







本篇为下集,介绍数据处理部分,包括数据导入导出、清洗的常见命令。内容源于help文档与网络公开内容,优质参考文档会放链接。
文约3万字,内容详实,讲解细致,需花一定时间消化。小的不足以做大标题的知识点我都内嵌到模块种了,每一块包含的内容都很多,认真学完整篇文档,基本可以用 stata 进行数据处理。跑回归只是几行代码,数据处理才是大头,希望这篇文档能对你有所帮助。由于文字过多,网页格式不利于查找,文末放有本文的 word 文档及相关练习数据,方便搜索查看。当然这个只是我把网页版的复制了一遍,排版别指望了。
本文涉及许多函数,只涉及最常用的几种,有些函数功能部分重叠,但不同人喜欢的函数不一样,多学一点还是好的。以例子讲解函数设置,看明白后自然知道 help 文档内的参数是什么意思。
字好多,肯定有一些错误的地方,望谅解。
1. 外部命令下载与基础命令
1.1 外部命令下载
介绍数据处理之前,需安装一些外部命令。想要实现更为复杂的功能需要组合很长的代码,将这些代码封装到一个命令里,则可使用一条命令完成多条代码所作的事情,这就是外部命令。一般而言有两种获取方式。
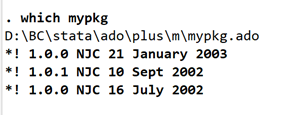
第一种是:ssc install mypkg,mypkg可更改为任意想安装的命令,该包的功能在于展示所有安装的外部命令。由于我已经安装,再运行会进行更新。

输入 mypkg 将会显示所有安装的外部命令及日期,若想查找特定的命令,则用通配符,mypkg d* 只会显示 d 开头的外部命令。 如果说想查看特定外部命令的基本信息,则输入 which mypkg,会显示该命令存储位置以及命令初创与迭代日期。
第二种则是 findit reghdfe,findit 可以搜索内部与外部命令,并以搜索结果的方式呈现。Reghdfe是一个固定效应回归包,搜索后有23条结果,但并不是每条都可以下载 reghdfe包,例如第一个包是 gr0091包。 往下翻到 reghdfe 开头的包,点击后再点 click here to install 即可完成包的安装。


安装外部命令后,输入help 包名,例如 help total ,查找用法及案例。
如果某些命令很多人都下载,说明该命令有助于实证研究。输入 ssc hot, n(15)即可显示下载量最大的15个命令,挑选你需要的进行下载。
1.2 stata运行状态判断
如果输入命令代码,发现程序无反应,不知道是网卡还是程序正在跑,有两个辨别方法。第一,看上方栏的×号的颜色,运行代码时显示红色,否则为灰色。


第二,看命令窗口的左下角,如果显示如下,说明仍然在跑,耐心等待即可。
![]()
1.3 基础函数介绍
gen 与 egen 函数
输入 gen a=17,gen命令为产生新变量,其为generate简写,也可简写为g。但该命令只能生成一些系统自带的函数,例如 gen a=17, gen a1=a^2, gen a2=ln(a),稍微高级点的都不行,输入 gen a3=mean(a),会显示 mean 为未知函数。
egen 同样可生成变量,其源于 egenmore 外部命令包,ssc install egenmore,该包提供了很多好用的函数,后续会介绍到。稍微高级一些的,如果 gen 无法生成就可以使用 egen,输入 egen a3=mean(a),此时不会报错。dis a3,a3数值即为a的均值,dis是display的简写,通常用于展示单个变量或函数结果。
什么时候使用 gen?什么时候用 egen?我觉得跟数值相关的用 gen,跟函数、变量相关的用 egen。只是经验之谈,如果用的不恰当系统会报错,再用另一个就行。
gen 很多时候也会作为函数的附加选项,即保留原数据下,将处理后的数据存入一个新变量。这种命令通常为:duplicates tag price, g(du)。其中生成新变量选项也就是 g(du) 在逗号后,逗号后的基础函数通常没有等号,采用 () 的形式,该命令表示对价格的重复值进行标记,并将重复值数量存入新生成的变量 du,了解即可后面会介绍。
空值设定、键入与随机抽样
set obs 5,br查看情况,可看到有5个编号。 gen a=17,你会看到变量为a,5个值都是17,这是因为设定样本数量后 gen产生的数值默认为向量。gen x=runiform() 你会看到新增变量 x,runiform函数为随机生成符合均匀的数值。
数据输入通常为导入文件,但也有时候需利用几个简单数值验证下函数的用法,因此学习键入也是有必要的。输入 input x,input 为键入命令(简写为 inp), x 指生成的数值都存到变量 x 内。输入一个数值后按回车键,会进入下一条数据的录入。由于我们之前设置了长度为 5 ,因此在第五个数值输入后就会结束录入。clear 空间,输入 input x,由于未提前设置长度键入不会自动结束,在新的一行输入 end,则结束当前输入。
if, list 与 replace
if 为条件语句,很常用。在生成新变量、浏览数据、分组计算时都会用到 if,后直接跟条件即可。比如说 if a>1,if a!=1(不等于), if a==1(注意两个等号为判断,一个等号为赋值)。如果为多条件,则加 & 或者 |。如 if a!=1 & b!=1,if a!=1 | b!=1。
sysuse auto, clear。这是一份关于车的数据集,make是制造商信息,rep78是78年该车的维修次数, foreign 是该车是国产还是进口。我们现在想查看第 46到55行的数据,输入 list in 46/55,会在代码运行结果处立即列示相关信息。
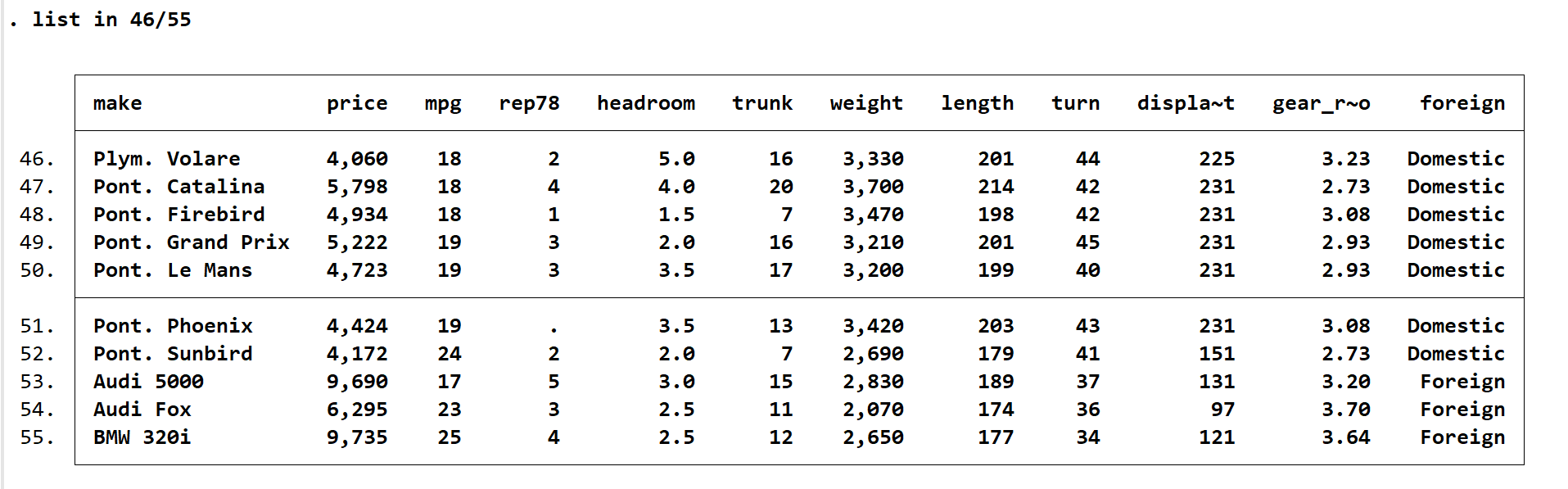
如果只想看 46/55 的属于国产车的数据,则输入 list in 46/55 if foreign==0(foreign=0则无法运行)。
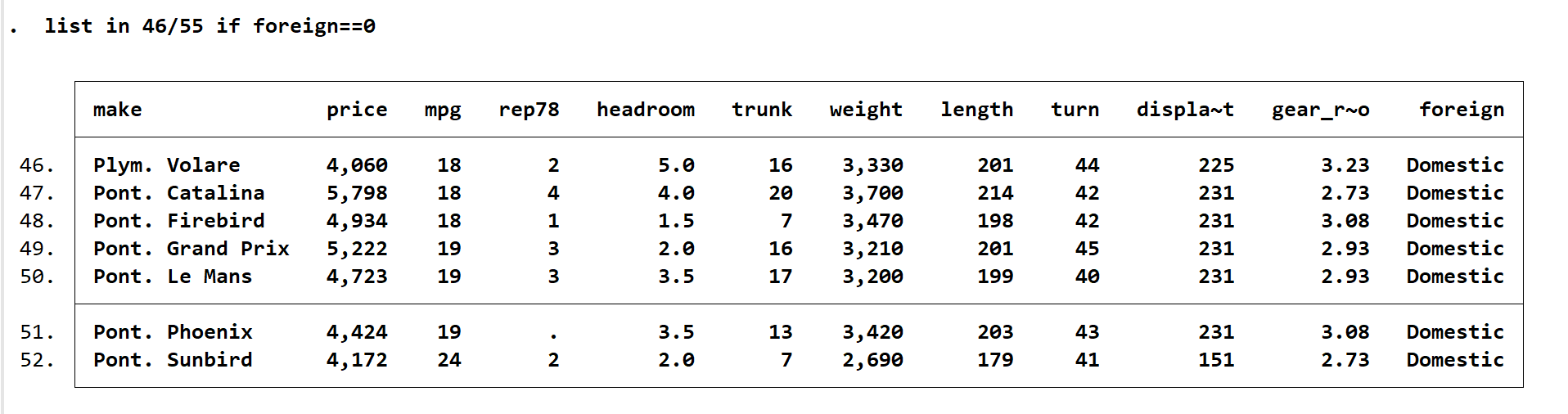
可以看到如果 list 后直接跟 if 会显示所有变量,输入 list make pr fo rep78 in 46/55 if foreign==0。由于 price 与 foreign 在变量中无相同前缀者,因此可以简写为 pr fo。
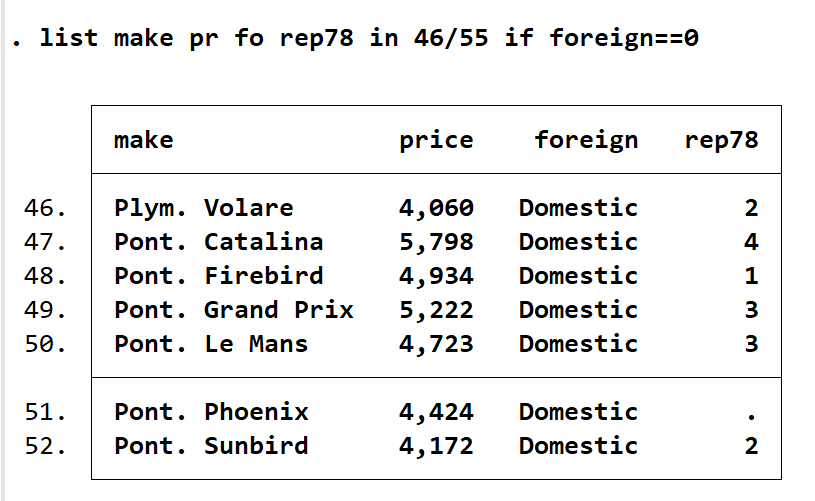
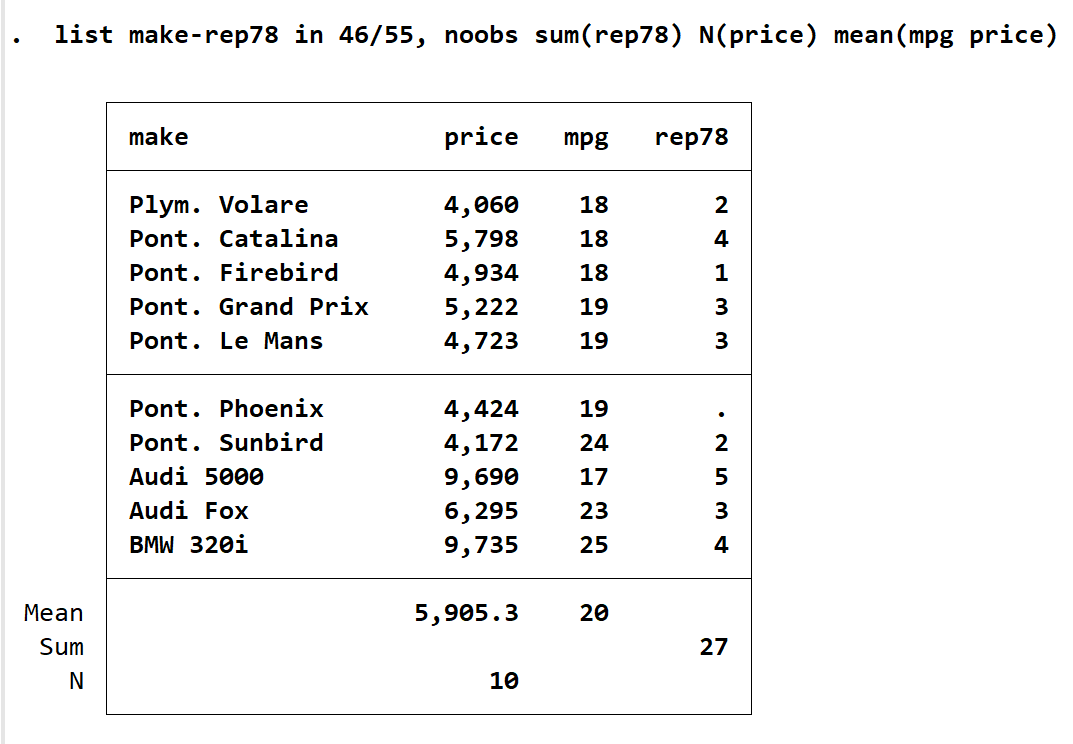
输入 list make-rep78 in 46/55, noobs sum(rep78) N(price) mean(mpg price),会得到下图。其中 make-rep78中的短划线指选中范围,从make到rep78间的变量都被选中,noobs指的是没有编号,可以和上图比较一下,左侧是没有 46/55 的数字。而 mean(mpg price)指分别对两者求均值,N(price)指计算列示出来的price有多少个。list 只提供了这三个统计选项,内可以包含多个变量。
replace 命令为覆盖命令。set obs 20后,gen x=runiform(),gen y=runiform(),br浏览数据,x与y不一样。输入 replace x=y,可看到 x 中数据均被替换为 y。replace 命令也常与 if 连用。
_n ,sort 与 gsort,by 与 bysort
sysuse auto, clear 可以看到数据无样本编号。输入 gen id = _n。_n 为按照样本当前或指定顺序生成1-n的编号,输入 br 可看到样本次序。_n 用处其实很大,仍以 auto 举例。假设我们现在想知道国产车和进口车中价格最便宜的五辆的制造商是谁。
我们第一步需进行排序,输入 sort foreign price。sort 命令为升序排列,首先对 foreign进行排列(为什么domestic是第一个,foreign为第二个,原因在于两者为值变量,输入label list,可看到domestic对应0,foreign对应1)。而后在国产车和进口车内部对 price 进行升序排列。如果说想知道不同组别车中,价格最贵(降序排列),维修次数最少(rep78升序排列),那么使用 gsort 命令。gsort foreign -price rep78,该命令默认升序,在变量前写 - 号表示降序排列 (+号为升序)。
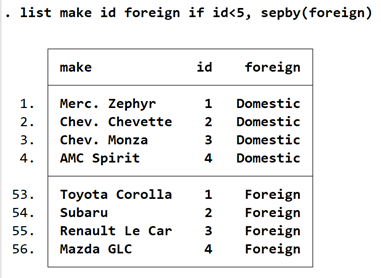
回到正题,排序后,输入by foreign: gen id=_n,by命令表示根据组别进行分开计算,具体计算方式在冒号后表明。该命令表示根据分类变量 foreign 分别生成编号。而在前面,我们已经对 foreign和 price 进行了排序,此时的编号显示的是不同组别的车之间从最便宜的到最贵的。list make id foreign if id<5, sepby(foreign)。
如果你搜过 stata 相关分组处理的代码会经常见到 bysort 而不是 by。重新引用 auto 数据集,我们先对price进行降序排列,后查看数据,你会发现 foreign 的组别混杂,此时输入 by foreign: gen id=_n,会返回 not sorted 的错误信息。这是要进行分组运算时,需要将性质相同的放在一起,放在一起的方式就是进行排序。因此可以先对foreign排序后再使用 by 分组计算,此时便不会报错。
另外可以使用 bysort foreign: gen id2=_n,该命令会自动对 foreign 排序后分组生成编号,其与 by的区别在于,在组别不同的个体混杂时,可以自动排序后进行分组处理,而不是先排序,再处理。
我们想知道不同组别中,最便宜且维修次数最少的制造商是哪些。可以参照上文的先排列后生成变量。bysort 命令可以顺便对变量进行排序,使用该命令是否能完成上述操作呢?输入 bysort foreign price rep78: gen id3=_n,br查看,你会发现 id3 全部是1,这是因为该命令是将 foreign price rep78三个变量视作联合条件,三者完全相同的才会有编号123,但是数据里显然三者不一致,因此,每一个 id3 都为1。因此 bysort 最重要的是 by 分组计算,sort 只是附带操作,省去了一个 sort 变量的命令行而已。若想使用 bysort 完成目标,则需先对 price 和 rep78升序排列,输入 sort price rep78,再输入 bysort foreign: gen id4=_n,此时 list make id foreign if id4<5, sepby(foreign),该结果与前文一致。
所以满足多条件时分组计算,我建议先进行排序,而后根据分类变量计算。如果只需根据一个分类变量计算,使用 bysort 即可。
数列生成
我觉得要是随机生成数据分析不如拿R,拿stata通常都是写毕业论文的。我介绍点生成规律数字的,符合分布的命令我就不说了。
range 函数可以生成等差数列。清楚空间,输入 range x 1 100 100,range表生成范围,新建变量 x,将1到100的数字存储到其中,步长为第三个100除以第2个100,第三个100表示set obs 100(空间)。如果有数据集时,sysuse auto, clear 后输入 range x 1 100,查看数据见有74个数值,其步长为 100/74=1.35,所以第二个数值为2.35。快速生成编号时,可以输入 range id 1 _N。这个_N 是当前数据有多少个观测值的意思,例如 auto 数据有74行,所以 _N 为 74。
egen提供的 fill 函数更加灵活。 clear 后 set obs 20,输入 egen x=fill(1 2),再输入 egen y=fill(100 99),查看数据。fill 参数只有 2 位数时,生成等差数列。如果是多个参数,则将 fill 内参数视为规律,下面是 help 文档的例子。其中 c 的生成中括号3表示步长为3。

seq 函数也可以提供同样的功能。clear 后 set obs 20,再输入 egen a=seq(), b(2) 这个 b我猜是以多少个为一组,b(2)以2个为一组,从1开始生成 (1 1 2 2 3 3 这样的)。输入 egen b=seq(), t(5) 得到从1-5的重复数列,t是to的意思,默认从1开始。输入 egen c=seq(), f(15) t(20) 得到从15-20的重复数列,f是from的意思。
1.4 变量查看补充
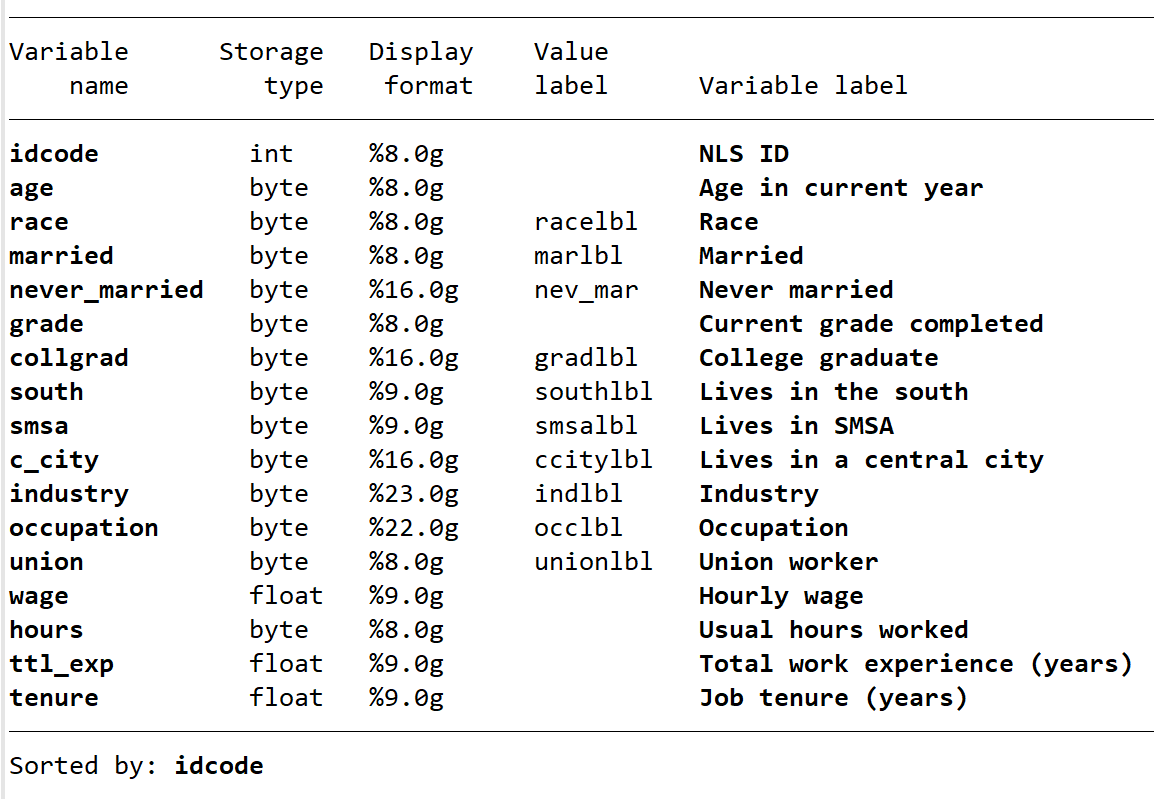
上篇中提到过 describe 函数可以提供相应变量存储类型,展示格式,相应标签的信息。如果想简单了解整个数据集时,输入 d, short。其提供了观测值数量,变量个数,分类标准,数据集标签以及在哪里存储。

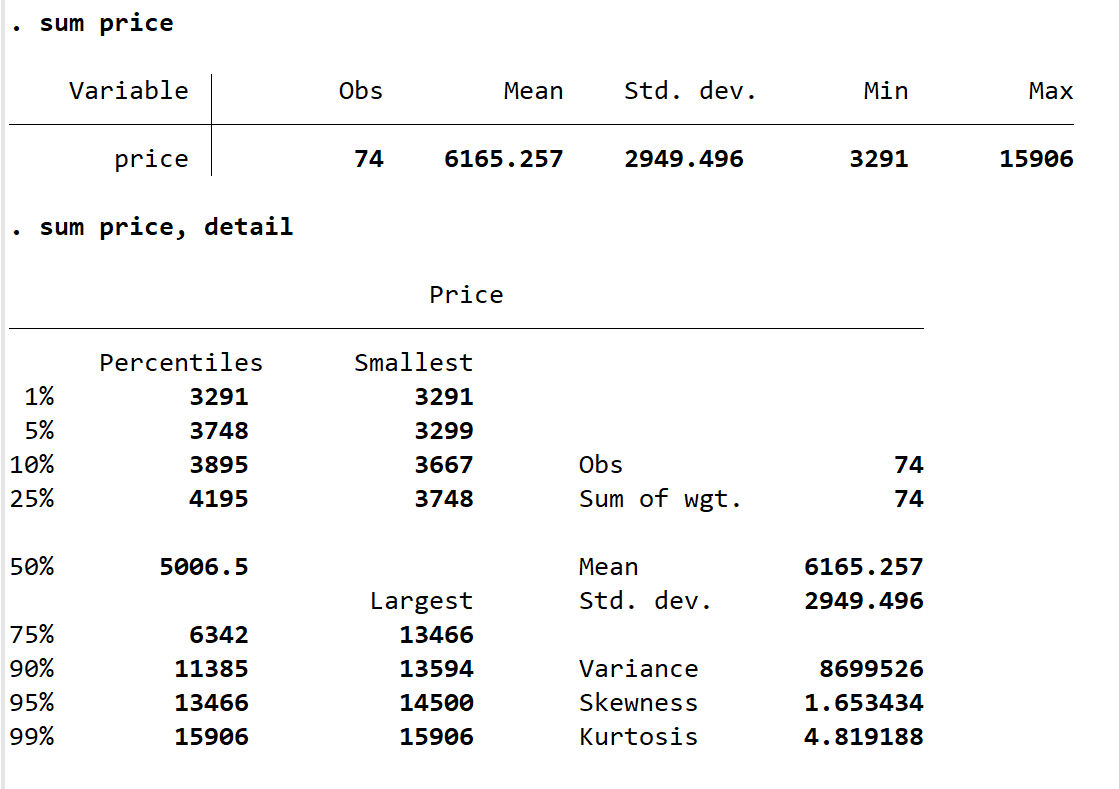
sum 函数可以展示变量观测值个数、均值、方差与取值范围,如果想进一步了解变量值的分布,则加入 detail 的选项。输入 sum price, detail。其展示了 price 的百分位数临界值与最小值,还有峰度等信息。
sum加detail选项虽然可以给出具体的分布数值,但图表更为直观,若要生成图又特别麻烦,那应该使用 inspect命令,该命令可以给出数据简要分布图表。输入 inspect rep78,左侧图是数据分布简要图,rep78有5个不同的取值,取值范围是1-5,点不是缺失值,而是说取值为1的很少,#则是很多的意思。右侧表指总观测值有74个, missing表示缺失值有5个,并且缺失值不视作不同的取值,但会报告出来。
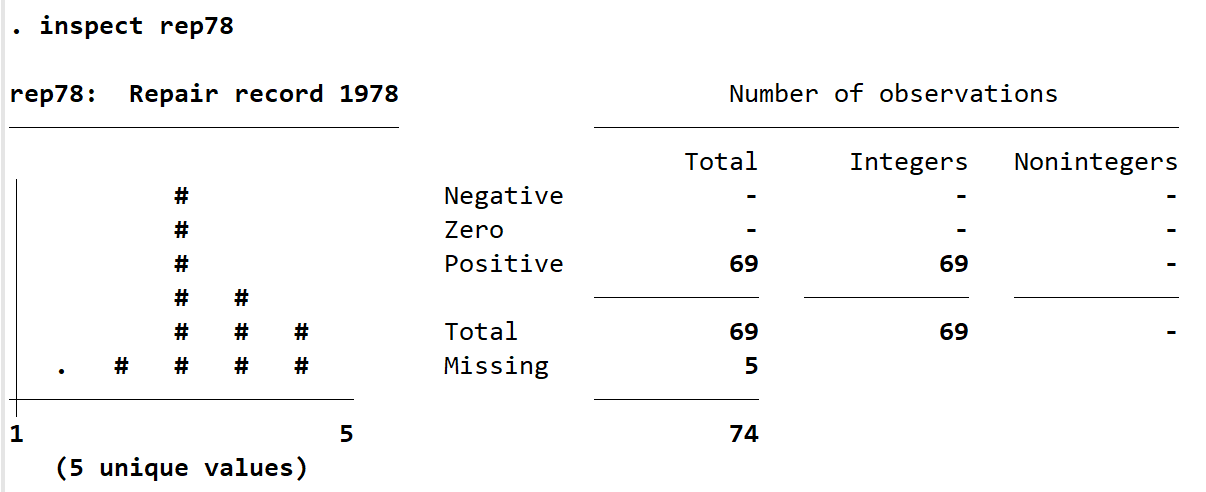
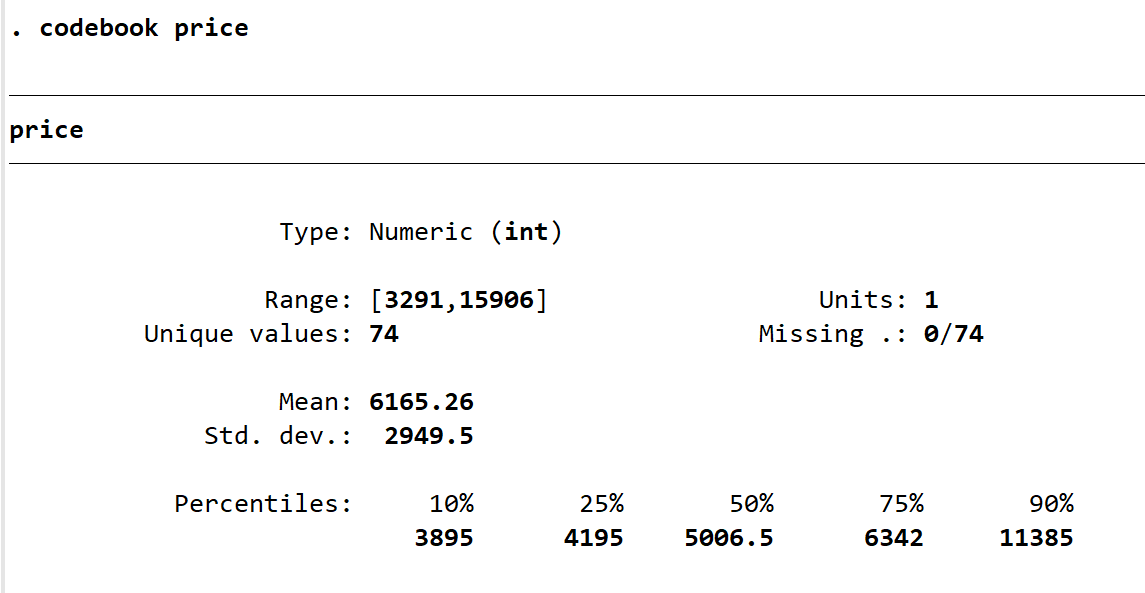
sum与detail的另一个类似命令为 codebook,其可以给出更为简洁有效的数据信息。输入 codebook price,可以得到数值范围,非重复值个数,缺失值占比,均值方差与百分位数。很好用
lookfor 函数
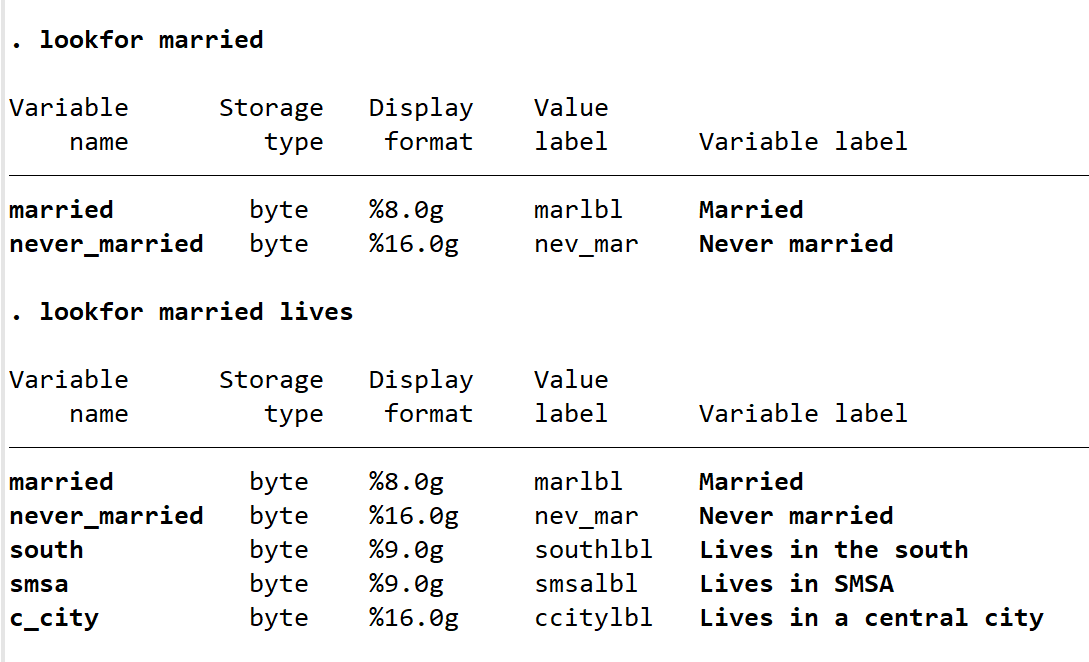
lookfor 函数可以在变量非常多时找到相关变量。sysuse nlsw88, clear。输入 lookfor married,如果变量名和变量标签或者值标签中包含 married 字样,则对此返回。如果输入两个变量 lookfor married lives 会一个一个变量查找,而不是找同时包含 married 与 lives 字样的变量。
elabel 标签管理命令
elabel 是标签管理命令,支持模糊搜索、条件语句、定义值标签、修改变量名与值标签名,而这些操作若使用 label 非常麻烦。
sysuse nlsw88, clear 后输入 d,可看到值变量的情况。我们现在要查看 race 的值与标签对应情况,如果用 label 则需记得 race 的值标签名。我们可以看到 race 的值标签名为 racelbl,但若忘了,则需要输入 label list。但这一命令会列出所有值变量的标签很烦人,elabel 可以很好的解决这一点。
如果你记得 race 的值标签是以 r 开头的,则使用通配符辅助。输入 elabel list r*。通配符的意思是可以代表任意字符,其中 ? 表示一个模糊字符,* 代表一个或多个匹配字符。上图中有两个 s 开头的值标签名,可以输入 elabel list s*查看结果。如果时间过于久远不记得race的值标签名是什么了,可以输入 elabel list (race) 会显示同样的结果。race 是要查询的变量,注意需括起来,为啥我也不知道。这可以直接通过变量查询值与标签的对应情况,非常方便。

elabel 支持条件表达式使得在值非常多时可以迅速找到对应信息。输入 elabel list (occ*),会得到下图。

我们现在想查询1-6对应的标签,输入 elabel list (occ*) iff (#<7),可得到第一个结果。条件用 iff 表示,注意是 iff 而不是 if ,我觉得应该是和stata自带的 if 所区别而特意设置的。#表数字占位符,意思是这里我需要一个数值,但是我不知道这个数值是多少,采用 # 表示模糊替代。在许多命令的 help 文档里,函数选项里多有 #,例如 abb(#) 表示的任意字数的缩写,好像 # 有运算的含义,但在函数选项里是数字占位符。
如果想查询职
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7648
7648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









