







基于多模态大模型给现实世界加一本说明书
前言
随着ChatGPT的蓬勃发展,大型模型正深刻地影响着各个行业,技术的飞速发展让人感觉仿佛“度日如年”(每天涌现的新技术数量甚至超过过去一年)。在这个快速发展的潮流中,多模态技术作为行业的前沿更是突飞猛进,呈现出一统计算机视觉(CV)和自然语言处理(NLP)的势头。
本文介绍了一款能够迅速解释现实世界的应用,它基于多模态大型模型,为现实世界提供了一本实时说明书。将手机置于车载摄像机位置,该应用能够实时分析当前地区今年新春的最新流行趋势。不仅展示了多模态技术的强大之处,还为我们提供了对真实世界的深入解释。
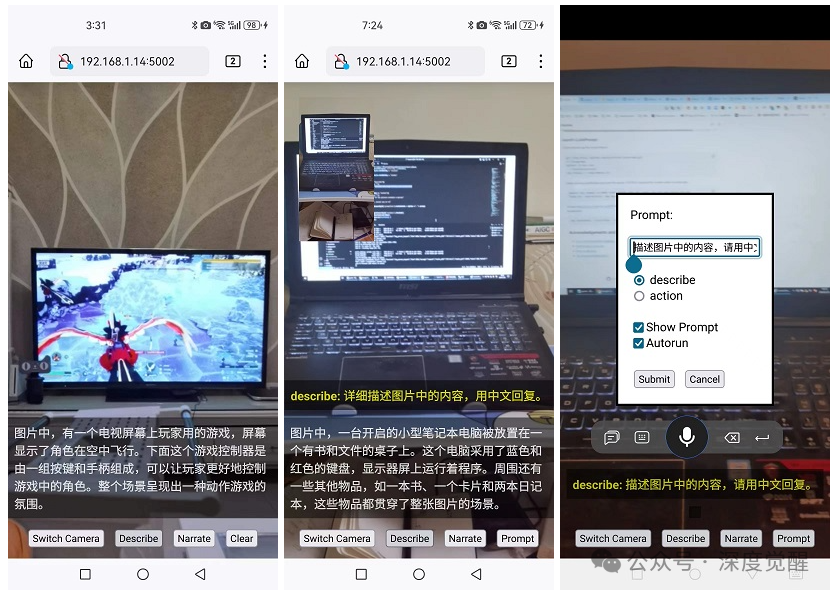
这是快速在手机上利用多模态技术的方式之一,「近距离地感受一下大模型对传统APP开发的降维打击」。
在这种架构中,后端采用 llama.cpp 挂载 LLaVA 模型,为应用提供推理服务。同时,部署了一个 Flask 应用用于数据前处理和后处理,提供 Stream 流服务。前端页面采用 HTML5,用于采集画面和用户输入,整体设计以简单高效为主打。
建立 llama.cpp 服务器

git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
mkdir build
cd build
cmake .. -DLLAMA_CUBLAS=ON # Remove the flag if CUDA is unavailable
cmake --build . --config Release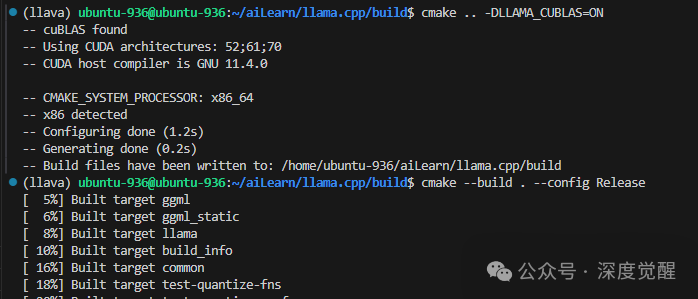
LLaVA 模型
下载模型 ggml_llava-v1.5-13b,这里选择是13b 4bit 的模型。
wget https://huggingface.co/mys/ggml_llava-v1.5-13b/resolve/main/mmproj-model-f16.gguf
wget https://huggingface.co/mys/ggml_llava-v1.5-13b/resolve/main/ggml-model-q4_k.gguf
BakLLaVA 推理速度更快,但对中文的支持较差,7b的模型在语义理解方面普遍存在不足,特别是在需要规范数据格式进行交互的场合。对于function call和action操作,极度依赖模型的AGI能力。希望开源社区在不断努力,早日赶上GPT-4V的水平。
运行推理服务
使用 llama.cpp 部署模型,其中 -ngl 指定35层放置在GPU上进行推理,而 -ts 100,0 将所有工作负载都集中在单卡上。
./bin/server -m ggml-model-q4_k.gguf --mmproj mmproj-model-f16.gguf -ngl 35 -ts 100,0 # For GPU-only, single GPU
# ./bin/server -m ggml-model-q4_k.gguf --mmproj mmproj-model-f16.gguf # For CPU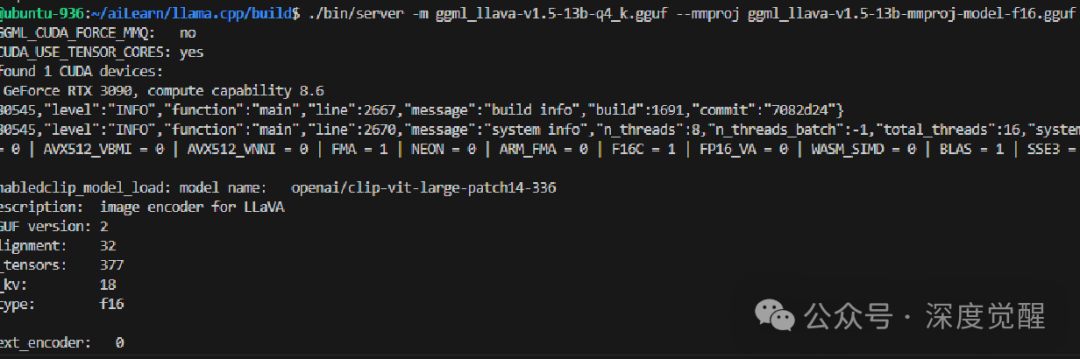
在3090型号的机器上,显存占用约为9GB左右,推理一张图片大约需要5~9秒。
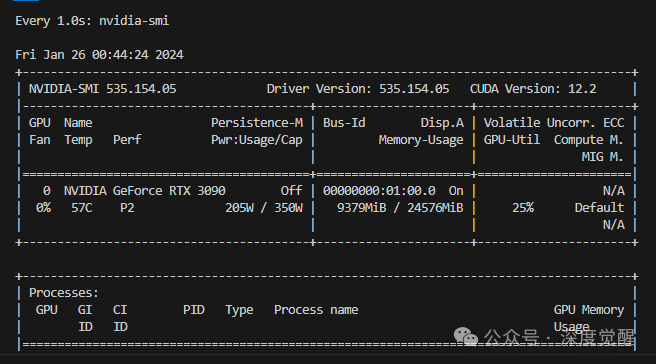
更多的参数请参考
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md准备 LLaVA Prompt
建立虚拟环境
git clone https://github.com/bluishfish/llavaprompt.git
cd llavaprompt
pip install -r requirements.txt生成 ssl 证书
采用 Stream 方式提供服务时,我们需要使用 HTTPS 协议,因此需要先生成 SSL 证书。这里开发者模式,简单处理没有绑定域名,浏览器访问时请忽略警告。
openssl req -newkey rsa:4096 -x509 -sha256 -days 365 -nodes -out cert.pem -keyout key.pem
flask run --host=0.0.0.0 --key key.pem --cert cert.pem --debug --port 5002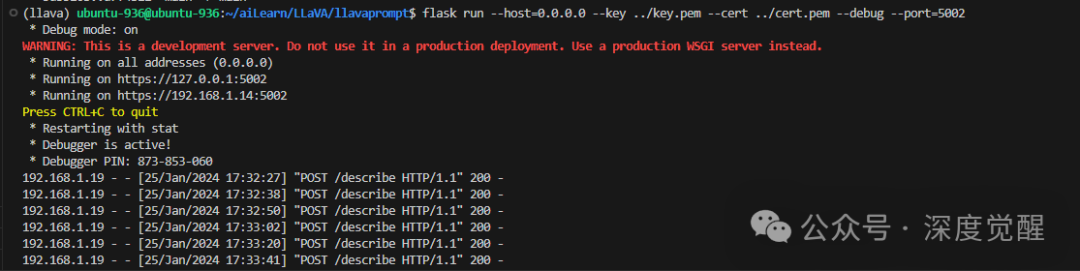
端口映射
在这里,将 Flask 的端口更改为5002,请确保在服务器防火墙中放行相应的端口。
sudo ufw allow 5002
sudo ufw status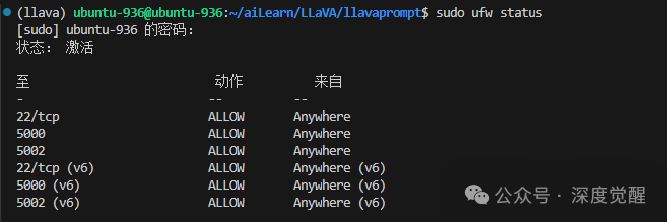
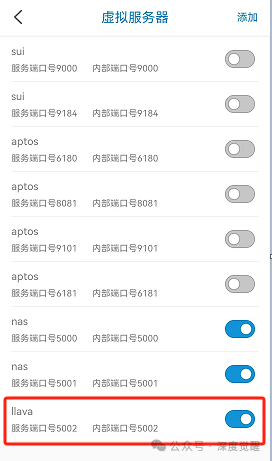
若需提供外网访问,请务必向运营商申请公网IP,并在路由器上进行端口映射,以实现对内网Flask服务器地址的穿透。
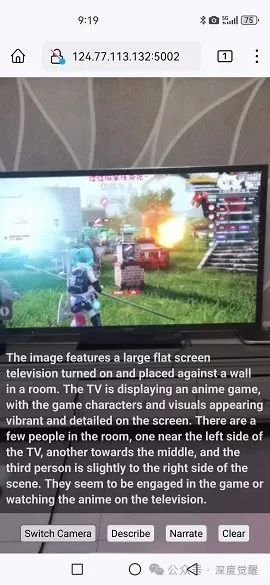
推理时间
在5G网络和WiFi的支持下,绝大多数时间都花费在大模型推理上。LLaVA 1.5 13b 4bit的推理时间约为9秒;
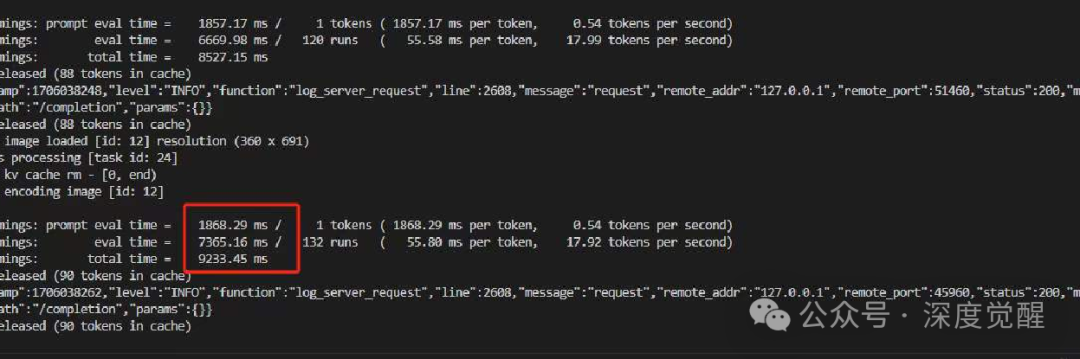
而BakLLaVA 7b 4bit的推理时间则可以加速到约800毫秒左右,这个速度基本上可以与端侧直接推理相媲美。
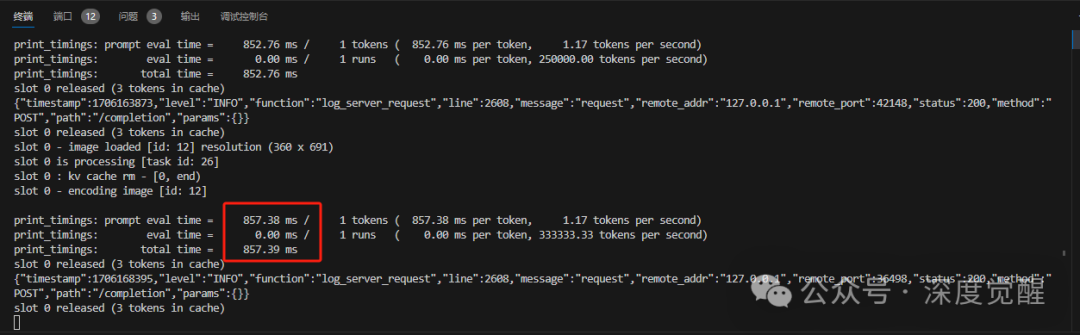
移动端访问
通过在手机上使用 https://your-machine-ip:5002 访问服务,在华为手机上使用Firefox,在一加手机上使用Chrome进行测试(其中外网访问摄像头,需要将“安全浏览”设置为“标准保护”模式)。这两款浏览器对HTML5的API支持较好,「其他手机浏览器情况欢迎在留言板反馈」。
主要功能包括:
Switch Camera:切换前后摄像头
Describe:进行一次LLaVA推理服务
Narrate:对结果文本进行语音朗读
Prompt: 自定义提示词
「准备工作已完成,理论上只需携带手机,就可以出门浪了」。仿佛低配版本的AR设备齐备了一样,这是不是很像 ai pin!
「不是 ai pin 不够好,而是闲置手机更具性价比」。利用家中的电脑和闲置的手机,以几秒的推理速度,无限的可扩展AI模型和自由设计的架构,还要啥自行车嘛~
自定义 Prompt
「通过自定义Prompt,可以瞬间获得极大的扩展能力。」让人感慨传统计算机视觉的口罩模型,需要准备多少数据样本和花费多少时间进行模型训练。如果需求变为安全帽检测呢...
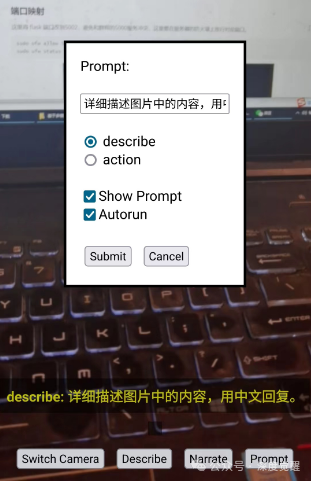
这个用来做demo,是「低成本商业验证的最佳方案」。没有比自定义prompt更低成本、又能完整走完整个工程链的测试工具了。
拥有强大的Prompt,就能解决大部分问题。随着不同项目落地越来越感叹,90%的问题可以通过一个强大的基础模型(比如GPT-4),结合构建提示词来解决。在剩下的10%中,90%需要挂接自定义知识库由RAG来解决,而「仅有1%的问题」需要算法工程师进行finetune,朝着AGI的方向努力吧。
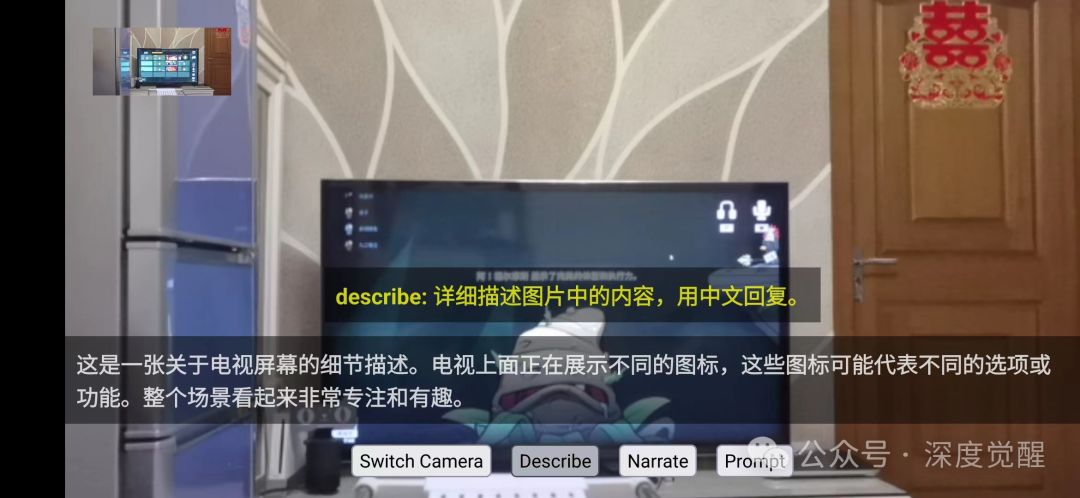
描述模式
该模式能够识别镜头上的目标,支持中英文双语,基本上可以理解场景中的内容,可用作基础的意图识别,也可用于场景内容分析。
条件触发模式
通过构建提示词,匹配结果为yes/no,并在前端做出响应。在当前的demo中,匹配到yes后,会在左上角显示满足条件的图片。
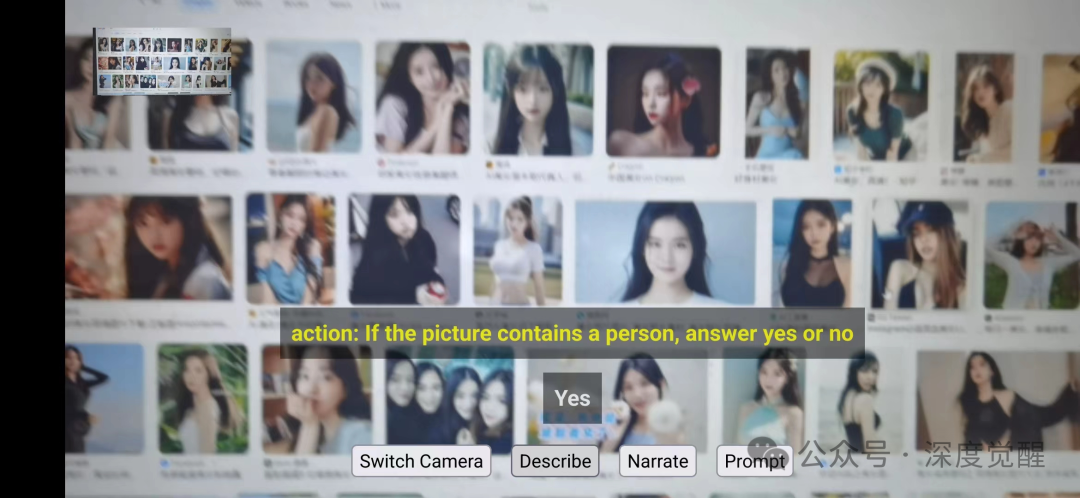

后续可以进行更多扩展处理,比如接入AIGC进行二次创作,进行溺水检测报告、火灾检测、口罩检测等等。想象的空间很广泛。
自动模式
前端会定期调用推理服务,实现无人值守的自动化。后端可以根据匹配到的场景,实时进行推理服务。那么问题来了,「有什么场景需要用到实时推理」呢?导出行车记录仪,进行「异步分析会不会更经济」?
能想到的应用场景有
道路状况:如果你遇到交通问题、拥堵或其他道路状况,分享车前图片可以让其他人了解实际情况。
风景美景:如果你驶过风景秀丽的地方,分享车前拍摄的景色图片,与他人分享旅途中的美好。
游戏互动:在幻兽大火,宝可梦死灰复燃的当下,基于 LBS 出门抓个神奇宝贝不过分吧。
大模型应用的利弊
优点:
适应性极好,通过提示词工程,方便「适应各种奇葩需求」。
对算法的要求降低了不少,大部分功能由大模型提供,特别是非结构化信息的处理。
大模型的API访问方式简化了边缘设备的要求,无论在Android、iOS、HarmonyOS或各种嵌入式设备上都能方便适配。
「AGI终将到来,拥抱未来,虽然路途艰难但相信方向是正确的。」
缺点:
大模型的推理时长目前仍是最大的障碍,传统目标检测或人脸识别优化后能达到100~300ms,而大模型动则需要10秒的延时,限制了许多场景。
模型的幻象和错误率仍然较高,导致上述推理时长问题,在多链路的复杂应用中迅速变得不可行。
在大多数生产模式下,仍然需要使用云服务数据中心,提交的画面不可避免地涉及到隐私问题。
商业私有化部署是刚需,当下的开源模型离 GPT4 代差在半年以上,技术人员任重道远的。
未来展望
大模型三要素,算法,算力和数据,巧妇难为无米之炊。车载支架已就位,待我出门逛一圈,将后端采集的prompt和源图存入数据集,然后进一步展开工作。

人生就是一趟单向旅途,你能所做的只是「尽量不错过沿途的风景」。
2024年了,先提前给大家拜个早年。在大型语言模型面前,技术已经平权,要卷的只剩下「创意和工程化落地能力」了。
源码下载
本期相关文件资料,可在公众号“深度觉醒”,后台回复:“llava01”,获取下载链接。
后续版本会持续更新开源,有兴趣的也可以去 github 上 star 一下
https://github.com/bluishfish/llavaprompt

















 3625
3625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











