






1.说说Innodb索引
1.Innodb索引使用的B+树,
2.在存数据的时候首先会进行排序,然后通过指针的形式将数据链接起来。
3.存取数据时,对数据进行了分叶存储,一个叶子结点大约为16KB
2.索引分类
普通索引:允许被索引的数据列包含重复值
唯一索引:可以保证数据记录的唯一性,允许有空值
主键索引:是一种特殊的唯一索引,不允许有空值
联合索引:由多个数据列组合(遵循最左前缀原则)
全文索引:用来搜索的
主键索引和唯一索引的区别,主键索引不允许有空值。
最左前缀原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。

3.B- 树和B+树的区别
- 非叶子结点只能存储键值信息
- 数据记录都存在叶子结点上
- 所有的叶子结点之间都有链指针。
4.聚簇索引和非聚簇索引
聚簇索引:就是将数据与索引放在一起,叶子节点保存了数据信息
非聚簇索引:将数据和索引分开放,叶子节点保存的是主键值
主键索引一定是聚簇索引
非聚簇索引查找数据总是需要二次查找(先找到Id,在根据id找到数据)
聚簇索引默认是主键,如果表中没有定义主键,InnoDB会选择一个唯一且非空的索引代替,如果没有这样的索引,会隐式的定义一个主键作为聚簇索引,如果已经设置了主键为聚簇索引又希望单独设置聚簇索引,必须先删除主键,然后再添加我们想要的聚簇索引。
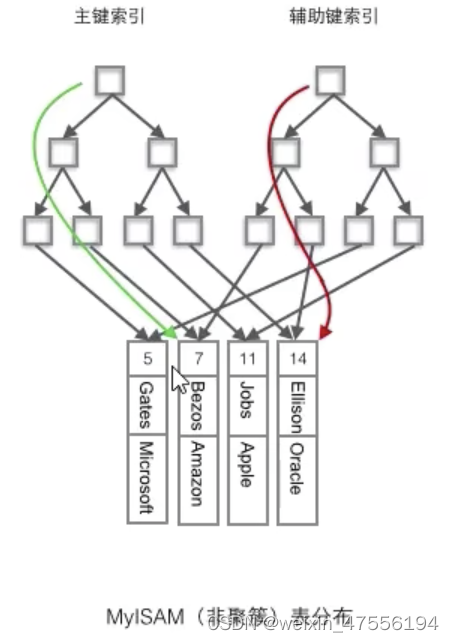
5.MyISAM
使用的是非聚簇索引,辅助键索引和主键索引都指向真实数据的地址,不需要二次查找。
6.聚簇索引的优点
1.访问数据更快,聚簇索引将索引和数据保存在一个B+树上,因为比非聚簇索引获取数据更快,非聚簇索引还得回表到聚簇索引上根据主键查询需要的数据行。
2.由于同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到内存中,再次访问时,会在内存中访问,获取数据更快。
7.回表
当我们需要查询的时候:
如果是通过主键索引来查询数据,例如 select * from user where id=100,那么此时只需要搜索主键索引的 B+Tree 就可以找到数据。
如果是通过非主键索引来查询数据,例如 select * from user where username='javaboy',那么此时需要先搜索 username 这一列索引的 B+Tree,搜索完成后得到主键的值,然后再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
对于第二种查询方式而言,一共搜索了两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。
从上面的分析中我们也能看出,通过非主键索引查询要扫描两棵 B+Tree,而通过主键索引查询只需要扫描一棵 B+Tree,所以如果条件允许,还是建议在查询中优先选择通过主键索引进行搜索。
8.MySQL为什么用自增主键?
MySQL数据记录本身存放在B+树的叶子节点上,这个要求每一个叶子节点内(大小为16K)的各条数据记录按主键顺序存放。当有一条新数据插入时,MySQL会根据逐渐插入适当的节点和位置,如果页面写满了,就会重新开辟一个叶子节点。
如果使用自增主键,当插入新纪录后,记录就会添加到当前索引节点的后续位置,当一页写满,就会自动开辟新的一页。
如果使用非自增主键,由于每次插入逐渐的值近似于随机,因此每次新纪录都要被查到现有索引的中间位置,此时MySQL不得不为将新纪录差到合适记录而移动数据,这个过程增加了很多开销。
9.什么情况下索引失效
- 1.查询语句中使用Like关键字
在查询语句中使用like,如果匹配字符串的第一个字符为“%”,索引就不会生效。 - 2.联合索引不遵循最左前缀原则
- 3.查询语句使用OR关键字
- 查询语句只有OR关键字,如果OR前后两个条件都是索引,那么查询中将使用索引。如果前后有一个条件不是索引,那么查询中索引不会生效。
- 4.如何字段类型是字符串,where时一定用引号括起来,否则索引失效
- 5.对索引使用了函数
- 6.对索引进行表达式计算
10.MyISAM和InnoDB区别
- 1.是否支持行级锁
MyISAM只有表级锁,InnoDB支持行级锁和表级锁,默认行级锁 - 2.是否支持事务和崩溃后安全恢复
MyISAM不支持事务,InnoDB支持事务 - 3.是否支持外键
MyISAM不支持外键,InnoDB支持 - 4.索引
MyISAM是非聚簇索引,InnoDB是聚簇索引 - 5.是否支持MVCC
仅InnoDB支持,MVCC仅在RC和RR隔离级别下工作。
使用场景:
MyISAM管理非事务表,具有高速存储和检索能力,所以需要执行大量SELECT语句时,可以使用MyISAM
InnoDB用于事务处理应用程序,遵循ACID原则,如果需要执行大量Insert和update语句时,可以使用InnoDB。
11.执行一条SQL语句很慢的原因有哪些?
大多数情况是正常的,只是偶尔会出现很慢的情况
1.数据库刷新脏页
当我们要往数据库中插入一条数据或者 更新-条数据时, 数据库会在内存中把对应字段的数据更新了,但是更新完毕之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到redo log日志中去,只有等到空闲的时候才会通过redo log里的日志把最新的数据同步到磁盘里。这里redo log的容量是有限的,所以如果数据库一直很忙且 更新有很频繁,那么这个时候redo log很快就会被写满,从而没办法等到空闲时再把数据同步到磁盘,只能暂停其他操作,全身心来把数据同步到磁盘中去,造成的表象就是我们平时正常的SQL语句突然会执行的很慢。
也就是说,数据库在同步数据到磁盘的时候就有可能会导致我们的SQL语句执行的很慢。
2.无法获取锁资源
执行的时候遇到了表锁或者行锁。
如果我们要执行的SQL语句,其涉及到的表正好别人在用并且加锁了,或者表并没有加锁,但是要使用到的某-行被加锁了,那么我们便无法获取锁,只能慢慢等待别人释放锁了。
12.count

count(1):其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1,这个字段也可以有null
13.MySQL为什么用B+树,而不用B树?
1.b+树只有叶子节点存数据 b树是每个节点都存数据 在相同数据量下b树的高度更高,所以查询效率更低
2.b树每一层存的是数据+索引;
3.b+树是除了叶子节点存的是数据+索引以外,其余节点只存索引,所以在相同数据量的情况下,b树的高度会比b+ 树高很多
MVCC
MVCC组成:
(1)隐藏字段:
- DB_TRX_ID:最后一次创建或者修改该记录的事务id
- DB_ROW_ID:隐藏主键
- DB_ROLL_PTR:回滚指针(一般与undolog使用)
(2)undo log
通过回滚指针将历史记录连在一起
(3)readview
对我们的进行读取的版本进行控制,通过readview我们才知道自己能够读取哪个版本。 - trx_list:系统活跃的事务id(未提交的事务id)
- up_limit_id:列表中事务最小的id
- low_limit_id:系统尚未分配的下一个事务id
可见性算法:
1、首先比较DB_TRX_ID < up_limit_id,如果小于,则当前事务能看到DB_TRX_ID所在的记录,如果大于等于进入下一个判断
2、接下来判断DB_TRX_ID >= low_limit_id,如果大于等于则代表DB_TRX_ID所在的记录在Read View生成后才出现的,那么对于当前事务肯定不可见,如果小于,则进入下一步判断
3、判断DBTRXID是否在活跃事务中,如果在,则代表在Read View生成时刻,这个事务还是活跃状态,还没有commit,修改的数据,当前事务也是看不到,如果不在,则说明这个事务在Read View生成之前就已经开始commit,那么修改的结果是能够看见的。
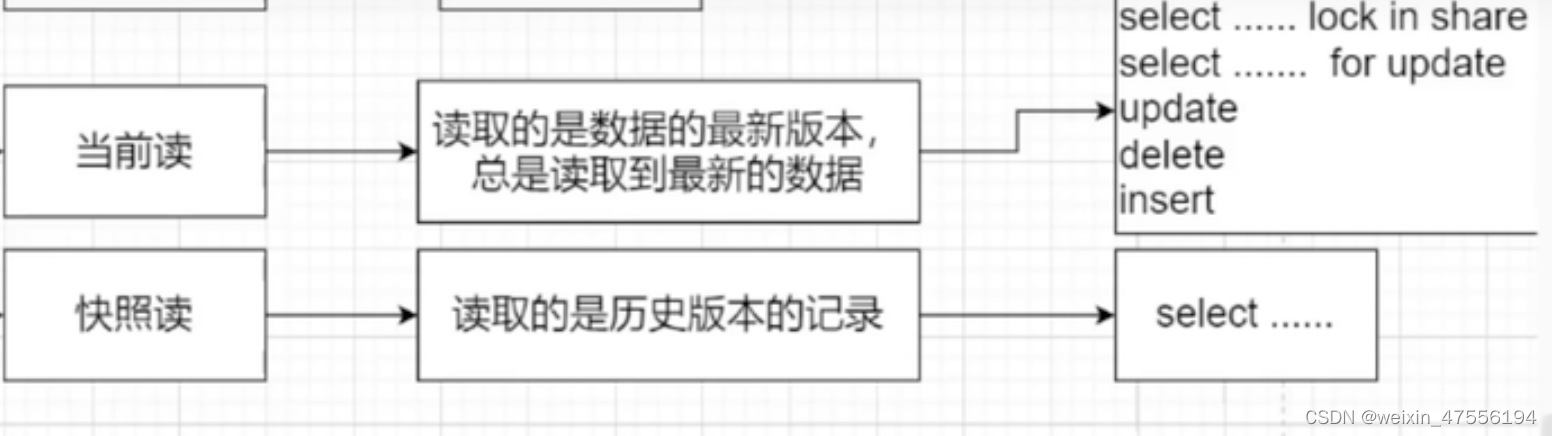
RC:每次在进行快照读的时候都会生成新的readview
RR:只有在第一次快照读时才会生成readview,之后的读操作都会使用第一次生成的readview
RR级别什么情况下第一次快照读失效
当第一次产生快照读(select)之后,继续使用了当前读(update,insert,delete等),再次进行快照读,存取的数据与第一次不同。
ACID
- 原子性 : undo log
- 一致性
- 隔离性:MVCC
- 持久性:redo log->两阶段提交->先写日志在写数据
两阶段提交:

一条 SQL 的执行过程详解
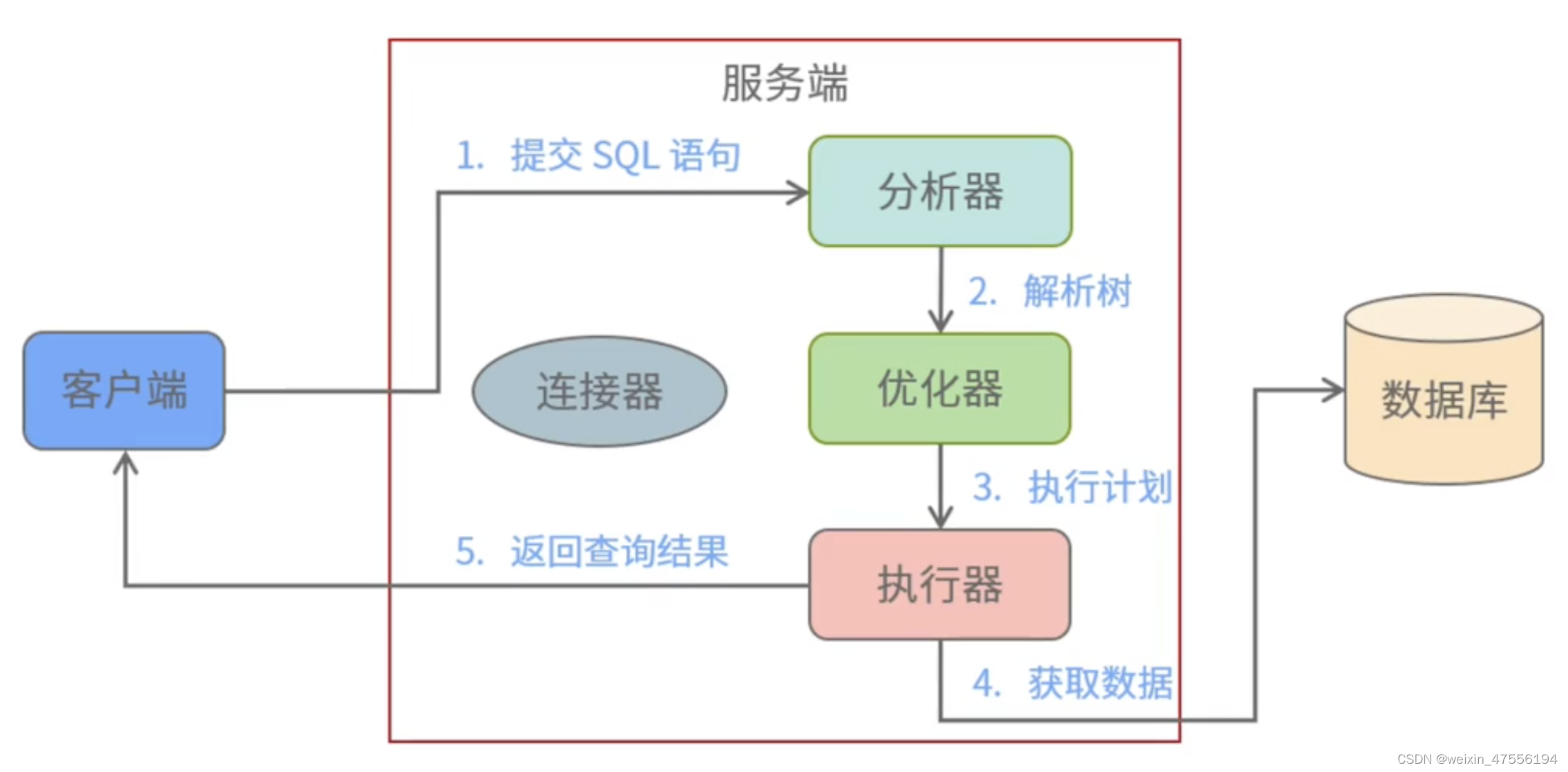
过程:
1.建立客户端与服务器端连接,
2.发送一条sql语句到分析器,判断语法有没有错误,表,列名,属性是否正确,如果正确生成解析树;
3.解析完成后,通过优化器选择最优执行过程,执行sql语句
4.通过执行器去数据库获取数据。
5.将查询结果数据发给客户端。
慢查询优化
- 查看索引是否失效
- 在写多读少的情况下,使用普通索引
- 分解关联查询,将一个大的查询分为多个小查询
- 优化Limit分页
- 优化数据库结构,分库分表等等。
Exists和in的效率问题
in适合于外表大而内表小的情况,in()适合B表比A表数据小的情况
select * from A where A.id in(select B.id from B);
exists适合于外表小而内表大。exists()适合B表比A表数据大的情况
select * from A where exists (select 1 from B where A.id=B.id);
原因:EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值TRUE 或FLASE 。只要查询到一个即可。
in是查询出B表中的所有符合的信息并缓存起来,需要遍历全部数据。
左连接、右连接、全连接、内连接区别
左连接:是以左表为基础,根据ON后给出的两表的条件将两表连接起来。结果会将左表所有的查询信息列出,而右表只列出ON后条件与左表满足的部分。右表没有的数据用null。
右连接:是以右表为基础,根据ON后给出的两表的条件将两表连接起来。结果会将右表所有的查询信息列出,而左表只列出ON后条件与右表满足的部分。左表没有的数据用null。
内连接:只返回两个表中连接字段相等的行。
全连接:返回左右表中所有的记录和左右表中连接字段相等的记录。














 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









