







1.MySQL配置文件

2.MySQL的逻辑架构

MySQL的逻辑架构也是分层处理的,一共分为4层:
- 连接层,最上层是一些客户端连接服务,包含本地的socket通信 和 基于客户端 服务器 的 TCP/IP通信,完成连接处理,授权认证等服务。该层还提供为连接准备的线程池。
- 服务层,完成大多数的核心服务,SQL接口,缓存查询,SQL的分析和优化,实现跨存储引擎的功能。服务器会在该层创建内部解析树,并对其完成优化以及确定查询顺序,是否利用索引,然后生成操作。如果是select还会查询内部缓存。
- 存储引擎层,服务器通过API与该层交互,不同存储引擎有不同的功能侧重点,根据作用去选择存储引擎,最常用的是innoDB,MyISAM。
- 存储层,通过与存储引擎的交互,把数据存到裸设备的文件系统上
innoDB和MyISAM的区别,面试题
回头补
SQL加载顺序

3.索引
索引是一种排好序的快速查询的数据结构
1.为什么会有慢查询
- 查询语句写的烂
- 索引失效
- 各种连接join,子查询 太多
7种join连接

只不过mysql不支持full outer join
图中的全连接 和 左右独有需要 用 union 可以把两条查询的结果连接起来然后去重
-
全连接:
select from A left join B on A.key = B.key
union
select from A right join B on A.key = B.key -
左右独有:
select from A left join B on A.key = B.key where A.key is null
union
select from A right join B on A.key = B.key where B.key is null
2.索引的优势劣势
回头补
3.索引的分类
- 单值索引,一个索引只包含一个列,一个表可以有多个单值索引
- 唯一索引,索引列的值必须唯一
- 复合索引,一个索引包含多个列
4.索引结构
- BTree树
- hash
- full-text
- R-Tree
BTree索引


4.explain怎么玩
mysql中有专门负责优化select语句的优化器模块,mysql query optimizer。他会进行性能分析,然后根据他认为最优的方式执行。
explain是模拟 优化器,可以看到对于当前sql,优化器咋执行的

包含这些字段
id,表查询顺序,如果是一个查询id都一样,子查询id会递增
- id相同,从上到下执行
- id不同,值大的优先执行
- 既有相同的又又不同的,先执行大的,在从上到下执行相同的
select_type,区别查询复杂程度

type,啥类型的查询,查询牛逼与否就看这个了
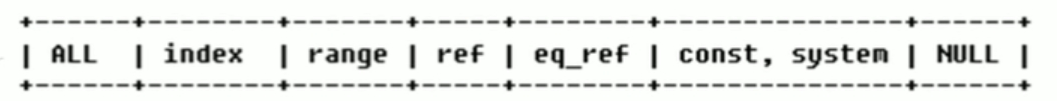

- system,就一行数据的表,叫什么玩意系统表,用不着
- const,索引查一次就查到了
- eq_ref, 根据条件查,对应的表里就一条,那就确定只有一条匹配的
- ref , 根据条件查,表里很多条,得都过一遍,找到所有匹配的,两者区别在于,哪怕最后只有一条匹配,但表是都过了一圈,因为不确定几条
- range , between , in 在一个范围里找,不如上面那个=精确
- index , 遍历整个索引树,和all一样都是找了一圈,但是索引树的空间小呀,所以比all牛逼
- all, 就是遍历全表
一般来说,最少得保证range级别,最好是ref,在往上也不太现实
possible_key, 就是优化器认为可能用到哪些索引
key, 实际执行了哪些索引
key_len,索引值长度,就是这列类型字节长度,字符类型会考虑字符集,允许为null加一bit,varchar加两bit
ref,执行表的哪个字段
row , 查找了多少行
extra,不适合在其他列显示,但又十分重要的信息,分为

其中,using filesort 是查询的时候用了索引,但是在排序的时候没用到索引,是很有可能引起mysql的性能问题的,
解决:
1.尽量把 order by的功能放在代码里做
2.把 order by的字段放在索引里面
3.注意> < 后面的索引会失效
using temporary,使用了临时表来保存中间信息,效率非常低,出现这个字段表示sql是烂sql
using index,表示sql非常好,也叫覆盖索引,就是只通过索引就取得了查询的字段,不用去读数据文件。
建立索引
两表查询的关联字段,如果是左连接就建在右表,右连接建在左表














 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









