






(笑,你的笔记检索线索过于迂回了)
quantile
应用之中遇到的问题:我所面临的学习大数据具有很多的记录,那么请问要如何运用分位点数据去粗略进行分组然后显示这些数据的一个大致的范围和分布呢?
百分位分组学习
【新提醒】如何按照分位数分组?不是等分 - Stata专版 - 经管之家(原人大经济论坛) (pinggu.org)
stata数据处理——分位数分组的命令 - 知乎 (zhihu.com)
原文里面的效果是按照分位点分组创造分位点分组新变量,然后recode成中低高收入标签就好了,但是我想要的效果是呈现出源数据按照分组切割的呈现,一直没办法搞出来还提示我说option行不通,可是我在只有一个变量的网络案例教学里面是跑通了的。
还有一个问题就是看不懂help文件里面的示例在讲什么,(sepby/)明明是按照它跑的。
你不知道能不能这些变量代表什么能不能不要乱试先拿简单案例尝试一下跑通了理解命令含义?中括号是可以省略
法一 -pctile- 命令
pctile 创造含有百分位点变量 Create variable containing percentiles
pctile [type] newvar = 表达式express [if] [in] [weight] [, pctile_options]
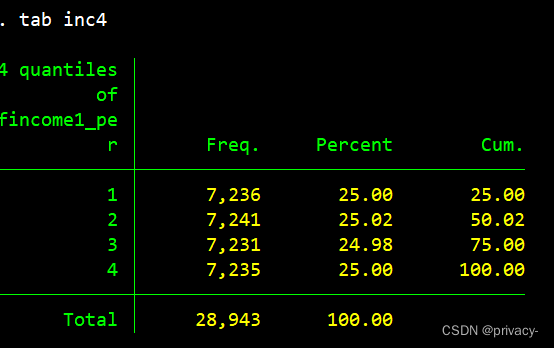
本文:pctile p_inc = fin, nq(5)
// nq(#) 命令有错, 指定4个百分位数,应当是把样本切割为4组而不是5
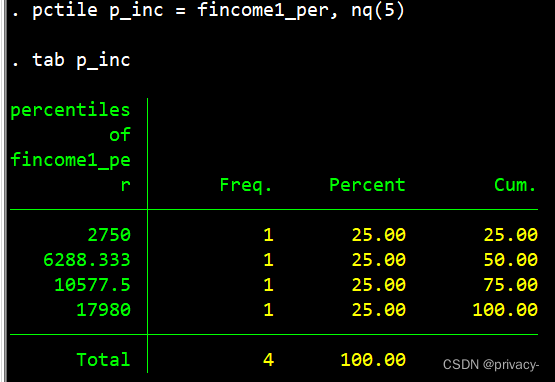

三个方法达成一致,方法工具稳健性检验完毕
然后tab p_inc 或者 list p_inc in 1/3, sep(0) 两个都是显示分位点变量取值的形式
~list if命令还可以用于匹?配,与merge具有相同功效(?可是merge的话不是主要用于横向跨库合并吗?又打开了我的认知新世界。)
~题外话,line是是什么?
help line,你会知道separator(#) 意味着draw a separator line every # lines; default is
separator(5),这个功能的意思只是显示的时候每五行画一条分隔符
破案了,只是显示方式选择
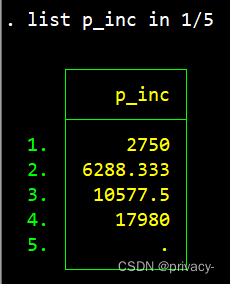
成功了,计算出分位点数量。btw 想要呈现你那样的形式也没有意义 因为取值太多了..
_pctile varname [if] [in] [weight] [, _pctile_options]
_pctile
法二 astile命令-创建百分位点
astile比 state 官方提供的xtile命令处理速度更快。 它的高效性在数据集较大或者当分组类别被多次创建时更加明显,比如说,我们可能需要根据每个年份或者月份分别创建分组。
astile inc4= finc_per, nq(4)
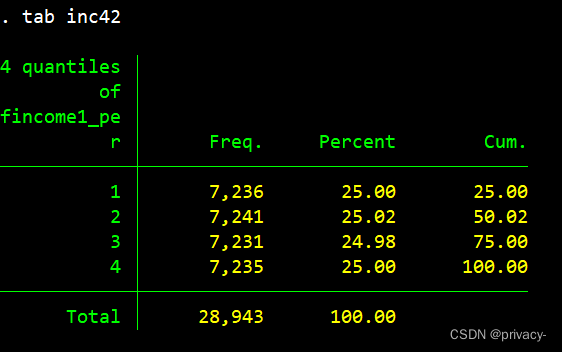
然后进行recode即可轻松实现原文目的
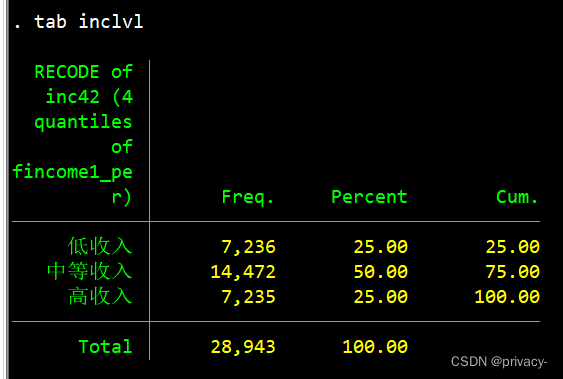
进一步list, sepby(inc4)? 这个命令是无效的,旧版的吧?
一致,后面算法性能优化,适合大数据















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









