







前言
随着大模型越来越庞大,LLaMA 2 (70B), Guanaco-65B, BLOOM-176B,这些模型的训练要求以远远超过单机可承受的范围。
本篇我们介绍一种新技术 「petals」,不同于之前的联邦学习或是传统分布式训练,它能将模型拆分到更小的颗粒度,每个节点仅下载一小片神经网络并行计算,大大加速了训练和推理速度,再也不用羡慕 H100*8 了。

另外近期自从遭遇联想售后修坏了3090的主机cpu和主板,无良物业又以莫须有的噪声迁了2080ti之后,对我的私有算力池造成了很大的干扰。集中式的训练方式虽然高效便捷,但鸡蛋放一个篮子里,风险过于集中,若能将各个朋友的闲置算力汇总起来共同搭建私有算力池,则大家再也不用担心算力不足了。

如同一切的恐惧来自于火力不足,一切的担忧来自于算力不足。
技术原理
Petals 采用类似 BitTorrent 方式,每次加载模型的一小部分,并加入其他人的算力池来继续推理或是微调。对于LLaMA 2 (70B) 可以获得十倍的推理加速,并行化处理更是可以达到每条数百 tokens。通过 pytorch 的 api 可以方便地对模型微调、采样、自定义或是查看神经网络的状态值。
https://github.com/bigscience-workshop/petals
更详细的细节,可以在文末链接中下载相关的论文:

应用状态
服务器端
我们可以加入公共池或是建立自己的私有池,先看一下公有池的状态:
https://health.petals.dev/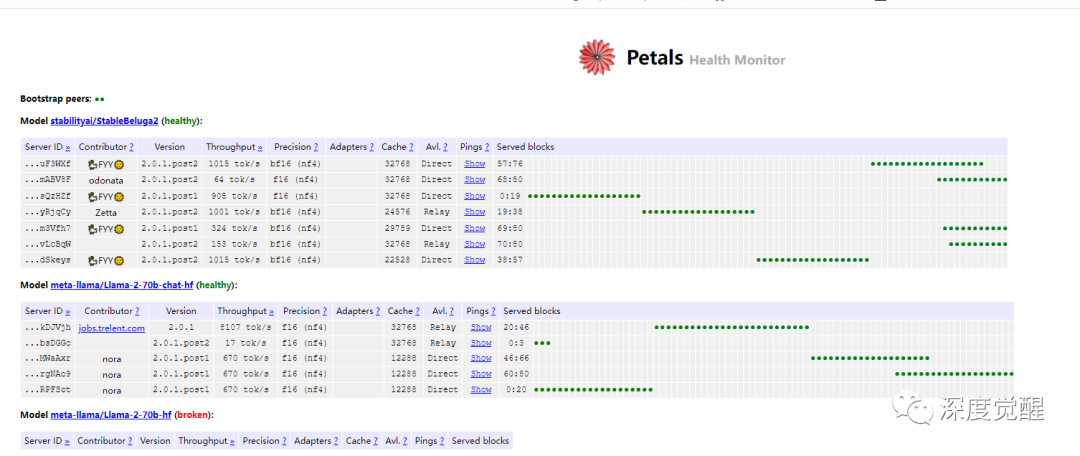
可以看到有几个 LLaMA 2 (70B) 模型正在运行中,有好几个人共享了自己的算力,绿色圆点则是他们各自提供模型推理的标记点。
客户端
我们可以实际测试一下 LLaMA 2 chat 实际生成回复的速度,每秒1个token左右,中文的相对较慢,英文可以达到每秒5-6个token。要知道这是70b的大模型,单卡几乎很难胜任了。
https://chat.petals.dev/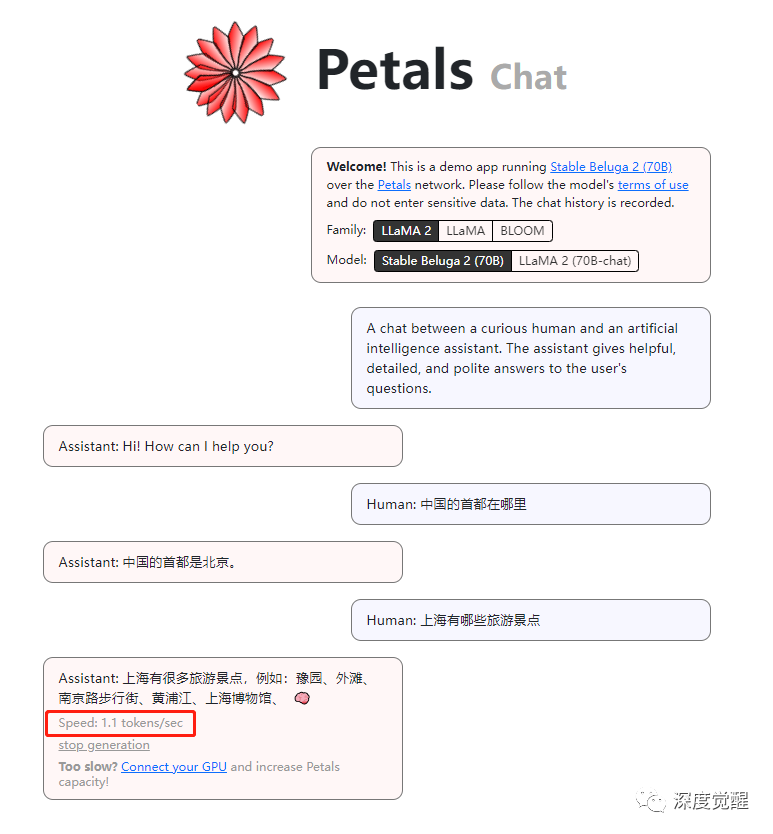
公有算力池
官方很贴心的提供了一个 Colab ,我们体验一下如何加入公有池,有需要也可以在本机共享 GPU。
https://colab.research.google.com/drive/1uCphNY7gfAUkdDrTx21dZZwCOUDCMPw8?usp=sharing首先是安装依赖
pip install petals然后来加载一个 LLaMA 2 70B 的 chat 大模型(登录 huggingface 获取 token)
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "meta-llama/Llama-2-70b-chat-hf" # stabilityai/StableBeluga2
# You could also use "meta-llama/Llama-2-70b-chat-hf" or any other supported model from 🤗 Model Hub
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()
默认分配的是 T4 16G的 GPU,正常情况单卡肯定扛不住......
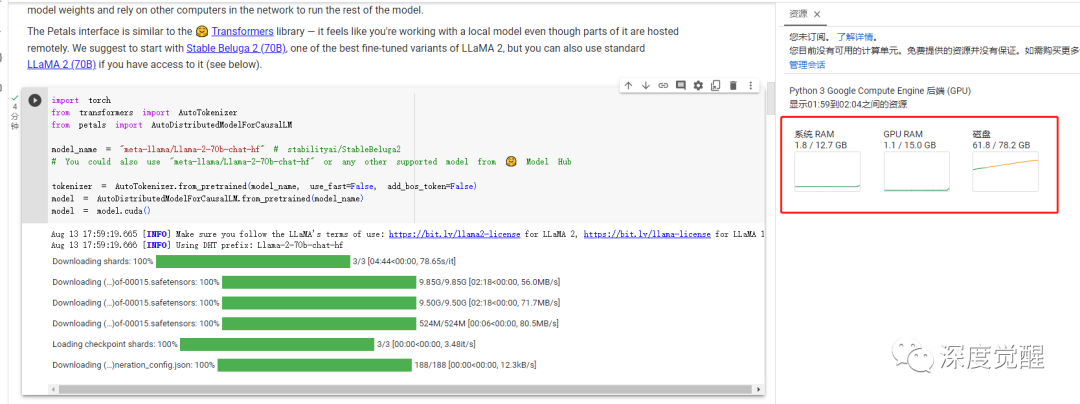
测试一下提问,可以看到分别经过 4 台设备完成推理。

对应节点的后缀可以在服务器端对应匹配到。

贡献算力
最后可以把自己的 GPU 贡献到池中,众人拾柴火焰高,其中 YOUR_TOKEN_HERE 可以通过 https://huggingface.co/settings/tokens 获取,public_name 则可以起一个别名,便于在服务端找到你的机器。
python -m petals.cli.run_server meta-llama/Llama-2-70b-chat-hf --token YOUR_TOKEN_HERE --public_name bluishfish
一切顺利的话,就能在公共页面上查看到你的设备了。
部署到算力池中的模型需要遵守一系列的约定,若要运行自定义的模型,则要根据接口来修改参数
https://github.com/bigscience-workshop/petals/wiki/Run-a-custom-model-with-Petals源码下载
本期相关文件资料,可在公众号“深度觉醒”,后台回复:“petals01”,获取下载链接。
下一篇预告
这一篇主要介绍了一下 petals 如何分布式加载超大参数的模型、部署推理和贡献公有算力,下一篇我们尝试构建一个私有池,将各个分散闲置的算力都整合起来,敬请期待。


















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











