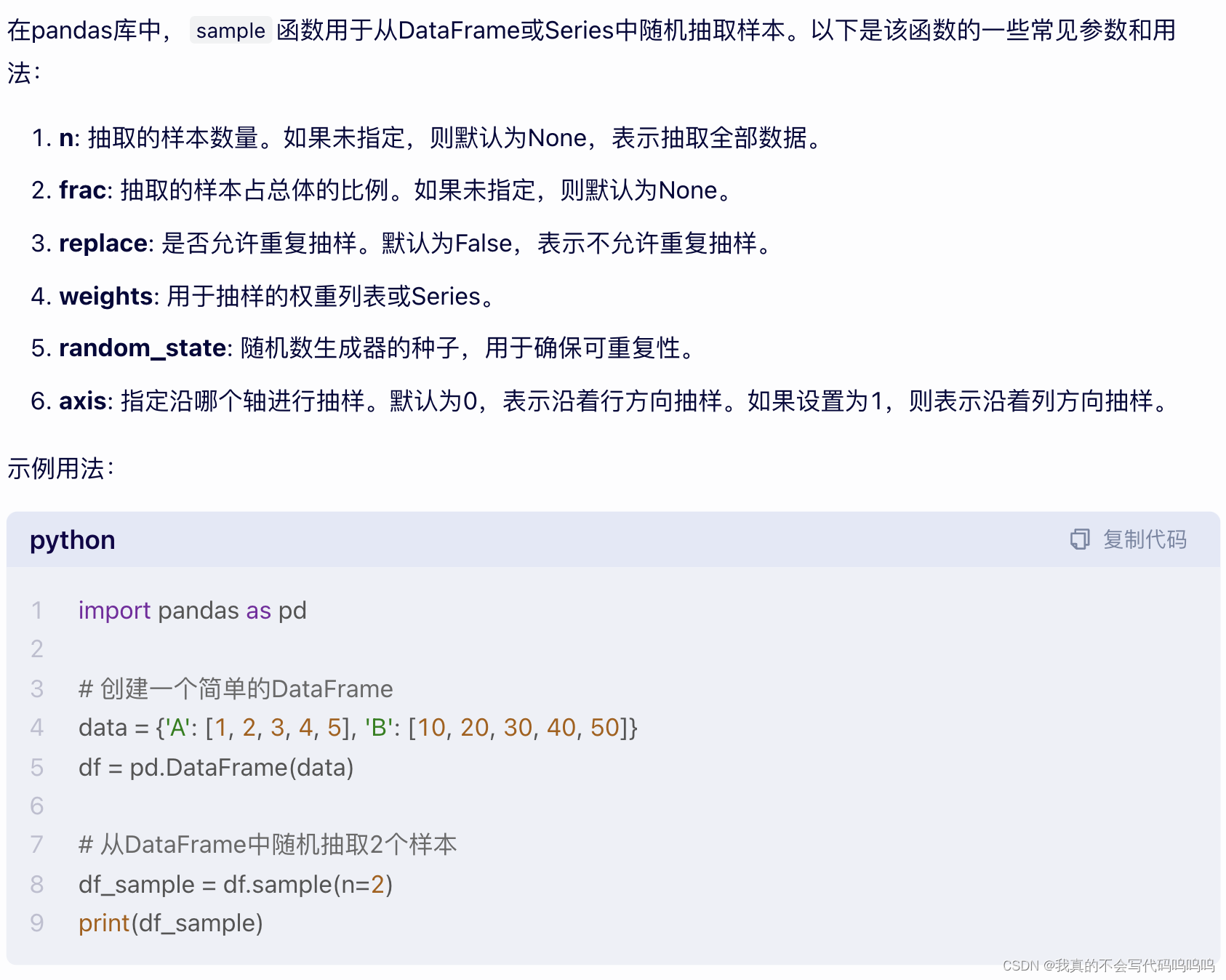
5、置换和随机抽样
(1)permutation函数
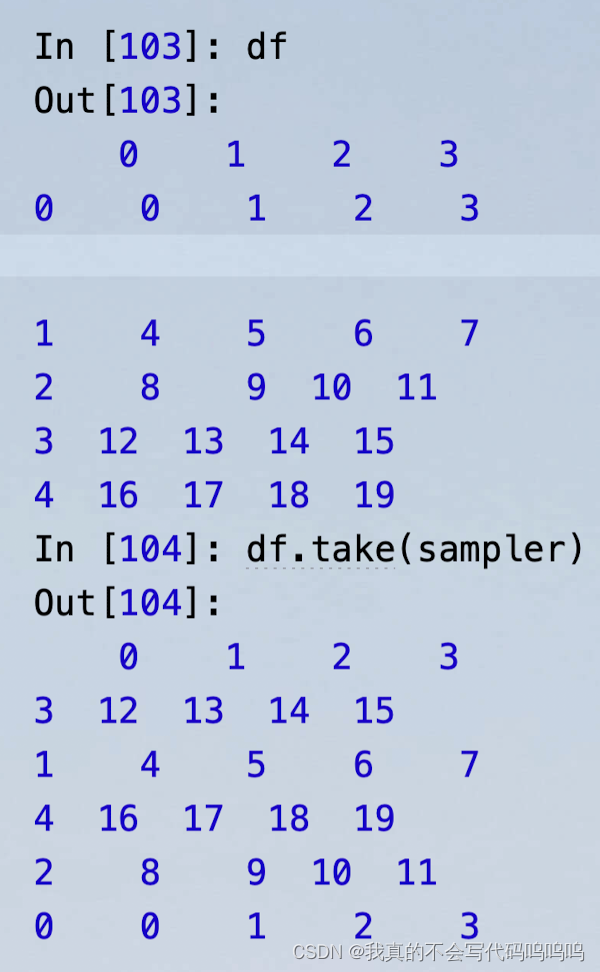
permutation函数:根据你想要的轴长度可以产生一个表示新顺序的整数数组

整数数组可以用在基于iloc的索引或等价的take函数中:df.take(sampler)/df.iloc(sampler)
(2)随机抽样
要选出一个不含有替代值的随机子集,你可以使用Series和DataFrame的sample方法

6、计算指标/虚拟变量
7、字符串操作
(1)split方法拆分

(2)split常和strip
- 一起使用,用于清除空格(包括换行)

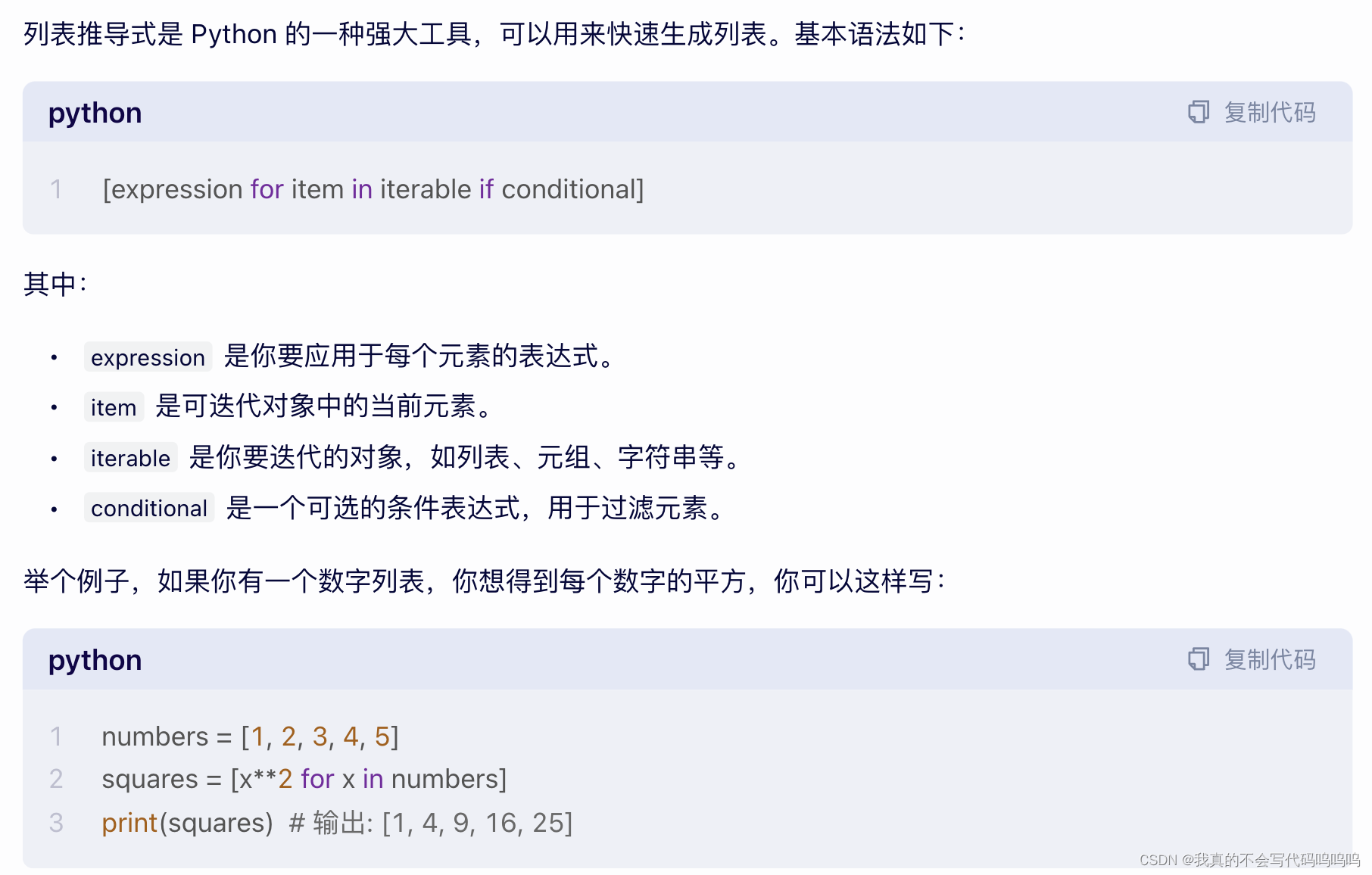
- 语法解析

注:对于解析3中的[....],为列表推导式:
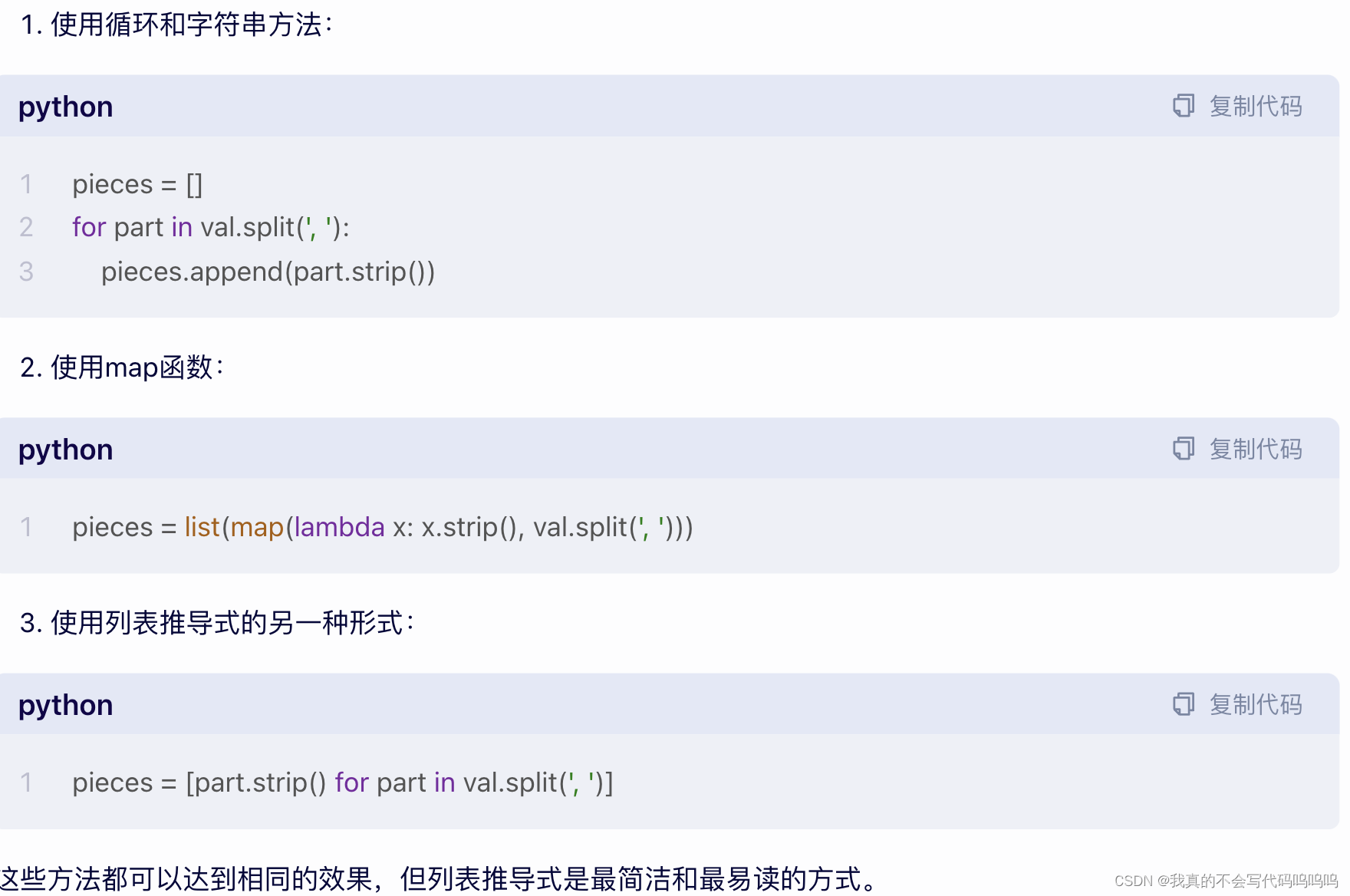
- 其他方式改写:
(5)字符串多重赋值

解析:

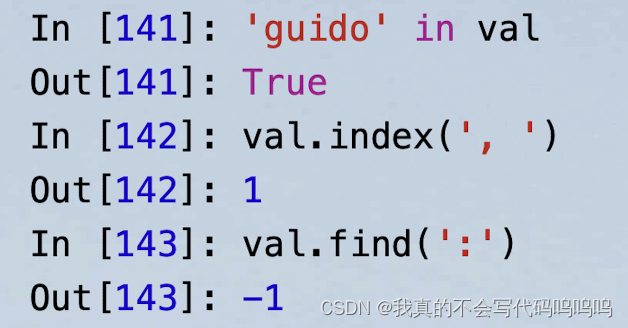
(6)定位子字符串
in关键字、index和find
注:find和index的区别在于index在字符串没有找到时会抛出一个异常(而find是返回-1)
(7)字符串方法的列表

案例:


8、正则表达式
正则表达式提供了一种在文本中灵活查找或匹配(通常更为复杂的)字符串模式的方法。
单个表达式通常被称为regex,是根据正则表达式语言形成的字符串。
Python内建的re模块是用于将正则表达式应用到字符串上的库。re模块主要有三个主题:模式匹配、替代、拆分
(1)re.split('\s+', text)

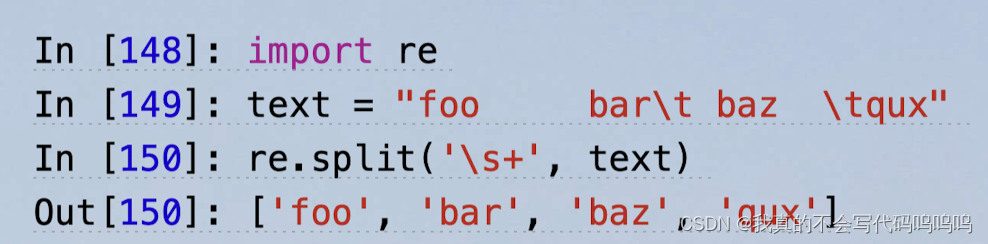
当你调用re.split('\s+', text),正则表达式首先会被编译,然后正则表达式的split方法在传入文本上被调用。
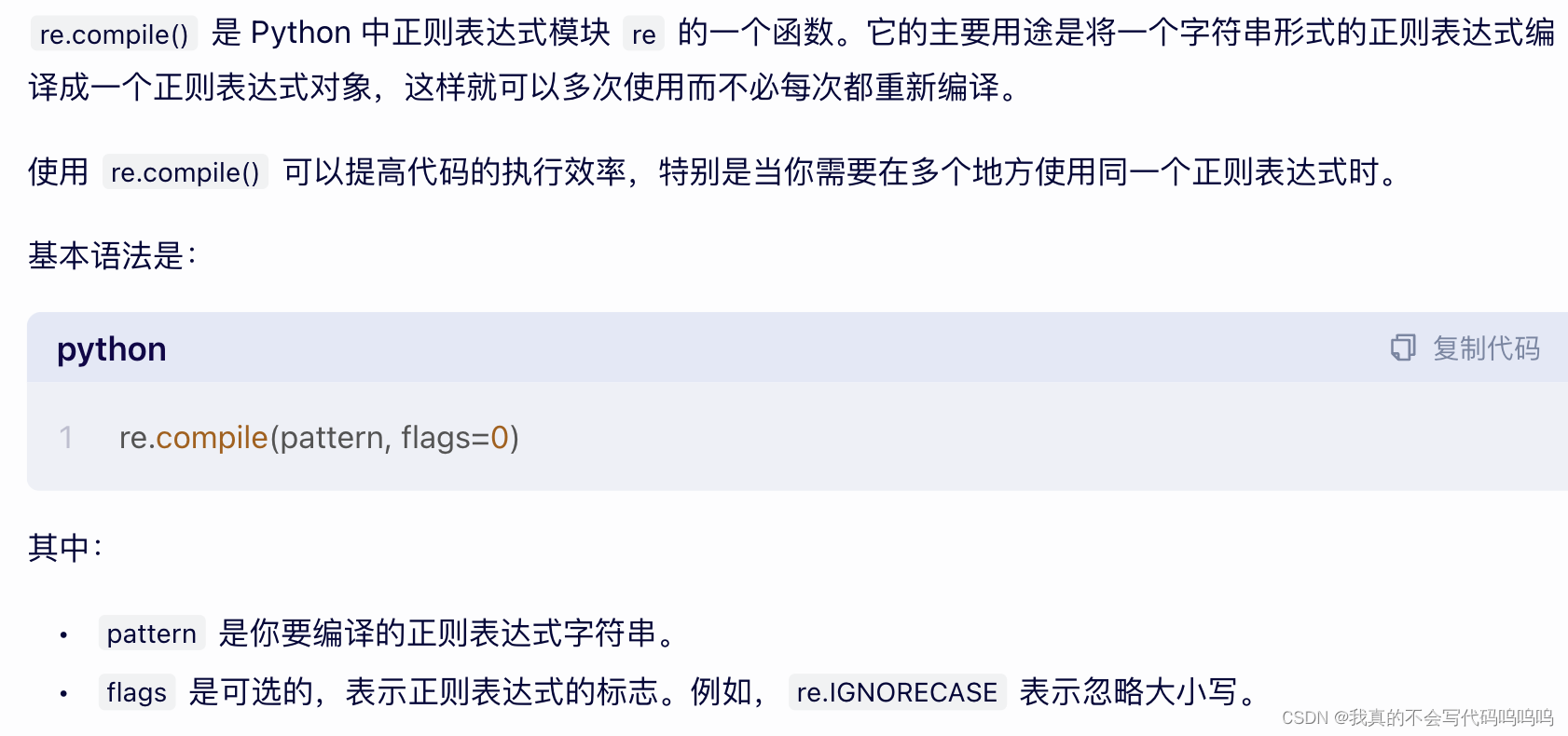
(2)re.compile
使用re.compile自行编译,形成一个可复用的正则表达式对象
注:如果你需要将相同的表达式应用到多个字符串上,推荐使用re.compile创建一个正则表达式对象,这样做有利于节约CPU周期。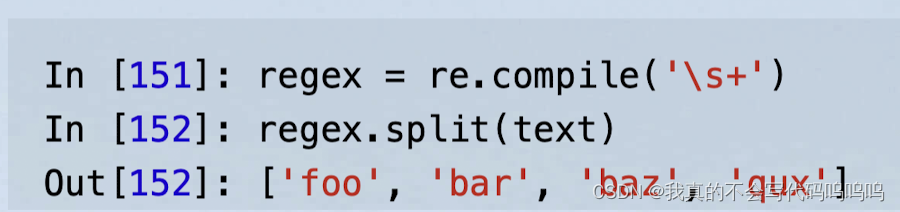

(3)findall函数



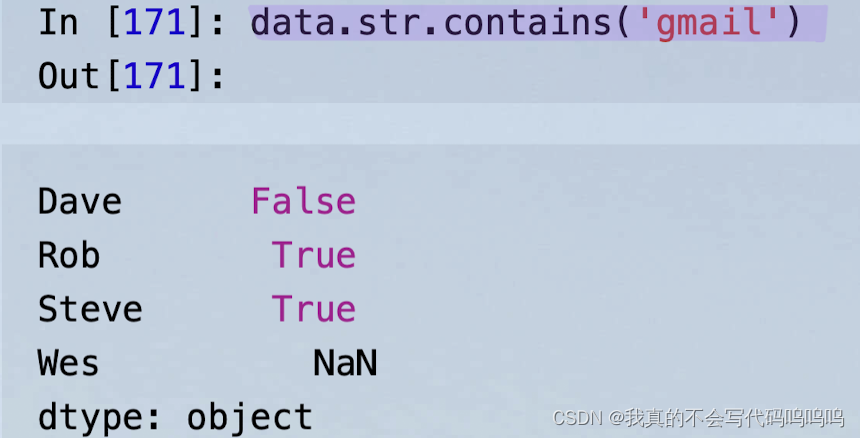
9、pandas中的向量化字符串函数

















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









