






在深度学习的征途中,高质量的数据集是通往卓越模型性能的金钥匙。特别是针对遥感影像的语义分割任务,细致精确的标注工作是基石。若您已使用ArcGIS精心标注了面要素,想要使之适应YOLOv8这一热门检测框架,一场标注格式的“跨界融合”势在必行!
 转为图中的txt点
转为图中的txt点 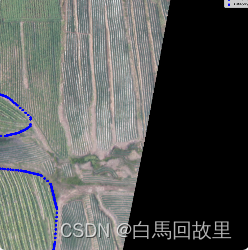
转换代码具体代码如下:
import cv2
import numpy as np
from pathlib import Path
import os
from shapely.geometry import Polygon
# 确保Pillow库的Image已被正确导入
from PIL import Image
global_unique_class_ids = set()
classes_of_interest = [0, 34, 17, 51, 255] #对应你的图片不同像素代表不同的类,根据自己需求改
def record_unique_class_ids(mask):
"""
记录TIF图像中的独特类别ID到全局集合中。
"""
unique_ids_in_image = np.unique(mask)
global_unique_class_ids.update(unique_ids_in_image.tolist())
# 这个函数可以帮助你查看你的图片有哪些像素值
def print_unique_class_ids(tif_path):
"""
打印TIF图像中所有不同的类别ID(像素值)。
"""
with Image.open(tif_path) as img:
mask = np.array(img)
unique_class_ids = np.unique(mask)
print(f"Unique class IDs in {tif_path}: {unique_class_ids}")
def polygons_to_normalized_coordinates(polygons, img_width, img_height):
"""
将多个Polygon的顶点坐标归一化到0-1范围,并限制到四位有效数字。
"""
normalized_coords_list = []
for polygon in polygons:
coords = list(polygon.exterior.coords)
# 归一化坐标
norm_coords = [((x / img_width), (y / img_height)) for x, y in coords]
# 格式化为四位有效数字
formatted_coords = [[f"{x:.4f}", f"{y:.4f}"] for x, y in norm_coords]
normalized_coords_list.append(formatted_coords)
return normalized_coords_list
# 该函数的作用为将像素映射为正确的类别
def map_class_ids_to_consecutive_numbers(classes_of_interest):
"""
将列表中的类别ID映射到连续的整数。
"""
global global_unique_class_ids
all_unique_classes = sorted(global_unique_class_ids.union(set(classes_of_interest)))
class_id_mapping = {original_id: new_id for new_id, original_id in enumerate(all_unique_classes)}
return class_id_mapping
def apply_class_id_mapping(class_id, class_id_mapping):
"""
应用类别ID映射。
"""
return class_id_mapping.get(class_id, -1) # 如果找不到映射,则返回-1或处理错误
# 在批量处理开始前,构建类别ID映射
class_id_mapping = map_class_ids_to_consecutive_numbers(classes_of_interest)
def simplify_polygons_to_txt(tif_path, output_dir, classes_of_interest, class_id_mapping):
"""
更新版函数,包括归一化坐标并格式化为四位有效数字。
"""
with Image.open(tif_path) as img:
mask = np.array(img)
img_width, img_height = img.size
record_unique_class_ids(mask)
# 初始化字典,用于存储每个类别的多边形
polygons_dict = {cid: [] for cid in classes_of_interest}
# 对每个感兴趣的类别
for class_id in classes_of_interest:
# 获取该类别的掩码
class_mask = (mask == class_id).astype(np.uint8)
# 寻找轮廓
contours, _ = cv2.findContours(class_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 转换轮廓为Shapely Polygon,并收集顶点坐标
for contour in contours:
if len(contour.squeeze().tolist()) >= 4: # 确保轮廓至少有4个点
poly = Polygon(contour.squeeze().tolist())
polygons_dict[class_id].append(poly)
else:
print(f"警告:发现一个无效轮廓,点数不足。轮廓长度为{len(contour.squeeze().tolist())},位于{tif_path}")
# 保存多边形顶点到TXT
output_txt_path = Path(output_dir) / Path(tif_path).with_suffix('.txt').name
with open(output_txt_path, 'w') as f:
for class_id, polygons in polygons_dict.items():
mapped_class_id = apply_class_id_mapping(class_id, class_id_mapping)
for polygon in polygons:
formatted_coords = polygons_to_normalized_coordinates([polygon], img_width, img_height)[0]
f.write(f"{mapped_class_id} ")
for coord in formatted_coords:
f.write(" ".join(coord) + " ")
f.write("\n")
f.write("\n")
# print("Unique class IDs across all TIFF images:", global_unique_class_ids)
# 批量处理函数
tif_images_folder = 'E:\\img' # 图片标签的文件
output_folder = 'E:\\out' # 输出文件
def batch_simplify_and_save(input_folder, output_folder, classes_of_interest, class_id_mapping):
for tif_file in Path(input_folder).glob('*.tif'):
simplify_polygons_to_txt(str(tif_file), output_folder, classes_of_interest, class_id_mapping)
# 示例使用,增加class_id_mapping参数
batch_simplify_and_save(tif_images_folder, output_folder, classes_of_interest, class_id_mapping)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









