





目录:
1.贝叶斯分类器的基础
2.朴素贝叶斯分类器
3.朴素贝叶斯分类实例
4.关于朴素贝叶斯容易忽略的点
5.朴素贝叶斯分类器的优缺点
1. 摘要
贝叶斯分类器是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类器。而朴素贝叶斯分类器是贝叶斯分类器中最简单,也是最常见的一种分类方法。并且,朴素贝叶斯算法仍然是流行的十大挖掘算法之一,该算法是有监督的学习算法,解决的是分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。但由于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。
2. 贝叶斯分类器的基础
要想学习贝叶斯算法的要领,我们需要先了解先验概率、后验概率的概念。
先验概率:是指根据以往经验和分析得到的概率。
举个例子:如果我们对西瓜的色泽、根蒂和纹理等特征一无所知,按照常理来说,西瓜是好瓜的概率是60%。那么这个概率P(好瓜)就被称为先验概率。
后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。
举个例子:假如我们了解到判断西瓜是否好瓜的一个指标是纹理。一般来说,纹理清晰的西瓜是好瓜的概率大一些,大概是75%。如果把纹理清晰当作一种结果,然后去推测好瓜的概率,那么这个概率P(好瓜|纹理清晰)就被称为后验概率。后验概率类似于条件概率。
联合概率:设二维离散型随机变量(X,Y)所有可能取得值为
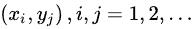
,记
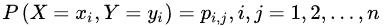
则称
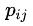
为随机变量X和Y的联合概率。计算如下:
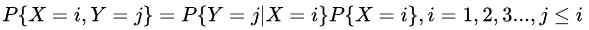
举个例子:在买西瓜的案例中,P(好瓜,纹理清晰)称为联合分布,它表示纹理清晰且是好瓜的概率。关于它的联合概率,满足以下乘法等式:
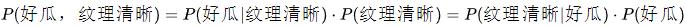
其中,P(好瓜|纹理清晰)就是后验概率,表示在"纹理清晰"的条件下,是"好瓜"的概率。P(纹理清晰|好瓜)表示在"好瓜"的情况下,是"纹理清晰"的概率。
全概率:如果事件组
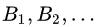
满足:
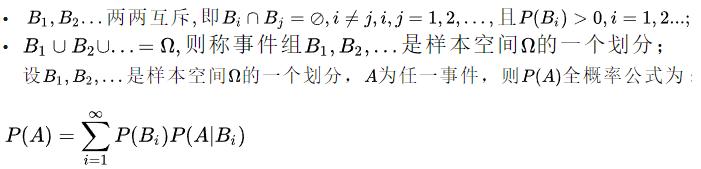
全概率公式的意义在于:当直接计算P(A)较为困难时,而
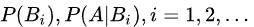
的计算较为简单时,可以利用全概率公式进行计算P(A)。
举个例子:上面联合概率概念买西瓜的例子中,我们要计算P(好瓜,纹理清晰)联合概率时,需要知道P(纹理清晰)的概率。那么,如何计算纹理清晰的概率呢?实际上可以分为两种情况:一种是好瓜状态下纹理清晰的概率,另一类是坏瓜状态下纹理清晰的概率。纹理清晰的概率就是这两种情况之和。因此,我们可以推导出全概率公式:
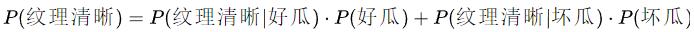
贝叶斯定理:贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件
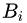
的概率),设
是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有贝叶斯定理:
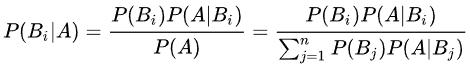
对于特征集合x,我们想要知道样本在这个特征集合x下属于哪个类别,即求后验概率P(c|x)最大的类标记。这样基于贝叶斯公式,可以得到:
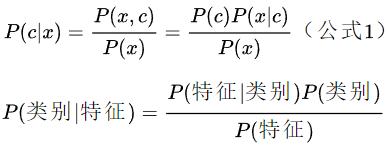
好了,学习完上面的先验概率、后验概率、联合概率、全概率、贝叶斯定理后,我们来小试牛刀一下:
西瓜的状态分为两种:好瓜与坏瓜,概率分别为0.6和0.4,并且好瓜里面纹理清晰的概率是0.8,坏瓜里面纹理清晰的概率是0.4。那么,我现在挑了一个纹理清晰的瓜,该瓜是好瓜的概率是多少?
很明显,这是一个后验概率问题,我们可以直接给出公式:

对公式里面出现的概率一个一个分析:
后验概率:P(纹理清晰|好瓜) = 0.8
先验概率:P(好瓜) = 0.6
后验概率:P(纹理清晰|坏瓜) = 0.4
先验概率:P(坏瓜) = 0.4
由上面分析的数值,我们可以直接求解上式:
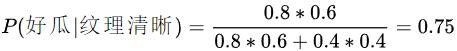
这样,我们就计算得到了纹理清晰的情况下好瓜的概率是0.75。上面计算后验概率P(好瓜|纹理清晰)的公式就是利用了贝叶斯定理。
3. 朴素贝叶斯分类器
不难发现,基于贝叶斯公式(公式1)来估计后验概率P(c|x)的主要困难在于:类条件概率P(x|c)是所以属性上的联合概率(即x代表的是多个属性),难以从有限的训练样本直接估计而得。为了避开这个障碍,朴素贝叶斯分类器(naive Bayes classifier)采用了"属性条件独立性假设":对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。
朴素贝叶斯的算法步骤:
1. 设某样本属性集合
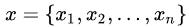
,其中 n 为属性数目,
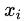
为x在第i属性上的取值。
2. 把这个样本划分为类别集合c中的某一类,
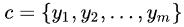
。
3. 计算后验概率:
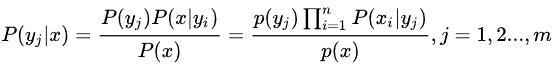
其中,
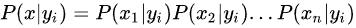
,体现了朴素贝叶斯的精髓:每个特征相互独立。
那么,如何计算出
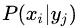
呢?首先找到一个已知类别分类集合,在这个集合中统计特征属性在各个类别下的条件概率,即得到我们要计算的
。
值得注意的是:上式中的分母部分,对于所有的类别来说都是一样的。因此可以省略,针对不同的
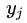
仅需要比较
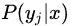
的分子部分。
4. 如果
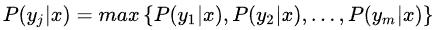
,则样本在属性集x下属于
。
温馨提示:如果对上面的算法步骤有点困惑,可以先看下面的例子,然后再回过头来理解朴素贝叶斯的算法步骤,理解效果会更好一点。
4. 朴素贝叶斯分类实例
我们已经了解了贝叶斯定理和朴素贝叶斯算法,可能你对上面的朴素贝叶斯算法还很困惑。这一小节,我们用一个实例来熟悉朴素贝叶斯算法。
我们还以买西瓜为实例。现在,我们有包含10个样本的数据集,这组数据集是以纹理、色泽、敲声为特征判断是好瓜还是坏瓜。数据集如下:

图1:样本数据集
其中,纹理分为:清晰和模糊,色泽分为:青绿和乌黑,敲声分为:浊响、沉闷和清脆。不同的特征值组合对应着两类:好瓜还是坏瓜。
现在,我从超市中挑选了一个西瓜,它的纹理清晰、色泽青绿、敲声沉闷。我们可以根据样本数据集和朴素贝叶斯算法来计算该西瓜是好瓜还是坏瓜?
(1)首先,计算好瓜的情况:
先验概率:P(好瓜)= 6 / 10 = 0.6
条件概率:P(纹理清晰 | 好瓜) = 4 / 6 = 2 / 3
条件概率:P(色泽青绿 | 好瓜) = 4 / 6 = 2 / 3
条件概率:P(敲声沉闷 | 好瓜) = 2 / 6 = 1 / 3
计算后验概率P(好瓜 | 纹理清晰、色泽青绿、敲声沉闷)分子部分:
P(好瓜) x P(纹理清晰 | 好瓜) x P(色泽青绿 | 好瓜) x P(敲声沉闷 | 好瓜) = 0.6 × (2 / 3) × (2 / 3) × (1 / 3) = 4 / 45。
(2)然后,计算坏瓜的情况:
先验概率:P(坏瓜) = 4 / 10 = 0.4
条件概率: P(纹理清晰 | 坏瓜) = 1 / 4 = 0.25
条件概率: P(色泽青绿 | 坏瓜) = 1 / 4 = 0.25
条件概率: P(敲声沉闷 | 坏瓜) = 1 / 4 = 0.25
计算后验概率P(坏瓜 | 纹理清晰、色泽青绿、敲声沉闷)分子部分:
P(坏瓜) × P(纹理清晰 | 坏瓜) × P(色泽青绿 | 坏瓜) × P(敲声沉闷 | 坏瓜) = 0.4 × 0.25 × 0.25 × 0.25 = 1 / 160。
(3)比较好瓜、坏瓜类别中的后验概率:
P(好瓜 | 纹理清晰、色泽青绿、敲声沉闷)> P(坏瓜 | 纹理清晰、色泽青绿、敲声沉闷),即4 / 45 > 1 / 160,所以预测该纹理清晰、色泽青绿、敲声沉闷西瓜为好瓜。
5. 关于朴素贝叶斯容易忽略的点
(1)由上文看出,计算各个划分的条件概率
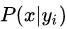
是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,能很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计
,下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
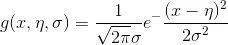
则:
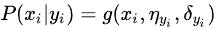
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。均值与标准差的计算在此不再赘述。
(2) 另一个需要讨论的问题就是当
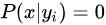
怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
6. 朴素贝叶斯分类器的优缺点
(1)优点:
1)简单易懂、学习效率高。
2)分类过程中时空开销小。
(2)缺点:
算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,会导致算法精度在某种程度上受影响。














 5332
5332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









