







 本文介绍了朴素贝叶斯分类模型的基本原理和数学表达,包括先验概率和条件概率的计算。通过西瓜分类的例子详细解释了模型如何工作,并提到了拉普拉斯修正方法来处理概率估计问题。同时,讨论了参数估计中的极大似然估计法。
本文介绍了朴素贝叶斯分类模型的基本原理和数学表达,包括先验概率和条件概率的计算。通过西瓜分类的例子详细解释了模型如何工作,并提到了拉普拉斯修正方法来处理概率估计问题。同时,讨论了参数估计中的极大似然估计法。
1、基本假设:各个维度上的特征被分类的条件概率之间是相互独立的
2、原理:单独考量每一维度特征被分类的条件概率,进而综合这些概率并对其所在的特征向量做出分类预测。
3、数学表达

p(y)的获得其实也较为简单:计算D中y的各个情况出现的频率即可(这里用到了大数定律:当训练集包含充足的独立同分布样本时,P(y)可通过各类样本出现的频率来进行估计)
p(x|y)的获得略显困难,因为x往往包含多个相关因素(是一个多种因素构成的向量)。
所以目标转换为 agrmax 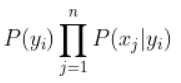

4、例子讲解
(1) 假设我们的任务是根据一个西瓜的特征来在它被吃之前判断它是否是个好瓜。现在我们有以下数据集:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4830
4830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









