







目录
一、分组操作
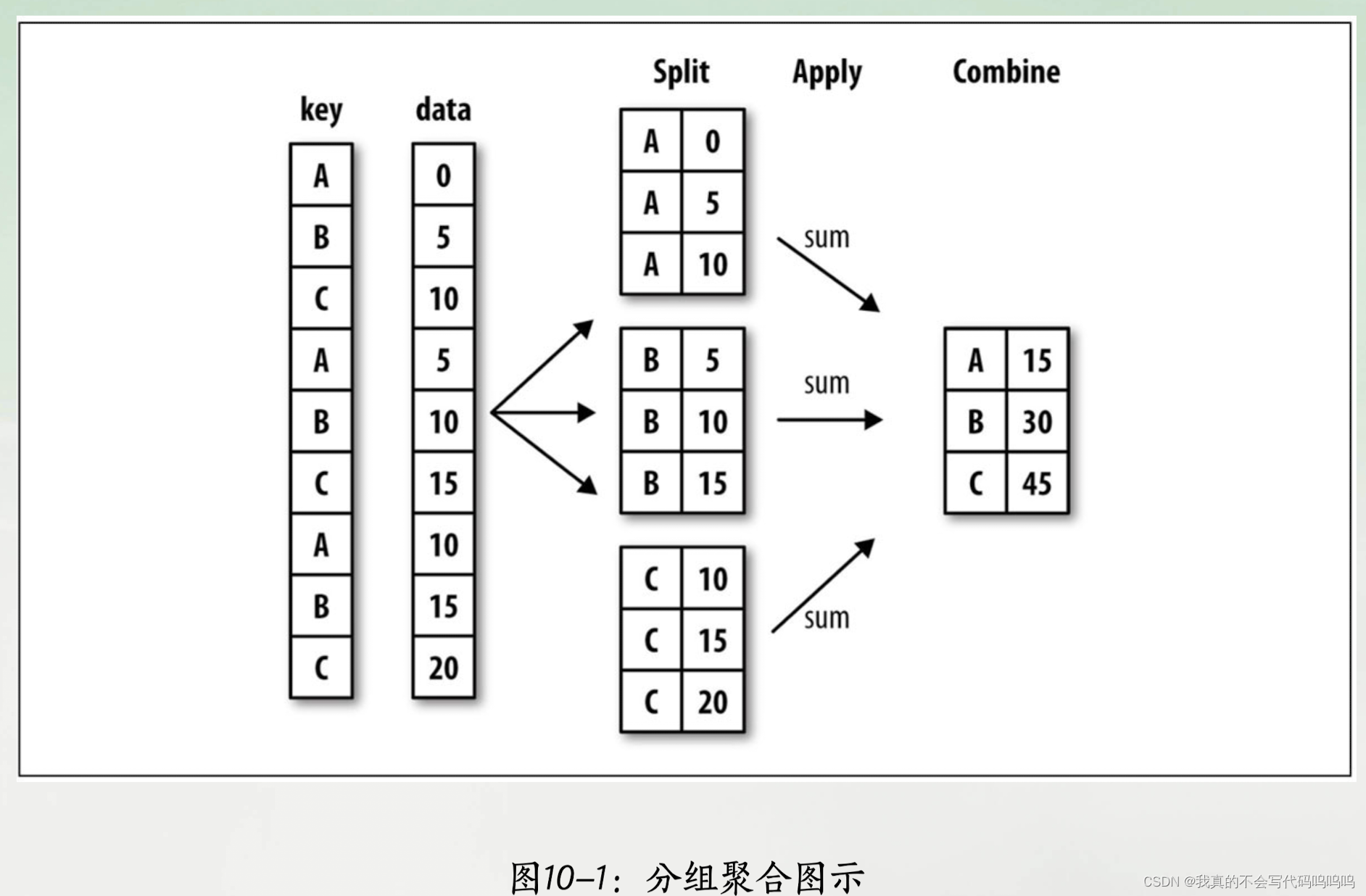
通过Python和pandas的表达,我们可以使用pandas对象或NumPy数组执行相当复杂的组操作
1、GroupBy机制
- 数据包含在pandas对象(Series、DataFrame或其他数据结构)中,根据提供的一个或多个键分离到各个组中;
- 分离操作是在数据对象的特定轴向上进行的。
- 例如,DataFrame可以在它的行方向(axis=0)或列方向(axis=1)进行分组。分组操作后,一个函数就可以应用到各个组中,产生新的值。
- 最终所有函数的应用结果会联合为一个结果对象。形式通常取决于对数据进行的操作。
基础数据
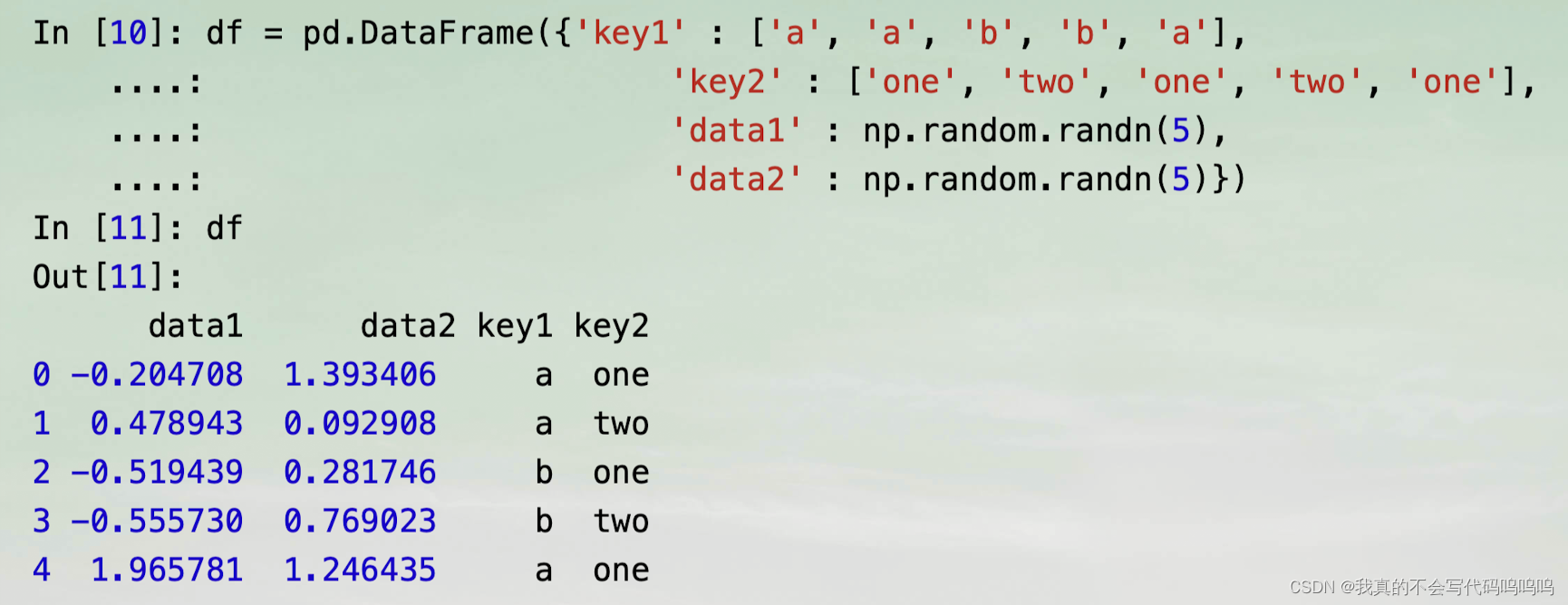
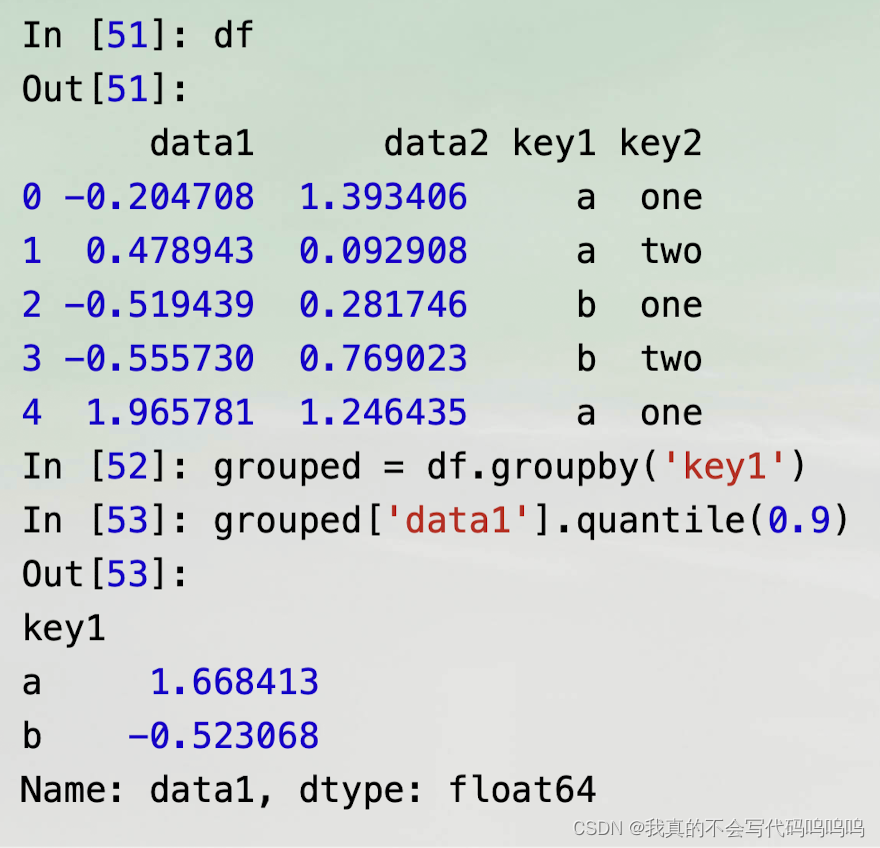
(1)groupby方法
- 调用groupby方法,并使用key1列分组,访问data1。
- grouped变量现在是一个GroupBy对象。除了一些关于分组键df['key1']的一些中间数据之外,它实际上还没有进行任何计算
import numpy as np
import pandas as pd
df=pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
print(df)
grouped=df['data1'].groupby(df['key1'])
print(grouped)
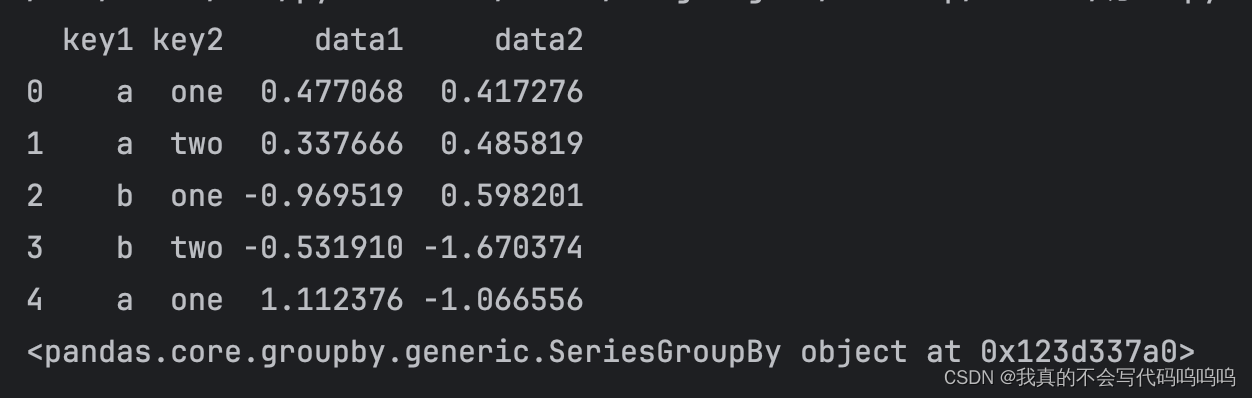
补充:为什么分组后不能直接输出数据?

输出方法示例:
# 创建一个示例数据集
data = {'column_name': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A'],
'value': [1, 2, 3, 4, 5, 6, 7, 8]}
df = pd.DataFrame(data)
# 按column_name列进行分组
grouped = df.groupby('column_name')
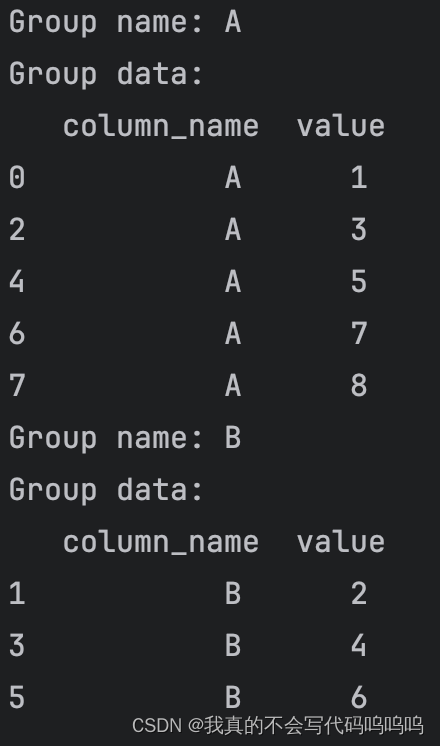
# 查看每个组的数据
for name, group in grouped:
print("Group name:", name)
print("Group data:\n", group)
分组输出结果
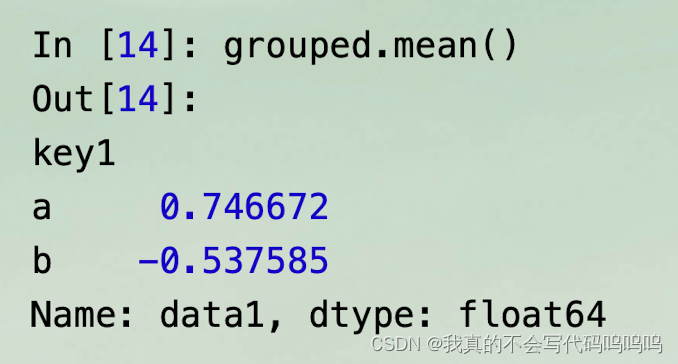
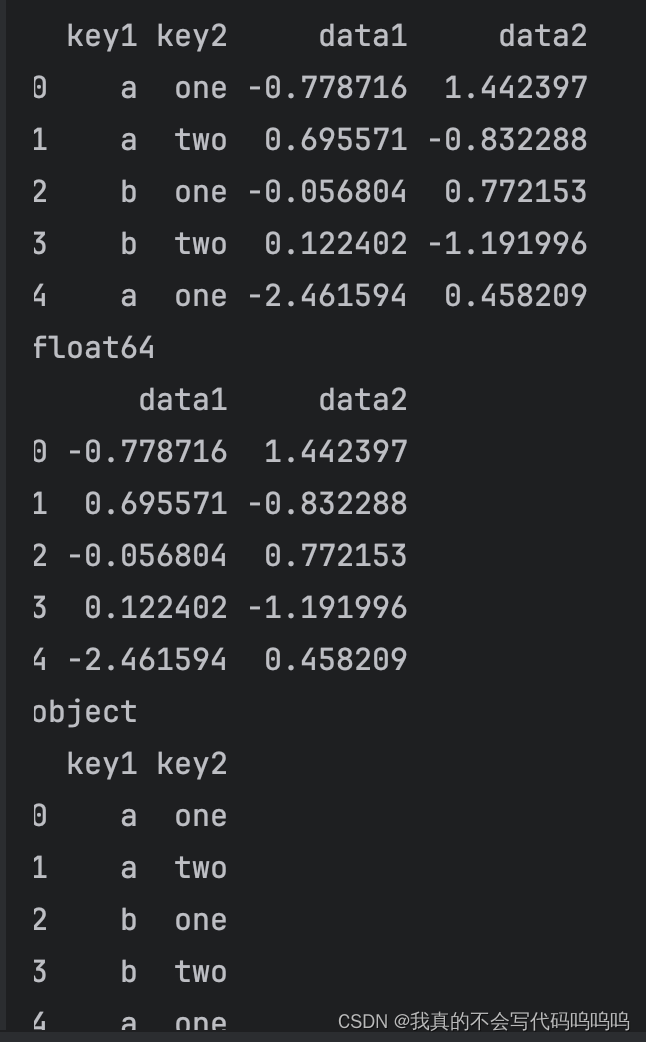
(2)分组对象计算
- 调用mean函数,处理分组后的对象。
- 数据(一个Series)根据分组键进行了聚合,并产生了一个新的Series,这个Series使用key1列的唯一值作为索引
(3)两个键分组计算
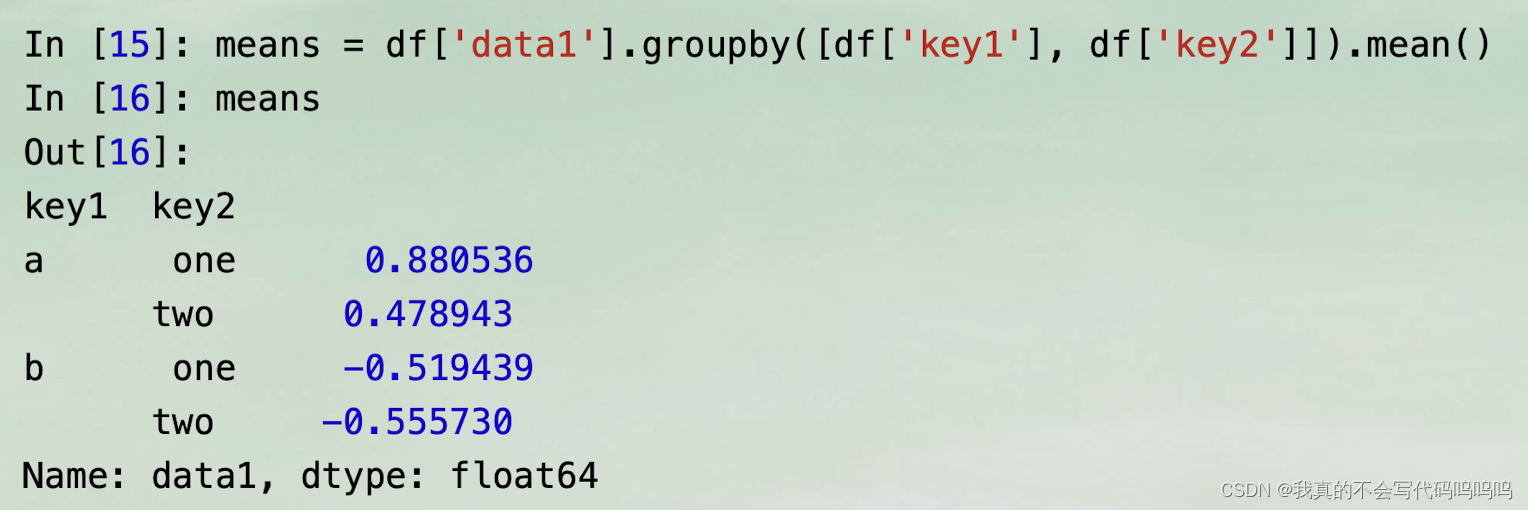

- 分组信息作为你想要继续处理的数据,通常包含在同一个DataFrame中;
- 这种情况可以传递列名(无论那些列名是字符串、数字或其他Python对象)作为分组键
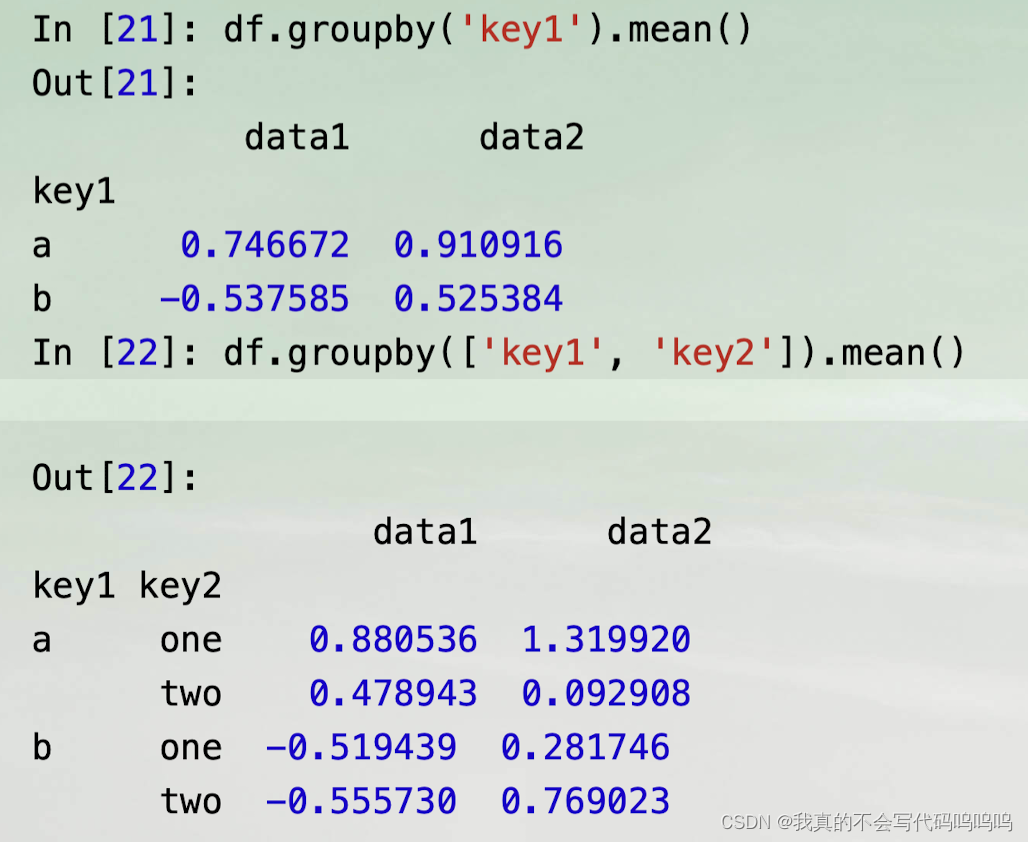
注意:
- 第一行代码中结果里并没有key2列,因为df['key2']并不是数值数据,即df['key2']是一个冗余列,因此被排除在结果之外。
- 默认情况下,所有的数值列都可以聚合,尽管可能会过滤到子集。
(4)数组分组
- 分组键可以是Series,也可以是正确长度的任何数组,
- 如果数组长度不匹配,运行会报错
import numpy as np
import pandas as pd
df=pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
#打印出初始数据
print(df)
#获取根据key1分组了的data1列数据
grouped=df['data1'].groupby(df['key1'])
#等长数据states与years
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
#根据两个等长数组,进行分组原数据
df2=df['data1'].groupby([states, years]).mean()
print('列表分组后')
print(df2)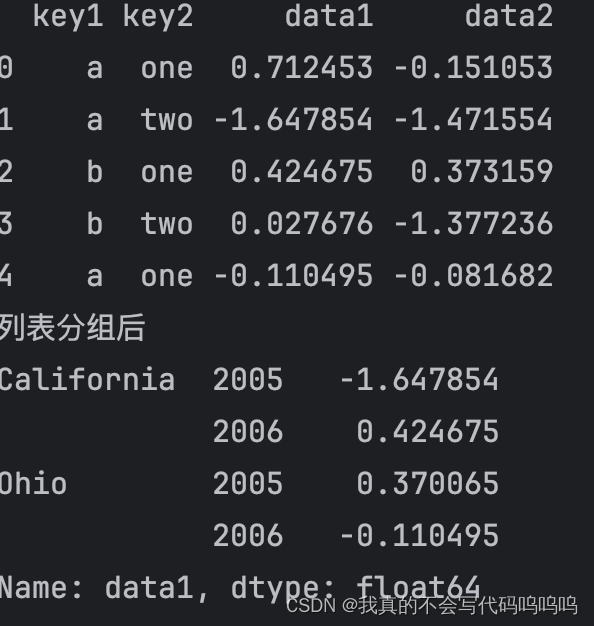
(5)size方法
- size方法返回一个包含组大小信息的Series

2、遍历各分组
- GroupBy对象支持迭代,会生成一个包含组名和数据块的2维元组序列
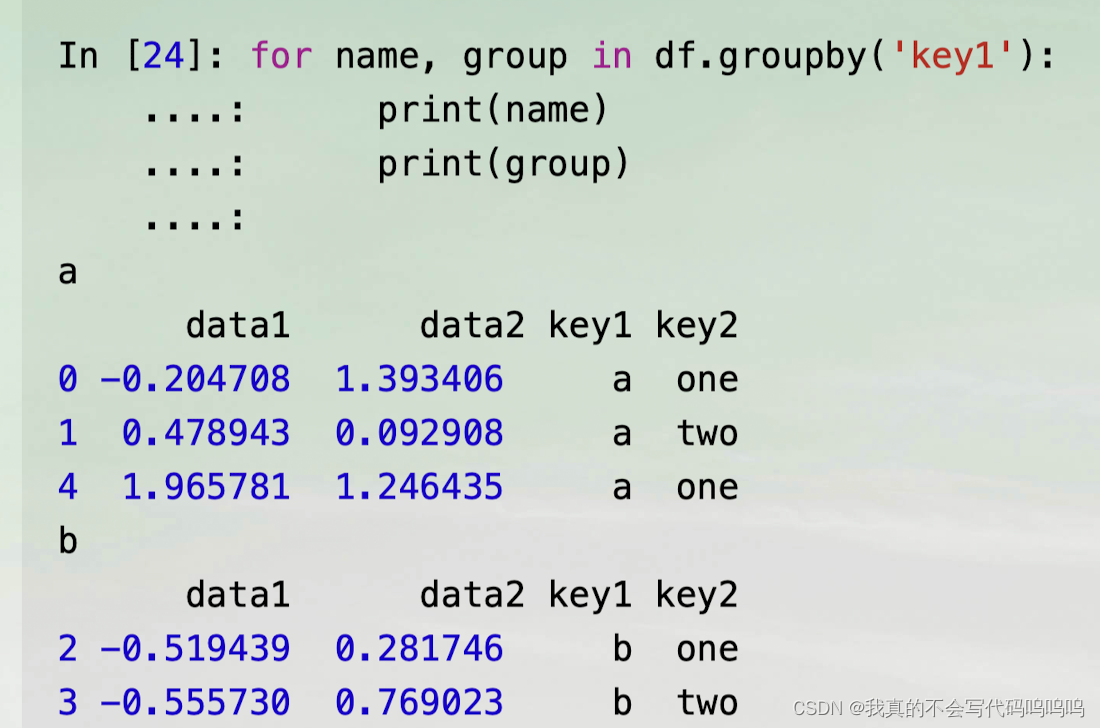
(1)单个键
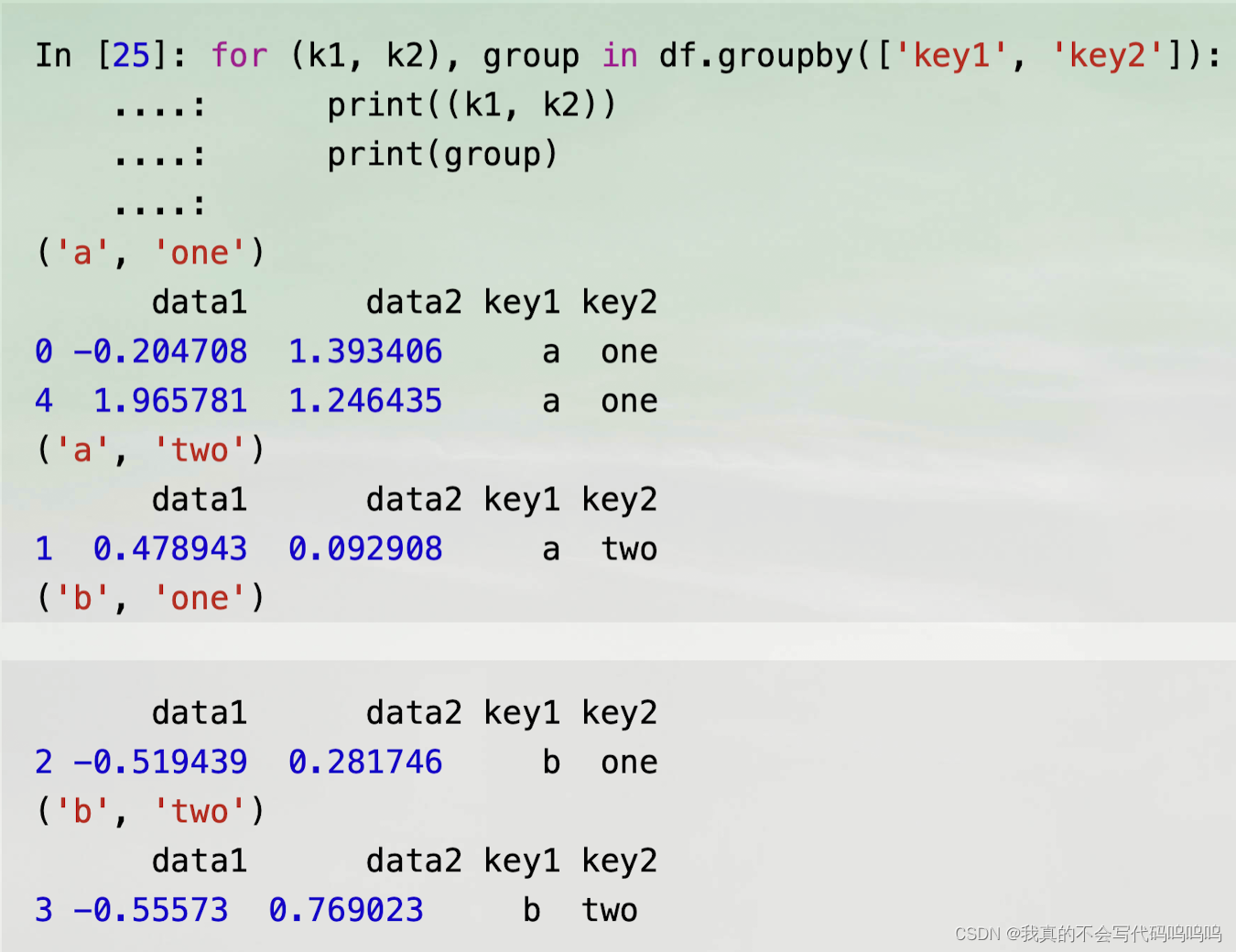
(2)多键
- 在多个分组键的情况下,元组中的第一个元素是键值的元组
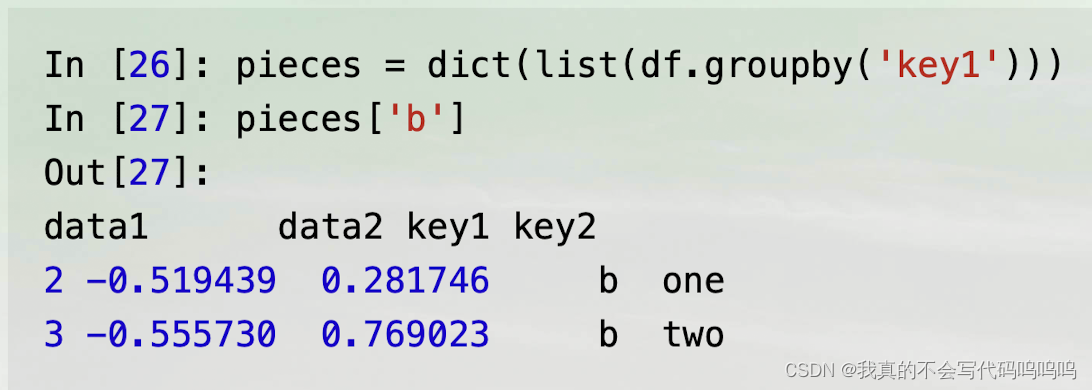
(3)字典形式输出数据块
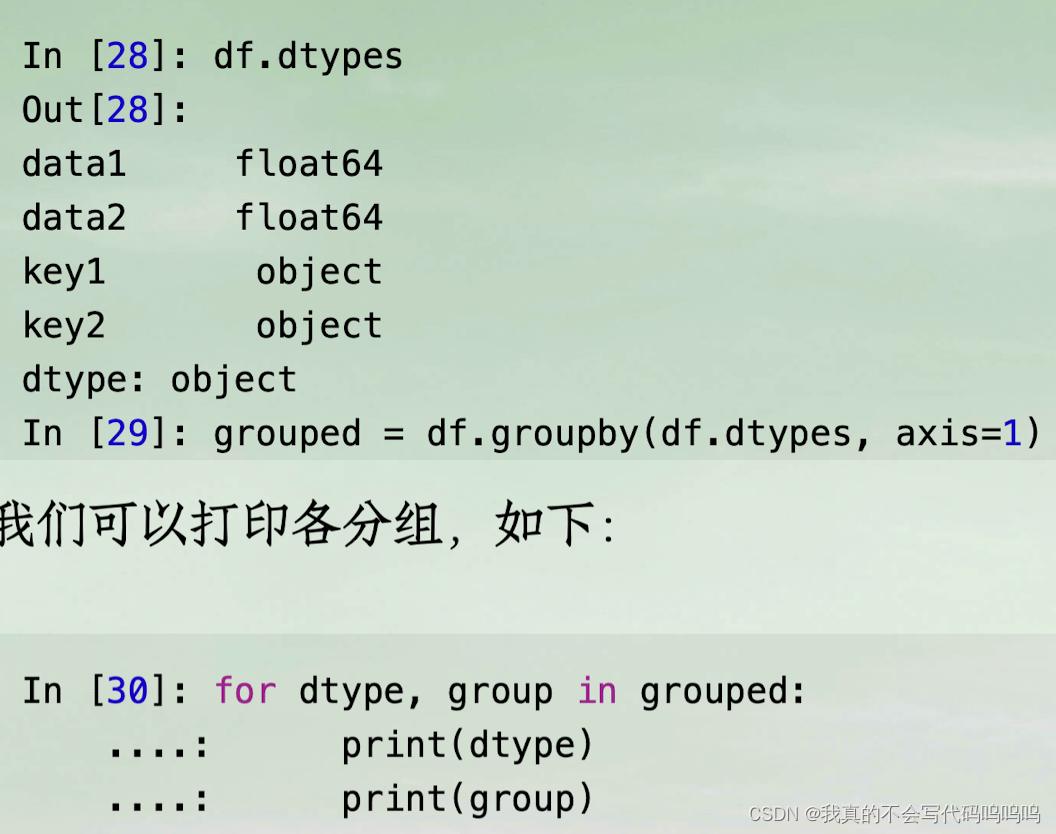
(4)不同轴分组
- 下方为纵轴示例,axis=1
3、选择一列或所有列的子集
(1)语法糖


(2)返回数据结构
如果传递的是列表或数组,则此索引操作返回的对象是分组的DataFrame;如果只有单个列名作为标量传递,则为分组的Series:
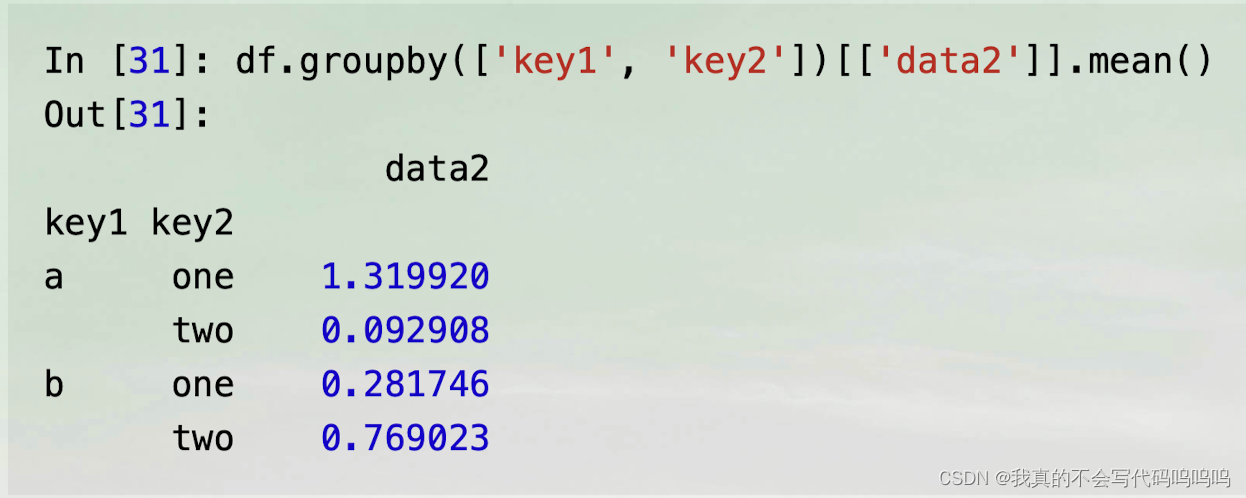
- 注意‘data2’写法,下面示例:返回dataframe
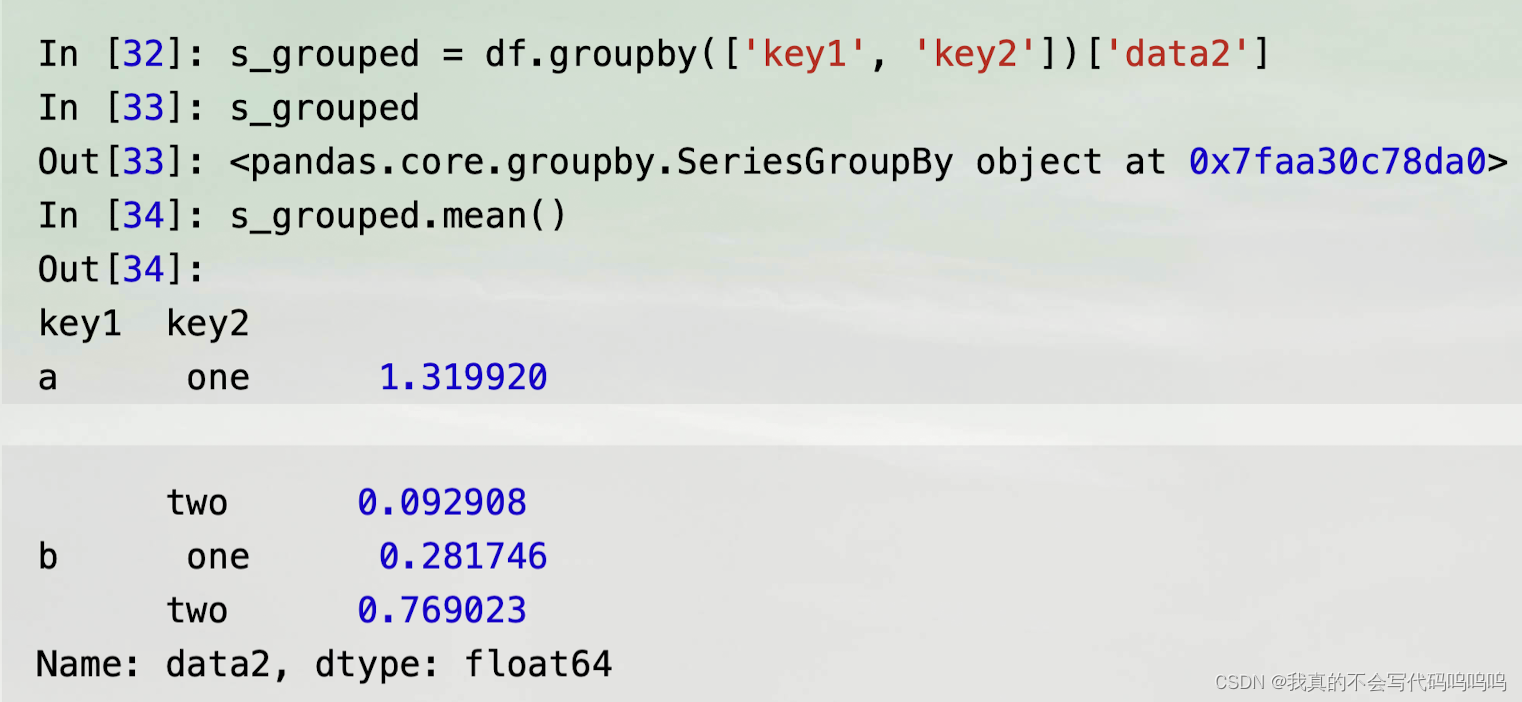
- 注意‘data2’写法,下方示例:返回series
4、使用字典和Series分组
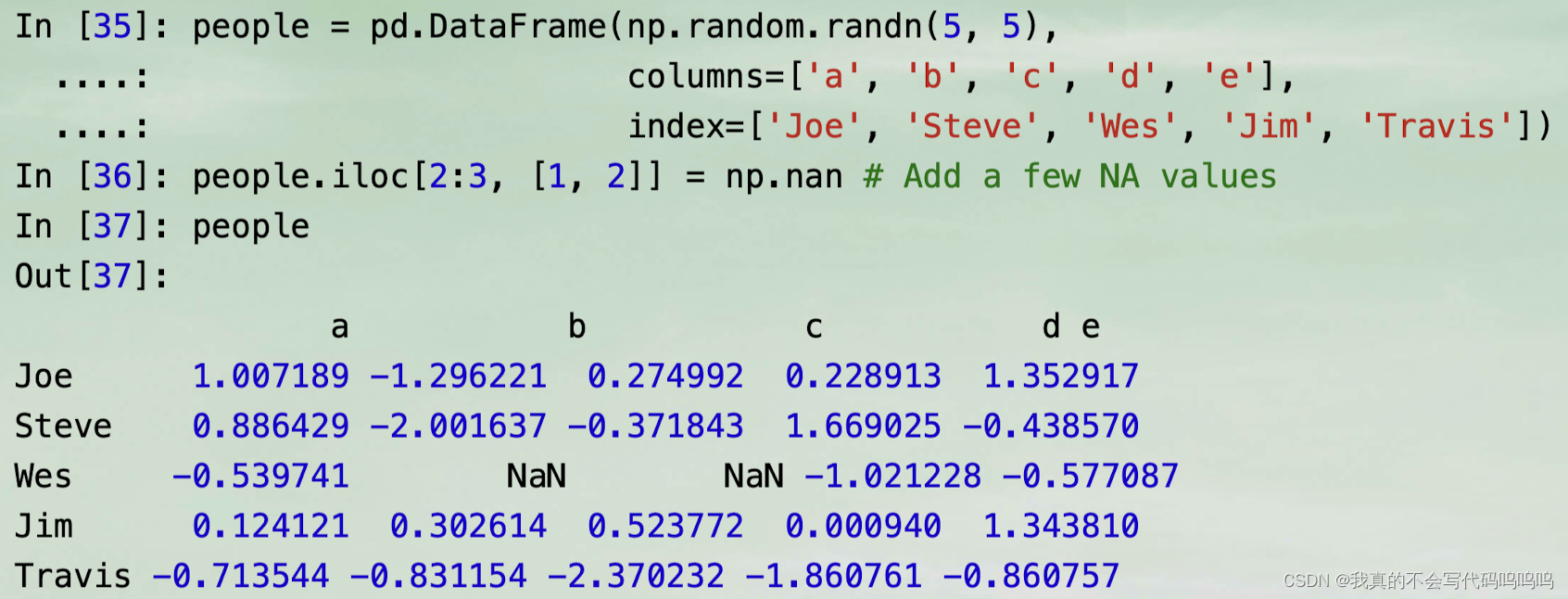
基础数据

(1)使用字典
- 将mapping这个字典构造传给groupby的数组,但是我们也可以直接传字典。
- 多写的键’f’:用于表明未用的分组键也是没问题的
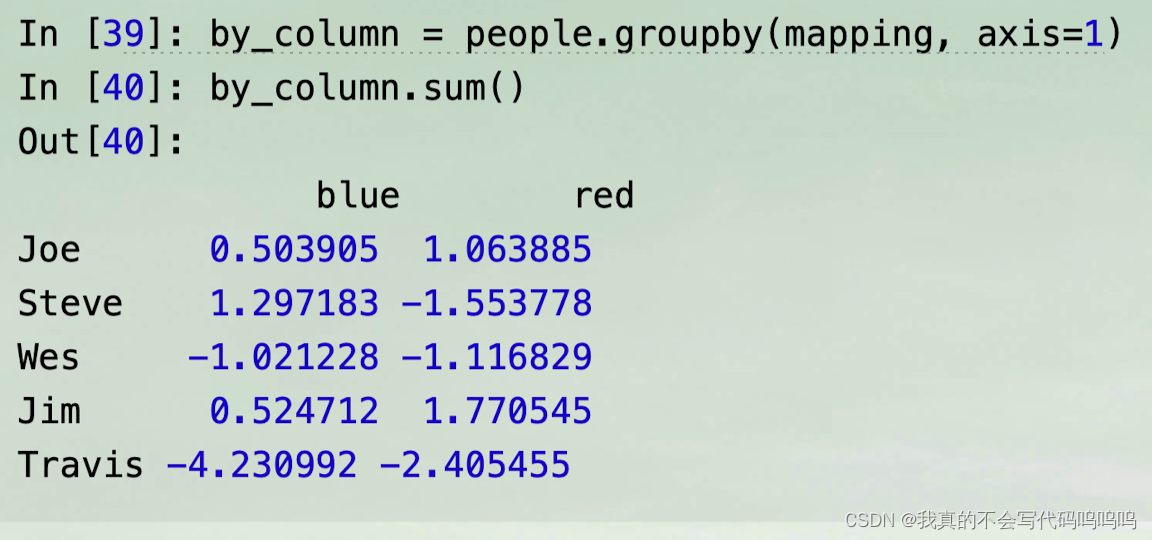
(2)使用series
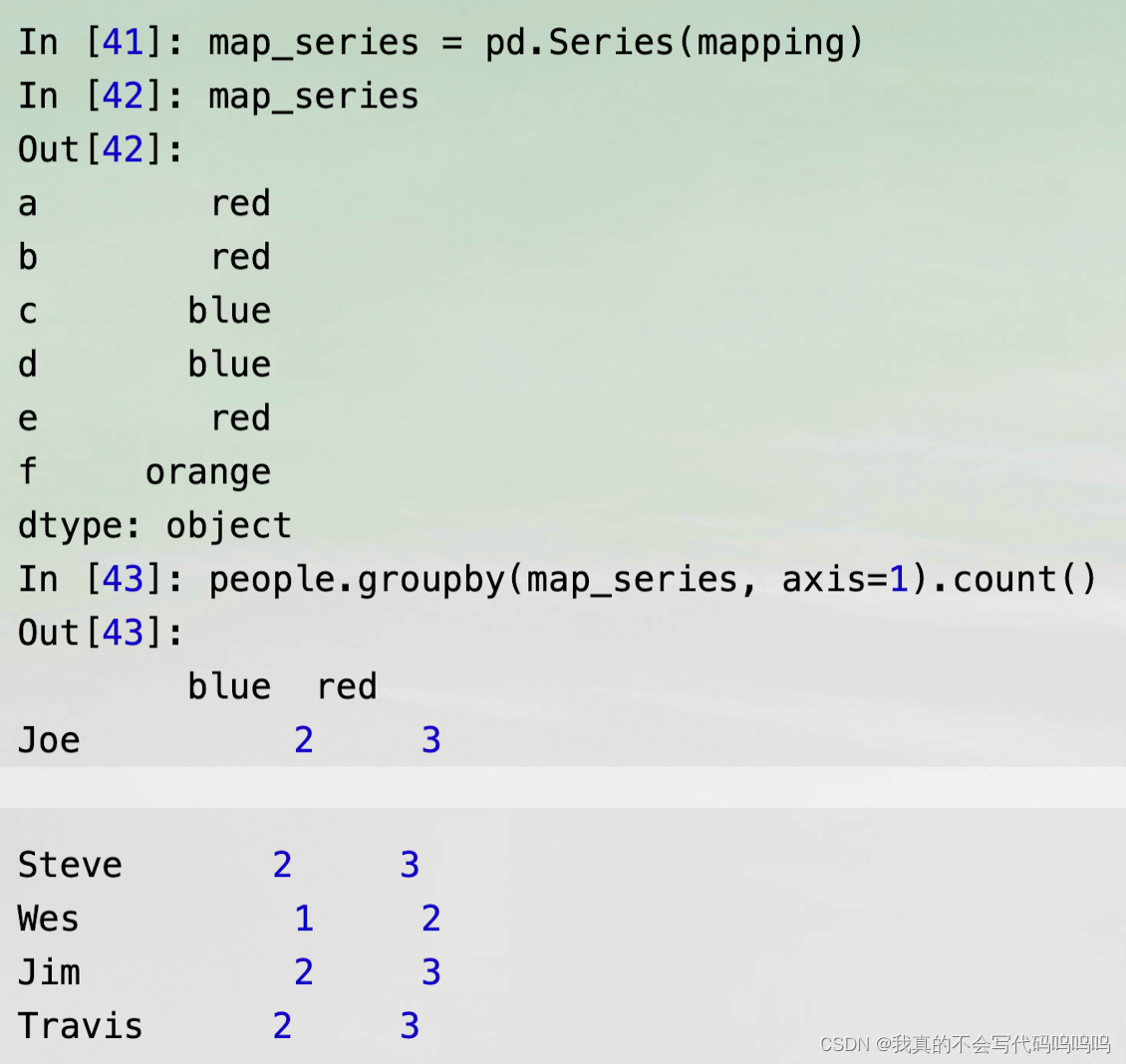
5、使用函数分组
作为分组键传递的函数将会按照每个索引值调用一次,同时返回值会被用作分组名称
(1)len函数
人的名字作为索引值。假设你想根据名字的长度来进行分组。虽然你可以计算出字符串长度的数组,但传递len函数更为简单


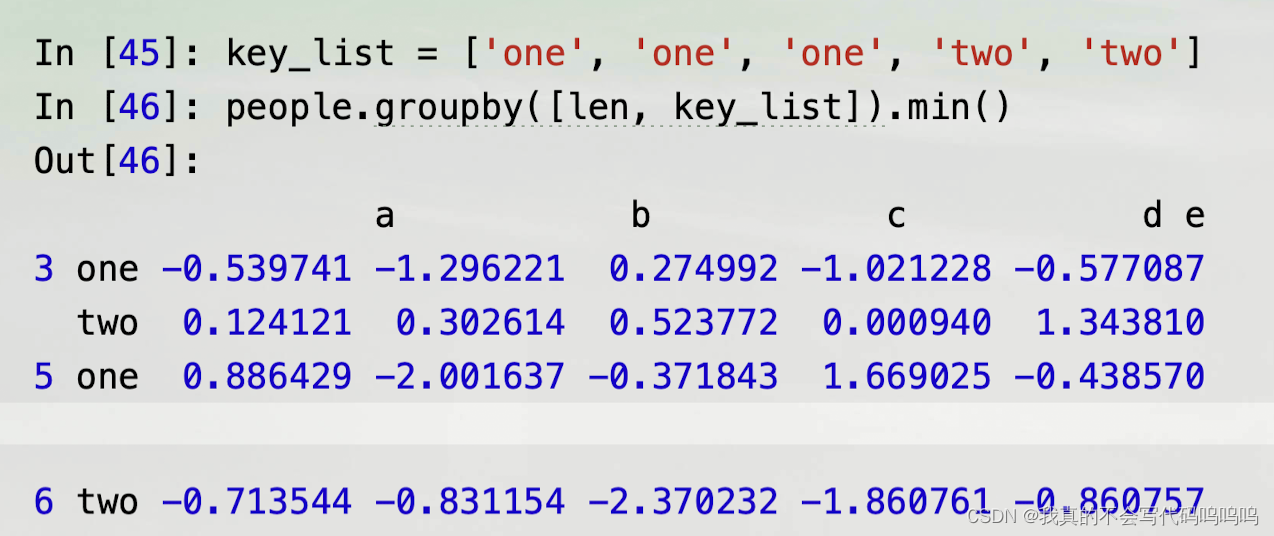
(2)函数混合
- 将函数与数组、字典或Series进行混合
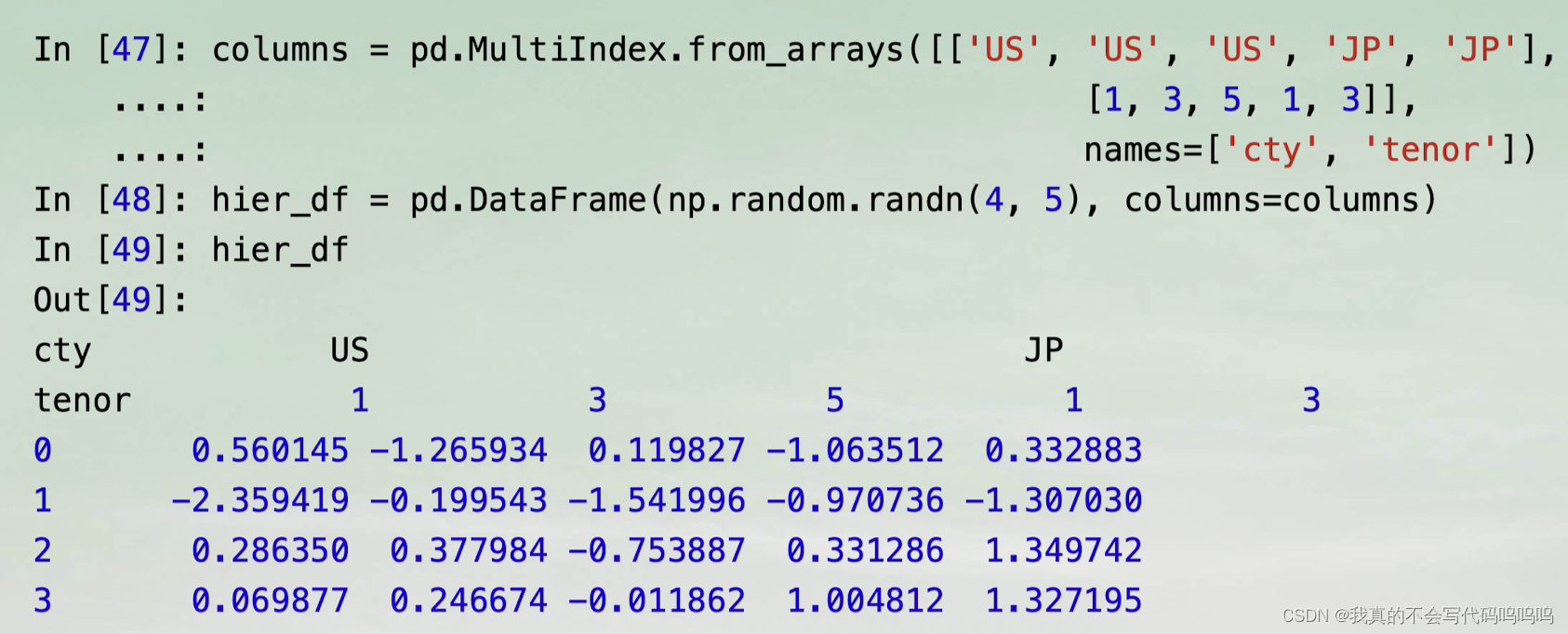
6、根据索引层级分组
分层索引的数据集有一个非常方便的地方,就是能够在轴索引的某个层级上进行聚合

补充:

二、数据聚合
聚合是指所有根据数组产生标量值的数据转换过程。包括mean、count、min和sum等


1、自定义聚合函数
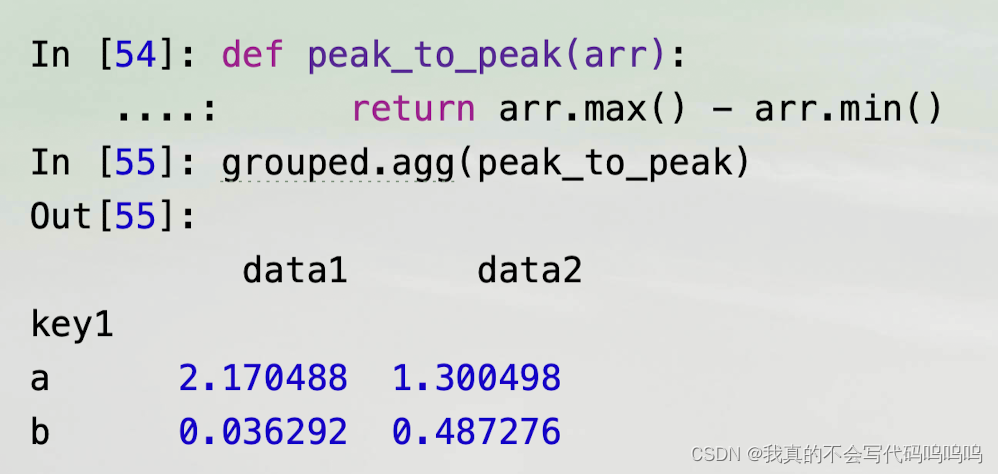
- 要使用你自己的聚合函数,需要将函数传递给aggregate或agg方法
2、逐列及多函数应用
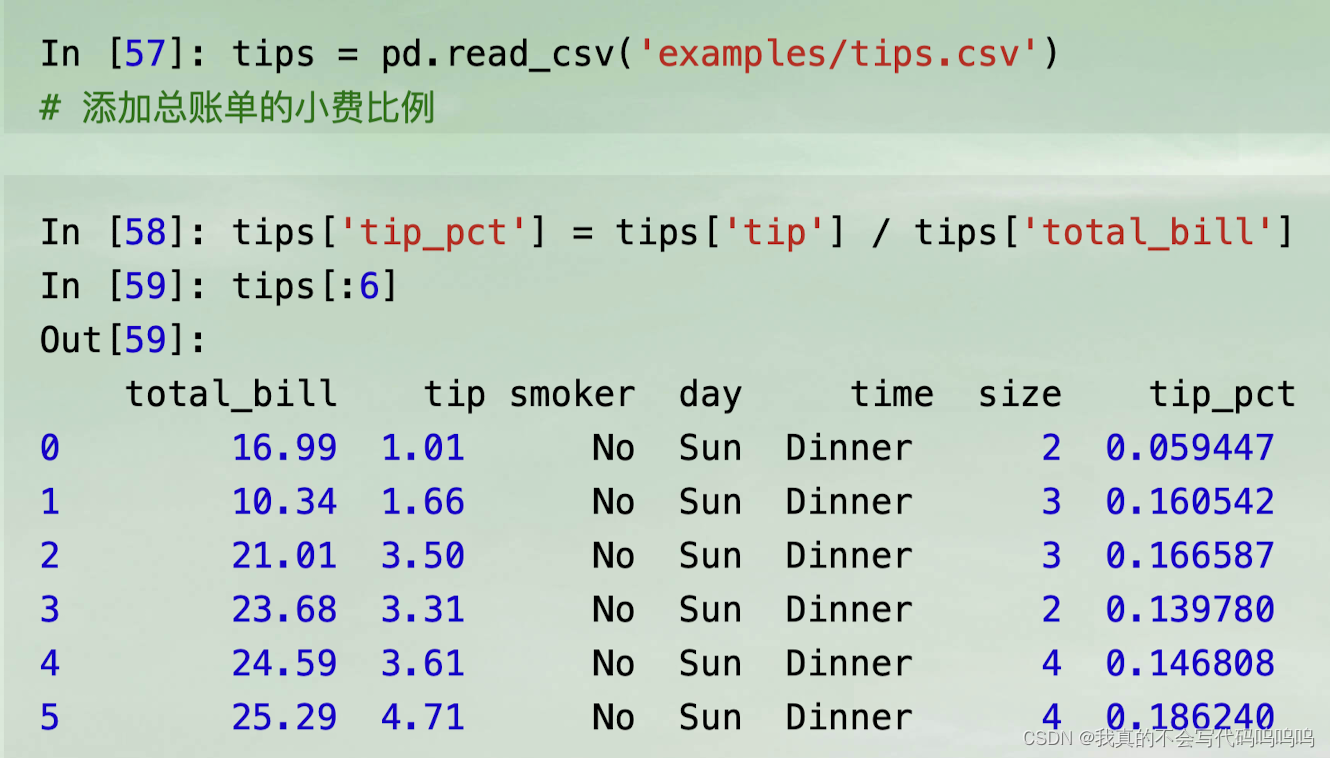
对Series或DataFrame所有列进行聚合就是使用aggregate和所需函数,或者是调用像mean或std这种方法的。
![]()
- 将函数名以字符串形式传递
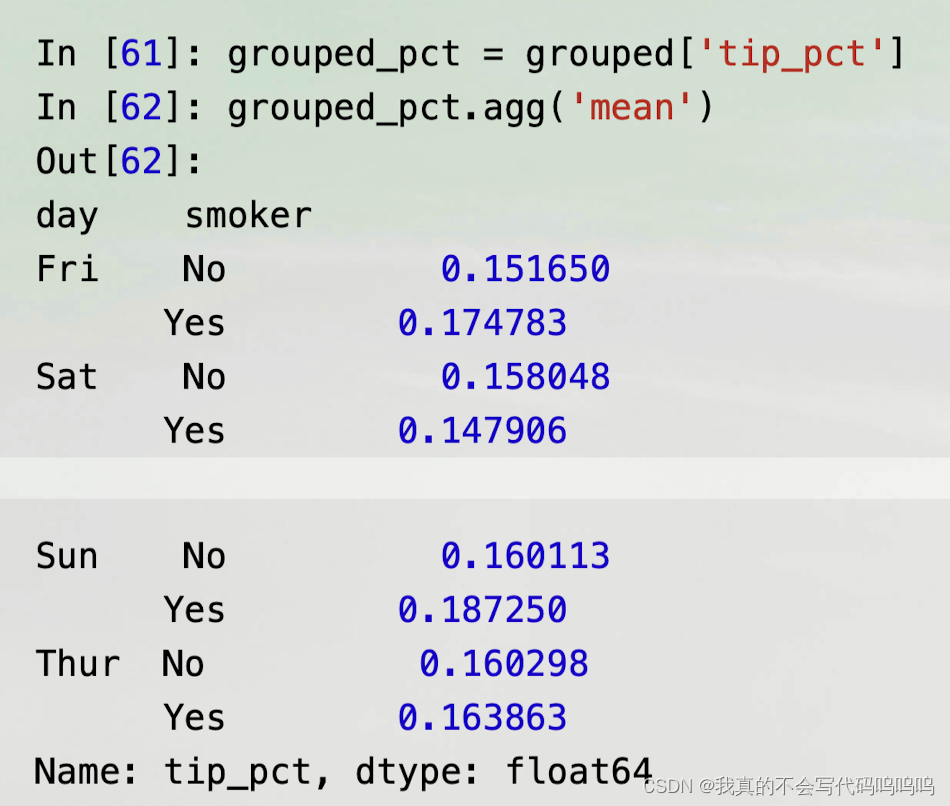
(1)分组名称
- 如果传递的是函数或者函数名的列表,你会获得一个列名是这些函数名的DataFrame:
- 这里我们传递了聚合函数的列表给agg方法,这些函数会各自运用于数据分组。
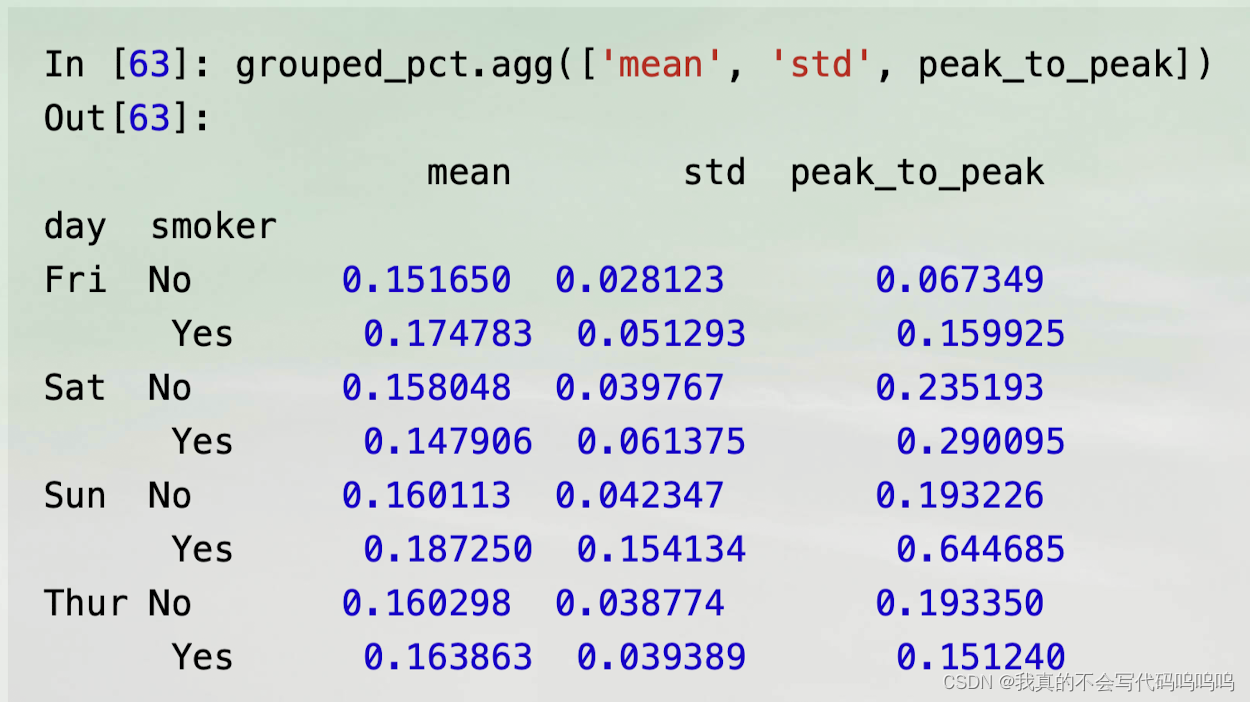

- 传递(name, function)元组的列表,每个元组的第一个元素将作为DataFrame的列名(可认为二元元组的列表是一种有序的对应关系)
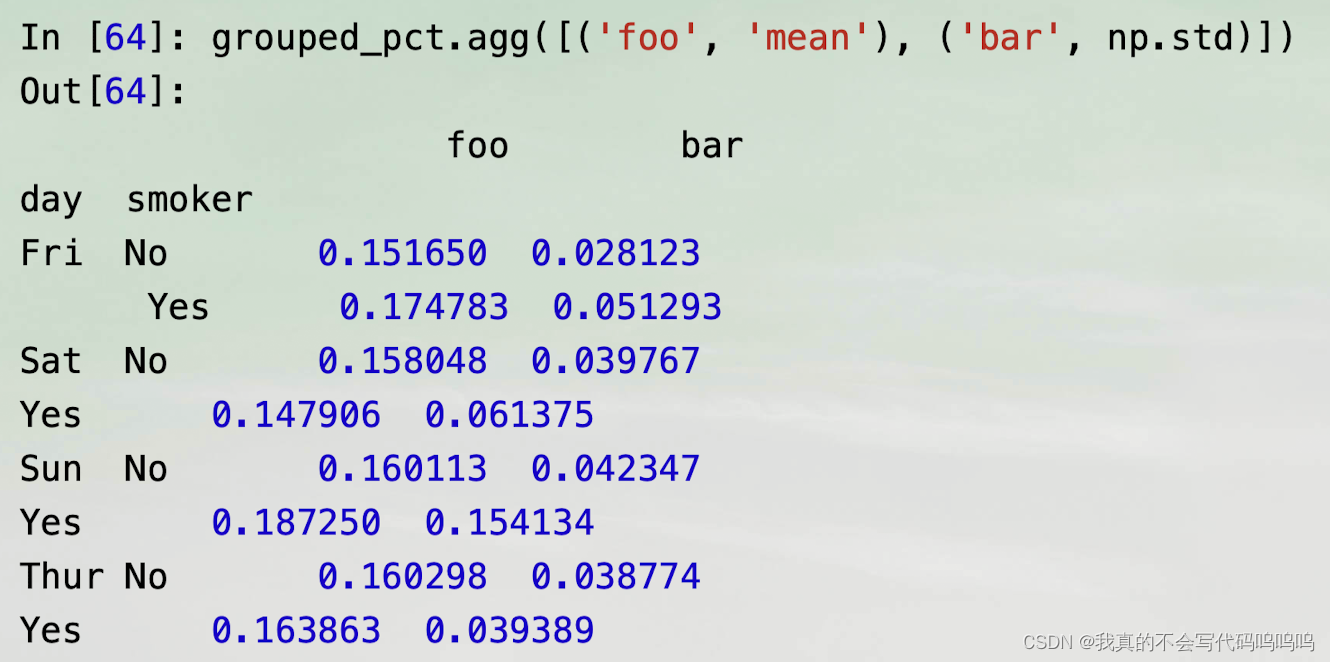
(2)不同函数应用不同列
可以指定应用到所有列上的函数列表或每一列上要应用的不同函数,
- 假设我们想要计算tip_pct列和total_bill列的三个相同的统计值(两列分别统计了三种统计值)
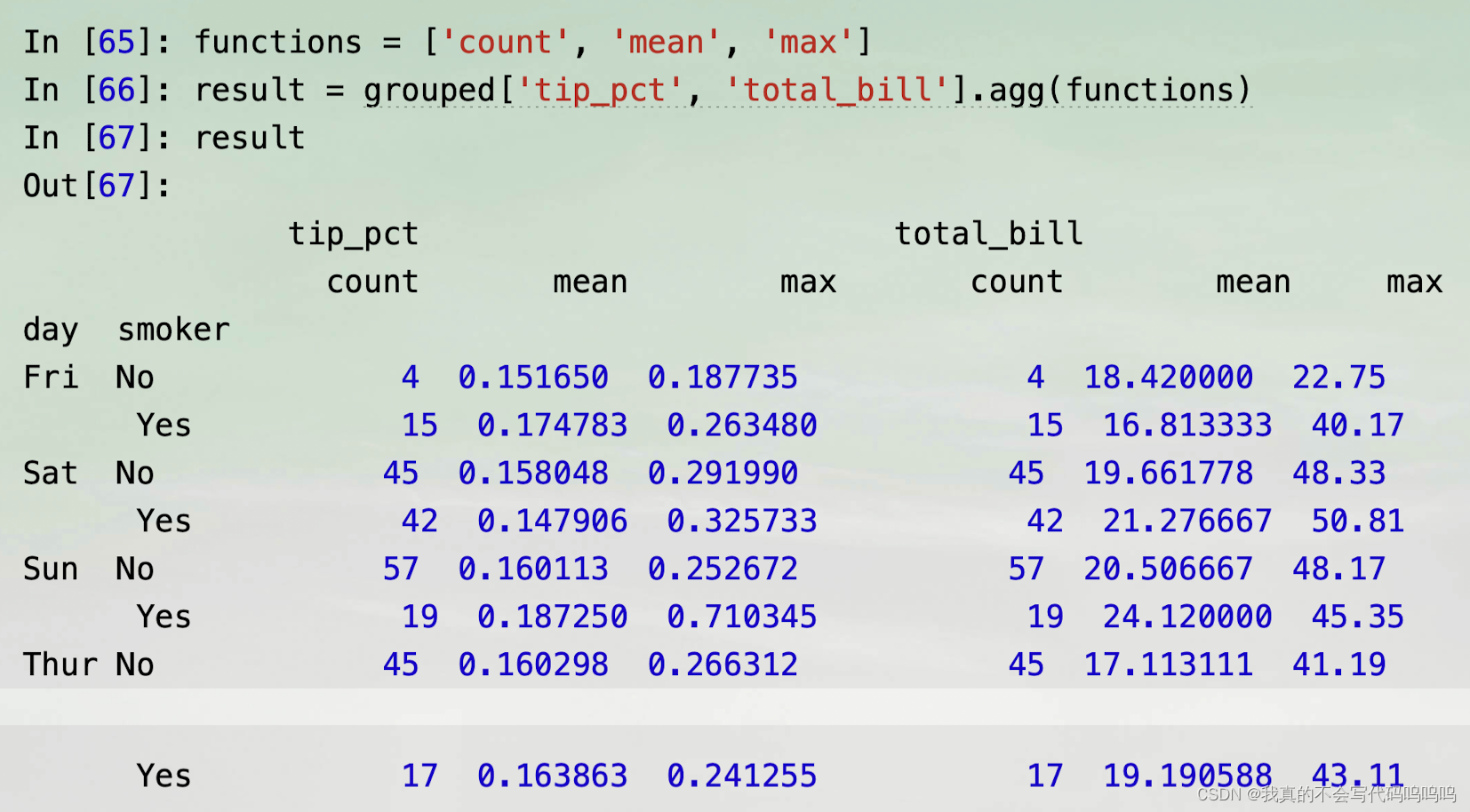
产生的DataFrame拥有分层列,与分别聚合每一列,再以列名作为keys参数使用concat将结果拼接在一起的结果相同:
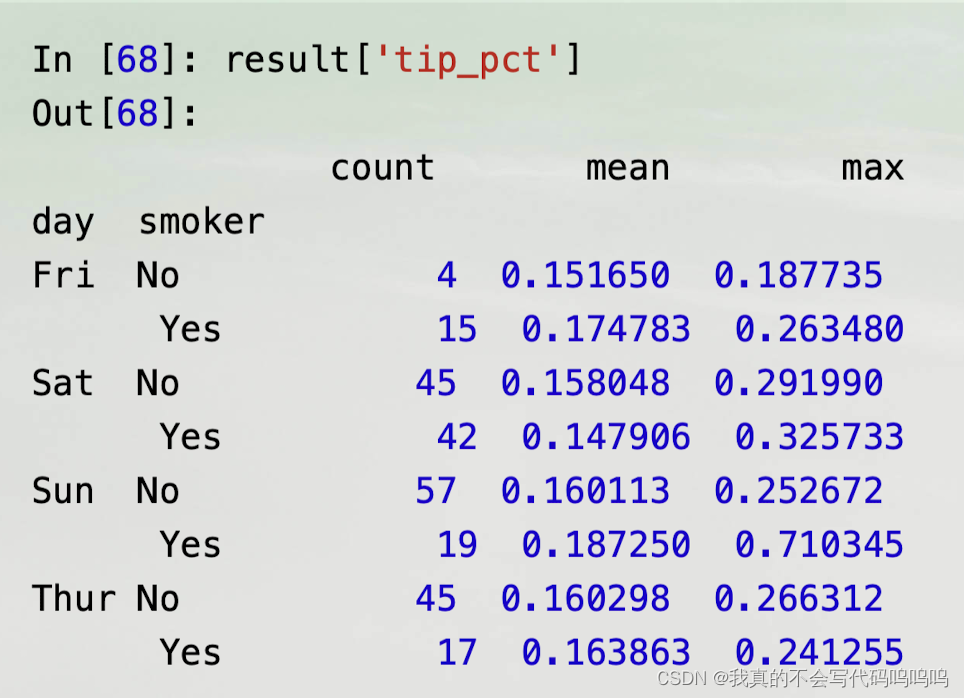
- 传递具有自定义名称的元组列表

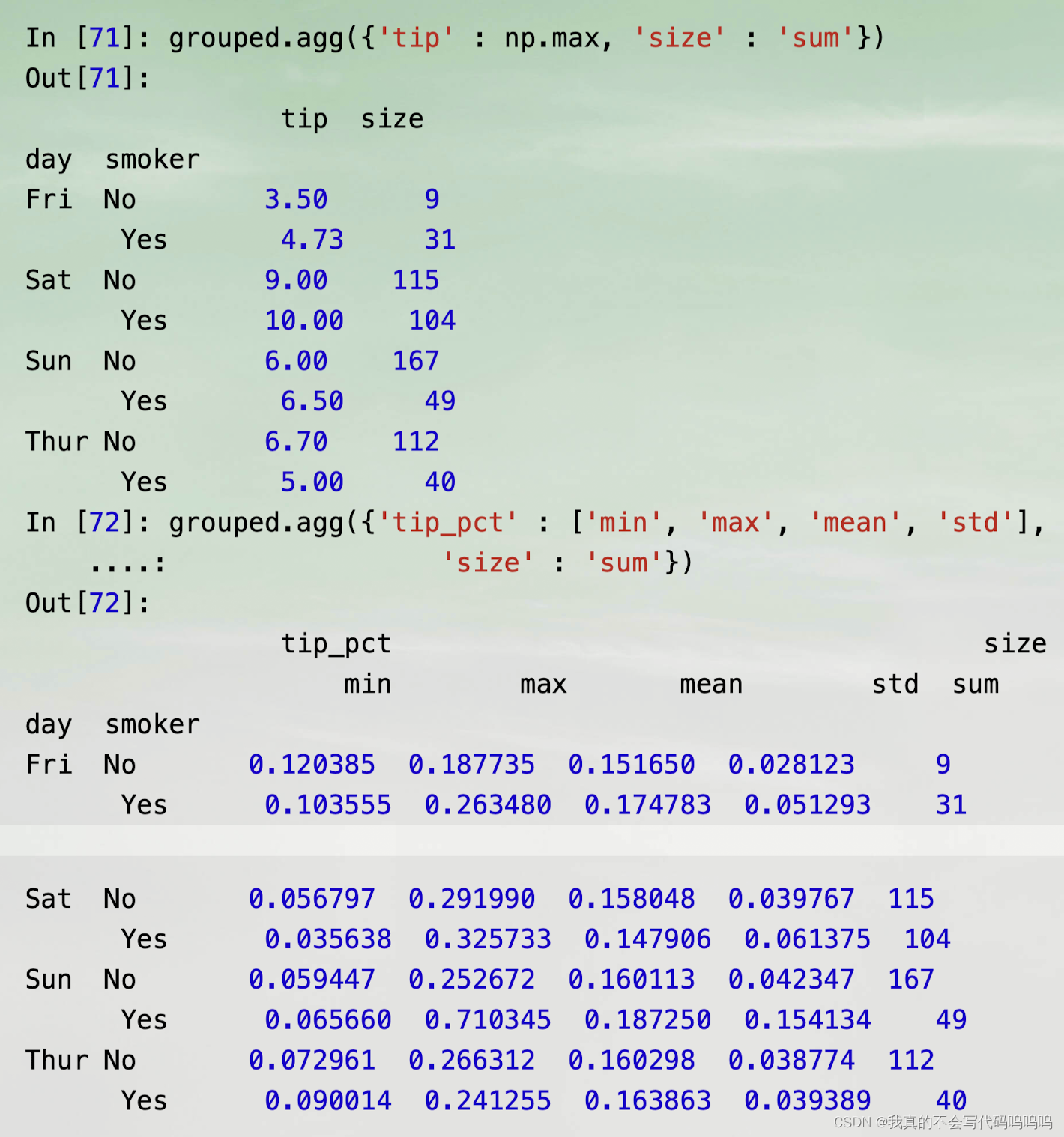
(3)不同函数应用一或多个列
- 需要将含有列名与函数对应关系的字典传递给agg:
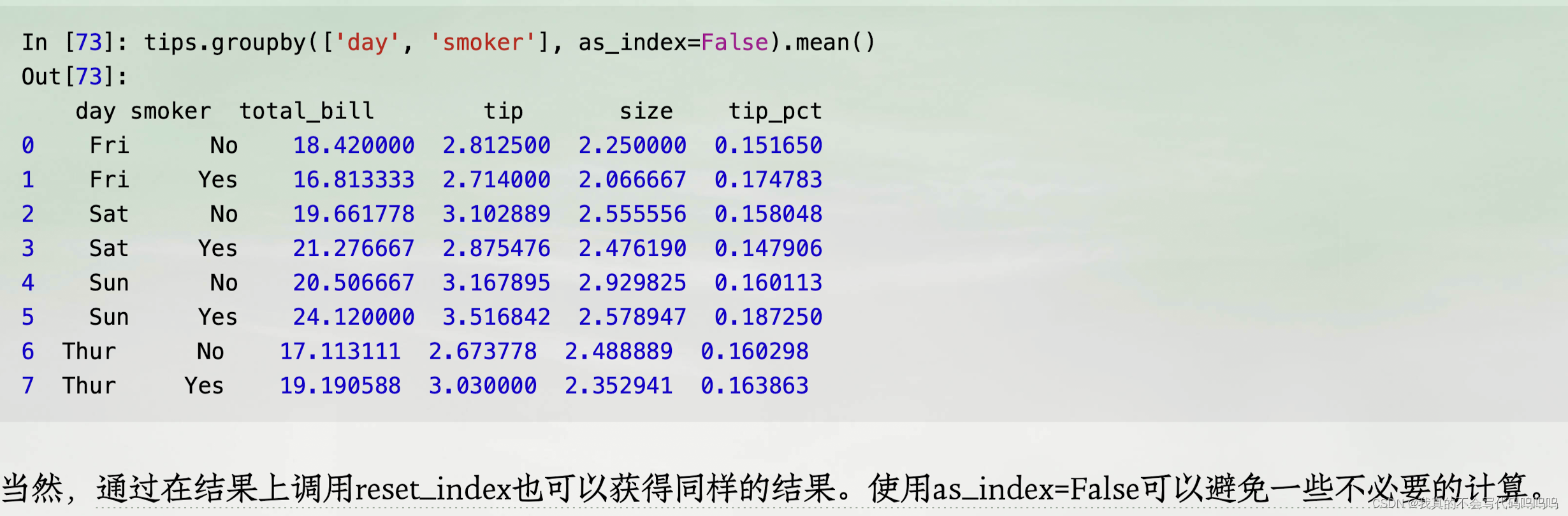
(4)返回不含行索引的数据

3、应用:通用拆分-应用-联合
apply将对象拆分成多块,然后在每一块上调用传递的函数,之后尝试将每一块拼接到一起。
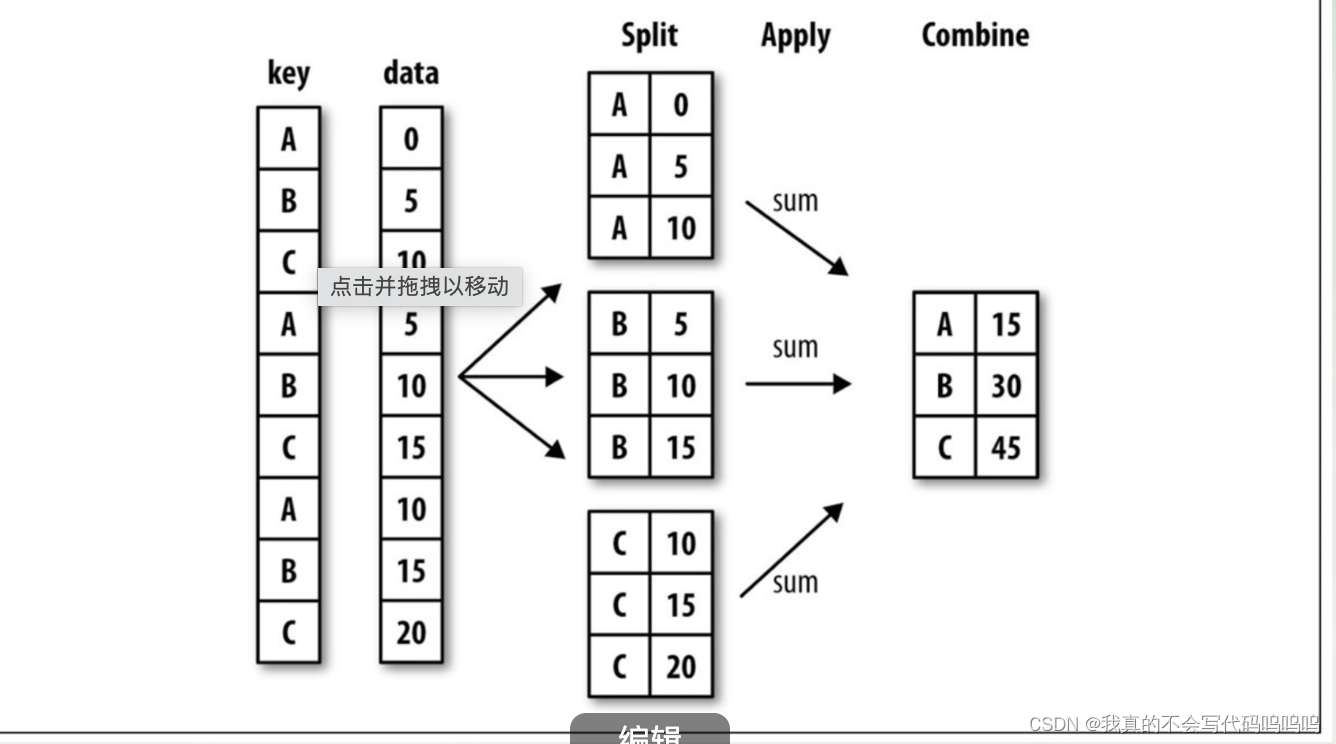
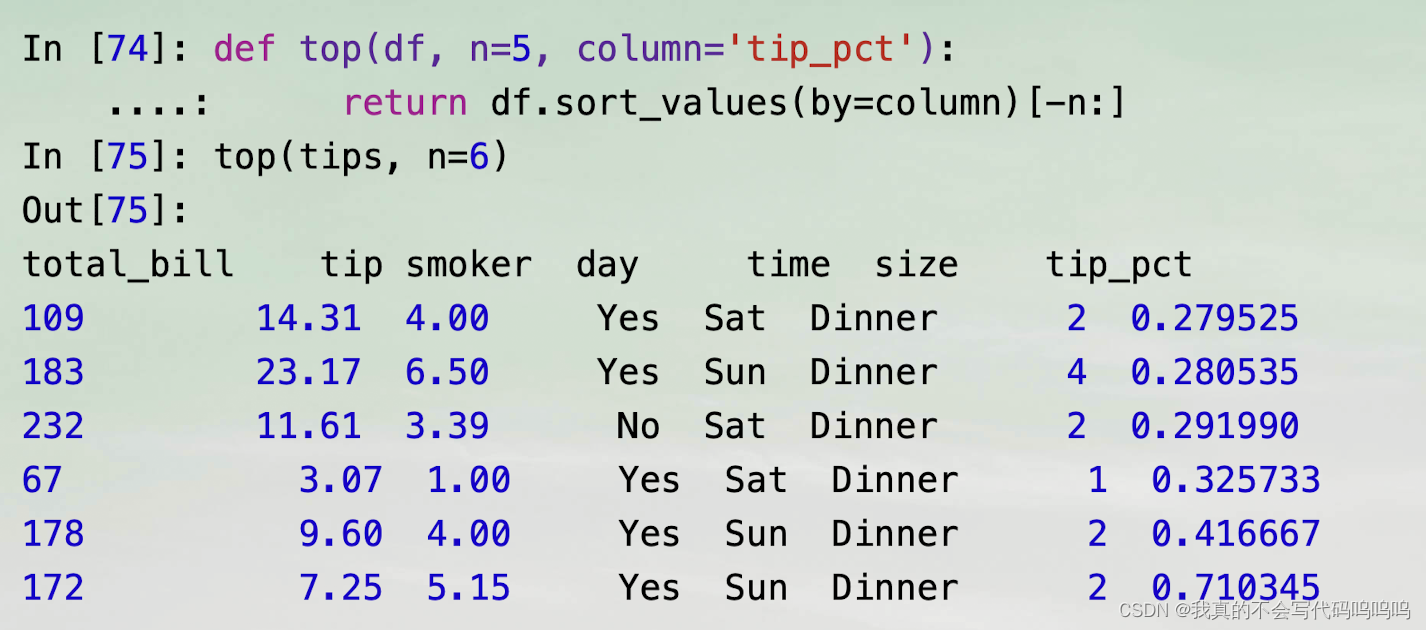
解析:

- 分组调用:top函数在DataFrame的每一行分组上被调用,之后使用pandas. concat将函数结果粘贴在一起,并使用分组名作为各组的标签。
- 因此结果包含一个分层索引,该分层索引的内部层级包含原DataFrame的索引值:
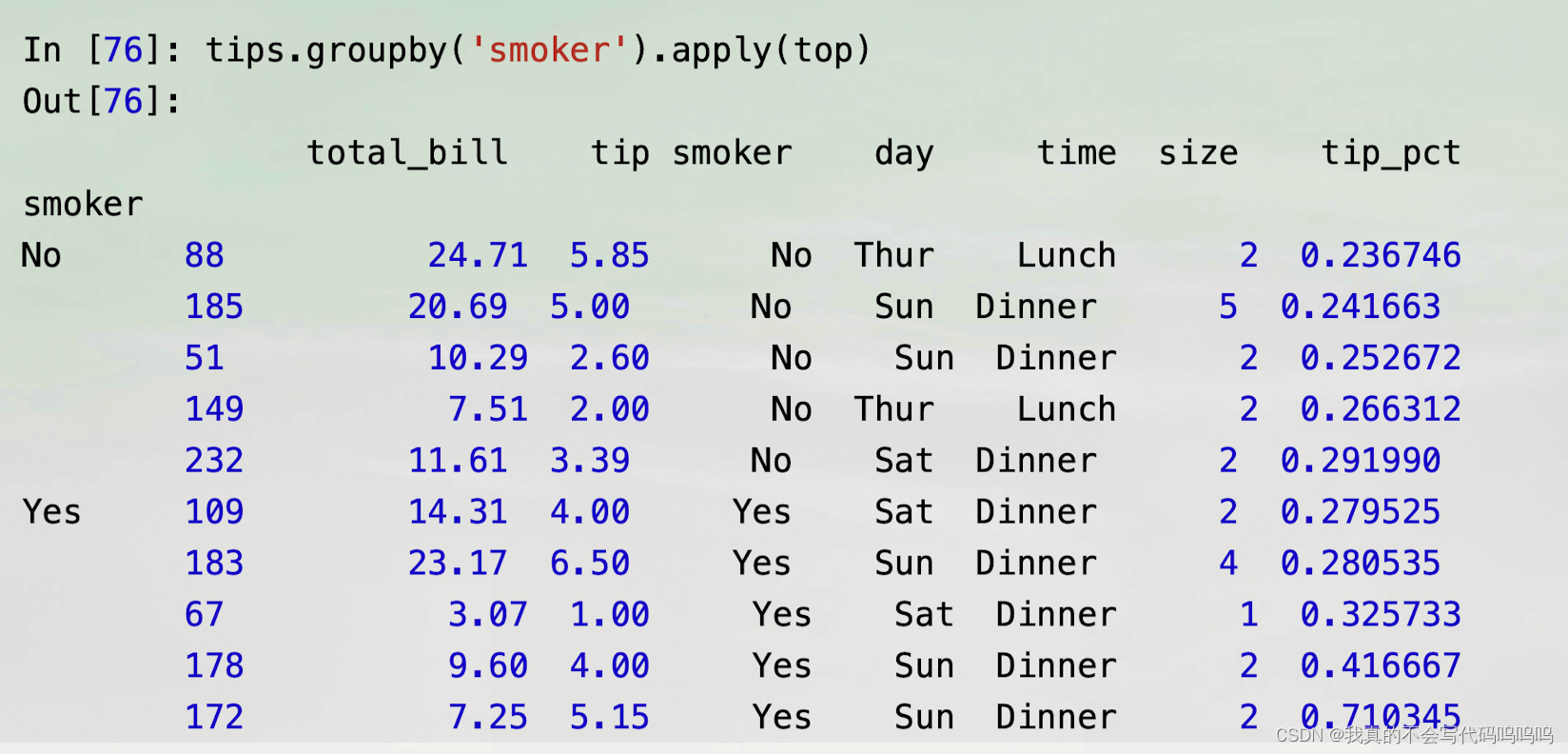
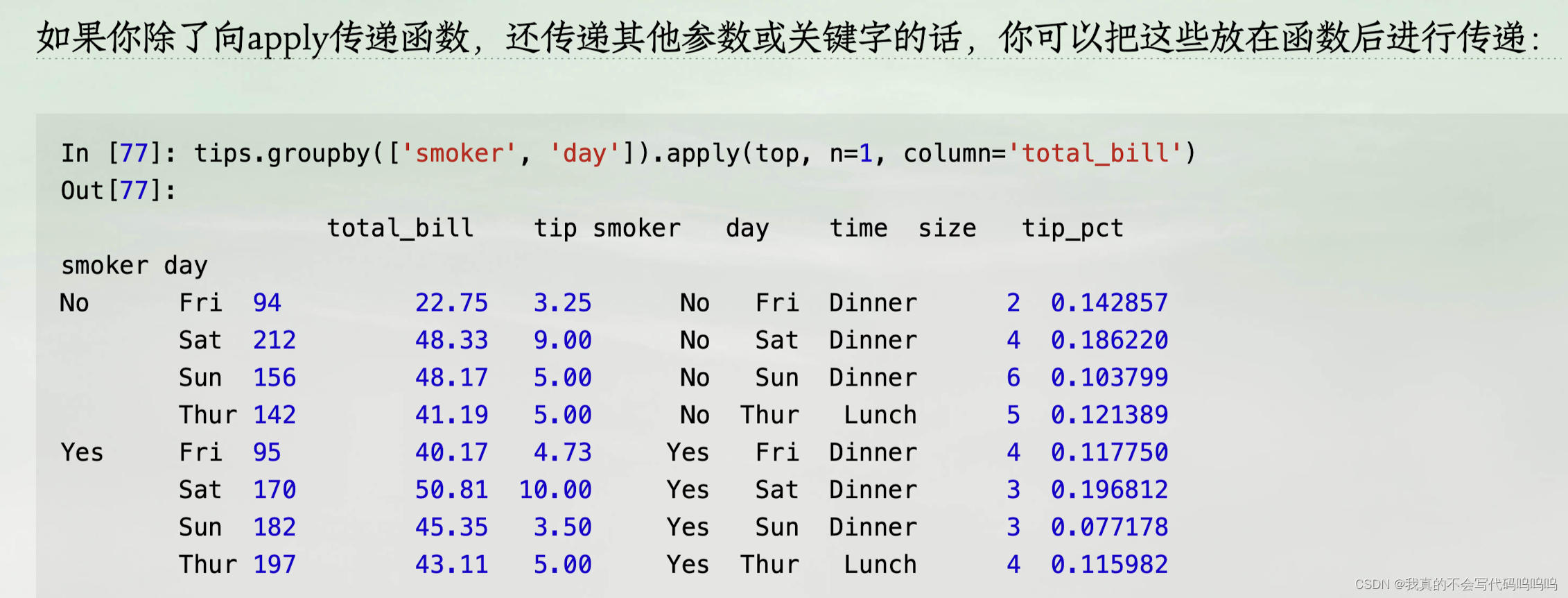
压缩分组键
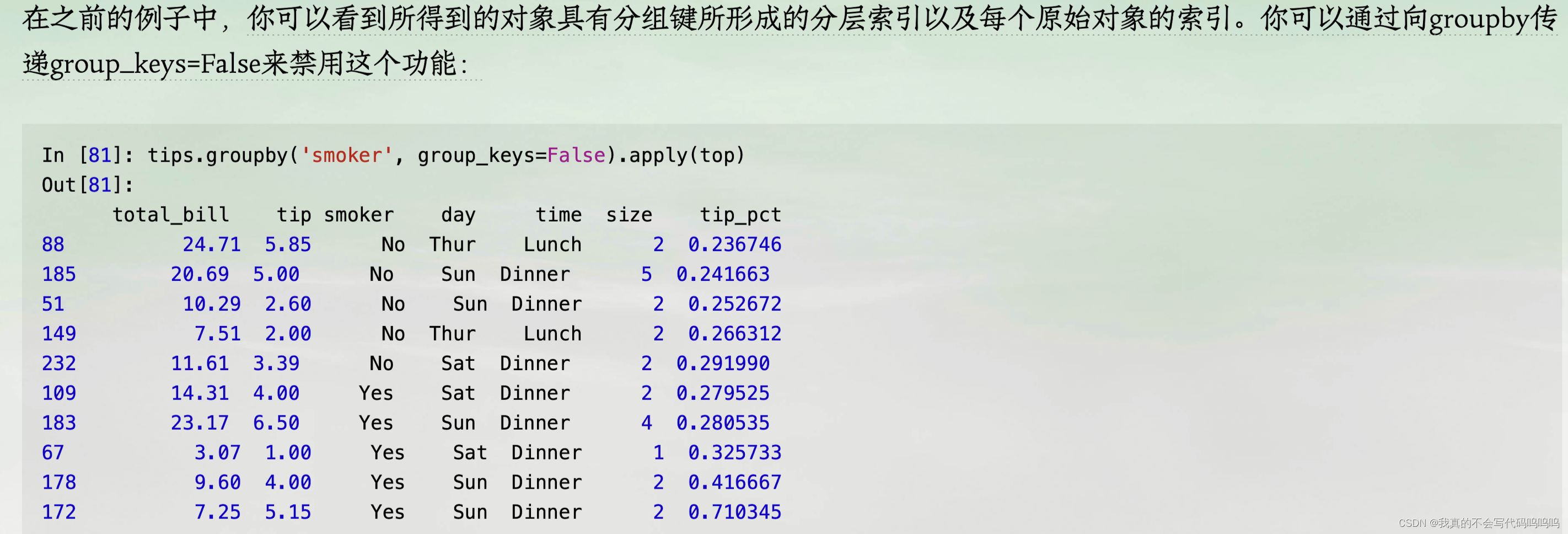
补充:



三、时间序列
1、日期和时间数据的类型及工具
(1)基础用法
- Python标准库包含了日期和时间数据的类型,也包括日历相关的功能
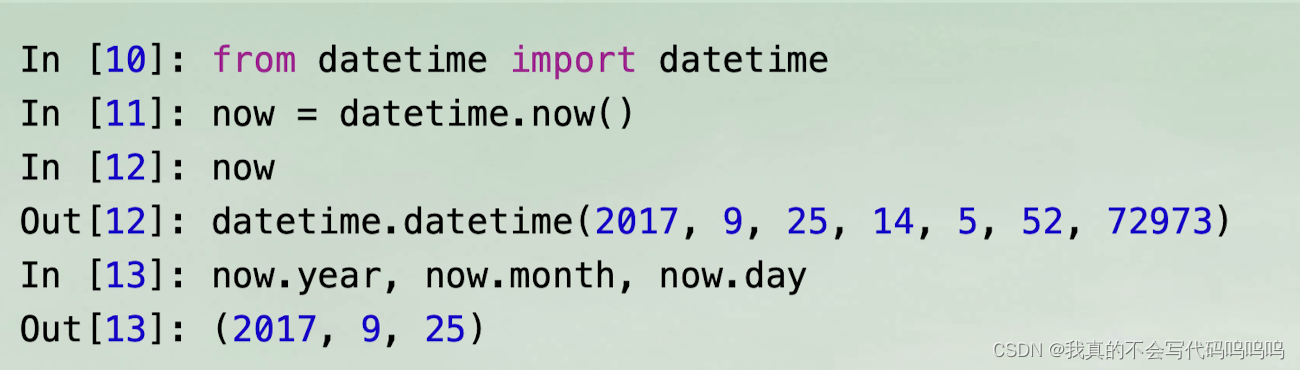
- timedelta表示两个datetime对象的时间差
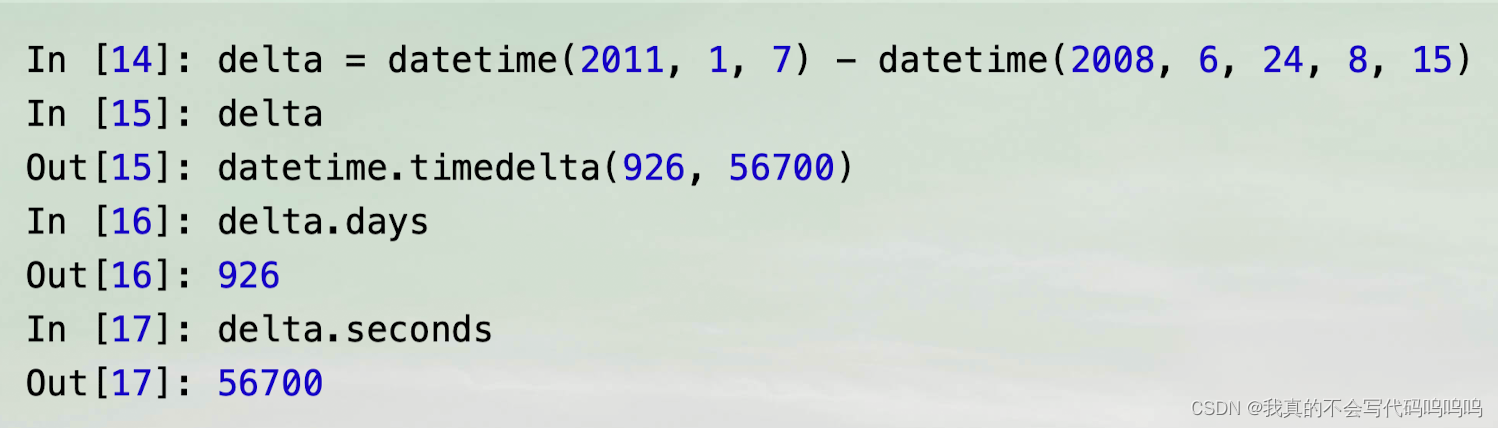

- 为一个datetime对象加上(或减去)一个timedelta或其整数倍,产生一个新的datetime对象
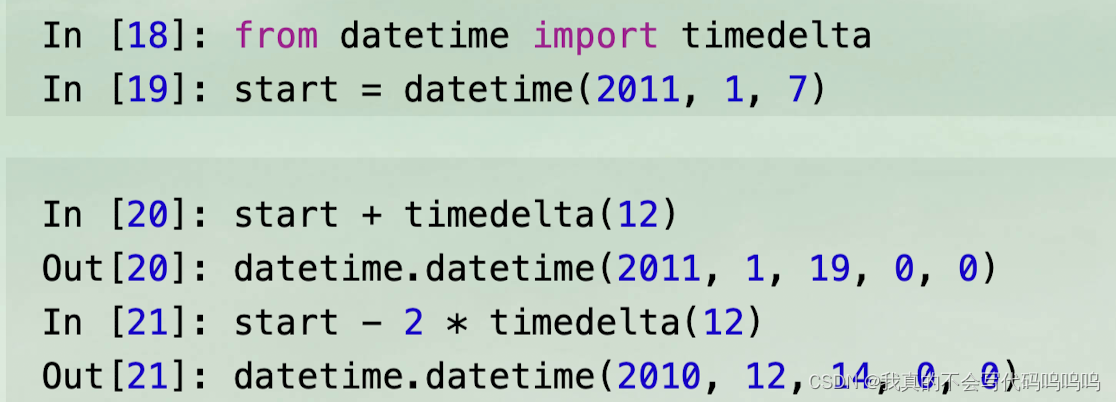

(2)字符串与datetime转换
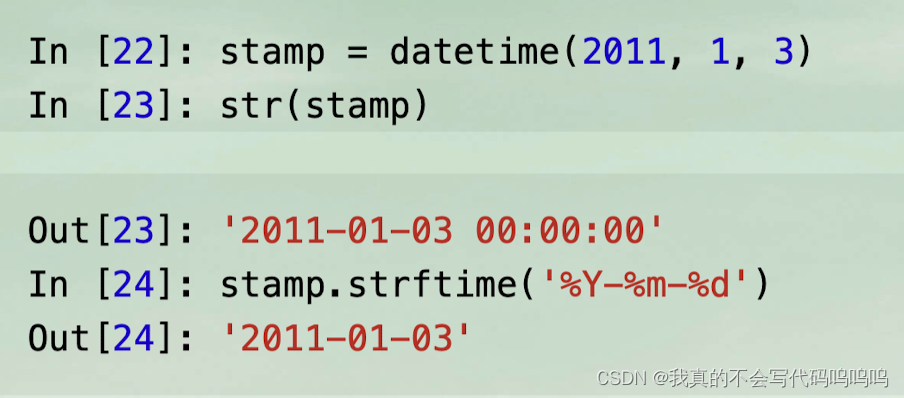
- 使用str方法或传递一个指定的格式给strftime方法,对datetime对象和pandas的Timestamp对象进行格式化

- datetime.srtptime和这些格式代码,将字符串转换日期
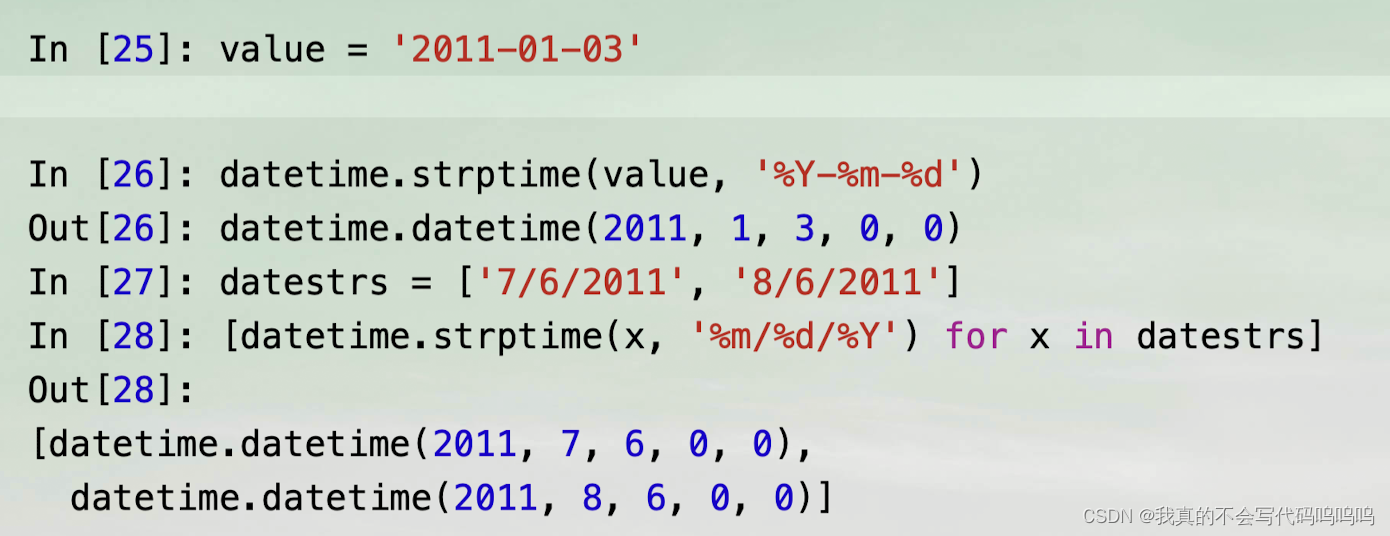
from _datetime import datetime
datestrs = ['7/6/2011', '8/6/2011']
#方法1:使用for循环输出
#for x in datestrs:
# y=datetime.strptime(x, '%m/%d/%Y')
# print(y)
#方法2:使用列表推导式输出
[print(datetime.strptime(x, '%m/%d/%Y')) for x in datestrs]
- datetime.strptime是在已知格式的情况下转换日期的好方式。然而,每次都必须编写一个格式代码可能有点烦人,特别是对于通用日期格式。
- 在这种情况下,你可以使用第三方dateutil包的parser.parse方法(这个包在安装pandas时已经自动安装):
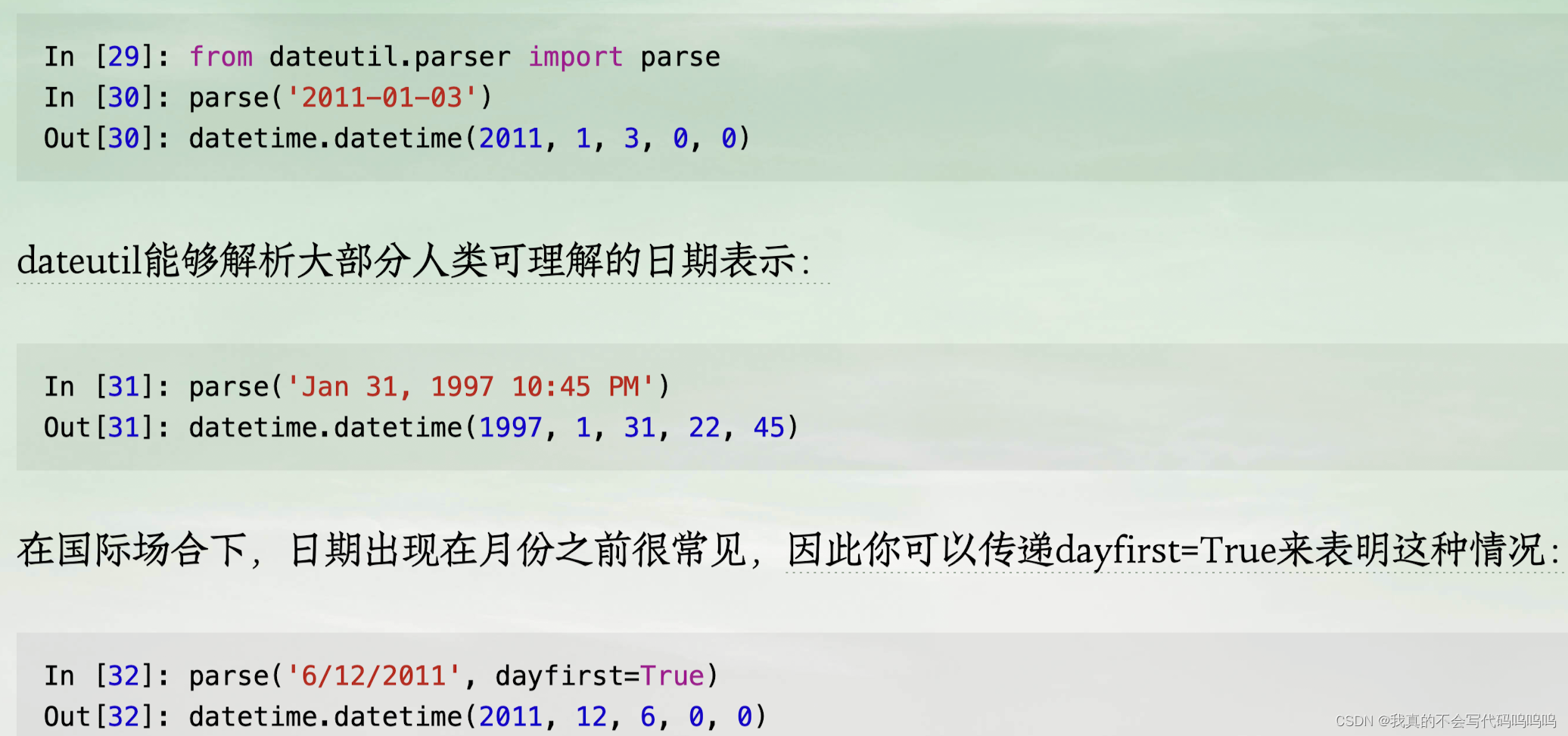
- to_datetime方法:转换很多不同的日期表示格式
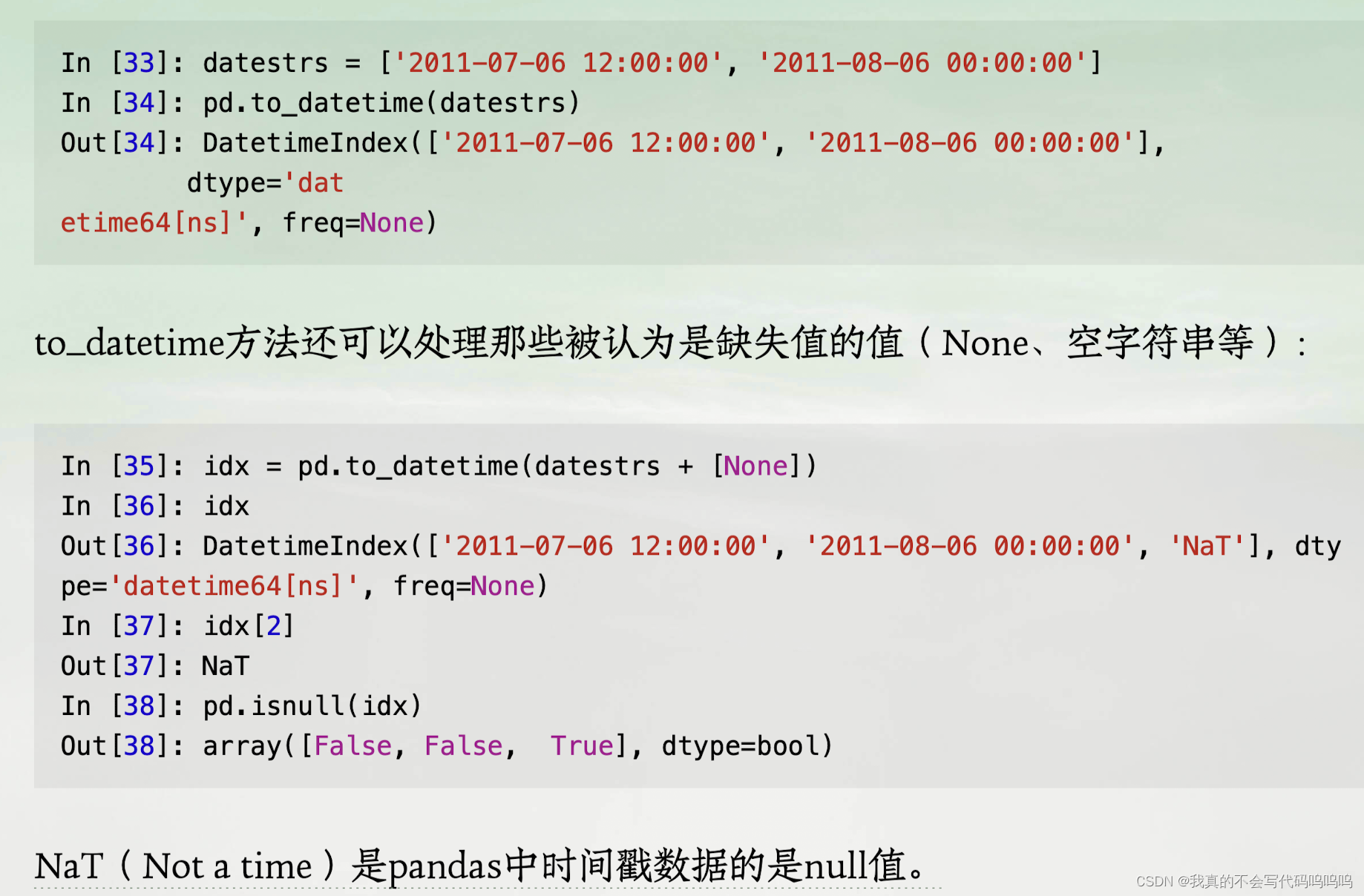
datetime对象还拥有许多其他国家或语言系统的本地化格式选项

2、时间序列基础
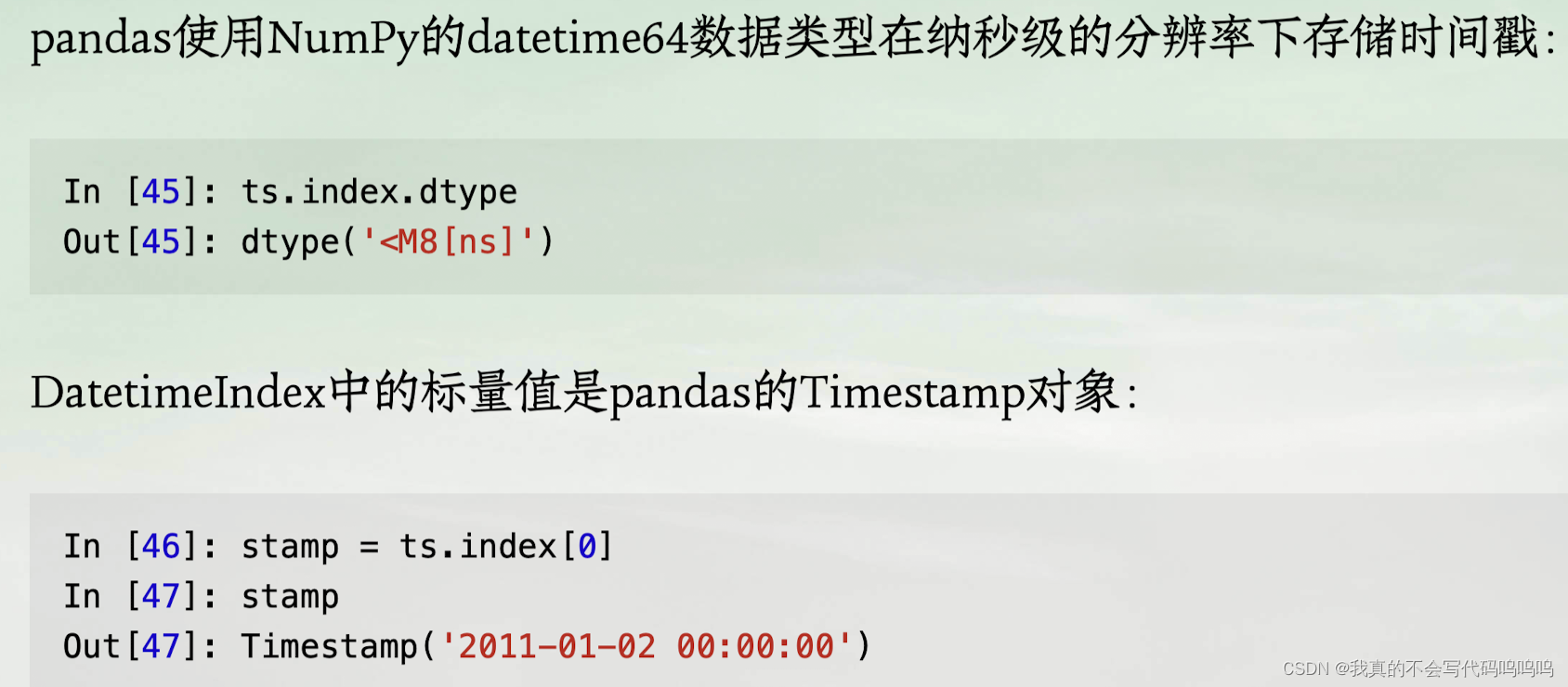
pandas中的基础时间序列种类是由时间戳索引的Series,在pandas外部则通常表示为Python字符串或datetime对象:
(1)基础时间序列对象
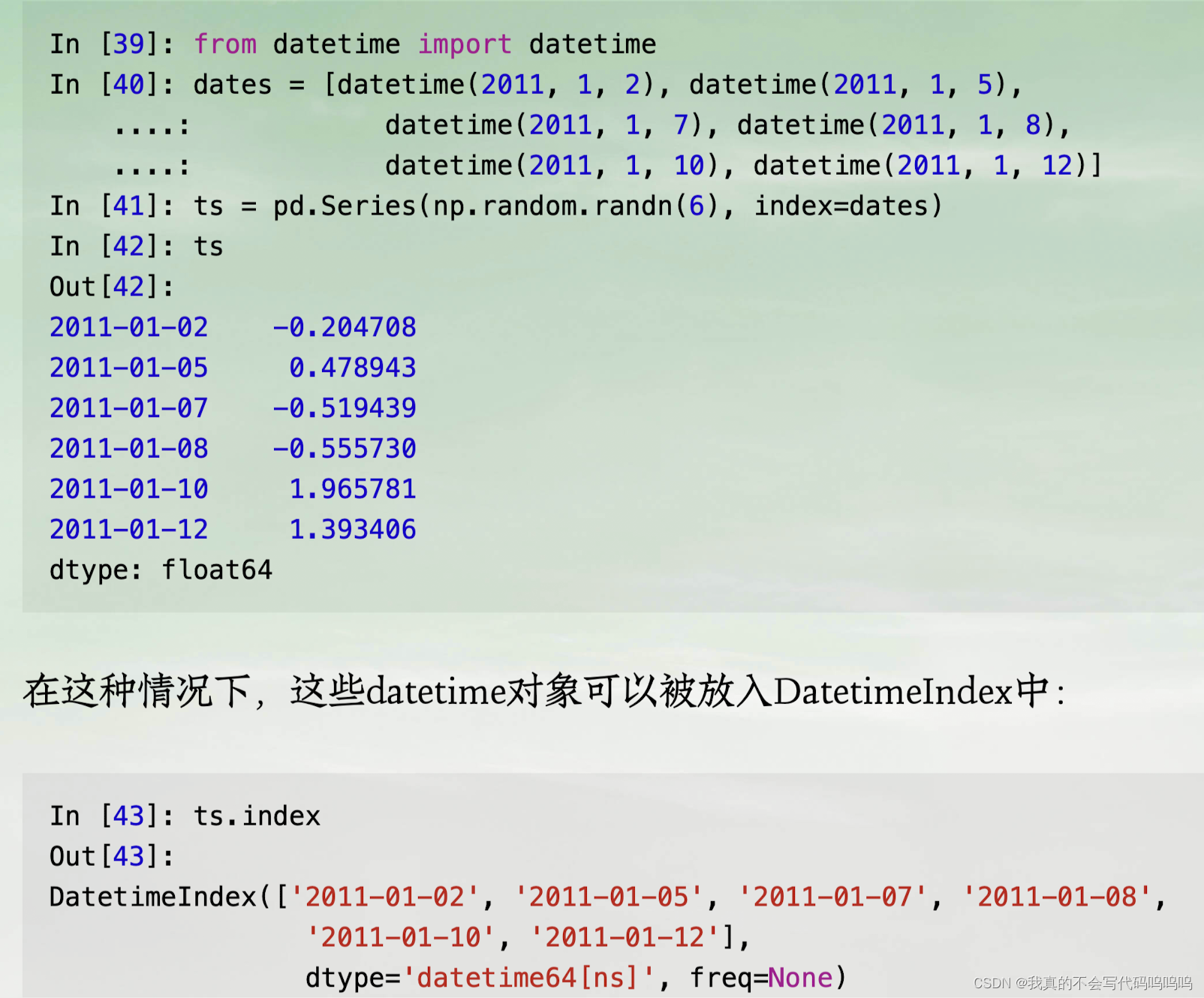
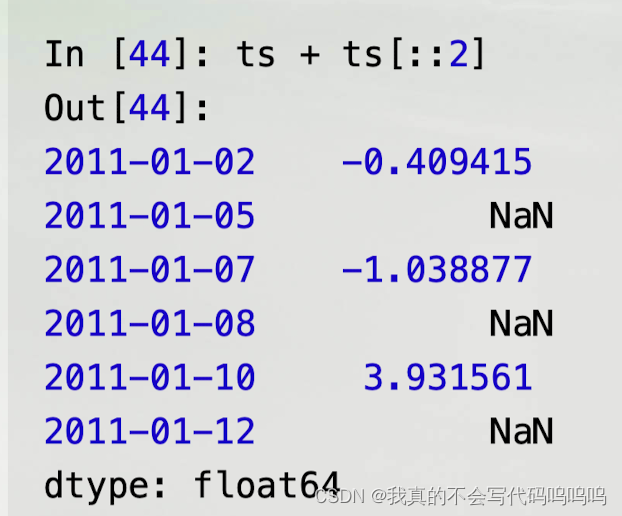
- ts[::2]会将ts中每隔一个的元素选择出。
(2)索引、选择、子集
- 获取索引值,根据索引获取值

- 传递一个能解释为日期的字符串(直接传入索引值)

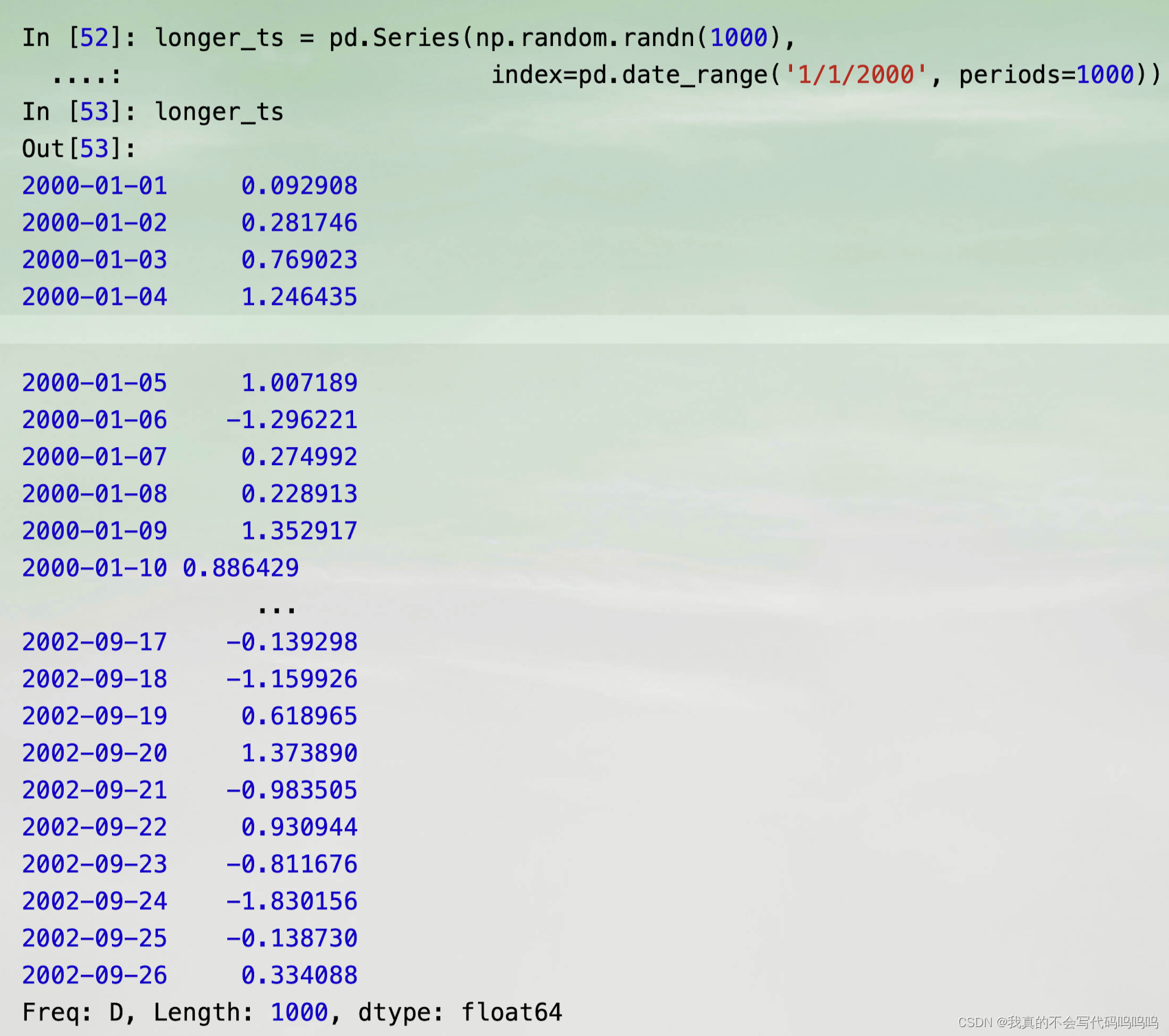
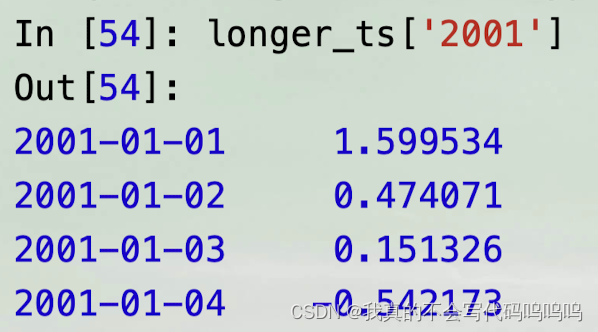
- 对一个长的时间序列,可以传递一个年份或一个年份和月份来轻松地选择数据的切片:
基础数据
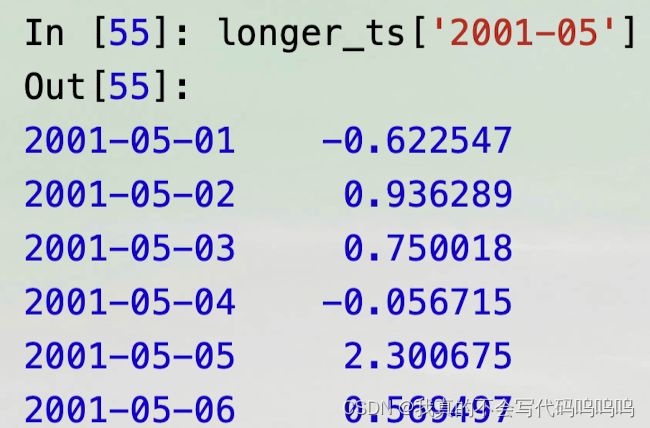

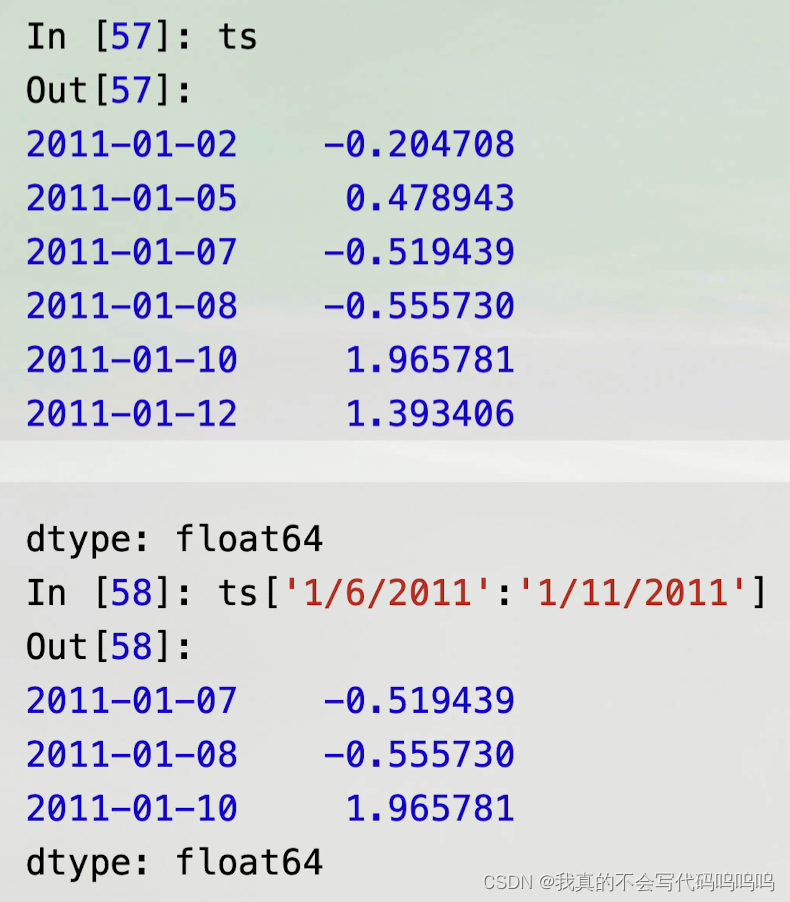
- 有一个等价实例方法,truncate,它可以在两个日期间对Series进行切片:

(3)含有重复索引的时间序列


对上面的Series进行索引,结果是标量值还是Series切片取决于是否有时间戳是重复的:
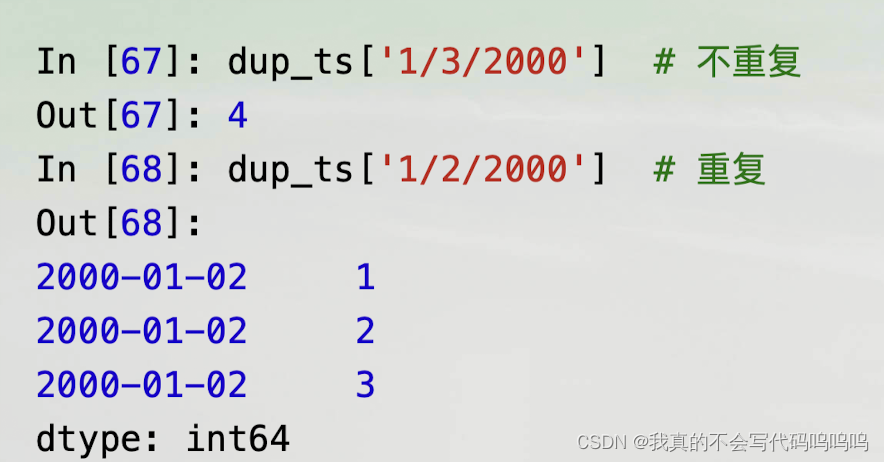
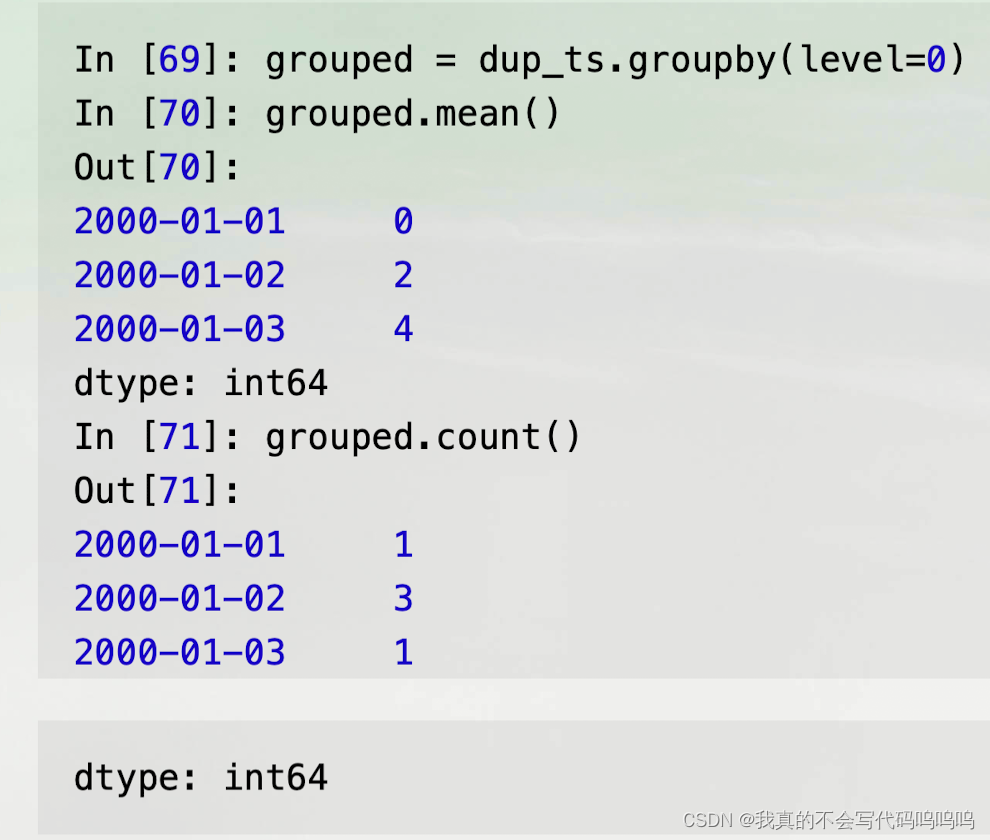
- 假设你想要聚合含有非唯一时间戳的数据。一种方式就是使用groupby并传递level=0:
3、日期范围、频率和移位
经常有需要处理固定频率的场景,例如每日的、每月的或每15分钟,这意味着我们甚至需要在必要的时候向时间序列中引入缺失值。
pandas拥有一整套标准的时间序列频率和工具用于重新采样、推断频率以及生成固定频率的数据范围。
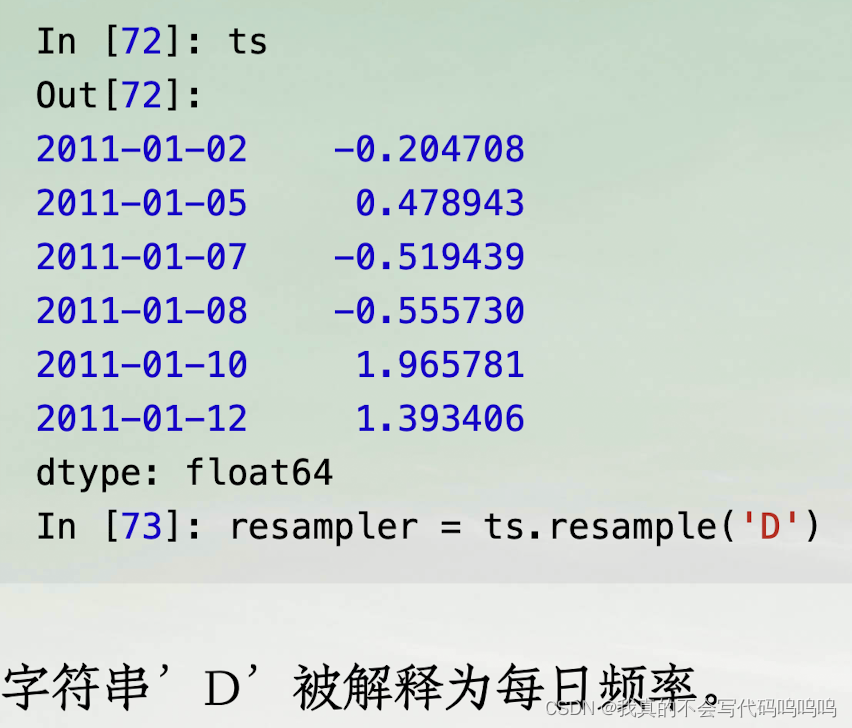
(1)resample方法
- 将样本时间序列转换为固定的每日频率数据:
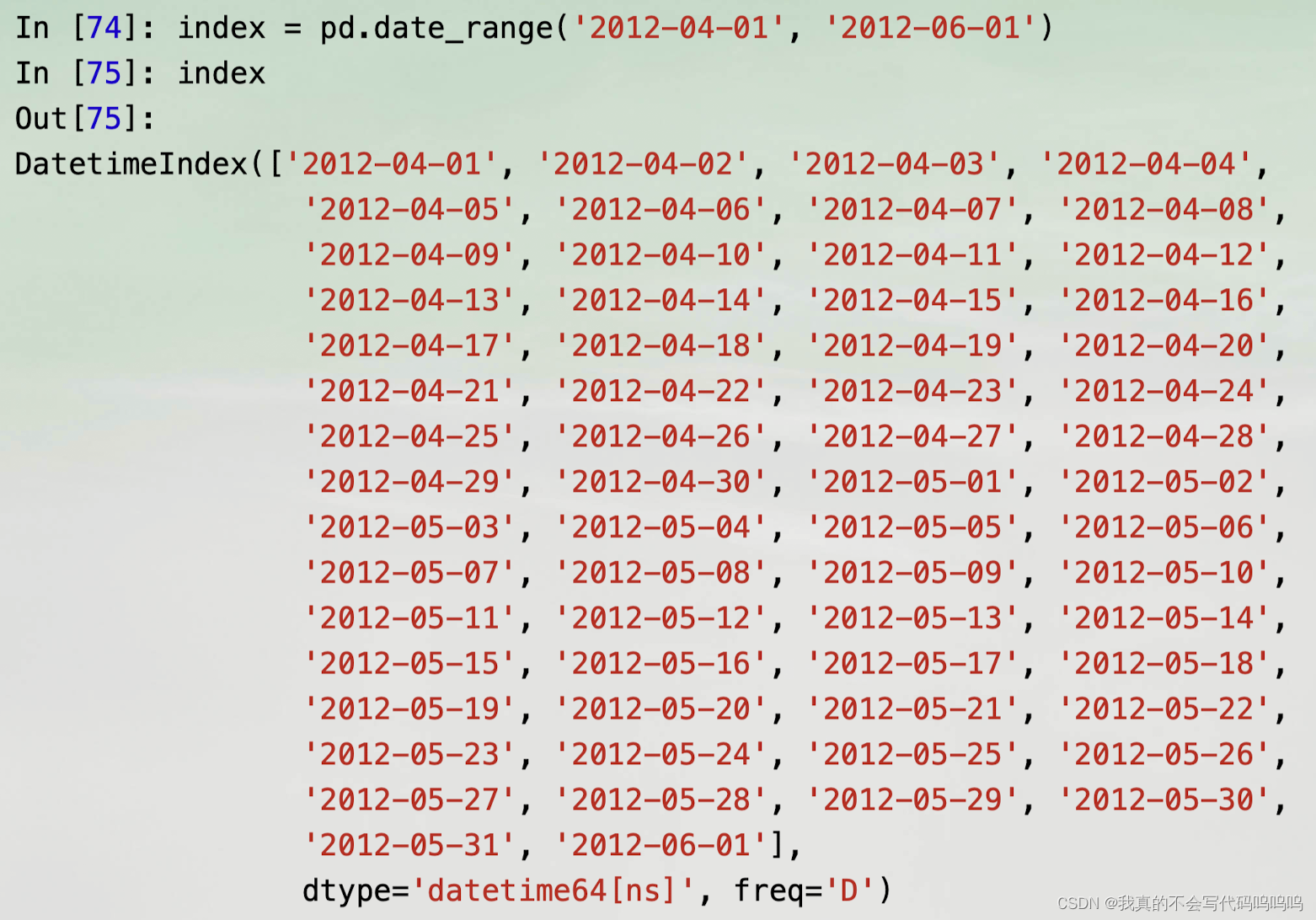
(2)生成日期范围date_range
-
pandas.date_range是用于根据特定频率生成指定长度的DatetimeIndex
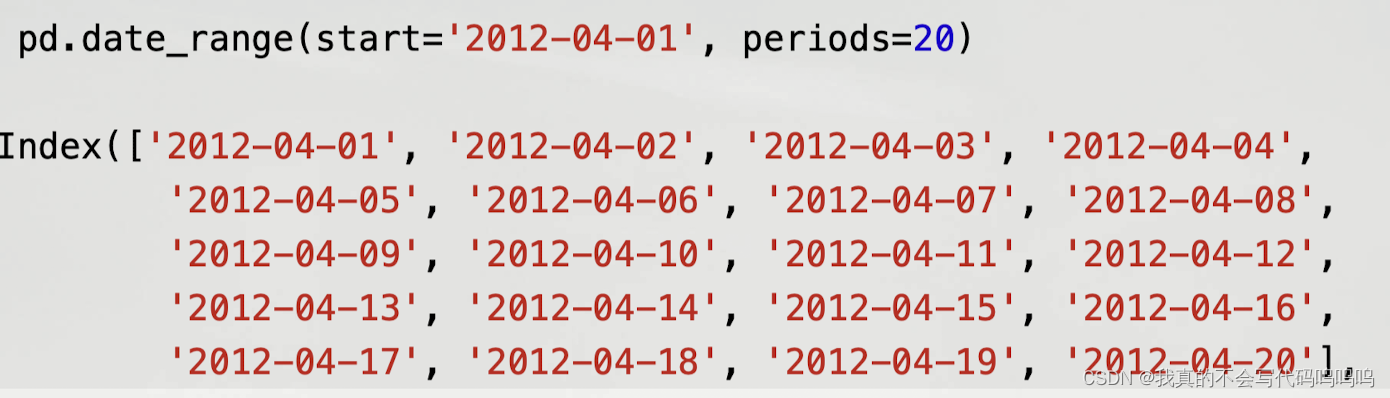
- 如果你只传递一个起始或结尾日期,你必须传递一个用于生成范围的数字:
![]()
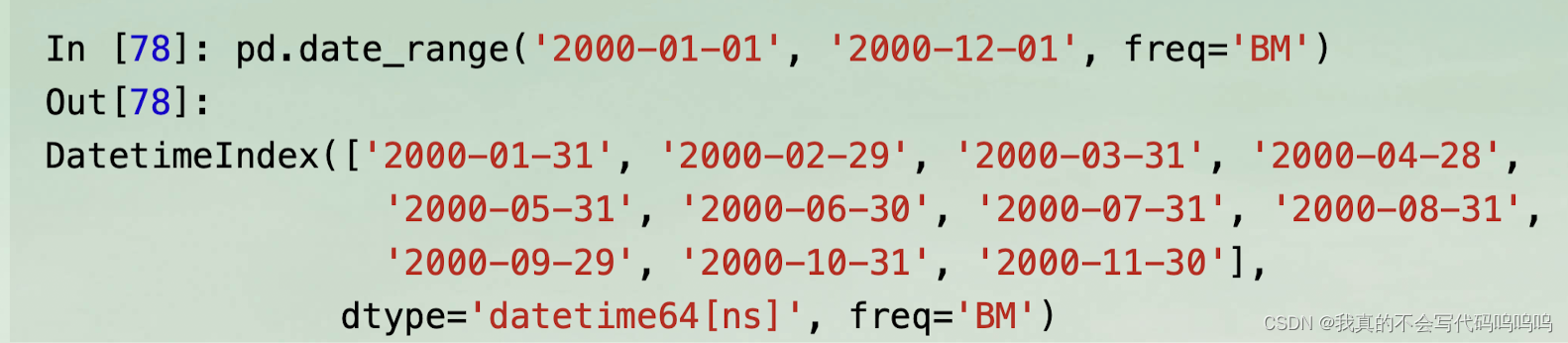
(3)时间频率参数
- 传递’freq’频率,只有落在或在日期范围内的日期会被包括


- date_range保留开始或结束时间戳的时间(如果有的话)
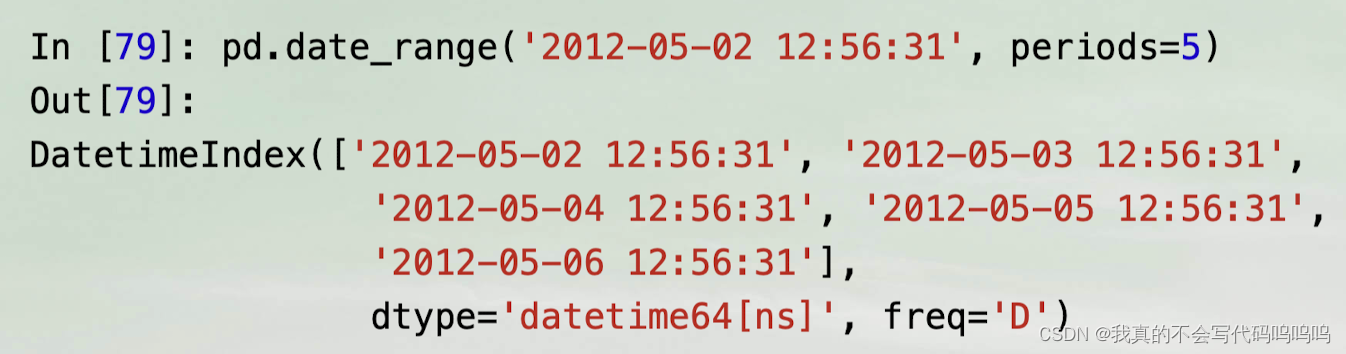
- 生成的是标准化为零点的时间戳。有一个normalize选项可以实现这个功能:
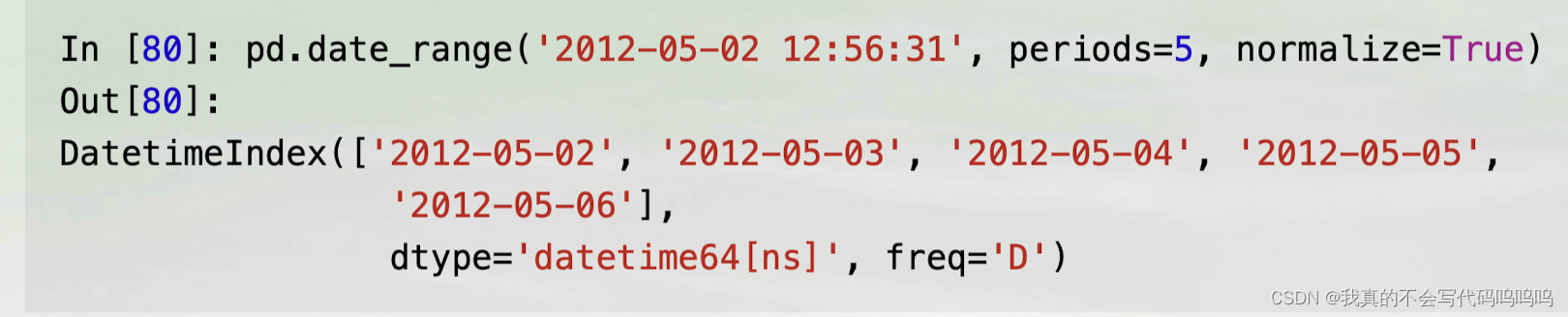
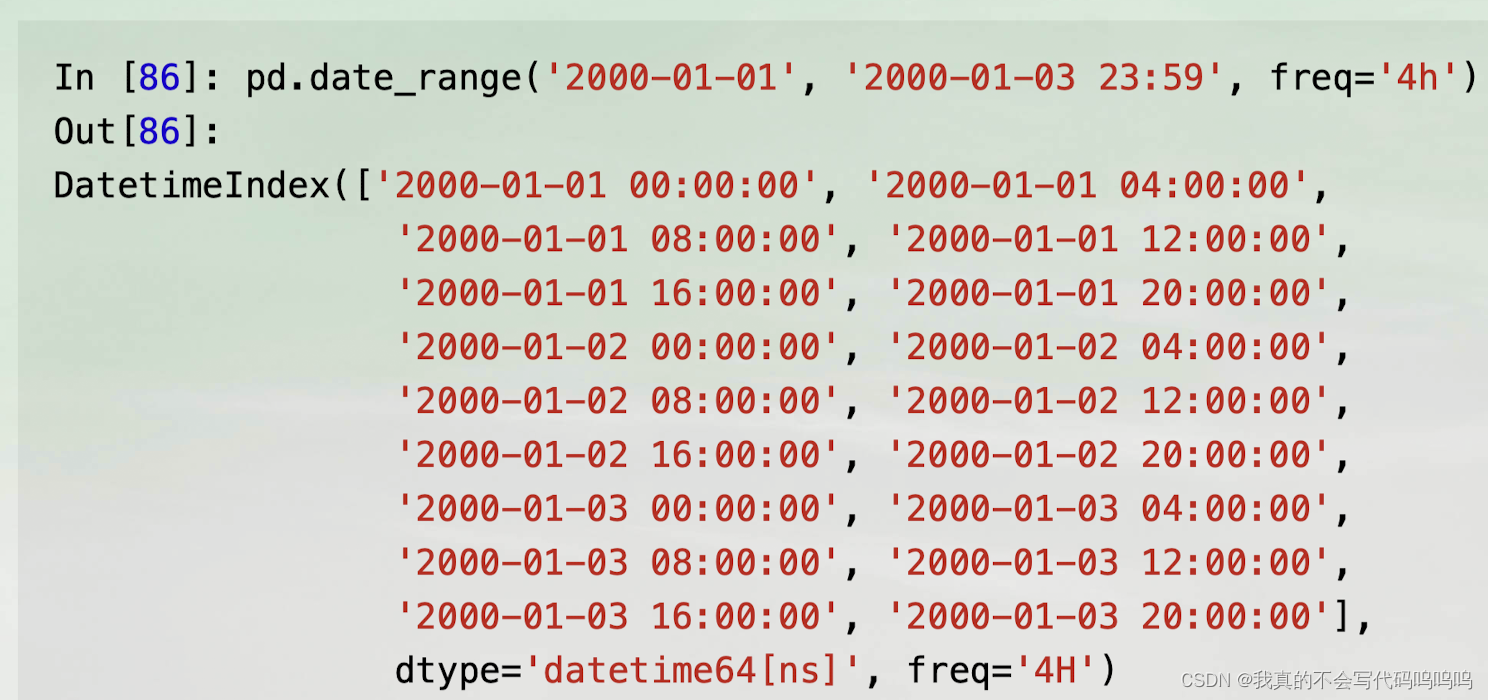
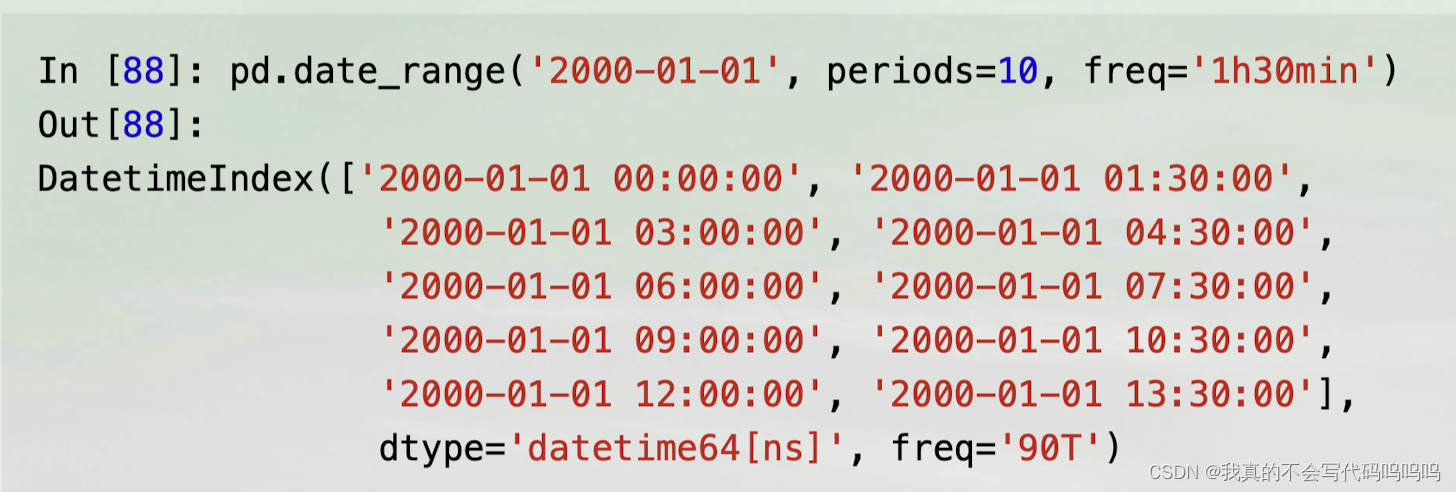
(4)频率和日期偏置
- pandas中的频率是由基础频率和倍数组成的。基础频率通常会有字符串别名,例如’M'代表每月,'H’代表每小时。
- 对于每个基础频率,都有一个对象可以被用于定义日期偏置。例如,每小时的频率可以使用Hour类来表示:
from pandas.tseries.offsets import Hour, Minute- 在基础频率前放一个整数就可以生成倍数:
(5)月中某星期的日期
月中某星期"(week of month )的日期是一个有用的频率类,以’WOM’开始。它允许你可以获取每月第三个星期五这样的日期: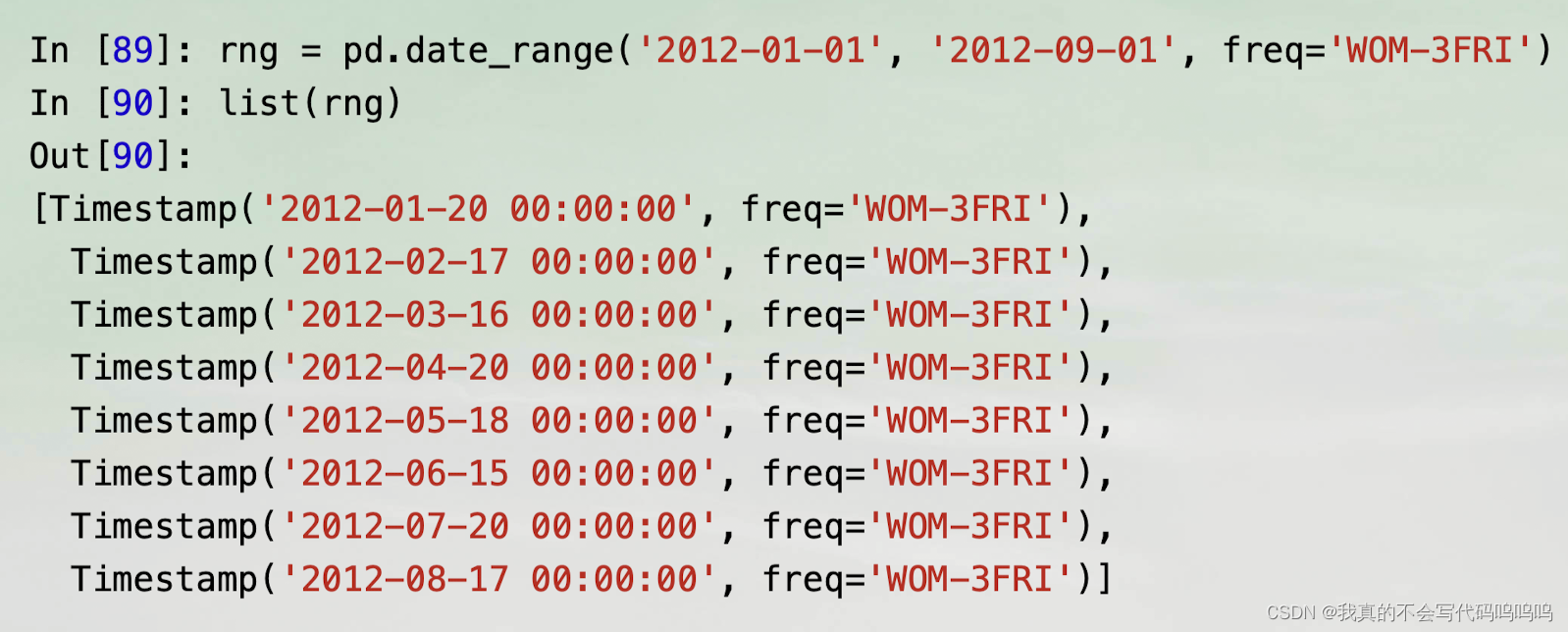
(6)移位(前向和后向)日期
- "移位"是指将日期按时间向前移动或向后移动;
- Series和DataFrame都有一个shift方法用于进行简单的前向或后向移位,而不改变索引;
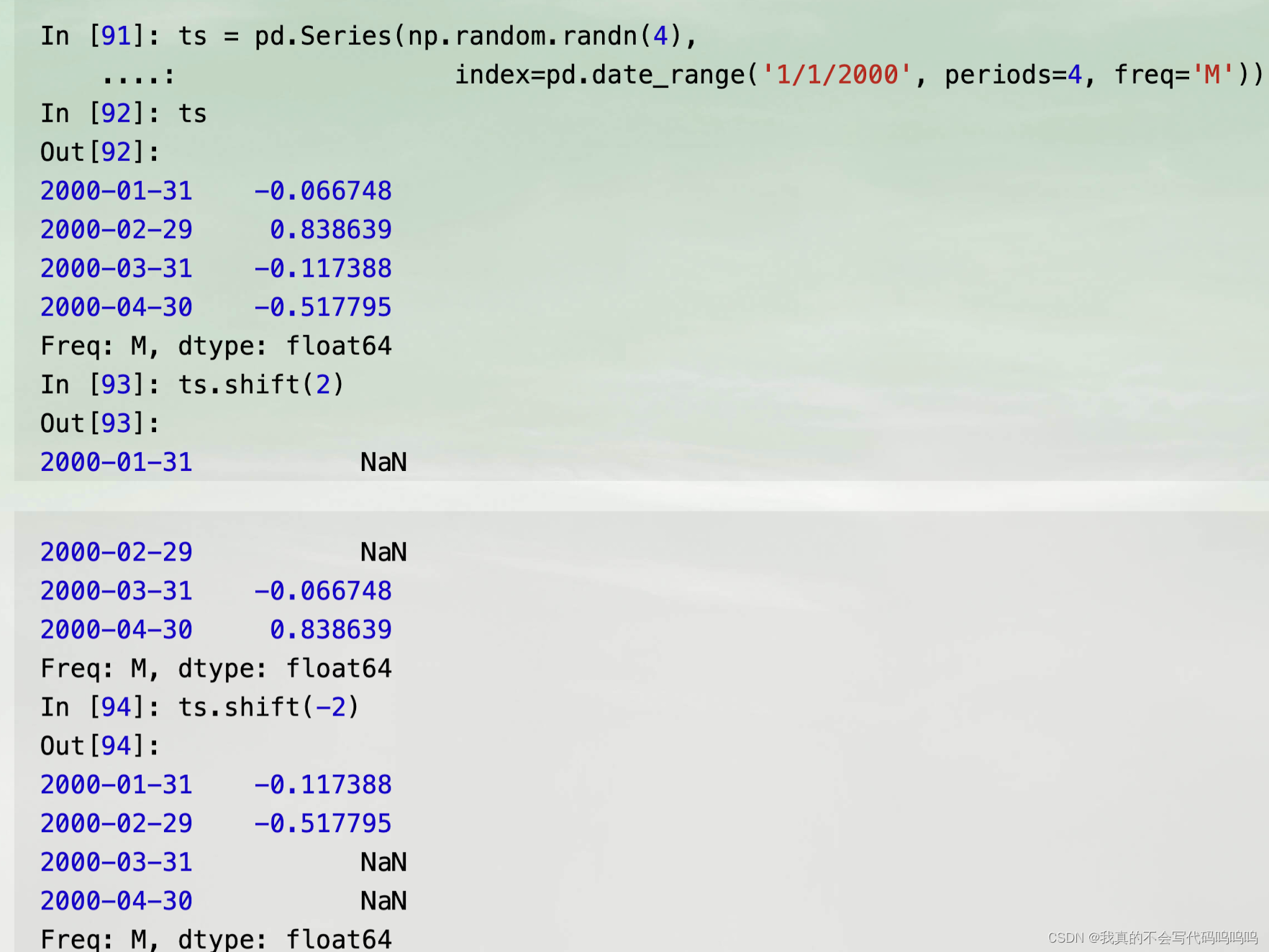

由于简单移位并不改变索引,一些数据会被丢弃。因此,如果频率是已知的,则可以将频率传递给shift来推移时间戳而不是简单的数据:

(7)使用偏置进行移位日期
- 如果你添加了一个锚定偏置量,比如MonthEnd,根据频率规则,第一个增量会将日期“前滚”到下一个日期
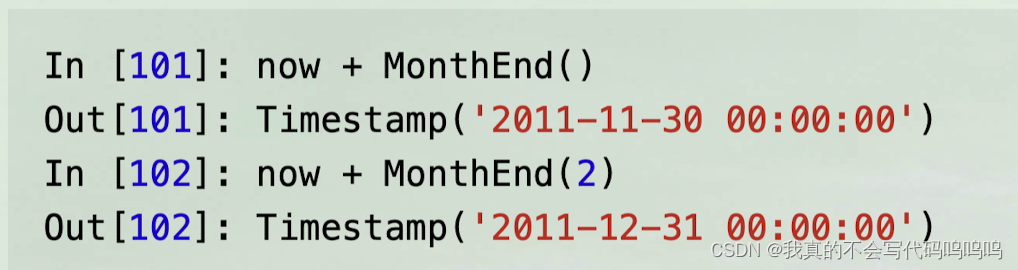
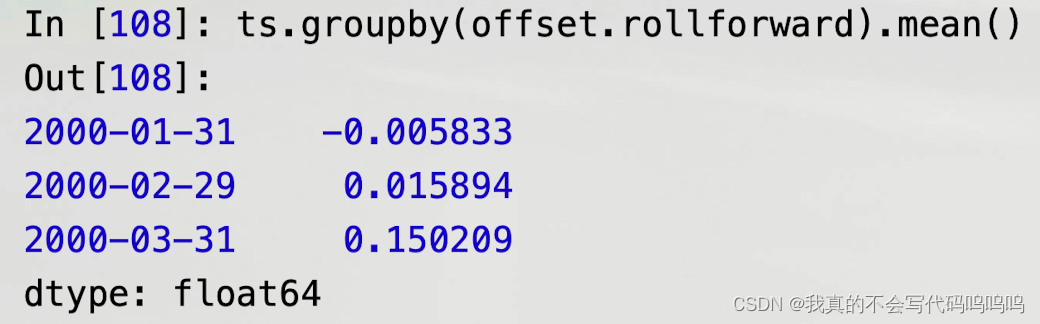
- rollforward和rollback

- groupby函数
4、时区处理
(1)时间区间和区间算术
- 时间区间表示的是时间范围,比如一些天、一些月、一些季度或者是一些年。
- Period类:2007 表示时间段的起始年份,A-DEC 表示时间段的频率,即按年结束于12月份。
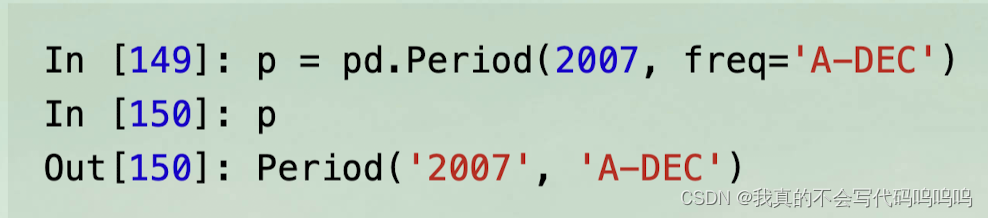
- 在时间段上增加或减去整数可以方便地根据它们的频率进行移位。

- 如果两个区间拥有相同的频率,则它们的差是它们之间的单位数:

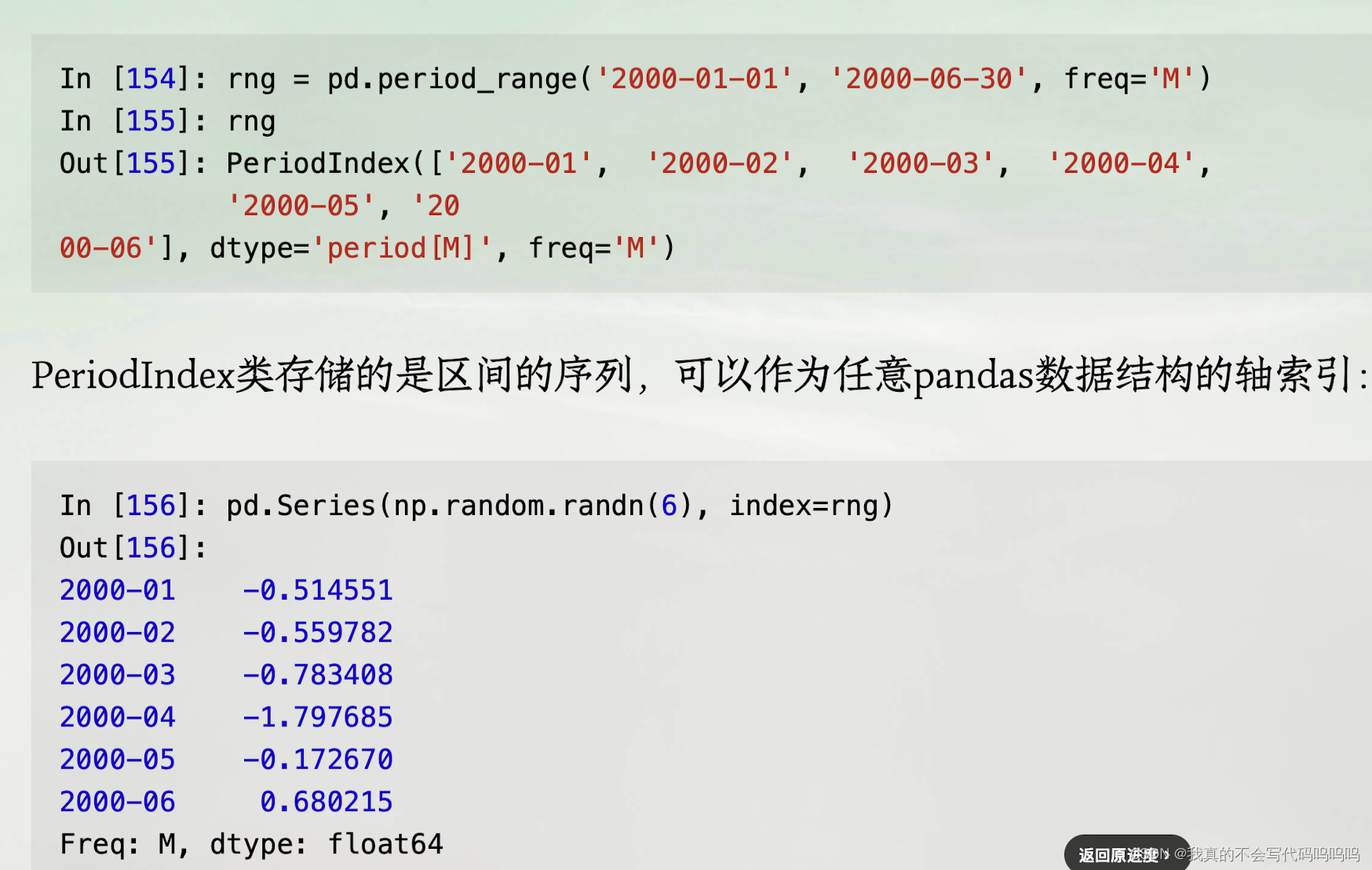
(2)period_range函数
-
构造规则区间序列:

5、区间频率转换
(1)asfreq频率转化
- 使用asfreq可以将区间和PeriodIndex对象转换为其他的频率。

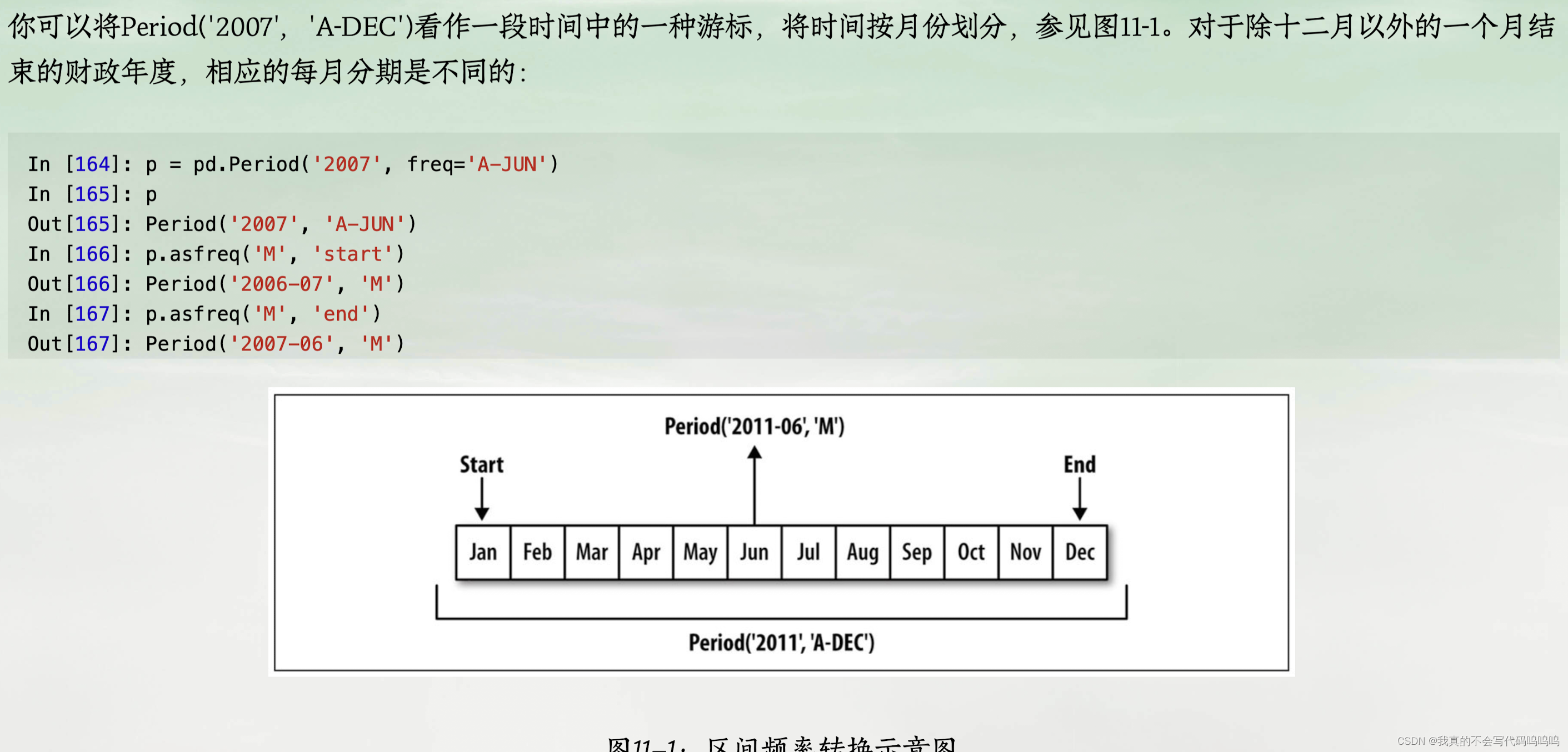



(2)季度区间频率

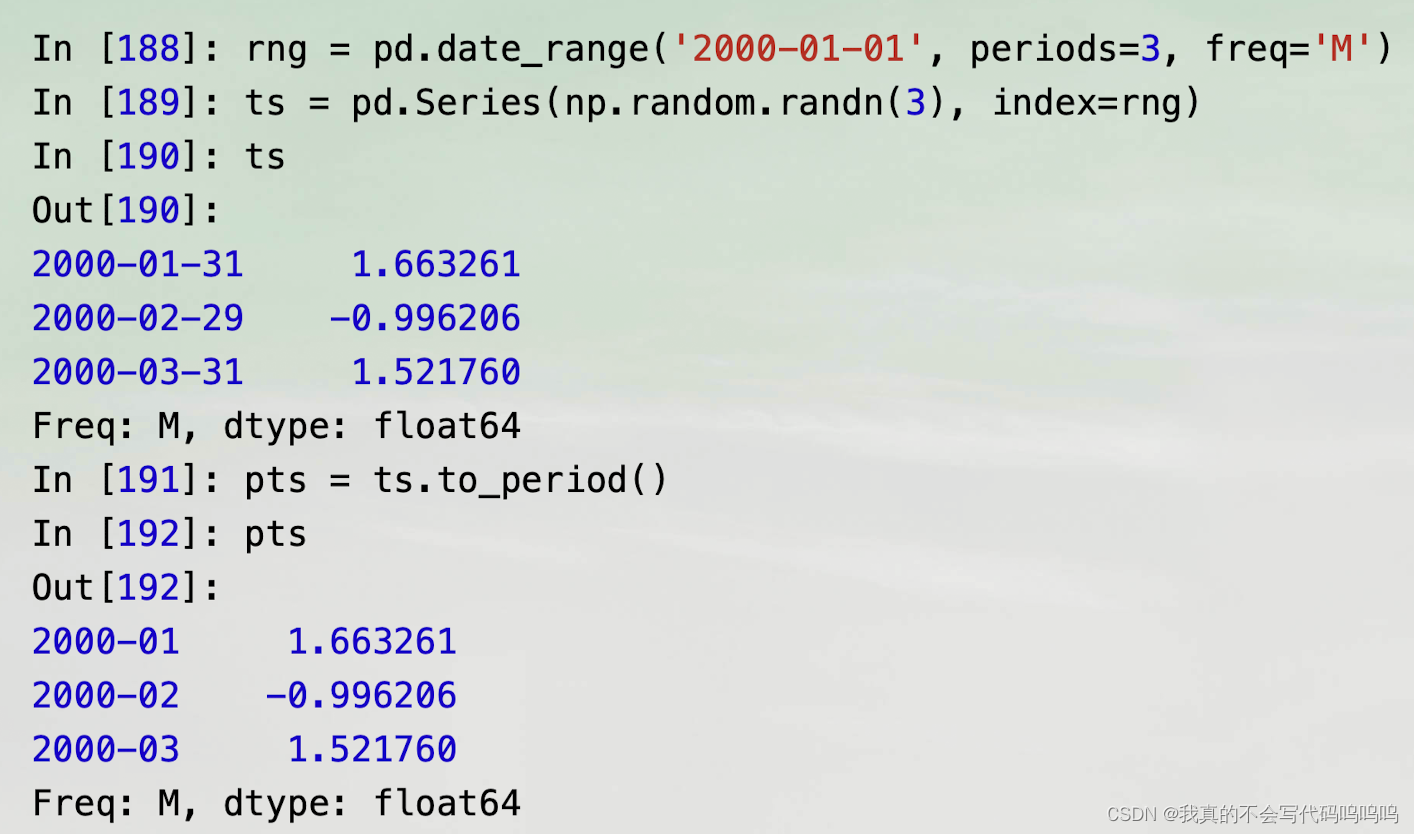
(3)时间戳转换区间(以及逆转换)
- 通过时间戳索引的Series和DataFrame可以被to_period方法转换为区间:
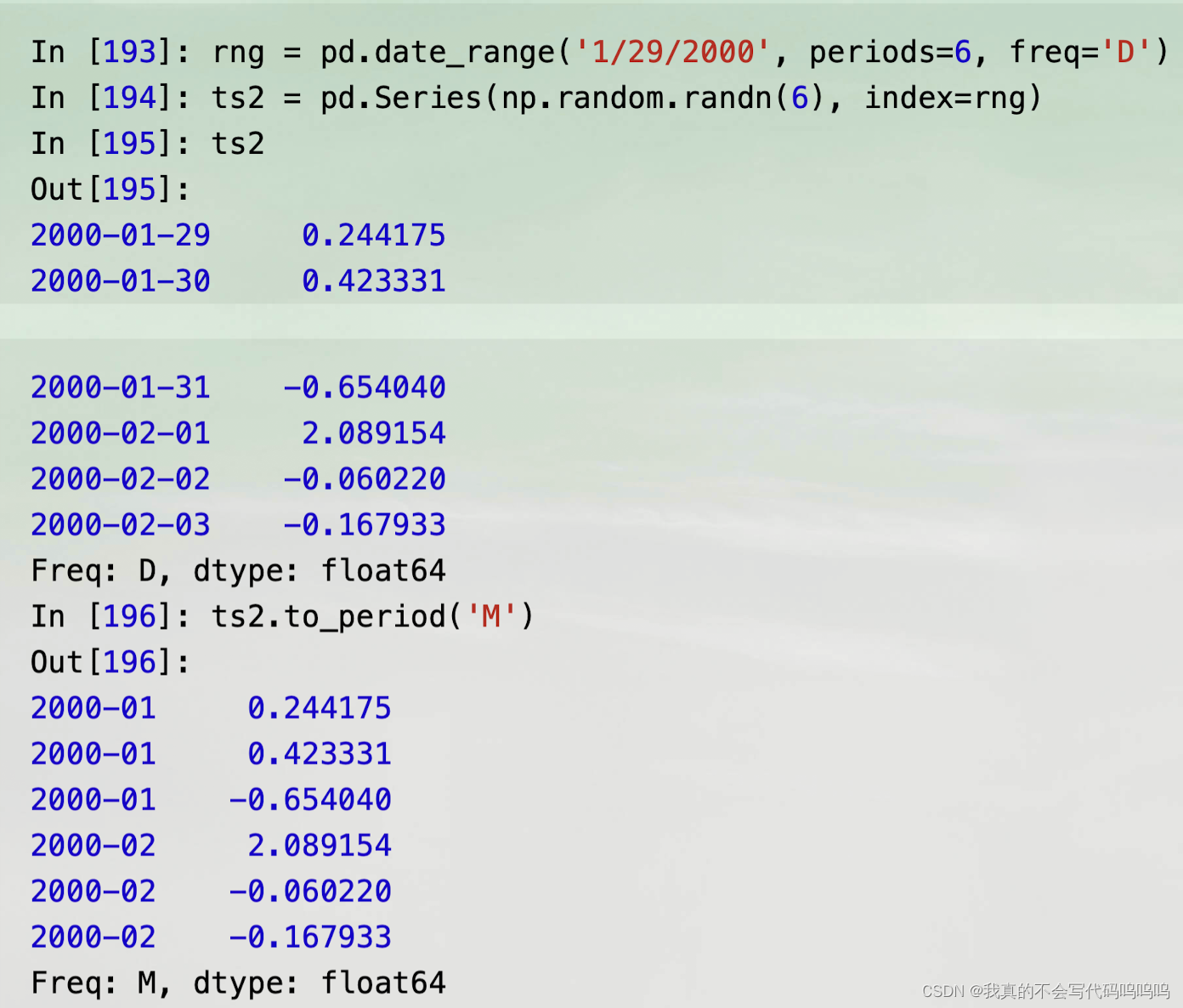
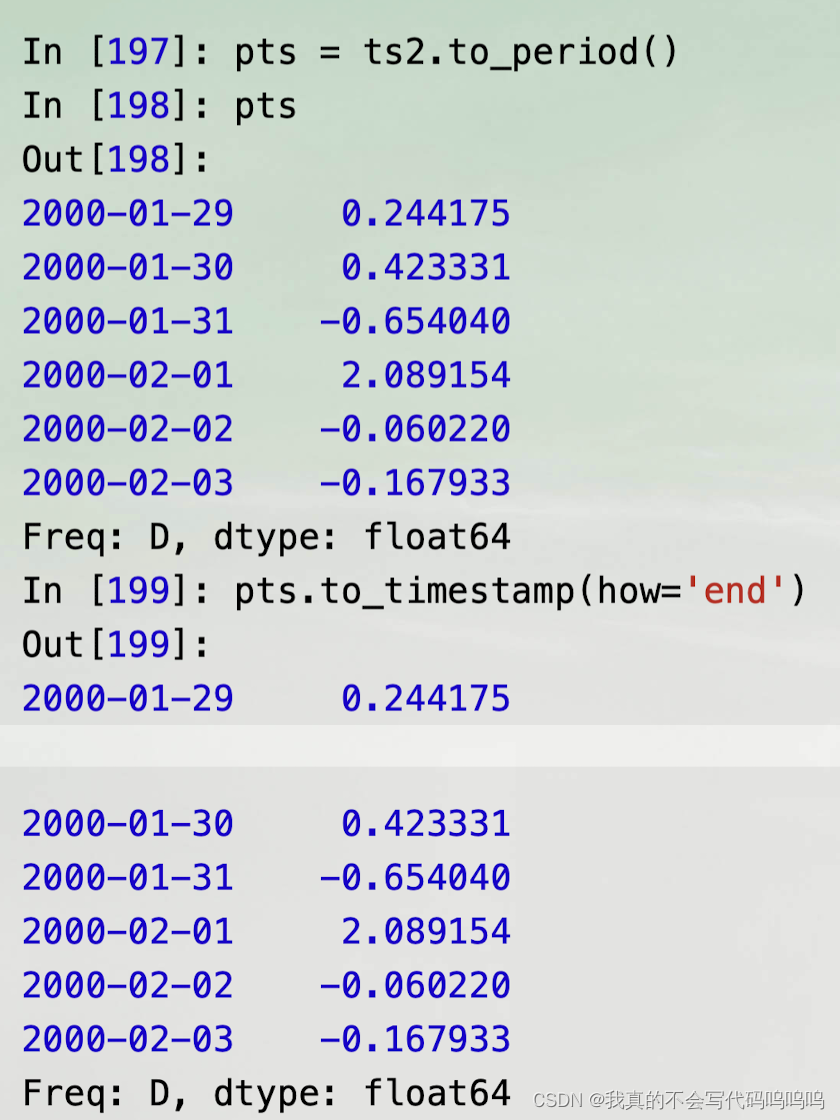
(4)to_timestamp()
(5)从数组生成PeriodIndex
年份和季度在不同列中:
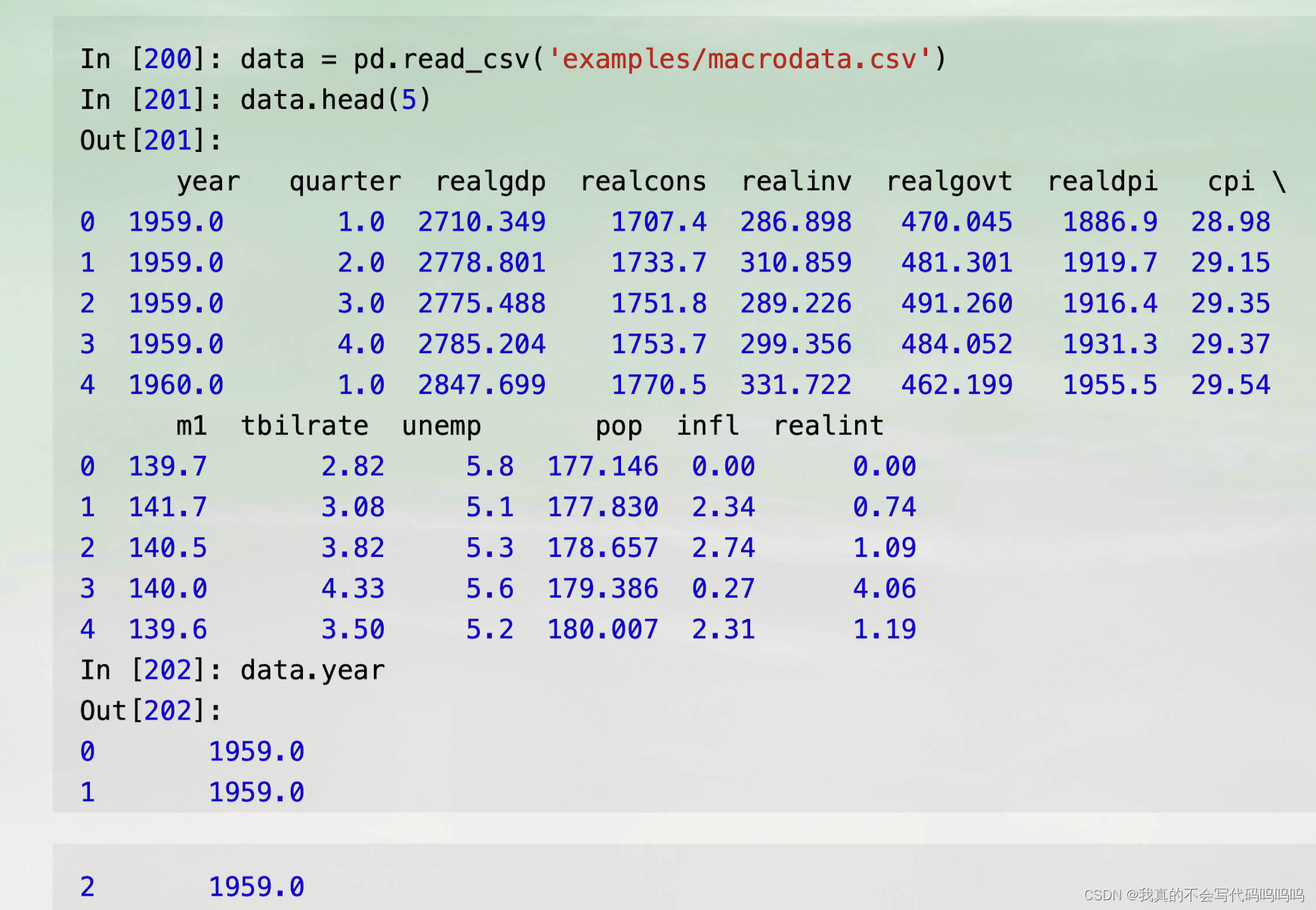
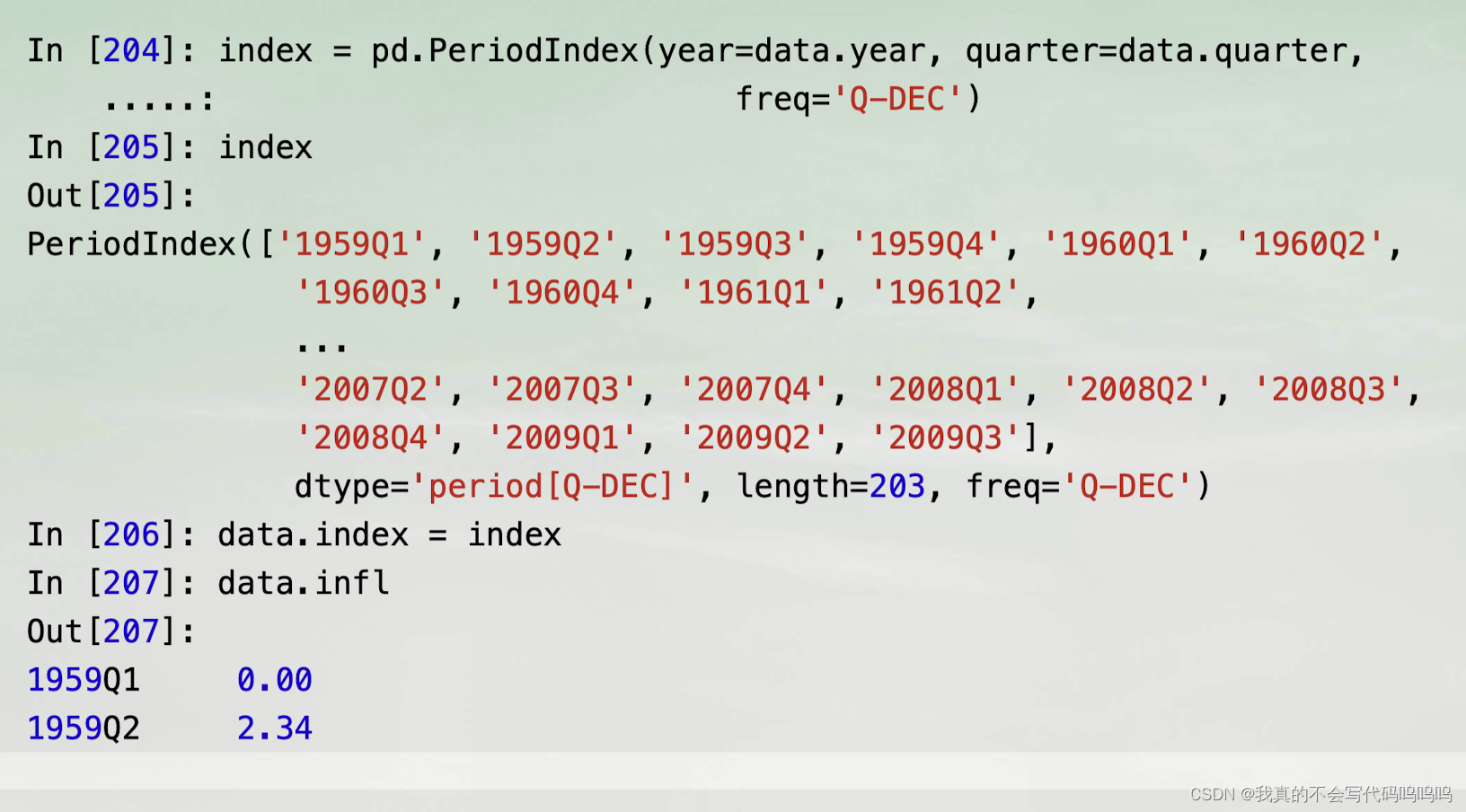
- 通过将这些数组和频率传递给PeriodIndex,你可以联合这些数组形成DataFrame的索引:
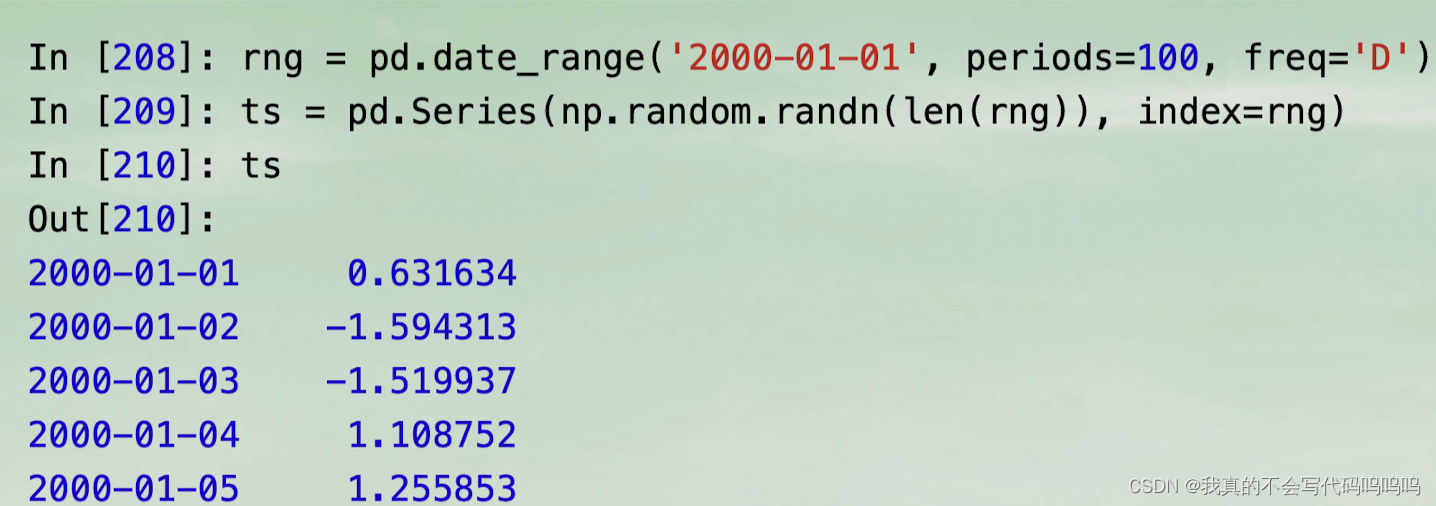
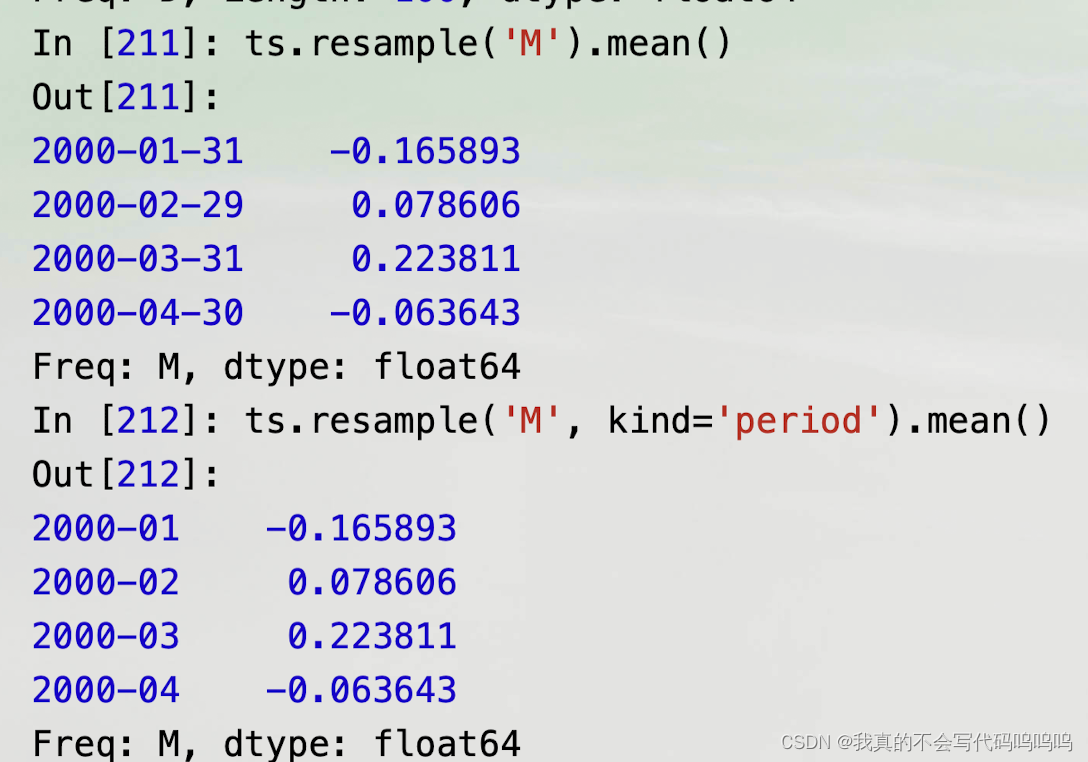
(6)重新采样与频率转换
- 重新采样是指将时间序列从一个频率转换为另一个频率的过程。将更高频率的数据聚合到低频率被称为向下采样,而从低频率转换到高频率称为向上采样。并不是所有的重新采样都属于上面说的两类;
- resample拥有类似于groupby的API;你调用resample对数据分组,之后再调用聚合函数:
















 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









